Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
If you’re starting a new greenfield project or rearchitecting an existing system, how much effort do you put into the overall architecture and design? What are the types of things you should be considering or thinking of? It’s also really applicable if you have an existing system that you might be trying to decompose or rewrite portions. I will discuss aspects critical to the foundational architecture and design, allowing you to evolve your system over time.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Large System
First, everything I’m referring to in this blog/video relates to large systems that could take years to develop. I’m not referring to a single application that could be rewritten in weeks or months but rather large systems. These large systems usually take years to develop and also evolve over the years.
Anyone that’s worked in a large system knows the pain when it becomes an unmanageable mess. It’s a mess of tight coupling that’s hard to change and easy to introduce bugs because of unknown side effects.
Nobody wants to develop a system that turns into a mess, so the question is, how much effort do you put into the initial overall architecture and design so you don’t develop a mess in the future?
Logical Boundaries

What does your system do? At the heart of it, what problems does it solve? Yes, it provides all kinds of functionality, but what are the core set of capabilities?
Not all functionality is created equal in terms of value. Your system’s core set of capabilities has a higher value than other features that are more for supporting purposes.
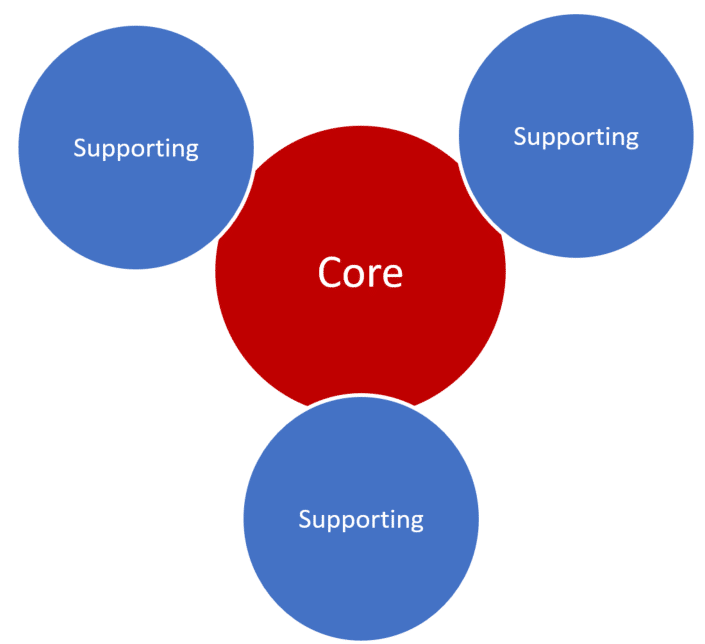
So your large system will have many different parts (logical boundaries). Some of those parts will be the focal point that contains a lot of the value your system provides, while other parts are there to support the core. As an example, food delivery system, the core might be the ordering and delivery process. However, CRM and Accounting might be in a supporting role.
Defining logical boundaries is one of the most important things to do, yet one of the most challenging to get “right”. This is because over time, your understanding and model might change, and you might realize your boundaries are “incorrect”. This is ok!

One of the reasons defining logical boundaries can be difficult, but is also a way to define them is by language. You’ll often hear about this in Domain Driven Design with the ubiquitous language. Often times you’ll hear the same terms used by different people but they mean different things. As an example, if you were talking about a distribution domain where you buy and sell products, the term “product price” means different things. To someone in sales, the product price is what we charge our customers. To someone in purchasing the product price is what the vendor or manufacture charges us. The concept of a product is different for each of hte people in sales and purchasing. The have different concerns.
Defining logical boundaries means grouping functionality that relates. We often have a free-for-all of coupling because we aren’t making the distinction that a concept can live in more than once place. Meaning if we only have a single instance for manging a “product” that mean that the concerns of sales woudl be mixed with that of purchasing.

Instead, we want to group functionality and split these concepts up and align with the business.
