Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
When building Software as a Service (SaaS) you’ll often need to use a Multi-tenant Architecture. There are many different ways that you can segregate compute and data storage in a multi-tenant architecture. Data storage can be in a silo or partitioned. Compute can be pooled or siloed. And both together you can create lanes for groups of tenants. In this architecture, having the identity of each request is critical in being able to route a request all the way through to the right services and resources.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything that is in this post.
Single-tenant Architecture
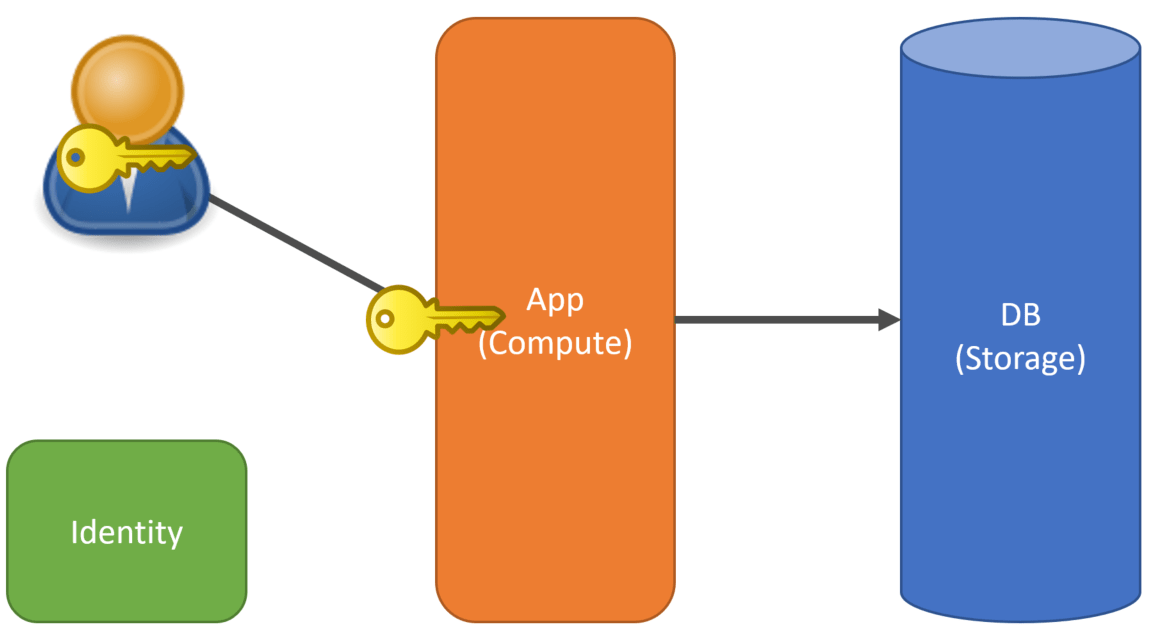
First, let’s talk about single-tenant architecture. This doesn’t mean it’s not a multi-user environment, just that all users belong to the same tenant or organization.
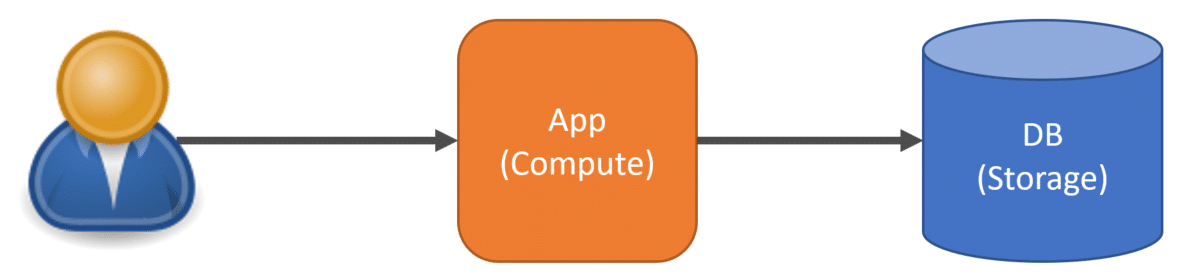
The App (Compute) refers to the compute to run your application. This could be load balanced or running as multiple instances on multiple nodes. The DB (Storage) is your database and any other infrastructure dependencies such as caches, etc.
