Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Distributed tracing is great for observing how a request flows through a set of distributed services. However, it can also be used as a band-aid to mask a problem that you shouldn’t have.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Distributed Tracing
So why is distributed tracing helpful? When you’re working within a Monolith, you generally have an entire request processed within the same process. This means if there is a failure of any sort, you can capture the entire stack trace.

When you’re in a large system that is decomposed with a set of distributed services that interact, it can be very difficult to track where the exception is occurring. Also, it can be difficult to know the latency or processing time for the entire request and where the bottleneck might be from service to service calls.
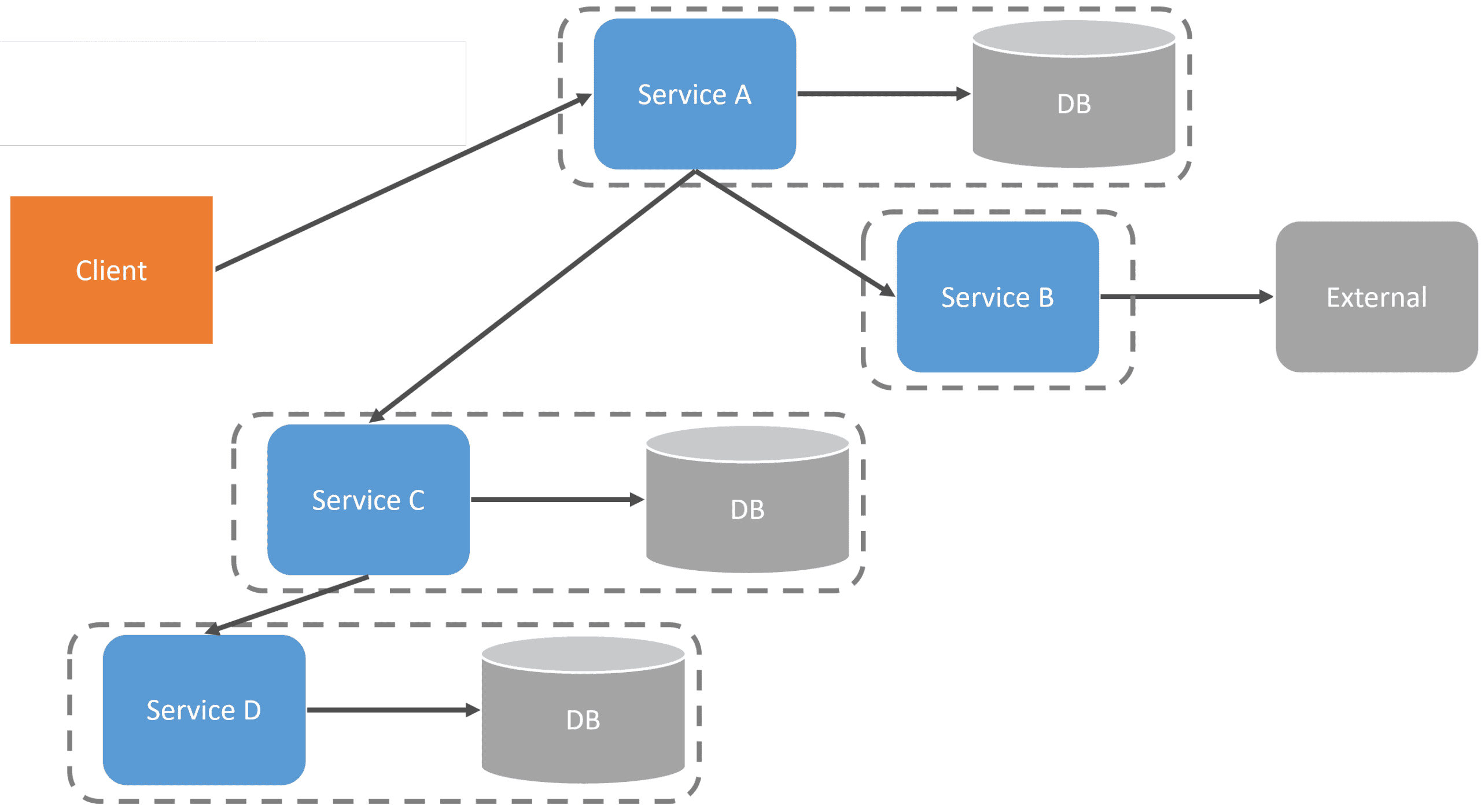
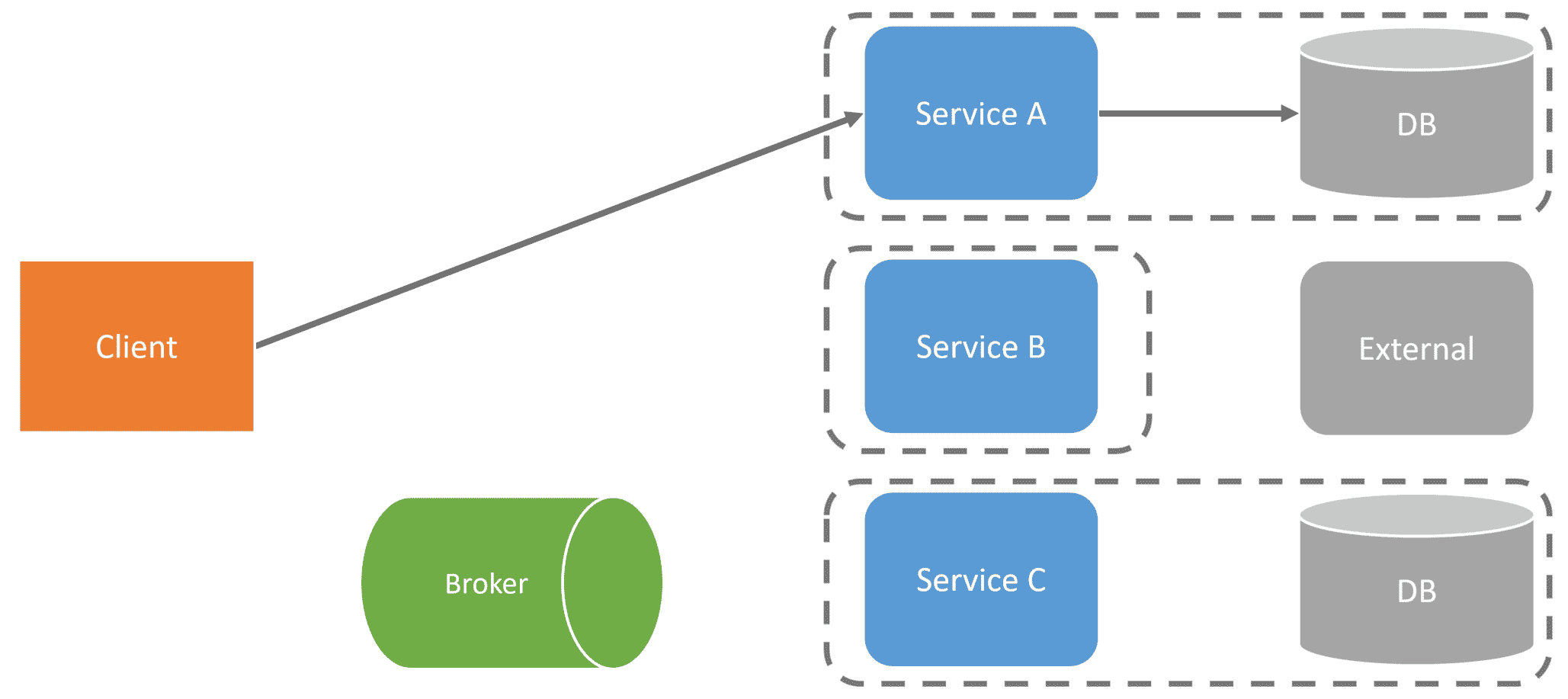
As an example, if there is a request from a client to Service A, and it needs to make a call to other services, they might make calls to other services.