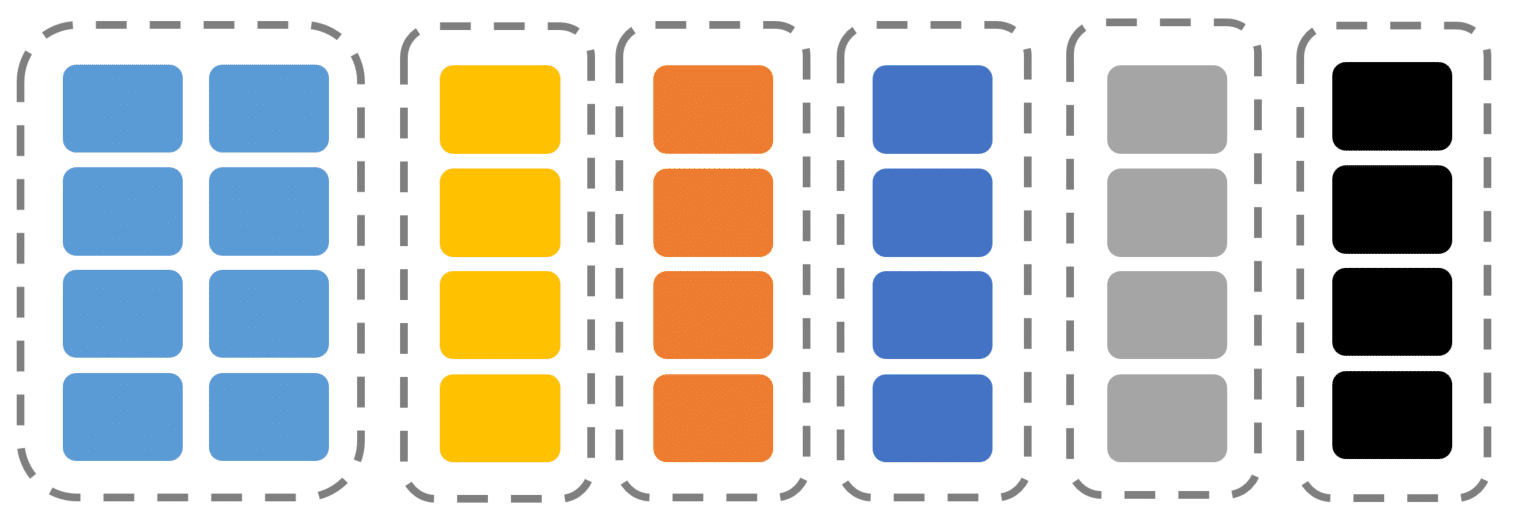
A significant advantage of defining logical boundaries as mentioned earlier is that they don’t all have the same value or the same requirements. This means that one logical boundary in a supporting role might be better suited to CRUD with Document Database. While another logical boundary that’s more the heart of our system is using an Event Store and is more Task Driven. We can define the implementation details per logical boundary based on its needs rather than the entire system.
Coupling
Once logical boundaries are defined, you’ll often need to communicate between them to execute workflows or business processes. Another foundational component to define early on is a message and event-driven architecture.
Asynchronous messaging allows you to decouple your logical boundaries by producing messages and having other services consume those messages.
There are two forms that I often talk about which are commands and events. If you’re unfamiliar, check out my post Commands & Events: What’s the difference?
Commands are used to tell a specific boundary to perform an action. There can be many different senders of a command. Senders send a message to a queue/endpoint where a single consumer will consume and process that message. The senders know which queue/endpoint to send the message to but are unaware of when the message will be processed by the single consumer.
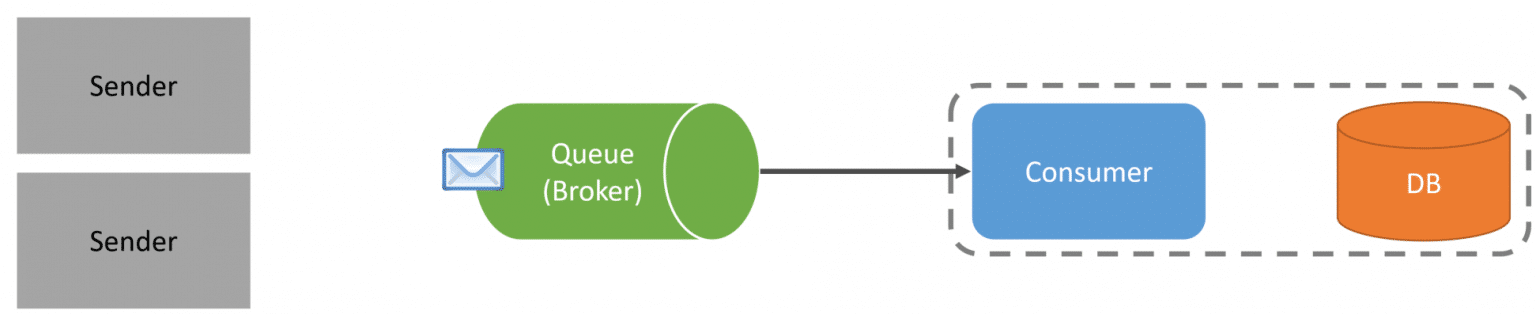
Events are used for the Publish/Subscriber pattern, where a publisher publishes an event on a topic, and there could be many or no consumers. The publisher is totally unaware of how many consumers there are or what they do.

