Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Are you using REST APIs for a Microservices architecture? If you’re using REST, HTTP APIs, gRPC, or any other Request/Response model as the primary way to communicate between microservices, you’re going to need to deal with possibly hard to debug latency issues and address availability concerns.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything that is in this post.
In-Process Single Transaction
First, let’s take a step back and talk about a monolith. When in a monolith, you’d typically have a single process communicating with your database. If you’re using an ACID-compliant database, then you’d be using transactions to make all database statements atomic.

In the example above, our monolith has some clear boundaries of Sales, Catalog, Billing, and Warehouse. If an order is placed, which is started in sales, all three of these boundaries might be involved in that business process. Billing will have to create an Invoice and the Warehouse will have to allocate the products to ship. That entire business process would be encapsulated in one transaction. If anything goes wrong through that process, the transaction will rollback. We don’t have to worry about data consistency because we have the safety net of the atomic transaction.
Distributed Transaction
When you move out of a single process and into a distributed system, you’re going to lose that single database connection and transaction.
If you’re developing a microservices architecture with REST APIs, then what happens to your single transaction?
In the same scenario as above, when placing an order, there are multiple services that are required as apart of this long-running process.
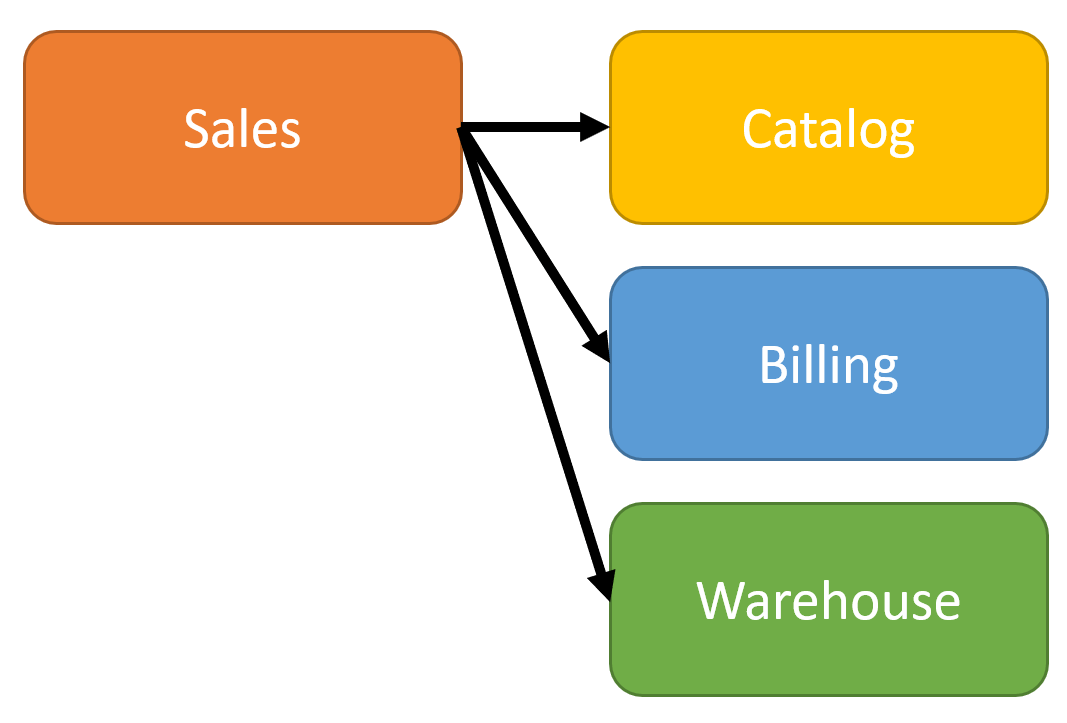
If all the interactions from Sales to Billing and Warehouse are done over a REST HTTP API (or any synchronous request/response), then all the dependent services must be available in order to place an order.

If an order was placed, then Sales called Billing to create an Invoice and it succeeded. Then it calls the Warehouse to allocate products for shipping. If that request to the Warehouse fails, for whatever reason, then we have to manually perform some “undo” or compensating action to try and revert out changes along the way. This means you must make a call back to Billing to cancel the invoice.