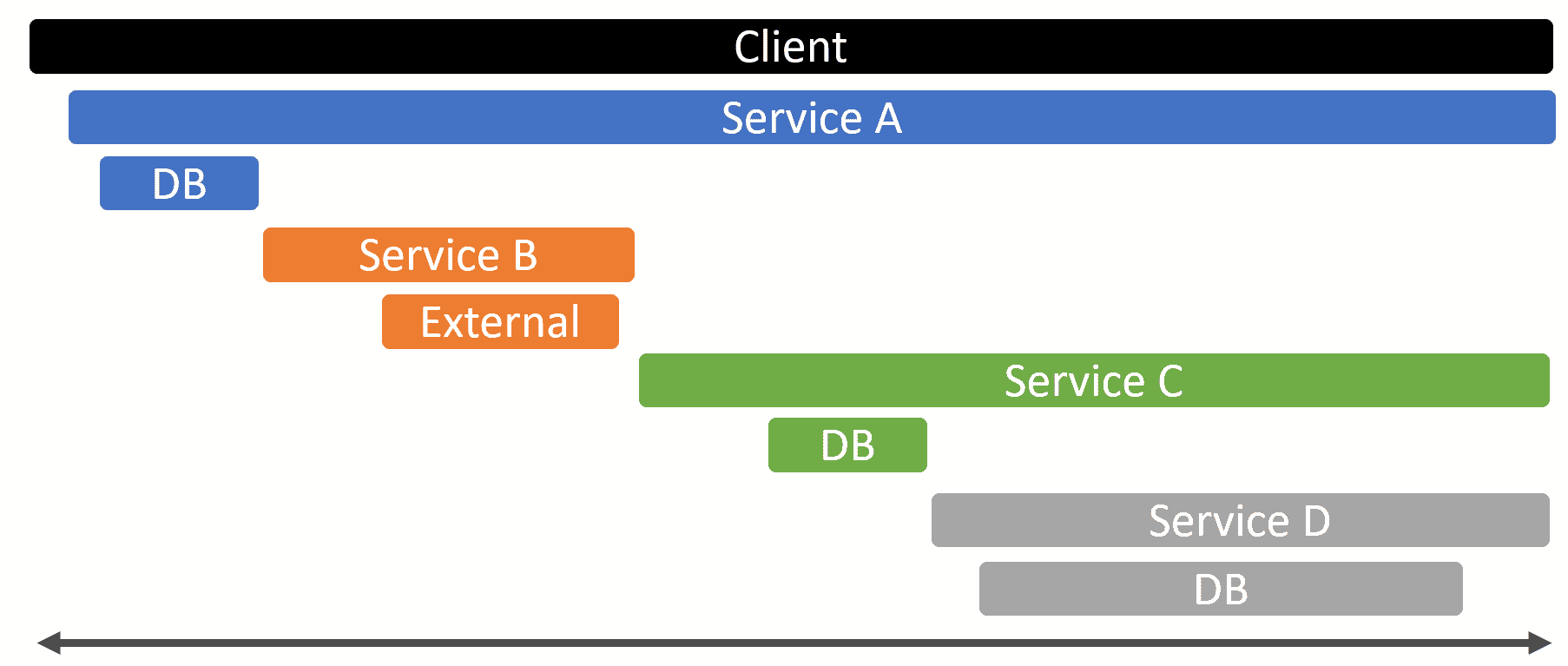
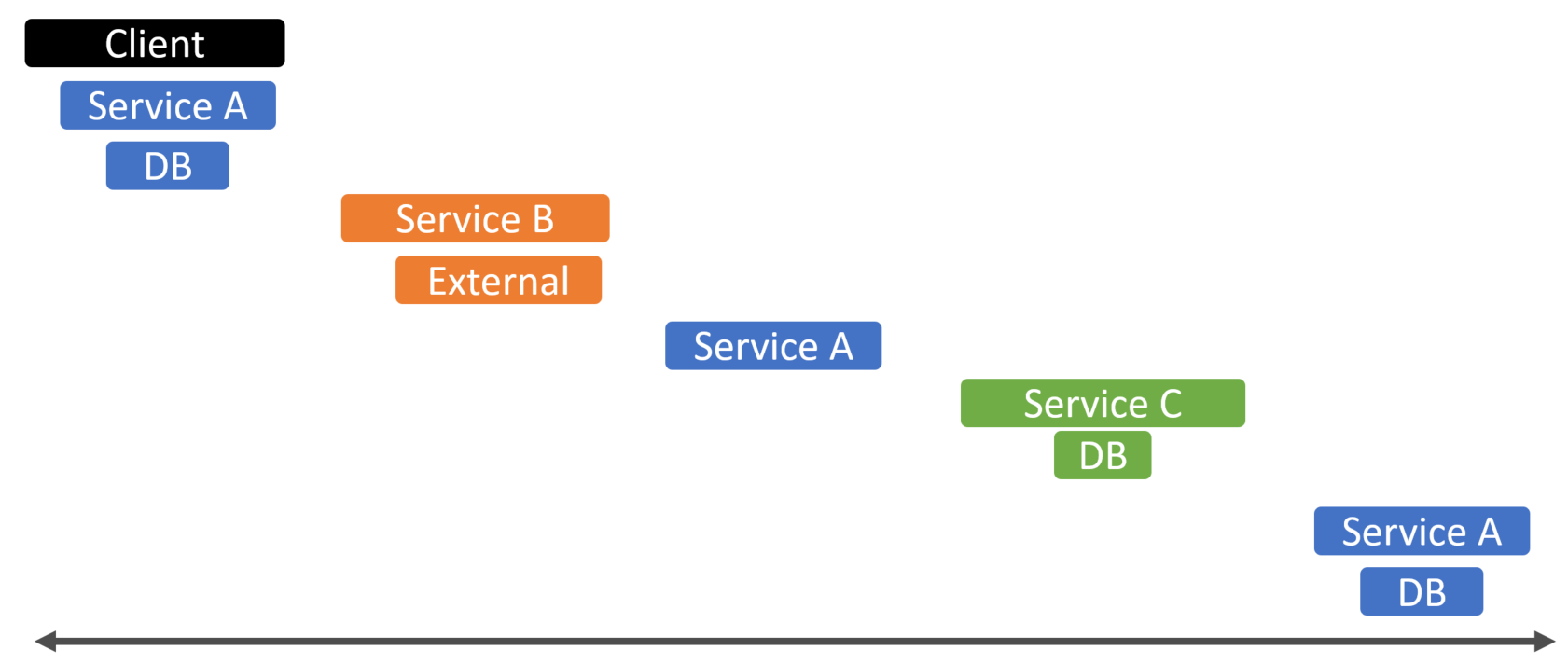
With distributed tracing, you could see the flow of a request that passes through multiple distributed services. To illustrate, here’s a timeline of the diagram above.
So it’s great that distributed tracing can give us away from observing a request’s flow. The problem is having service-to-service communication can lead to another set of challenges beyond tracing.
Distributed tracing in this service-to-service system style is a band-aid to a problem you shouldn’t