Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Want strategies for scaling a monolith application? You have many options if you have a monolith that you need to scale. If you’re thinking of moving microservices specifically for scaling, hang on. Here are a few things you can do to make your existing monolith scale. You’d be surprised how far you can take this.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Scaling Up
When referring to scaling, we’re talking about being able to do more work in a given period. For example, process more requests per second.
The most common approach to scaling is scaling up by increasing the resources related to our system. For simplicity’s sake, let’s say we have two aspects to our system that are physically independent, our application (compute) and database (data storage).
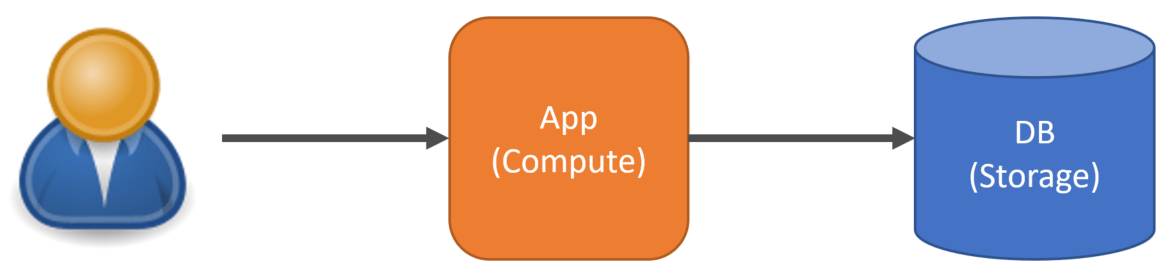
Depending on where the bottleneck is, we could scale up by increasing the resources, CPU, and Memory on our app compute.
However, with any bottleneck, once we alleviate it, we may affect downstream resources, in this case our Database. If we can now handle more requests in our App, we might be now overwhelming our database, in which case we would need to scale it up as well.
All of this depends on the context of your system. Maybe it’s CPU intensive, and you need to scale up your App and your database will be fine with fewer resources. Maybe you’re more database driven and it is what needs to be scaled up. It really depends on the type of system you have and where its needs are.
Scaling Out
Another common approach is often to scale out by adding more instances of your App in front of a load balancer. Typically you’d call out your app compute because scaling your our your database is typically more difficult depending on which type of database you’re using.
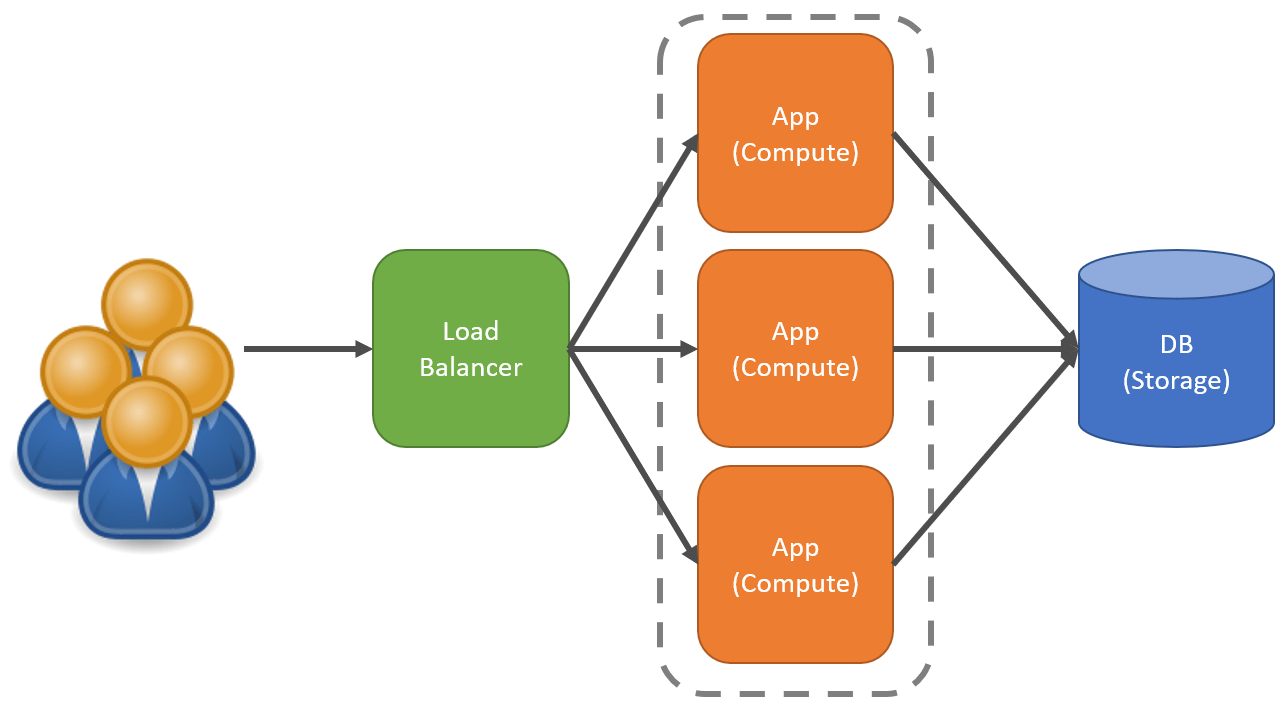
This means you have multiple instances of the same app running, and the load balancer, typically via round robbin will distribute incoming requests to different instances. While this helps to scale, it also helps availability.
