Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Event-Driven Architecture is excellent for loose coupling between services. But as with everything, it comes with its challenges and complexity. One of which is Troubleshooting. I will dive into issues Wix.com experienced when using Kafka with over 2000 microservices. While this might not be your scale, you’ll likely encounter the same situations when working with Kafka or Event-Driven Architecture.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Tracing
One of the common issues people face with Event-Driven Architecture is understanding the flow of events and interactions that occur. Because of the decoupling of producers and consumers, it can be difficult to understand how a business process or workflow is executed. This is especially true if you’re using Event Choreography. If you’re unfamiliar with Event Choreography, check out my post Event Choreography for Loosely Coupled Workflow.
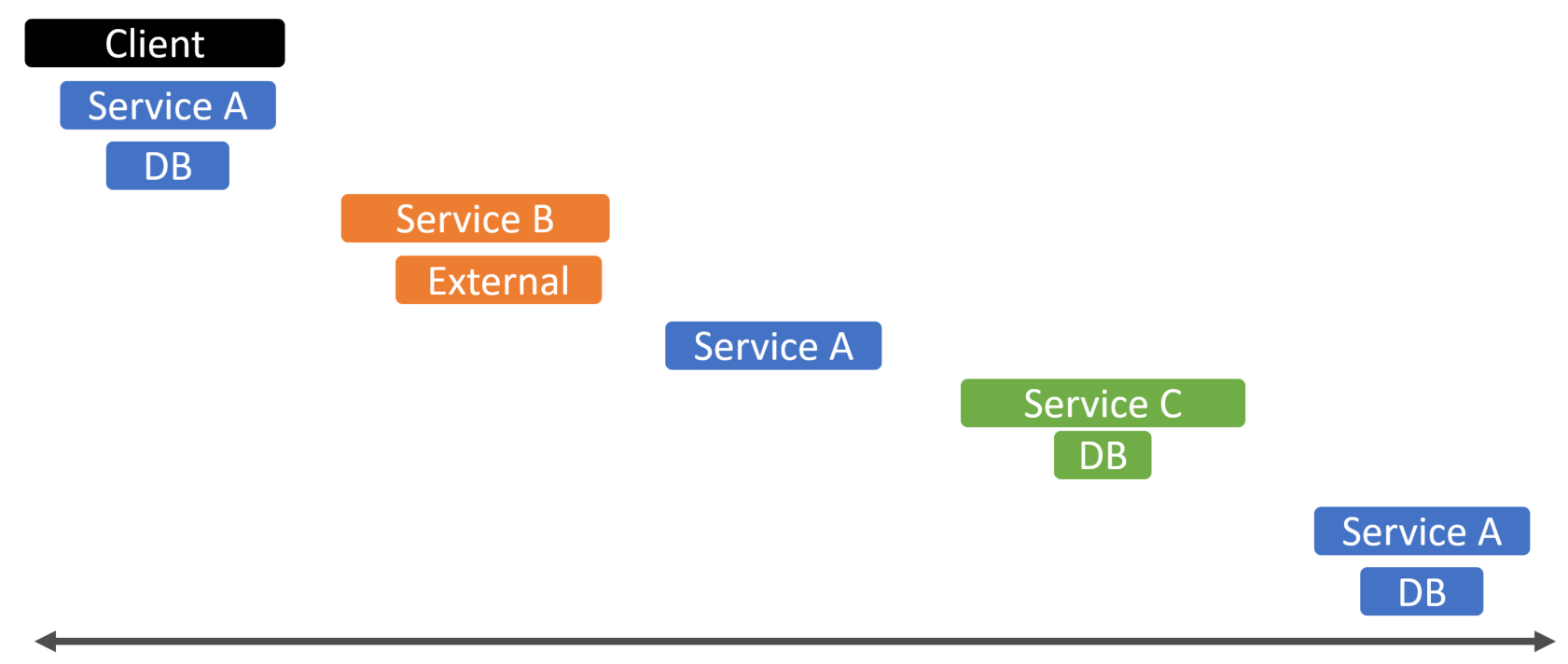
Consumers are processing events and publishing their own events. As you can expect, this can be difficult to debug if there are any issues along the way. That’s why distributed tracing is an important aspect if you have a lot of long-running business processes that are driven by events.
Because of the asynchrony of an event-driven architecture, typically, you’d want to see when an event was published, which other services consumed it, and when. Also, did they publish their own event that was also consumed by who? In other words, you want to correlate from the very beginning all events and also have causation from one event to another.