have. Blocking synchronous calls, such as HTTP, from service to service can provide issues with latency, fault tolerance, and availability, all because of temporal coupling. Check out my post on REST APIs for Microservices? Beware! that dives deeper into this topic.
Blocking Synchronous Calls
However, not all blocking synchronous calls can be avoided. Specifically, any type of query, such as a request from a client, will naturally be a blocking synchronous call. If you’re doing any type of UI composition, you may choose to use a BFF (Backend for frontend) or API gateway to do this composition. The BFF makes synchronous calls to all services to get data from each to compose a result for the client.
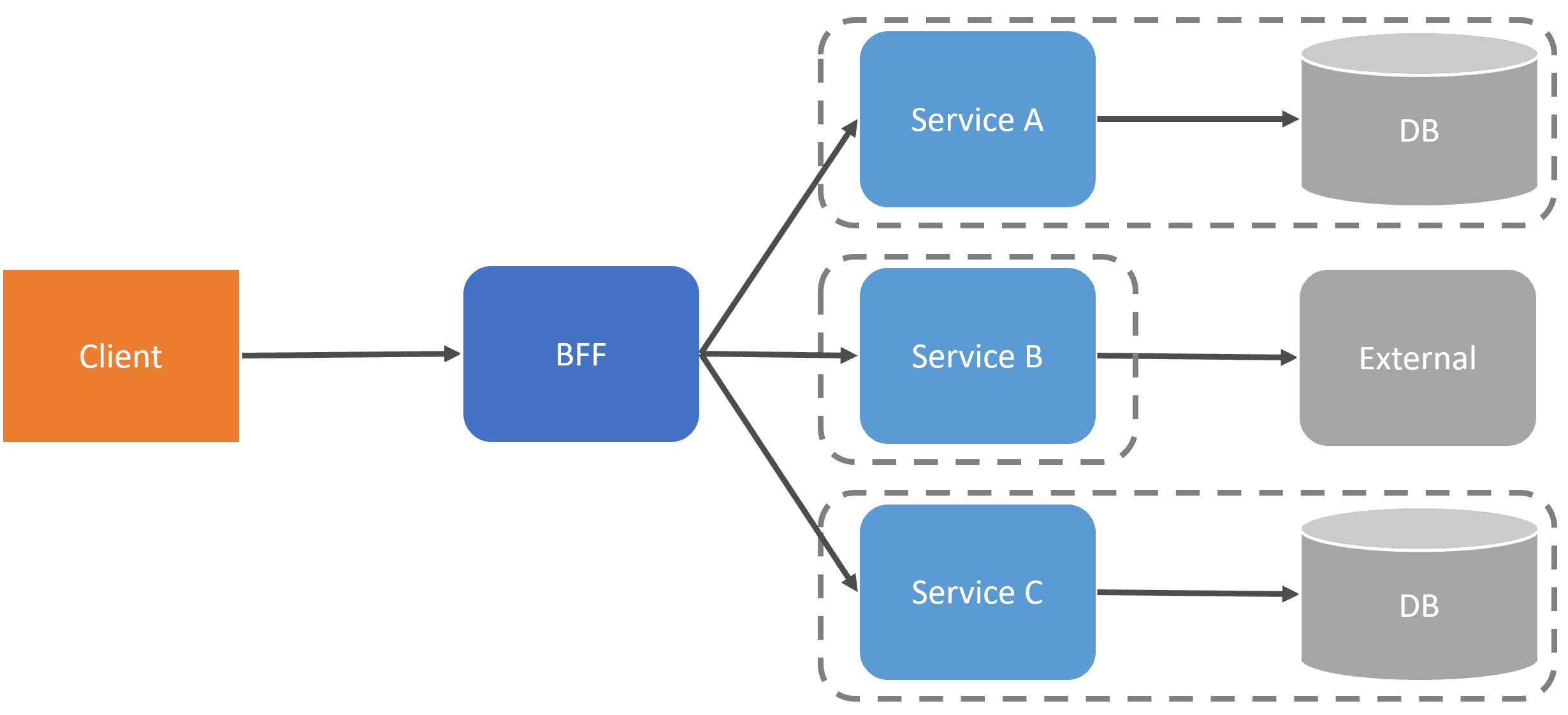
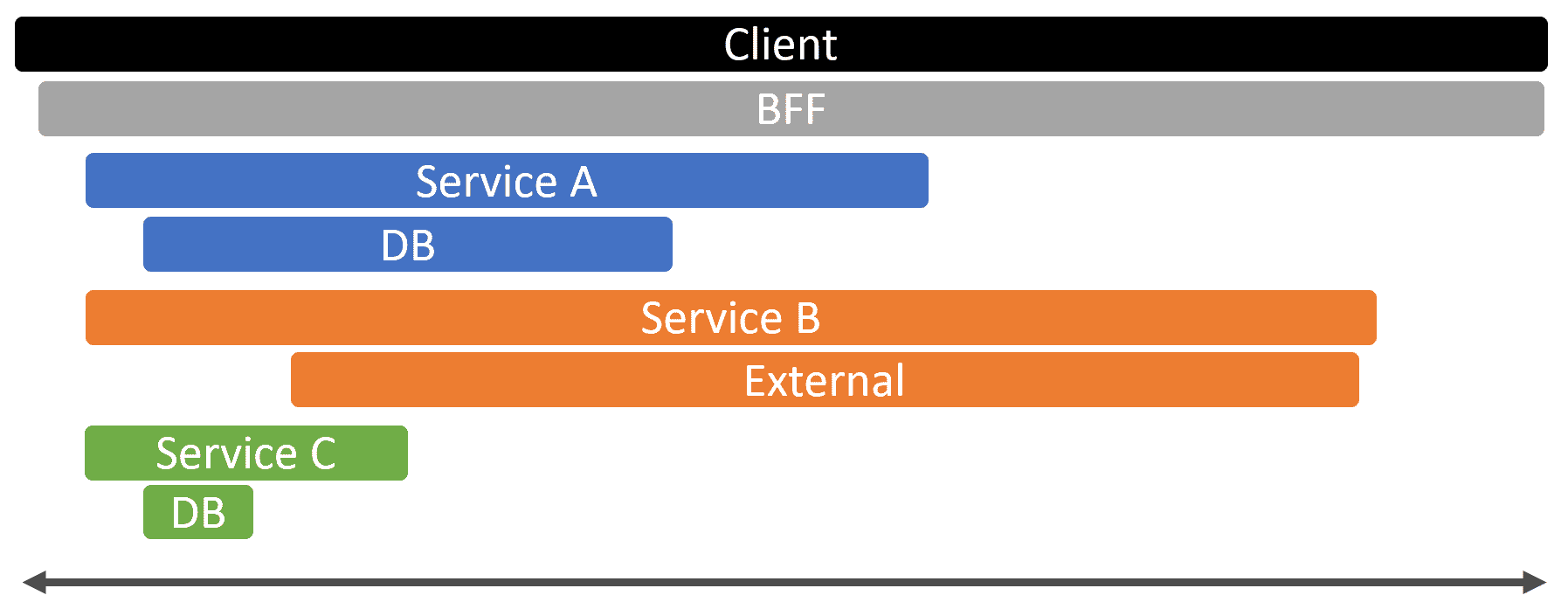
Distributed tracing in this situation is great! We’ll be able to see which services have the longest response time because, ultimately, if we are making all calls from the BFF to backing services concurrently, the slowest response will determine the length of the total execution time from the client.
