Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
With the popularity of Microservices, Kafka, and Event Sourcing, the term “Event” has become pretty overloaded and has caused much confusion about what EDA (Event-Driven Architecture) is. This confusion has led to conflating different concepts leading to unneeded technical complexity. I will shed some light on different aspects of EDA, such as Event Sourcing, Event-Carried State Transfer, and Events for Workflow.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
“Event”
If you ask people how they apply event-driven architecture, you’ll likely get many different answers. It would be best if you had specifics about how they use events, as there are many different purposes and utilities for them.

Events and EDA could be referred to when using events for state persistence, data distribution, and notifications. If you break these down further, those relate to Event Sourcing, Event Carried State Transfer, Domain Events, Integration Events, and Workflow events.
Let’s dig into all this to answer the question: “What do you mean by event?”
Event Sourcing
Event sourcing is about using events as a way of persisting state. Full stop. It has nothing to do with communication between service boundaries. It’s about state.
Check out my post Event Sourcing Example & Explained in plain English for more of a primer, or if you think you understand Event Sourcing.
Greg Young posted a snippet of a book he’s working on, in which he wanted a simple and clear definition to explain Event Sourcing.
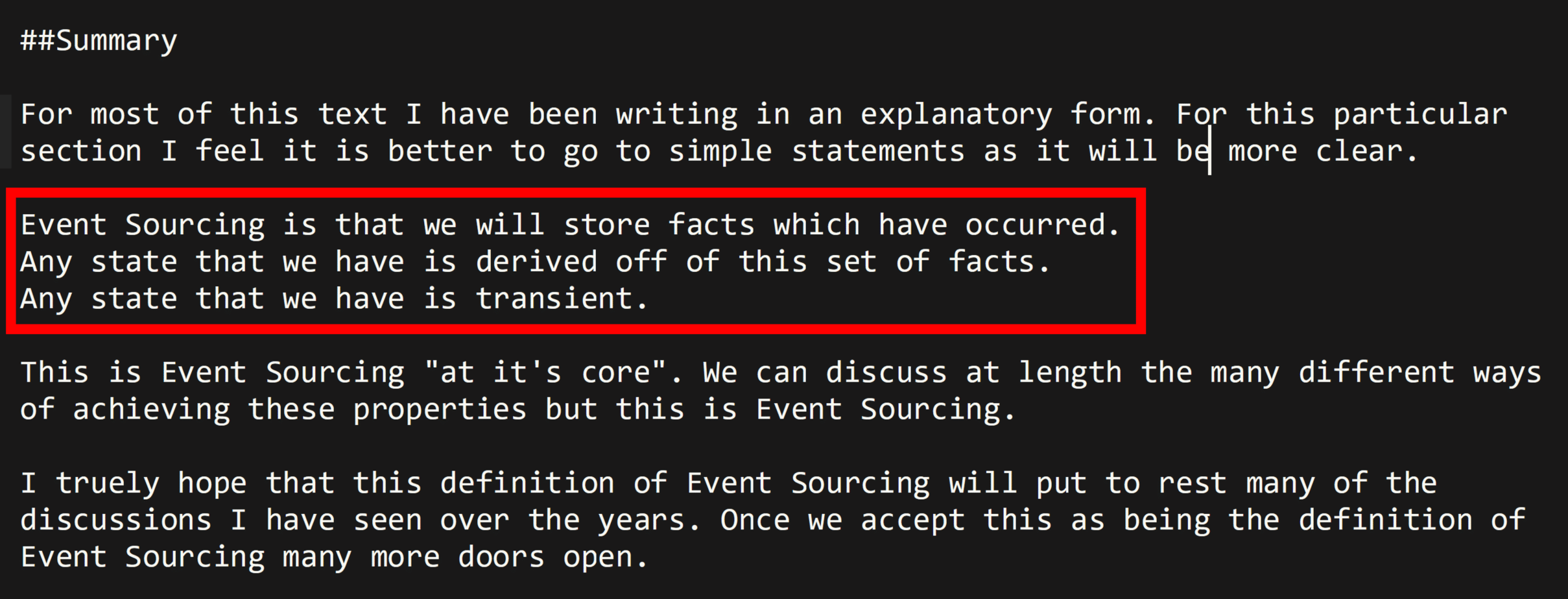
Event Sourcing is often confused with Event Streaming, or you must be using event sourcing to use events as means to communicate with other service boundaries. Which often means using the events used in event sourcing as a form of data distribution (more on that below).
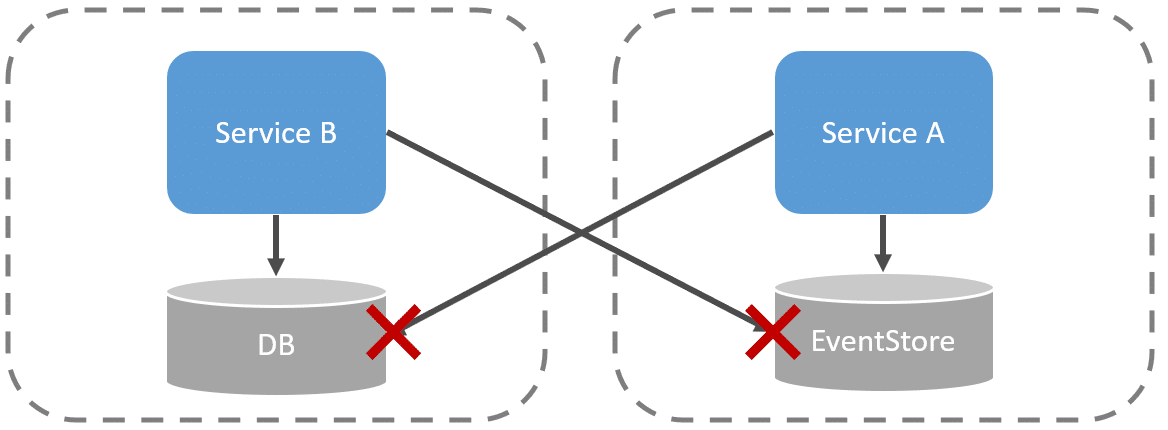
How you persist state is an internal implementation detail of your service boundary. You provide public APIs or contracts to expose any state within your service boundary. Other services should not reach out directly to your service boundaries database to query or write data. We don’t do this. We expose APIs as contracts for this and version them according. State persistence is an internal implementation detail. So if you use event sourcing to persist state, the same rules still apply. You cannot have other service boundaries querying your event store directly.
Data Distribution
Events are often used as a way to distribute data to other services. This is called Event-Carried State Transfer, as the event payload contains entity-related data. While this can have utility, I’m often very concerned about distributing data.
Why do you need data from another service boundary? Most often, the answer is because of query or UI Composition purposes. If that’s the case, check out my post The Challenge of Microservices: UI Composition
If you need data from another service boundary to perform a command/operation, then realize you’re working with stale data if you have a local cache, and you will not have any consistency.
Why would we want a local cache to begin with? The route most people take to land here is they first start with publishing events to notify other service boundaries that some entity state has changed. Other service boundaries (consumers) then process these events by then making a synchronous RPC call from the publisher to get all the current data related to the entity that changed.
Because this callback to the publisher can have a lot of implications, such as latency, increased traffic, and availability, the next logical step is then to include the data in the event itself, so no callback to the publisher is required. This is why this is termed Event-Carried State Transfer.
You may have noticed that I used “Entity” a few times. This is because these types of events are often more entity-centric. As an example, they might be ProductChanged or ProductPriceChanged.