Another aspect of scaling out that isn’t mentioned as much, related to availability, is directly specific traffic to specific instances of your app.
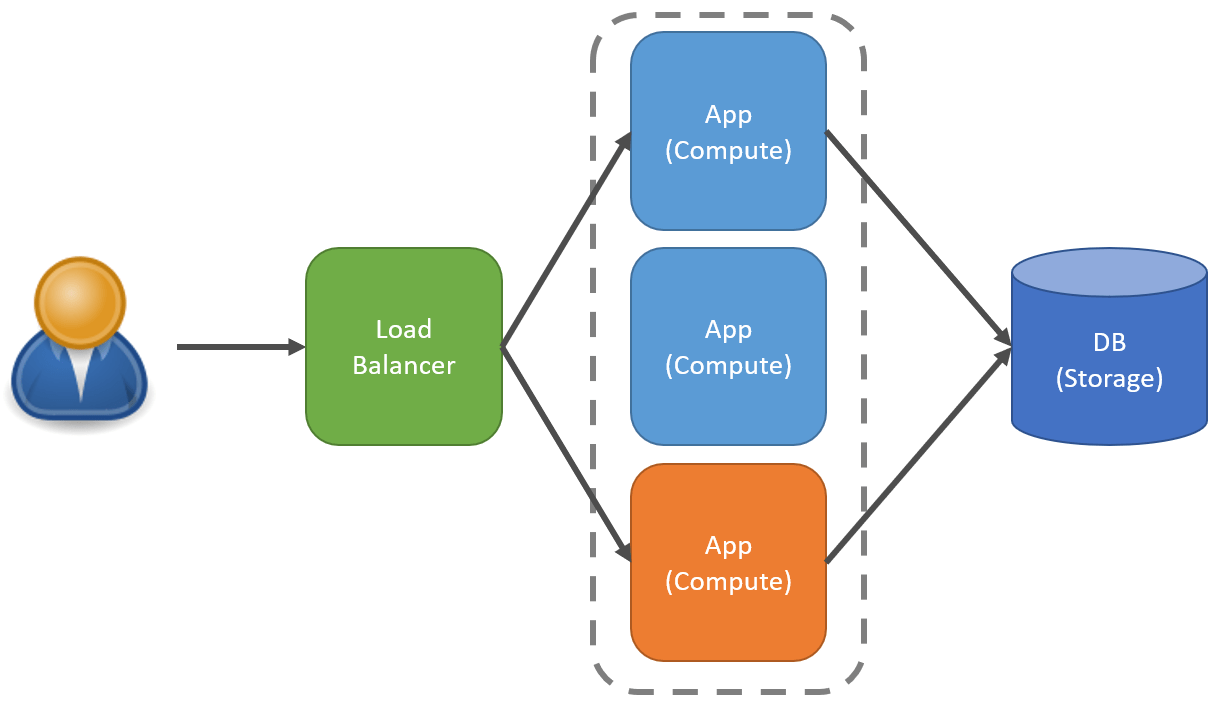
You may choose to have different resources (CPU & memory) for different app segments. In the diagram above, the top two instances of the app may handle specific inbound requests defined by rules within the load balancer. Those instances may have CPU & Memory requirements than the instance at the bottom that handles a different set of requests.
Queues
Often when we need to do more work, that doesn’t mean it needs to be done immediately as the request comes in. Often time we can perform the work asynchronously. A good method for doing this is leveraging queues. There are probably many places you can find within an existing system where you can move the work asynchronously and out of process using a queue.
When an inbound request comes in, we can then place a message on our queue and return back to the client. The message enqueued would contain all the relevant information fro the initial request.