Workflow
Another great place for distributed tracing is with asynchronous workflows. It has always been very challenging to see the flow of a request executed asynchronously by passing messages via a message broker. Distributed tracing solves that and allows us to visualize that flow.
As an example, the client requests the initial service to perform a command/action.
The service will then create a message and send it to the message broker for the next service to continue the workflow.
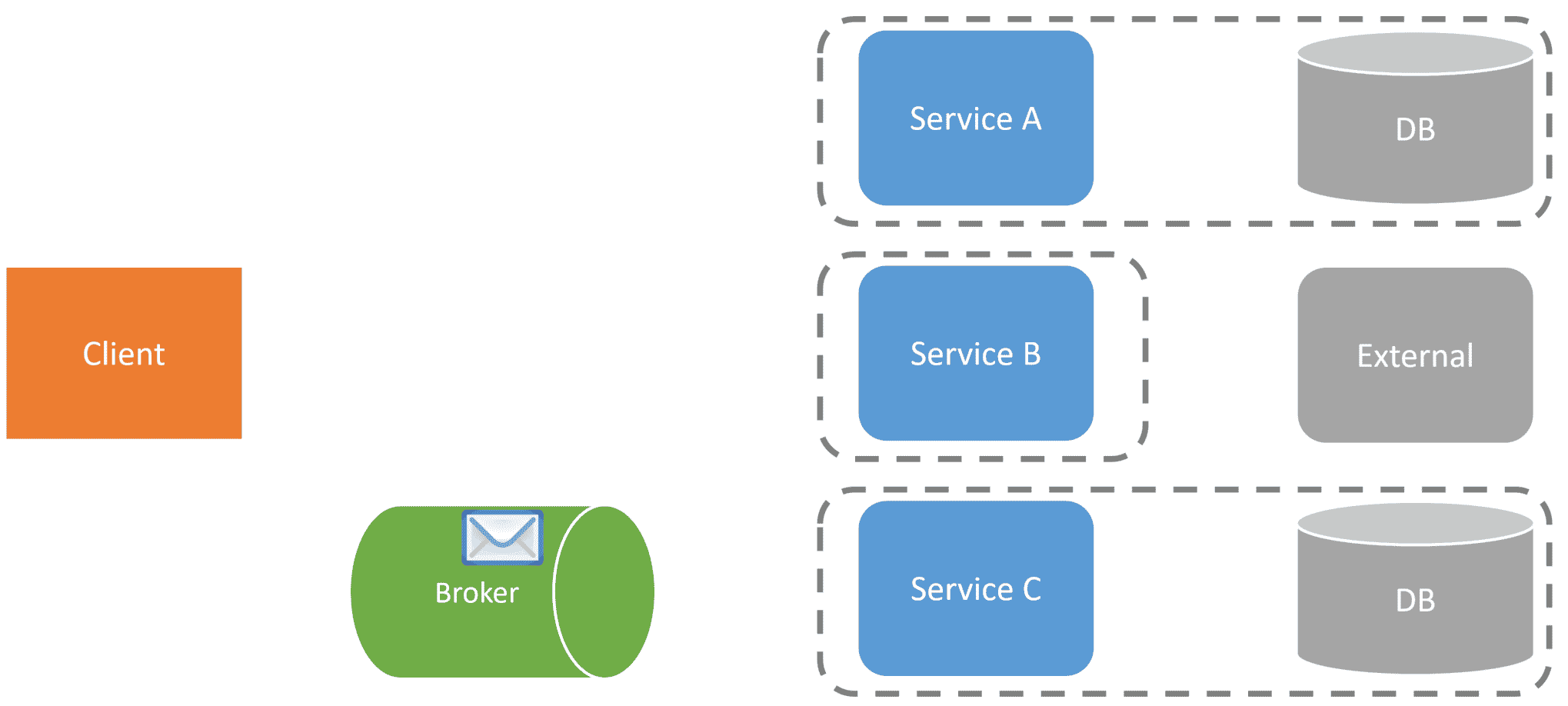
Another service will pick up this message and perform whatever action it needs to take to complete its part of the entire workflow.