This is often caused by the service itself being CRUD-driven and not task-based. If you are consuming these CURD/Entity type events, you do not really know why something changed, just that data changed related to an entity. If you consume a ProdcutUpdated event, why was it updated? Was there a price increase? You would need to infer the reason for the change without any certainty.
Check out my post Event Carried State Transfer: Keep a local cache! for more on where this is applicable and where you should avoid it.
Notifications
Events used for notifications within EDA are generally more explicit. They notify other service boundaries (or your own) that a business event has occurred. Events as notifications generally do not contain much data other than identifiers. They are used in Event Choreography or Orchestration to execute long-running business processes or workflows.
These are the types of events that relate to business concepts and are often driven by a tasked based UI—as an example, ProductPriceIncreased, ProductDiscontinued, or FlashSaleScheduled. By looking at these event names, you can tell explicitly what they are and what occurred. ProductChanged does not. These events explicitly define what has occurred and why, as they are directly related to the business capabilities your system provides.
Events used as notification can come in a couple of forms. Domain Events and Integration Events. Personally, I rather term these as Inside Events or Outside Events.
Inside Events (Domain) are within your service boundary. Outside Events (Integration) are for other service boundaries to consume. Why the distinction? Because inside events are internal implementation details about how you may communicate within a boundary. They can be versioned much differently than outside (integration) events. Once you publish an event for other service boundaries to consume, and they rely on that event and its schema, you have to deal with versioning. With inside events, your versioning strategy is much different as you control the consumers. Outside events (integration), you may have little control over the consumers.
EDA Tooling

Depending on what you’re using events for in EDA will determine what type of tooling you need. Are you event sourcing? Then you’ll want to use a database such as Event Store based around event streams that include optimistic concurrency, subscription models for projections, and more.
Are you using events as Notifications for workflows and long-running business processes? You likely want to use a queue-based broker like RabbitMQ and a messaging library like NServiceBus that facilitates many messaging patterns used when using events as notifications.
Are you using events to distribute data? For this purpose, you might want to look at event streaming platforms like Kafka.
While some tools claim they can provide all the functionality outlined here, sometimes it’s a forced issue to try and mimic the functionality—square peg, round hole type of situation.
All these different utilities for events are not an either-or. You could be using Event Sourcing without anything else. You could be using Events as notifications without Event Sourcing. You could be doing both. They all have different purposes, and understanding that help will help you so you aren’t going to shoot yourself in the foot by conflating different concepts.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.