With this type of topology, if you need to move to a multi-tenant architecture, the most common option is to replicate the compute and storage for every new tenant.
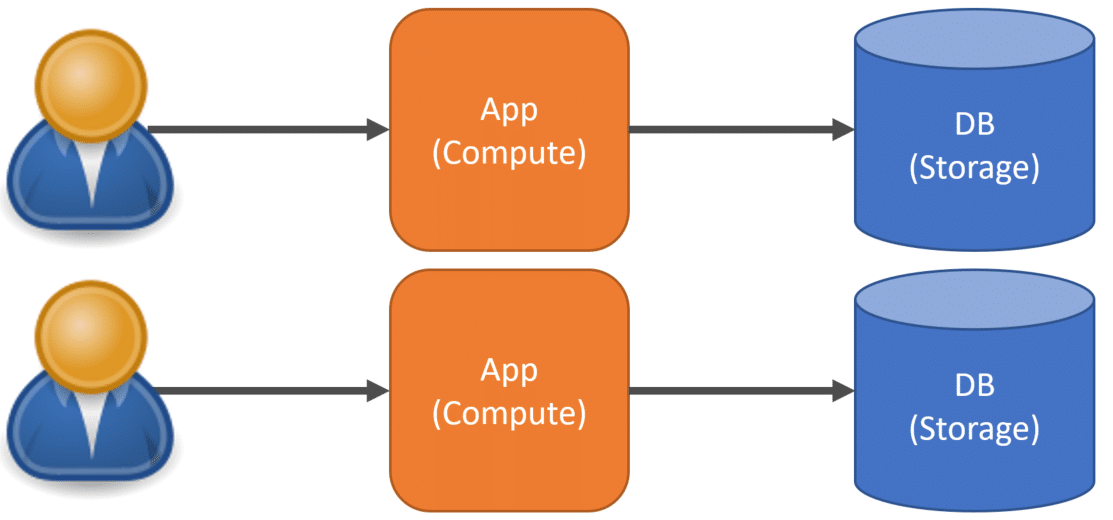
This means each tenant has its own compute and own storage.
The advantages are that each tenant is completely siloed. They share nothing. There is no concern for data being exposed to the wrong tenant. Each tenant can be scaled independently. There are no “noisy neighbors”, meaning one tenant can’t hog or over-consuming compute resources affecting other tenants.
The disadvantages are managing more infrastructure, which includes deploying the application and related changes storage. The cost of potentially having more compute and storage than are required by