Why does this decoupling matter? Because it allows you to extend your system and embraces the asynchrony of the real world.
For example, let’s say your food delivery system has a new requirement to send a text message to the customer when the delivery driver is approaching your home. The delivery driver’s mobile phone would be sending GPS coordinates to the system as it’s traveling. What are these coordinates? They’re events. DrivePositionUpdated event would contain the latitude/longitude and date/time. We can have this event published to a topic that we can create a brand new consumer for, which would process these events and when applicable, send the text message to our customers to notify them. None of this new functionality is coupled to existing code, it’s entirely new and segregated.
Logical isn’t Physical
Developers love talking and working on scaling a system to handle more traffic or have a higher workload. Absolutely different requirements related to scaling and performance can drive requirements and your architecture. However, there needs to be a distinction between logical boundaries and physical boundaries. They aren’t the same thing. They can be, but they don’t have to be.
If you’re unfamiliar, check out my post on the 4+1 Architectural View Model which is the diagram below.
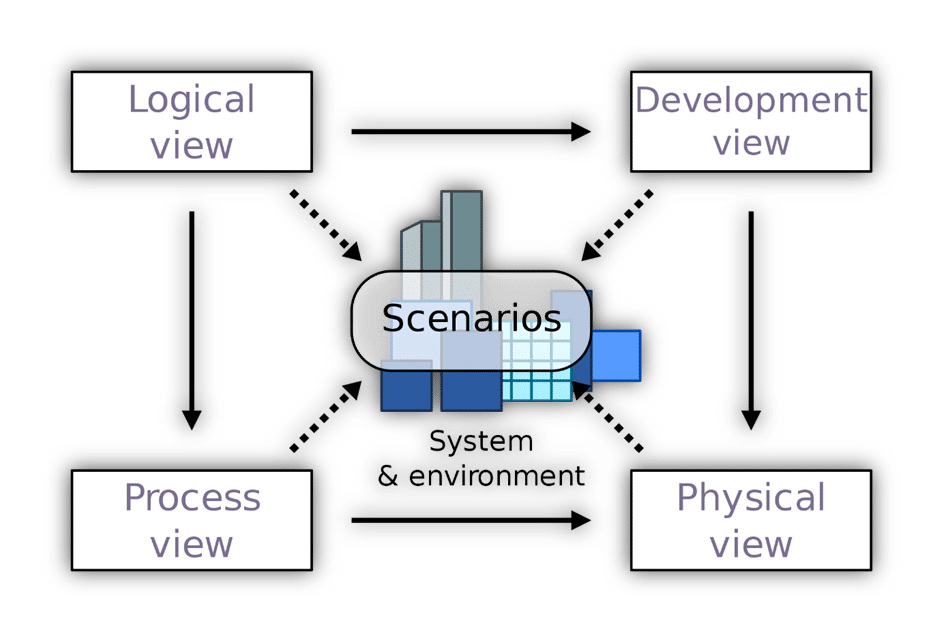
There are different representations of your system. How you define a logical boundary doesn’t mean it needs to be deployed as a single unit.
As an example, here are four logical boundaries. CRM interacts with an external source of Salesforce, Finance interacts with an external source for accounting, Ordering has its relational database, and Delivery uses an Event Store.