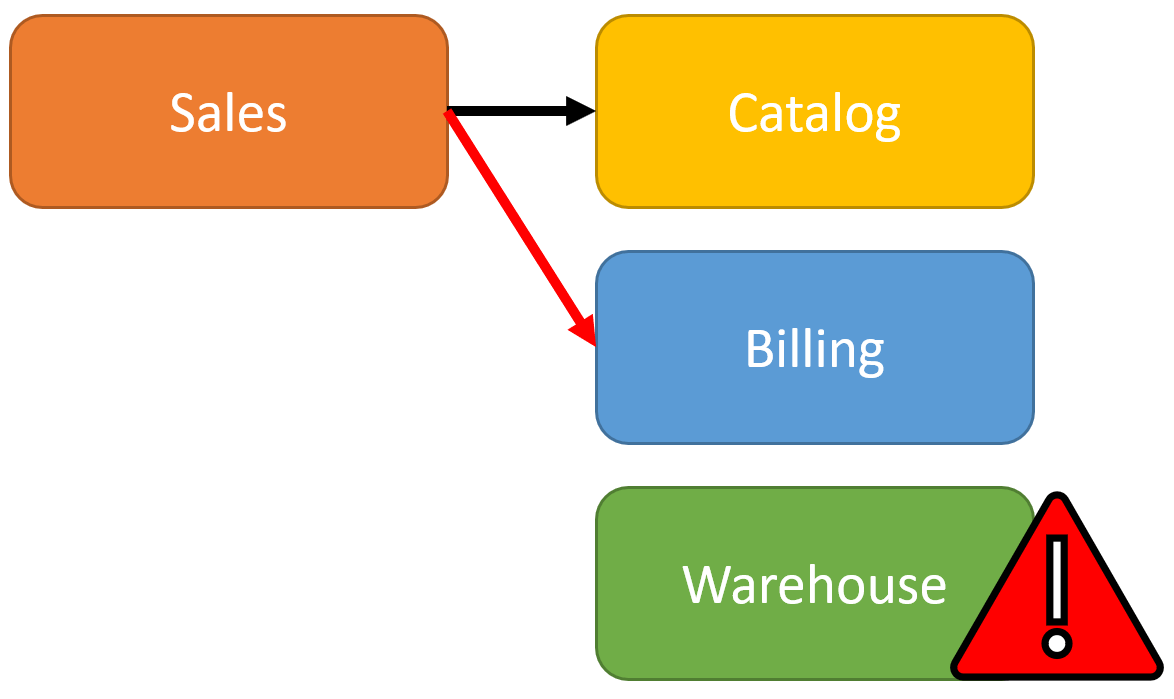
But what happens if the request to cancel the Invoice in Billing fails? Now you’ve created an order, that has an invoice, has no allocated products.
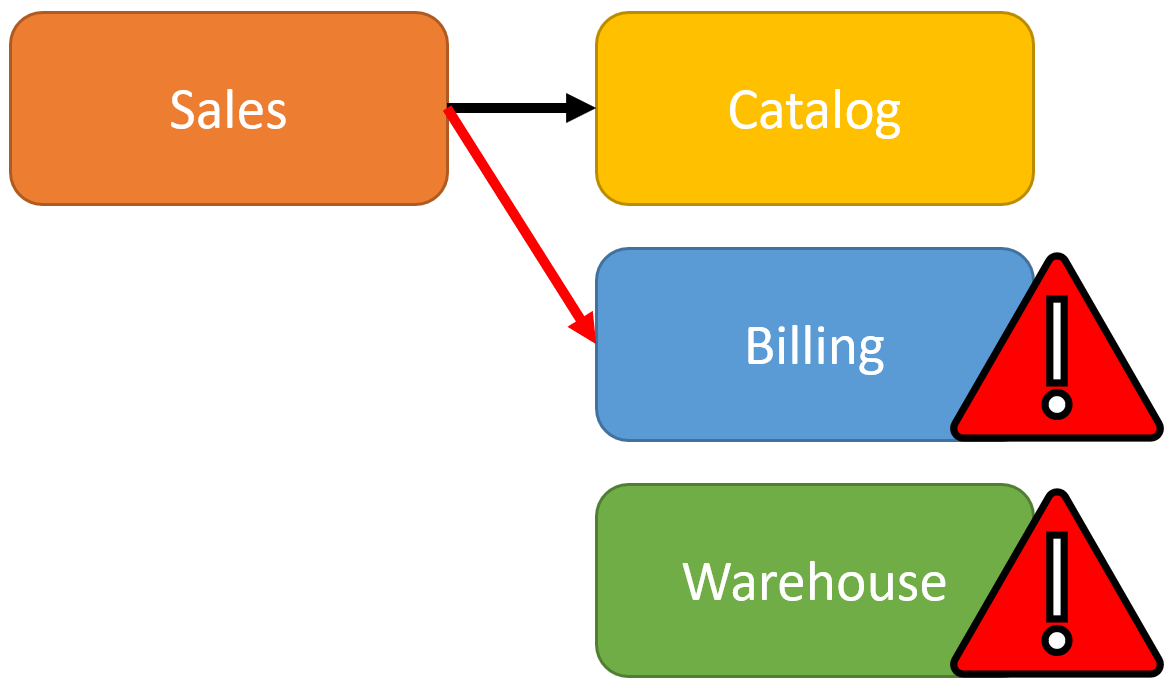
Since there is no single transaction, you need a distributed transaction (or a two-phase commit). One way to solve this is what a transaction coordinator. But this means that all services must be using compatible technologies for databases. The likely hood of this is not high if you haven’t planned this initially.