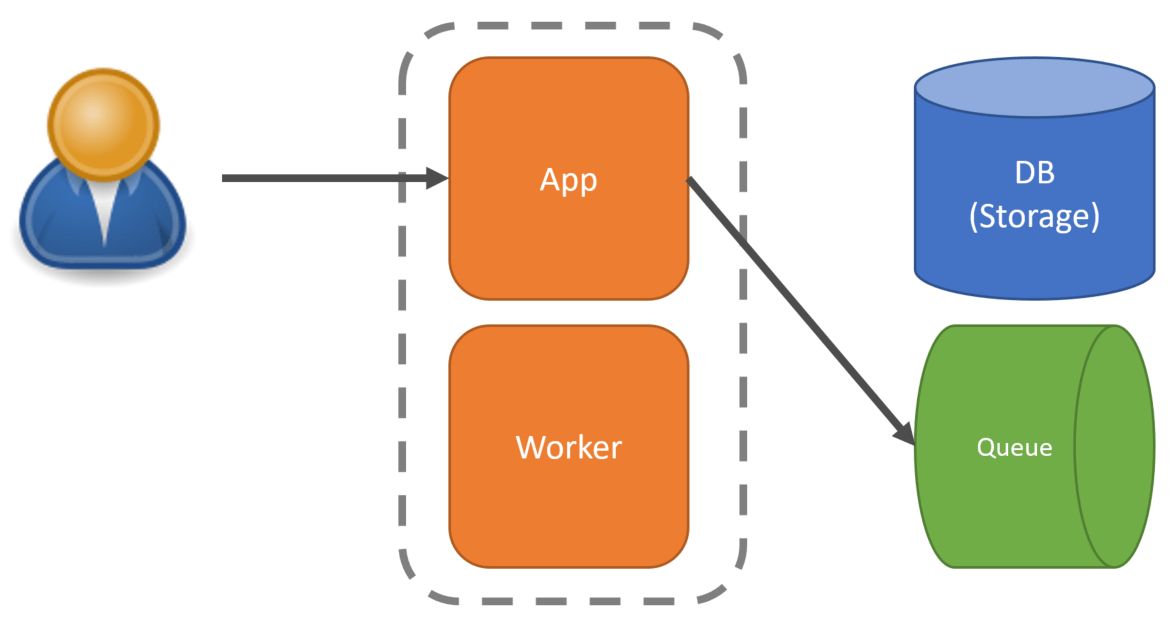
Asynchronously we can have the same process, or a separate process then pull that message from the queue and perform the work based on the contents of the message.
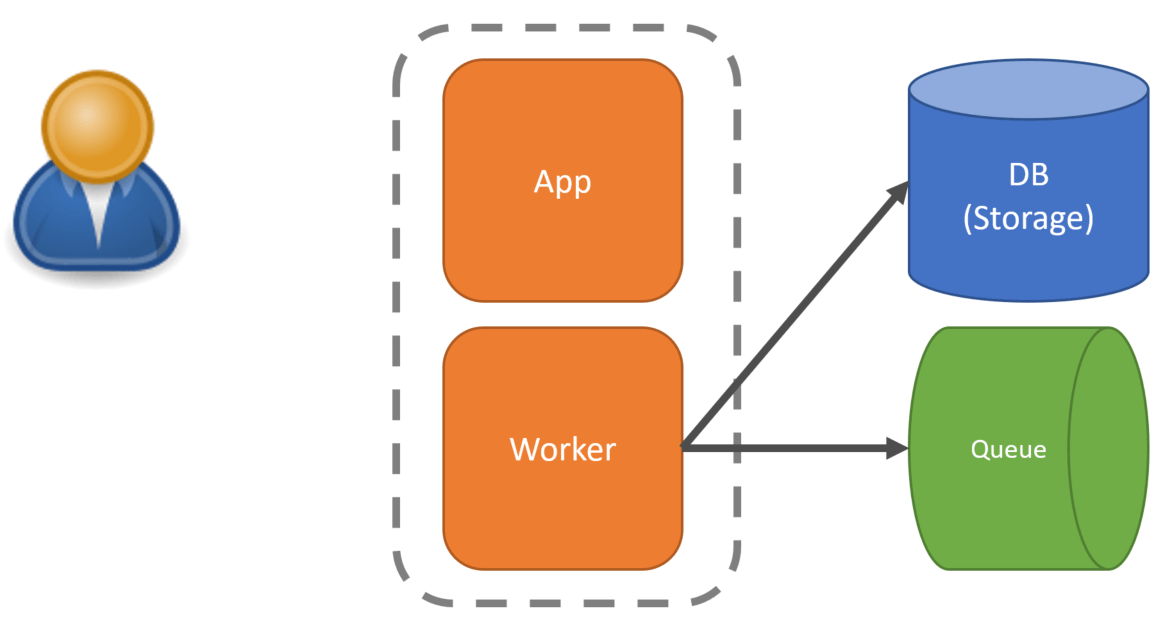
A really common example of this is anywhere you might generate and send an email in your system. Instead of sending the email when some action occurred, enqueue a message and do it asynchronously. You can return back to the client the initial request without having the email also be sent in that same request most often. It can be done asynchronously.