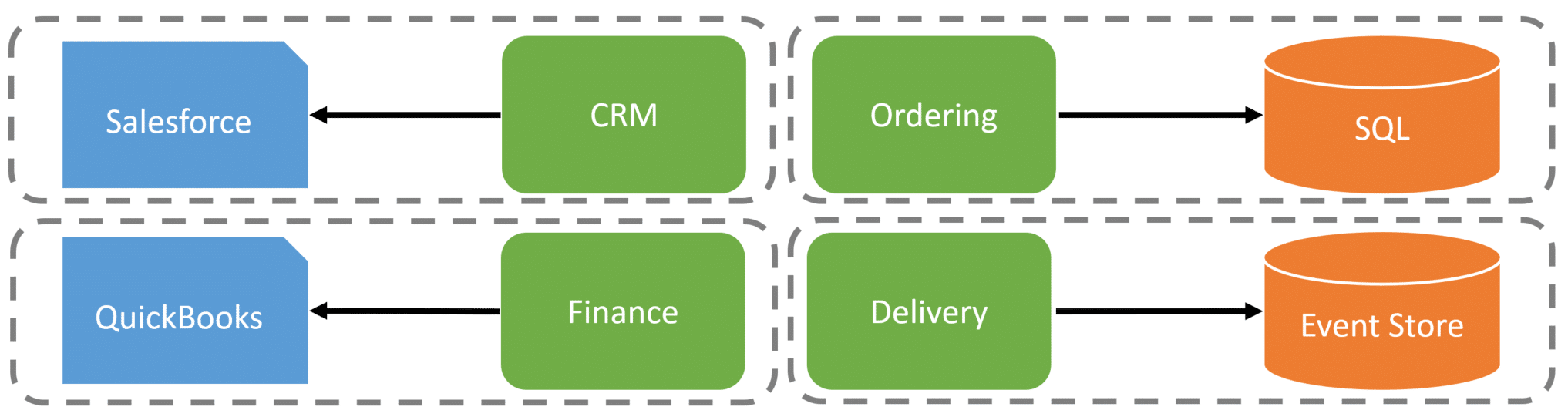
However, all 4 of these logical boundaries could be composed together and deployed as a single process.
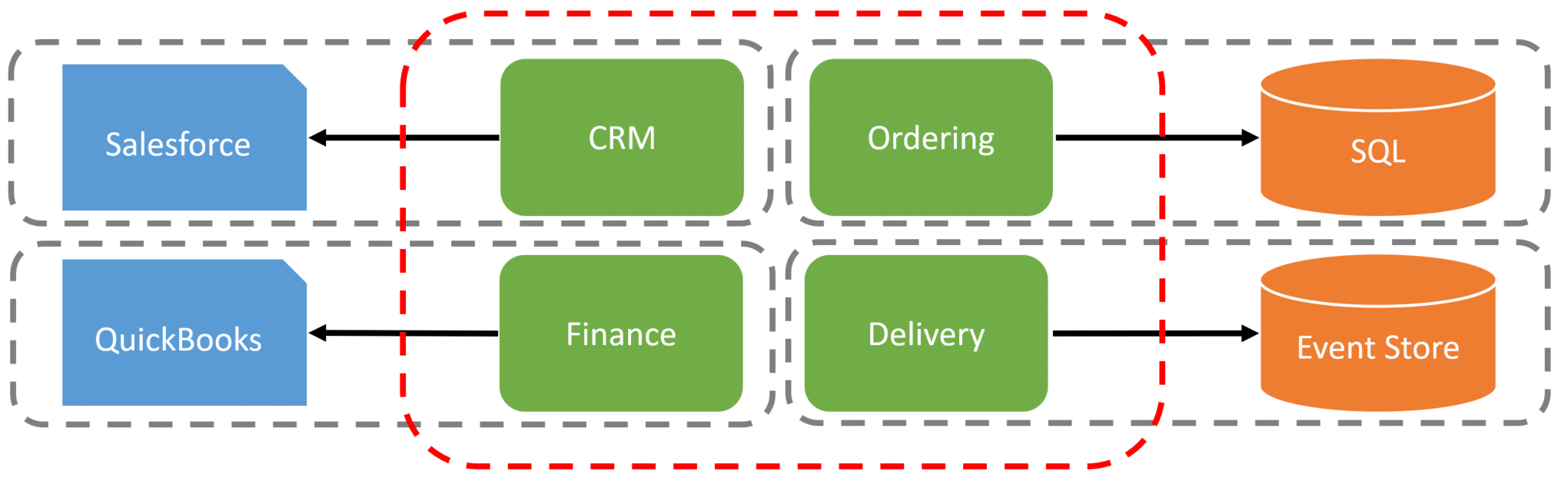
Because logical boundaries aren’t tightly coupled, if any one of them needed to be scaled differently, we could deploy it independently.
Your logical boundaries don’t need to be the same physical boundaries.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.