The solution to this is through Event orchestration or choreography. But hang on, before that, there are more issues to discuss.
Latency
When making a network hop, you’re going to add latency. The issue is, if you’re inside one service, making an HTTP call to another service, that’s where the visibility ends. You are unaware of what the internals are of the other service is that you’re calling. What happens when the service you’re calling, has to call another service? And so on!?
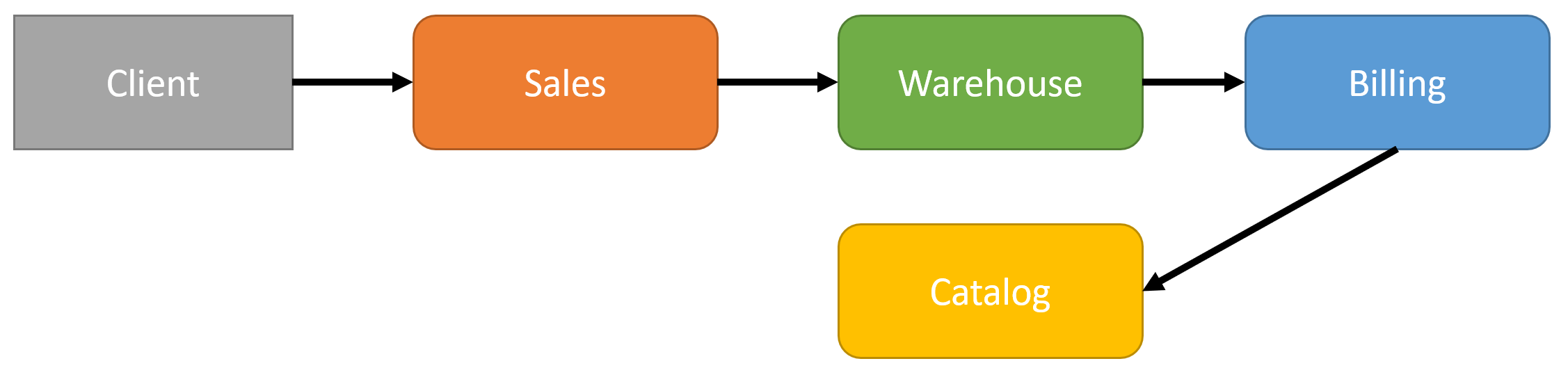
In the example above, there is a network call chain from service to service. If each service takes (on a happy path) 200ms to respond to the other service, in my example above, it would take a total of 800ms roundtrip to the client.
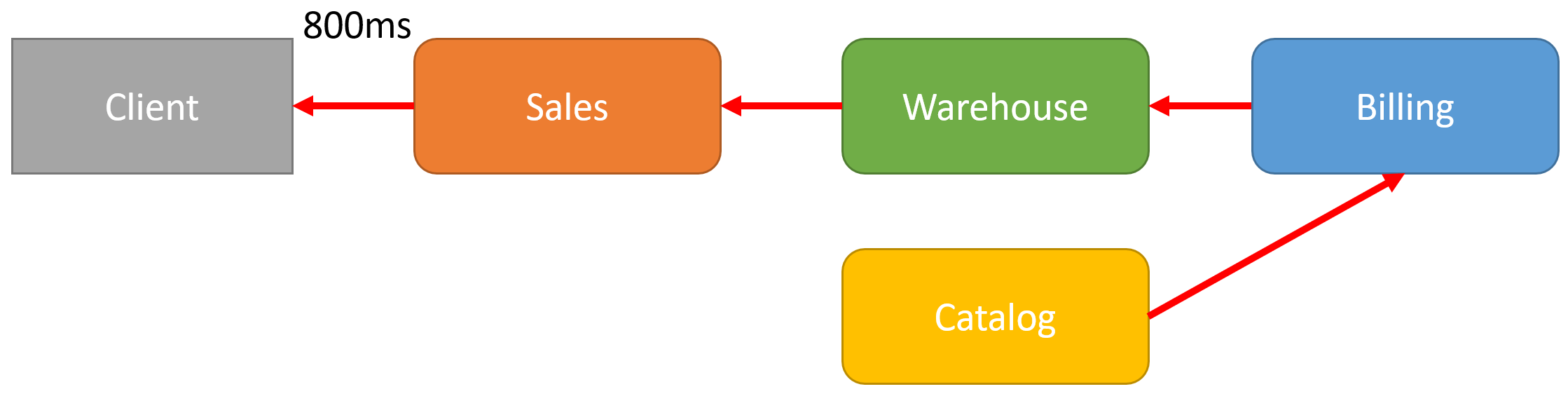
The above is a best-case scenario. But because there’s so much coupling, that can’t directly be seen, latency can skyrocket if availability issues arise anywhere in the call chain.