Read Replica
Depending on the type of database you use, scaling may be more difficult. A common approach is to add read replicas that you can then use to perform queries against. Since most applications perform more reads than they do writes. This allows you to scale out your reads to your database by introducing read replicas.
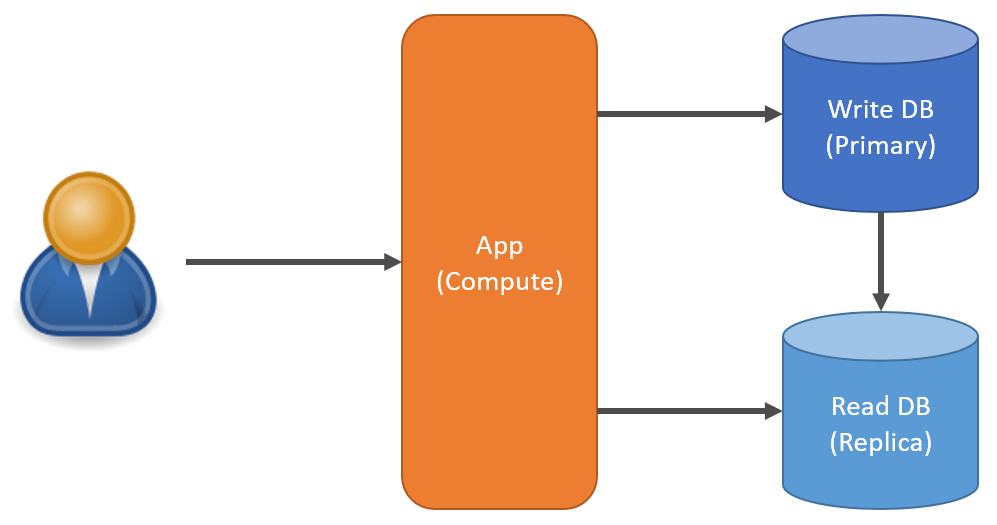
Often times read replicas can be eventually consistent and there can be a lag in replicating the data from the primary database to your replicas. In these scenarios, you need to be aware of this and handle it appropriately in code if you expect to read your own write.
Materialized Views
Similar to read replicas is generating separate read models that are specialized specifically for queries. This involves pre-computing values and persisting them to a specialized read model. If you’re familiar with Event Sourcing, this is what you think of Projections as.
Materialized views, since they are pre-computed, allow you to have specialized views specific for queries. As mentioned, since most systems are more read-intensive than they are write-intensive, this allows you to optimize complex data composition ahead of time rather than doing it at the runtime of a query.
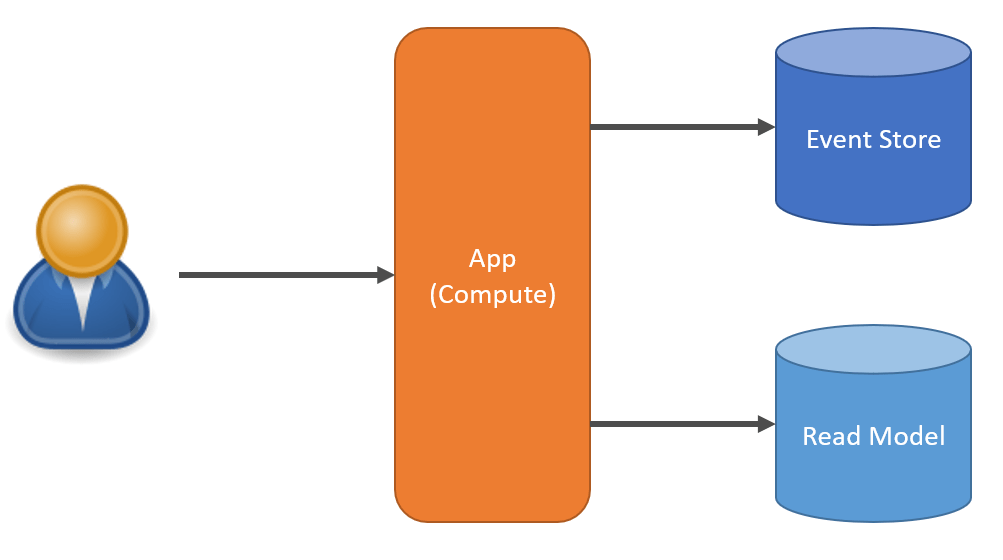
Caching
First, caching isn’t easy. Check out my post The Complexity of Caching, before you go down this path. Caching is useful in reducing the load from your read replicas or primary database from those pesky queries that I keep mentioning. Similar to materialized views, you can choose to cache values that are pre-computed or in a shape that are more appropriate in a given context for a query.