a tenant. If a tenant is barely using the application and only consuming 5% of the compute, you’re just wasting resources and still having to pay the cost of those resources.
Multi-tenant Architecture
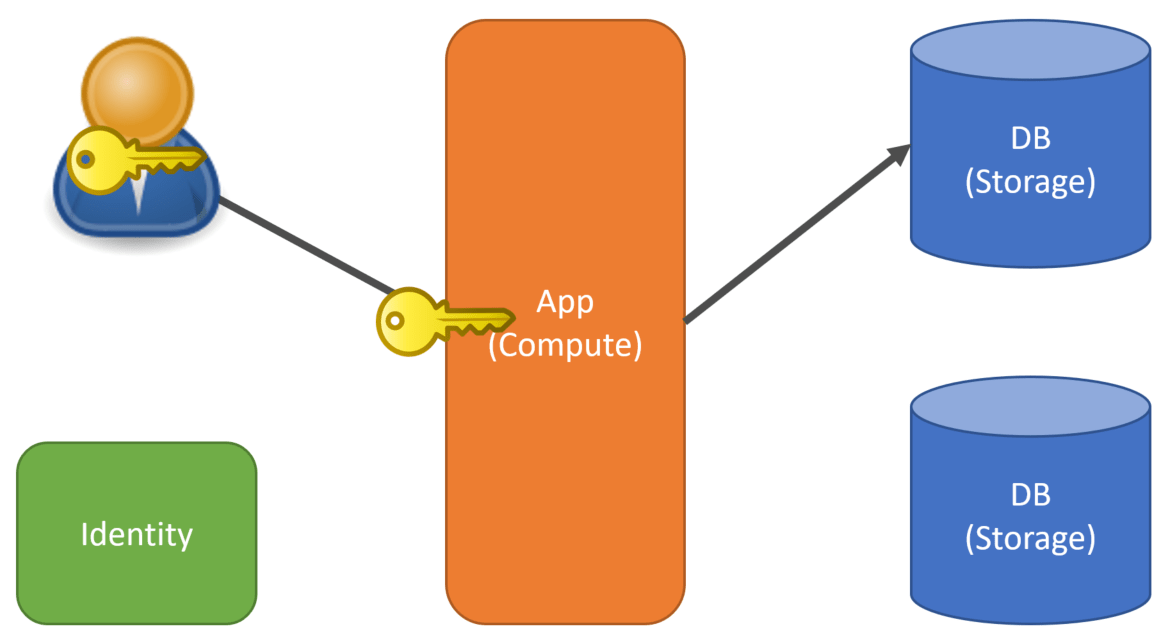
The next logical step for most is to share compute but keep storage separate. This allows you to silo data to prevent exposing data to the wrong tenant but sharing compute resources.
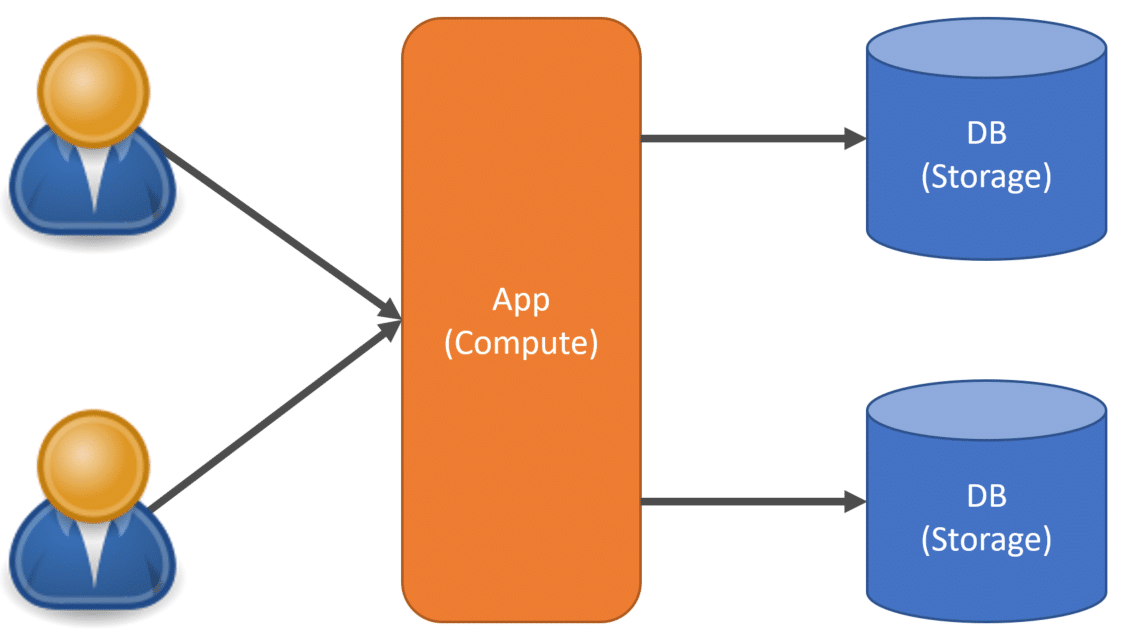
This allows you to maximize the compute usage and scale when necessary but keeps data separate. In order to achieve this, your application must now be aware of the tenant making the request o the application so you can route to the correct database/storage.
Another option is sharing compute and storage.