Over the last several years, distributed tracing has become a lot easier because of tools like OpenTelmery. This allows you to have multiple different services involved in providing tracing data for an entire business process.
As an example, here’s an inbound request that starts from ASP.NET Core and then flows through a message broker to various other services (Sales, Billing, Shipping). You can also see internal tracing such as database or HTTP requests that occurred.
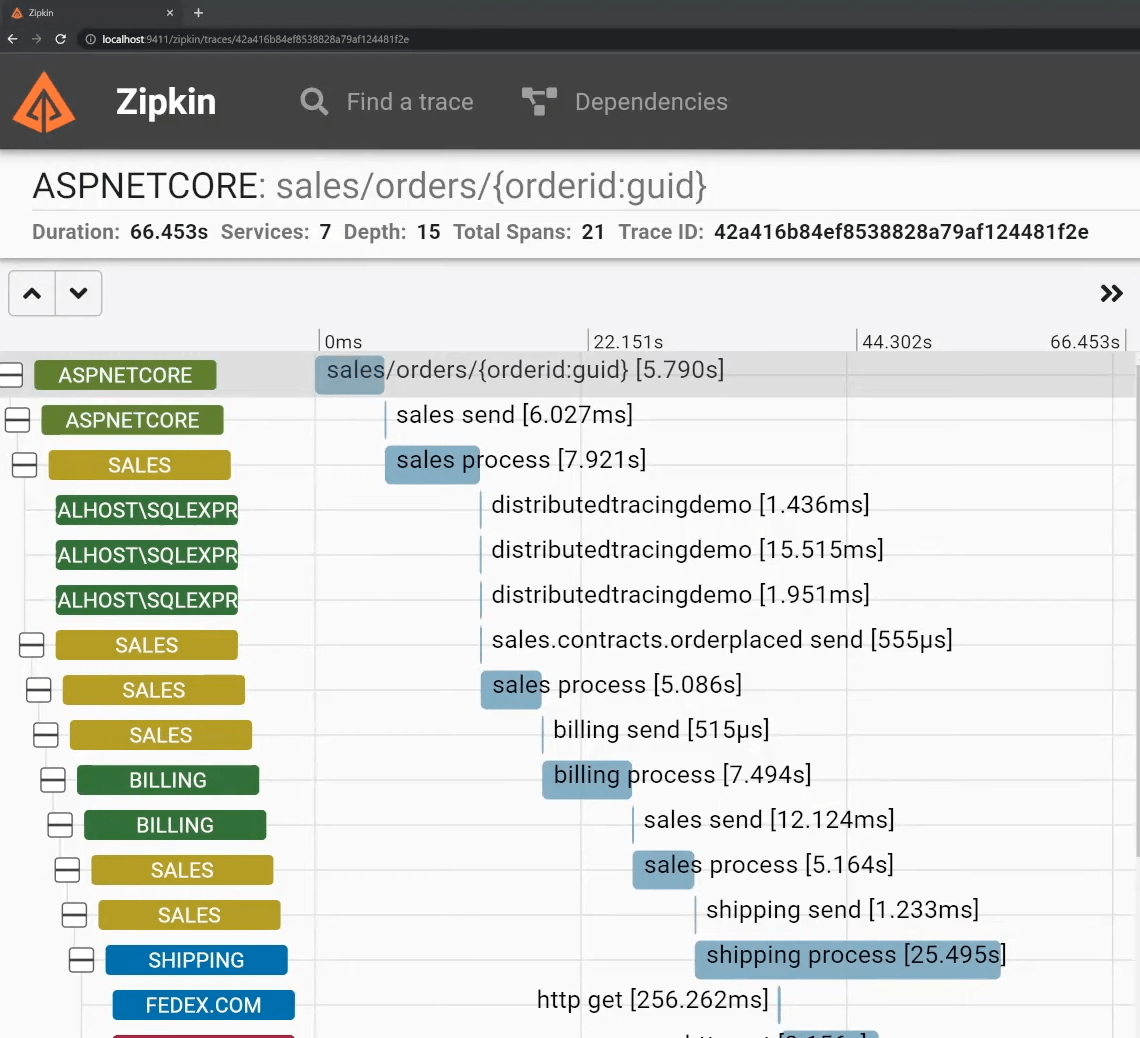
Check out my post on Distributed Tracing to discover a Distributed BIG BALL of MUD for more.