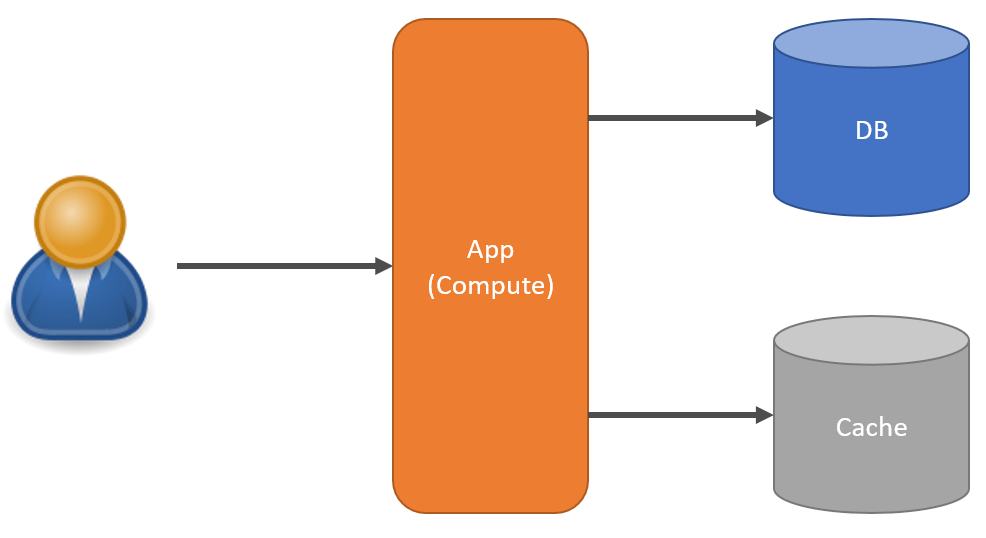
Multi-Tenant
If you have a multi-tenant SaaS application, data can be siloed into its own databases per tenant. Compute can be pooled or siloed in the same way. Or you can do both and create lanes for tentats that have their own dedicated compute and databases. There are many different options to consider. Check out my post Multi-tenant Architecture for SaaS.
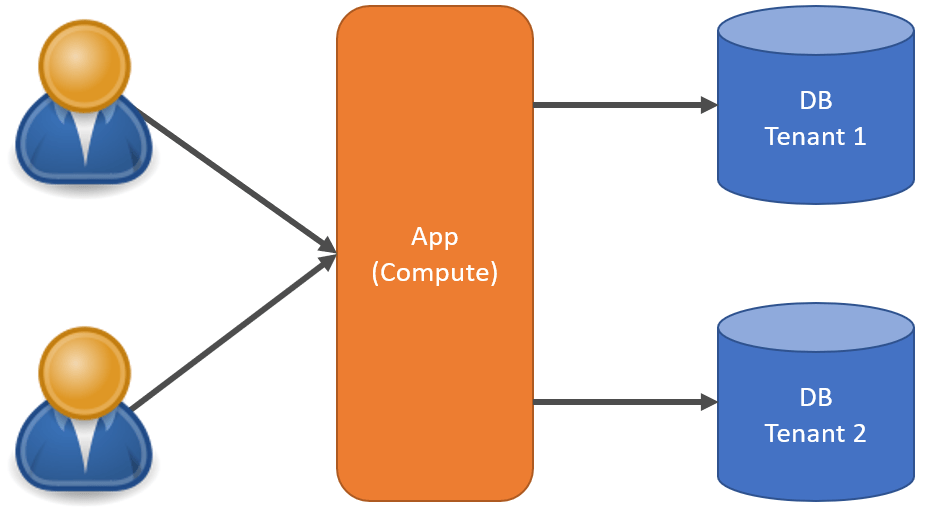
Mix & Match
You have a lot of options when it comes to scaling a monolith. It’s not just about scaling up, you can also scale out differently from your compute and underlying database. Moving work and process out of process using a queue and creating materialized views or caching along with using read-replicas. Depending on your context you may choose to employ different techniques or possibly all of them depending on the size of your system.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.