What happens if the catalog is having performance issues and isn’t responding at 200ms, but at 700ms?
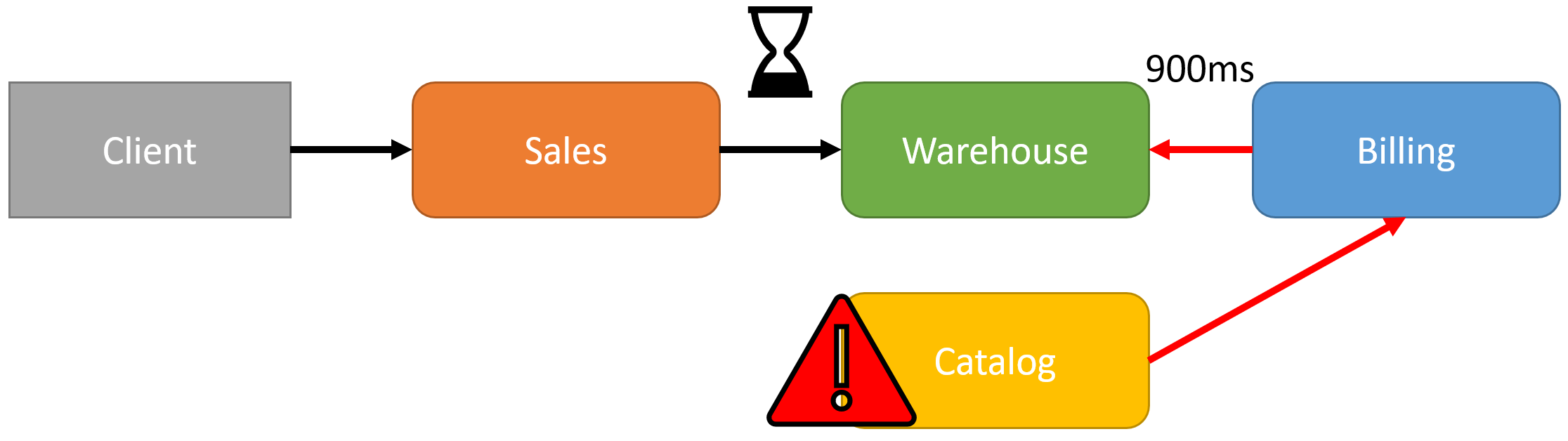
From our client, this is now going to take 1.3s. All because of downstream issues that are going to be very difficult to identify. From the perspective of Sales, it’s getting a slow response from the Warehouse. But the warehouse is getting a slow response from Billing. Who’s fault is it? Clearly, in my diagram, it’s the Catalog service, but without clear metrics, this is going to be very difficult to address. Beyond that, every network hop added in any downstream service is going to add latency.
Distributed Ball of Mud
It gets worst. The reality is if a service must make HTTP calls to other services, either for getting data or performing an action, then all the dependent services must be available for it to perform correctly.