Ops
Continuing on with visualization, another common situation is wanting to have visibility into your topics. Wanting to look at messages that are published to topics, understanding where a given consumer is within the topic. While Wix.com uses Kafka, this is all very true if you’re using a queue-based broker such as RabbitMQ. You want to be able to see what messages are in a topic, and what their payloads are.
If an event has a bad/incorrect payload, either bad data or bad schema, you may need to manually fix that data so it can be consumed correctly. Having a dashboard, UI, and tooling around that is often required.
There are different tools depending on the messaging platform you’re using however I do find this space to be pretty limited still. This is why it seems most end up creating their own internal visualization, as did Wix.com
Consumer Lag
Consumer Lag occurs when events are being produced faster than you can consume them. Often there are peaks and valleys for producing events. During the valleys is when consumers can catch up so they are at or close to the most recent event published. Using a queue-based broker, you would think of this just as a queue backlog. This can happen for many reasons, one of them being the consumer cannot process an event.
The first aspect of this is knowing your topic/queue depth, processing times, latency, and other metrics. Having these types of metrics allows you to pre-emptively know when something might be going wrong and alarm.
If you’re producing 10 messages per second, and for whatever reason, you can only consume 5 messages per second, you’ll develop consumer lag that you’ll never catch back up.
With Kafka, a single partition is associated to a single consumer within a consumer group. The benefit to this is it allows ou to process messages in order from a partition. The downside to this is you don’t have competing consumers.
In the example below, there are two partitions (P1 & P2). There are three consumers. However, only one partition can have a consumer. This means that one consumer isn’t associated with any partitions.
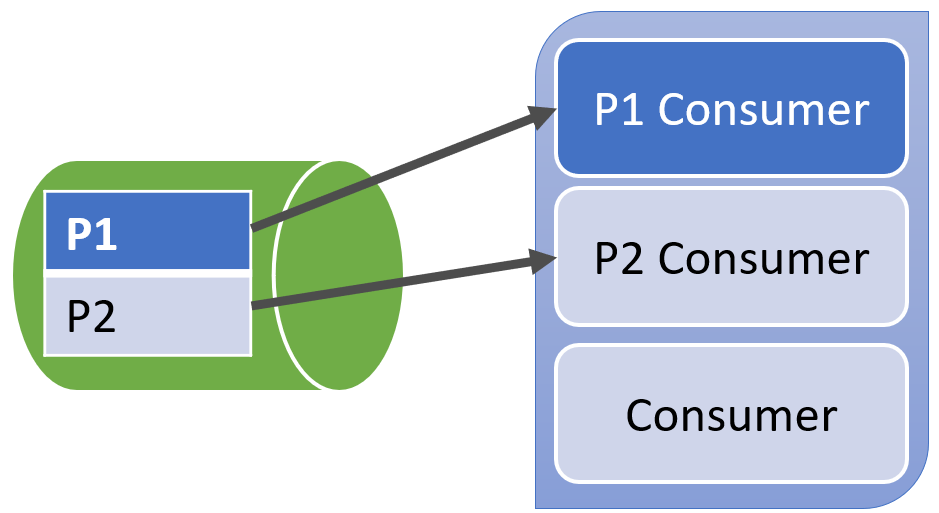
The benefit here is that because there’s a single consumer per partition, this allows for ordered processing. However, the trade-off is you can’t call out.
If you incorrectly produce more messages to a single partition, this is another reason why you may develop consumer lag.
Failures
As mentioned, consumer lag can also be caused by failing to process a message. If this occurs, what do you do with the message you can’t process? In a queue-based broker, you may move the message to a dead letter queue. With Kafka, you’d have to copy the message to a “Dead-Letter Topic”, and then move your cursor/index past the failing event in the topic.
However, if you’re using ordered processing, you might not be able to skip an event in the topic. Because of this, I often suggest looking at why you think you needed ordered processing. Check out my post Message Ordering in Pub/Sub or Queues, which elaborates on this more and gives examples of asynchronous workflows.
Troubleshooting Kafka
Regardless if you’re troubleshooting Kafka or a queue-based broker, or if you have 10 services or 2000 microservices, you’ll likely run into most described in the Wix.com post and this blog if you’re using an Event Driven Architecture. These are all very typical situations when working with an event-driven architecture so hopefully, they shed more light on what you’ll run into.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.