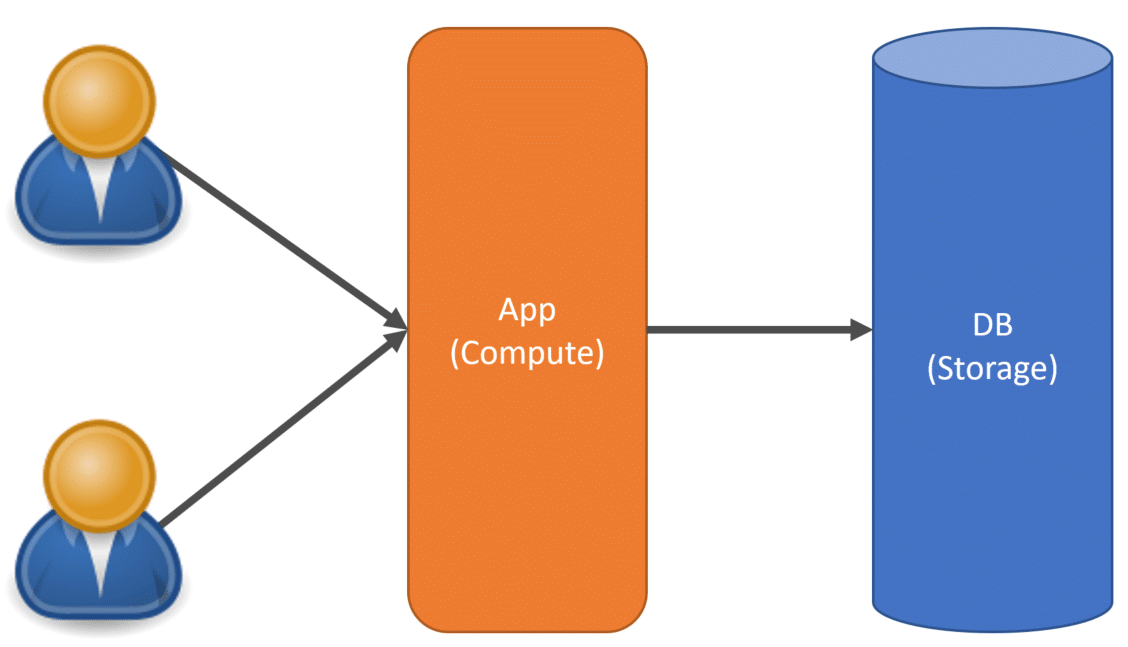
In this situation, the usage of compute and your storage is maximized. However, this means that data is no longer siloed. This means you must use a partition key in your schema tables or documents to indicate which tenant the data belongs to. In a relational database, this means adding a TenantId to your tables.

In the example above, the first and third rows belong to Tenant1. When performing any queries to the database you must be filtering by the TenantId.
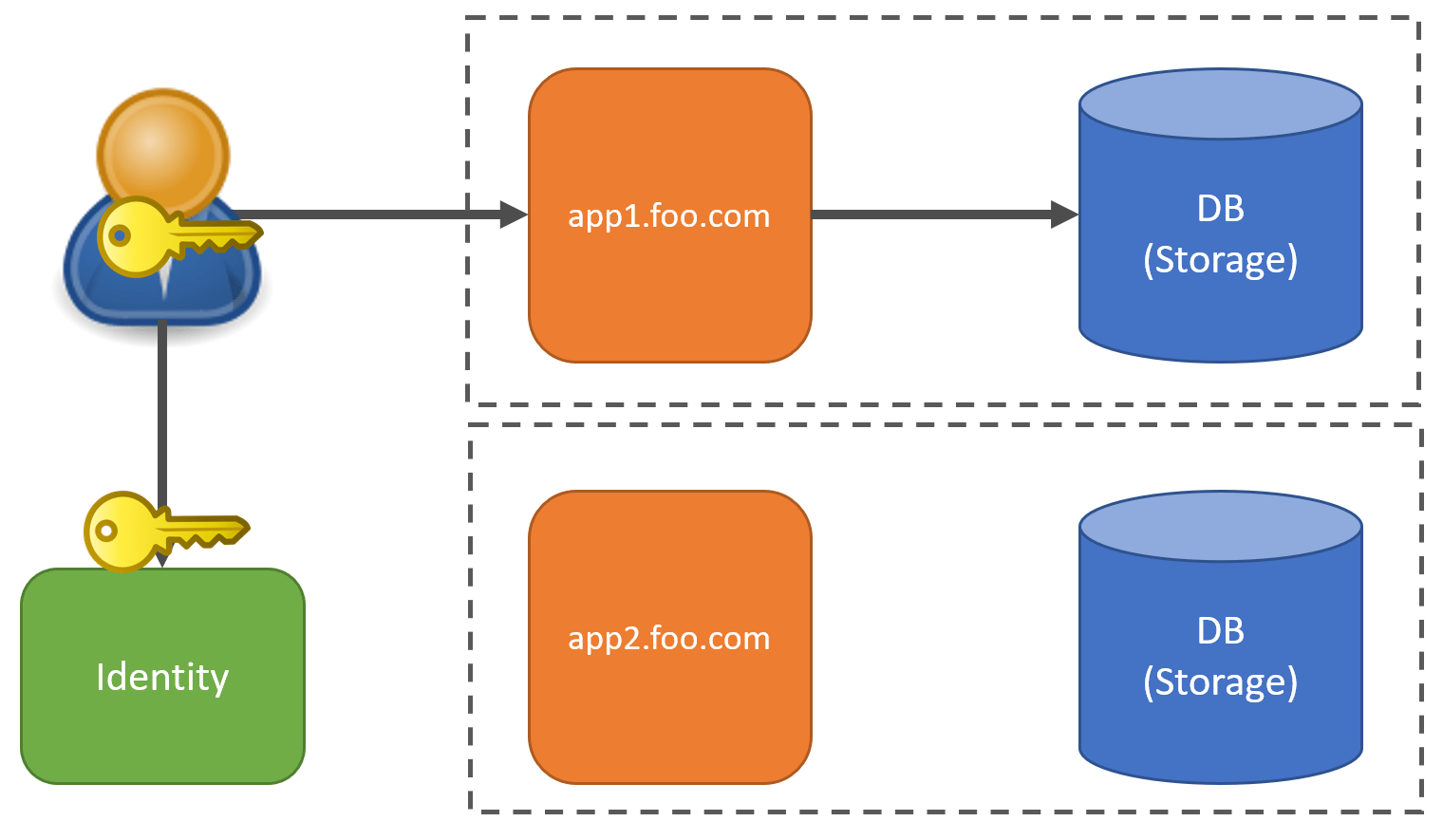
Identity
If you’re sharing compute or storage and using a partition key, you must be aware of who is making the request to your application so you can route to either the correct database or use the partition key. Identity is important to manage this.
When you have a user login to your application through whatever means, the token it returns to the client/user must contain some identifier of the Tenant that user belongs to.

Then any requests made to the application will pass that token containing the TenantId. This can then be used in any queries to make sure it’s filtering and selecting the data for that tenant.
If the database was siloed then it would also use the TenantId in the token to determine which schema or database instance to use.
As an example of what that looks like using Entity Framework Core is u can use the HasQueryFilter when building the model to have the DbContext automatically add the filter on every query.
There are many different ways and techniques to do this so that when writing your application code, you don’t have to think much about having to write the actual filter. You don’t want to have to think about writing this logic at all. I recommend it being at a higher level or abstracted so when you’re writing application code, you feel like you are in a single-tenant architecture and not a multi-tenant architecture.
Hypermedia
Another option is using Hypermedia. If you’re developing an HTTP API then when your client app authenticates with the Identity service, it will also specify the host with which you’re interacting. Meaning it will tell the client at runtime which hosts it will be making the HTTP Requests to.
With hypermedia, you’re not building URIs but rather the server is providing them to you in responses. If you want more details on leveraging hypermedia check out my post on building Smarter Single Page Application with a REST API
If you’re developing a web app that’s server-side rendered, the same is applicable by redirecting the user to the correct host after login.
What this provides are different “lanes”. There can be many tenants that belong to a lane. Each lane has its own compute and storage. This is really like a mix and match of everything else described in this post.