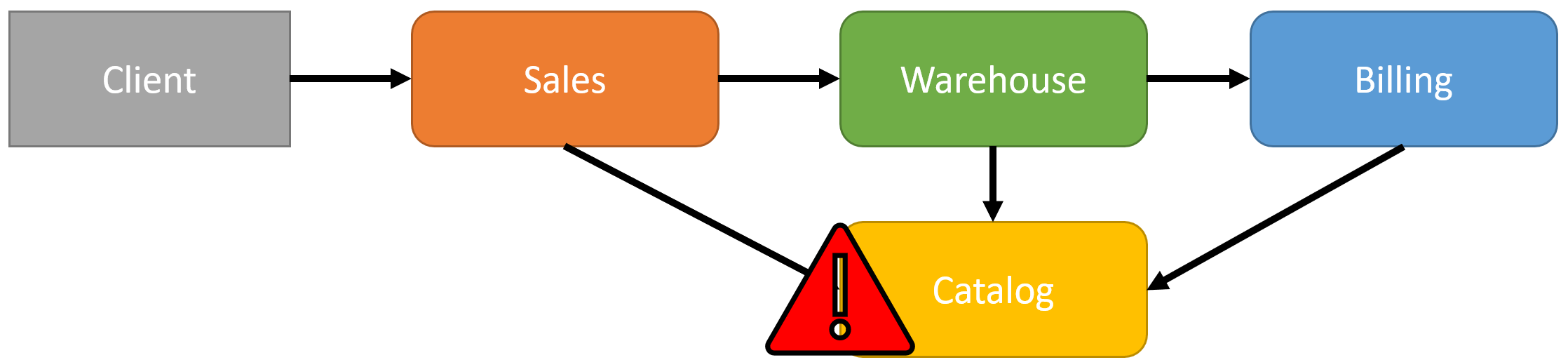
For example, let’s say that Sales, Warehouse, and Billing all require the Catalog Service. If the Catalog service is unavailable or is having performance issues, then not only is it an issue, all the services are going to be failing.
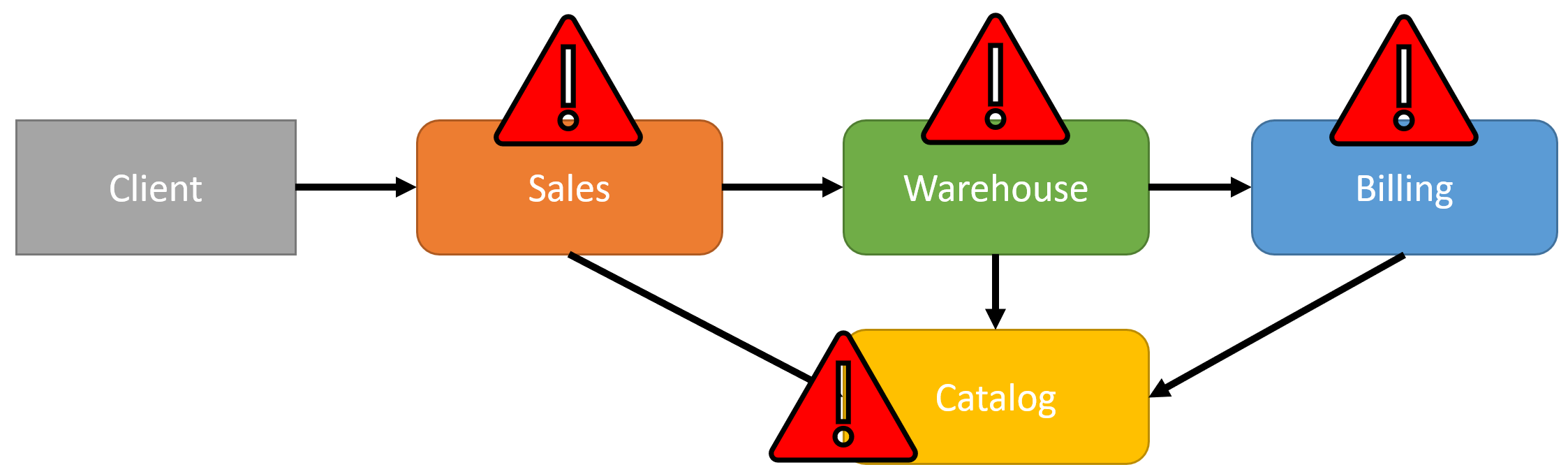
This is a distributed monolith. Services require each other to be available and cannot function without other services.
Boundaries & Asynchronous Messaging
One solution to this distributed monolith is using asynchronous messaging between well defined boundaries.
Services should be autonomous. They shouldn’t depend directly on other services through synchronous interactions. If communication is done asynchronously through messaging, this means a service does not require other services to be available.
In order to make services autonomous, you need to have boundaries defined correctly. This means focusing on the behavior of the services and then the data required for those behaviors.
Once you have well-defined boundaries around capabilities, then you can use asynchronous messaging to define the workflow. Check out my post on Event Choreography and Orchestration to develop long-running business processes between services.
Source Code
Developer-level members of my CodeOpinion YouTube channel get access to the full source for the working demo application available in a git repo. Check out the membership for more info.