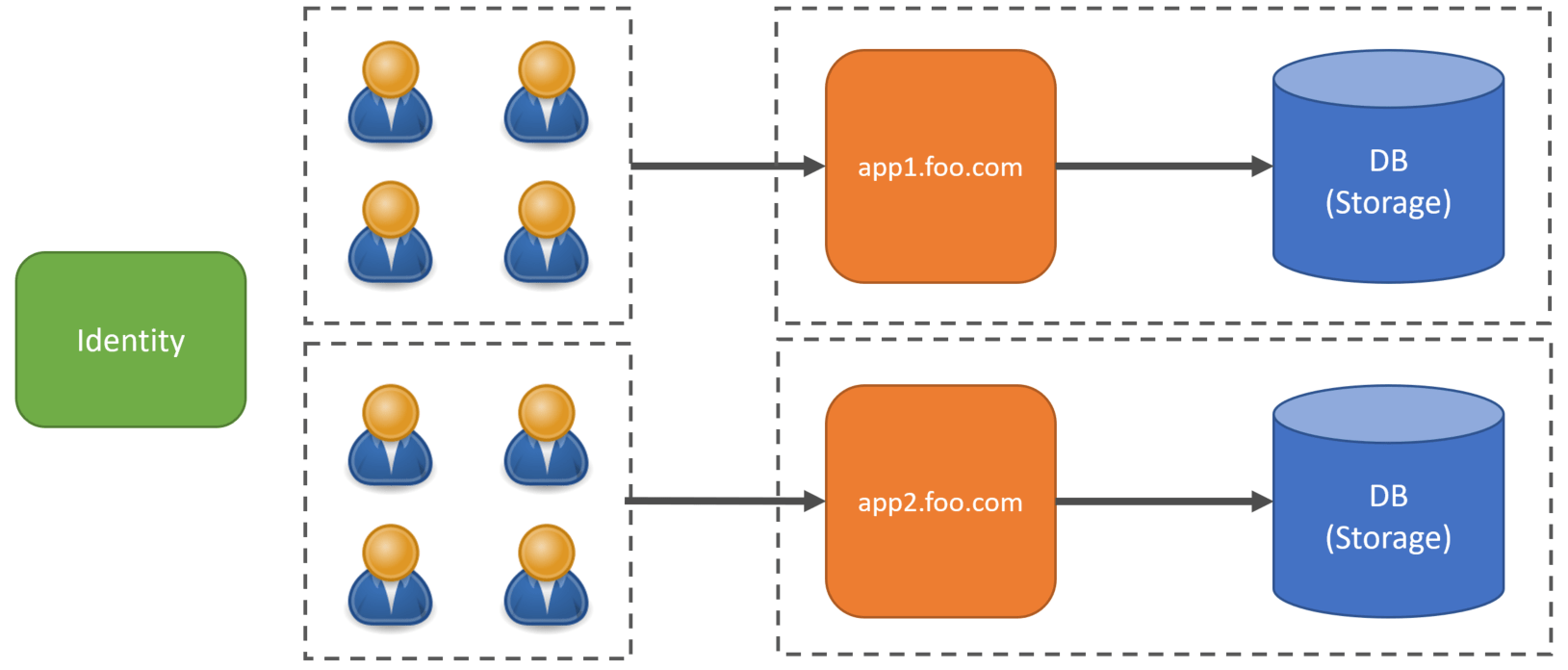
Lanes allow you some flexibility in how you deploy. You can deploy updates to a single lane as a canary deployment. You can deploy to a single lane, verify the changes are working correctly and everything is stable, and if so, deploy to more lanes.
Options
Hopefully, this illustrated that there are many ways to implement a multi-tenant architecture. You can fully silo and have a tenant have their own compute and storage. Tenants can share compute but still have siloed storage, or you can share both compute and storage with a partition key. With all these options, you can segregate further by adding lanes.
Source Code
Developer-level members of my CodeOpinion YouTube channel get access to the full source for any working demo application that I post on my blog or YouTube. Check out the membership for more info.