Once the second service is completed processing the message, it may send another message to the broker.
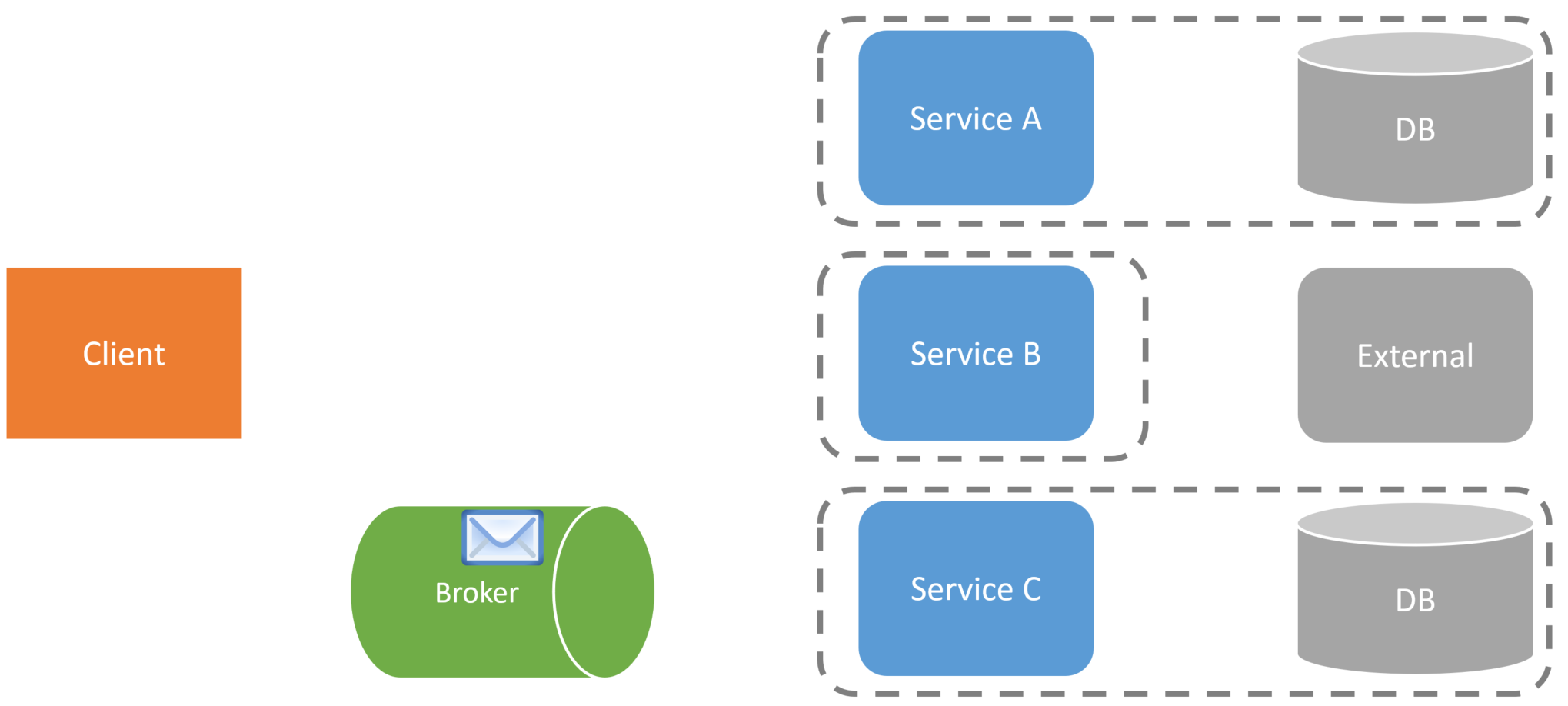
A third service (ServiceC) might pick up that message from the broker and perform some action that is a part of this long-running workflow. And just like the others, it may send a message to the broker once it’s complete.
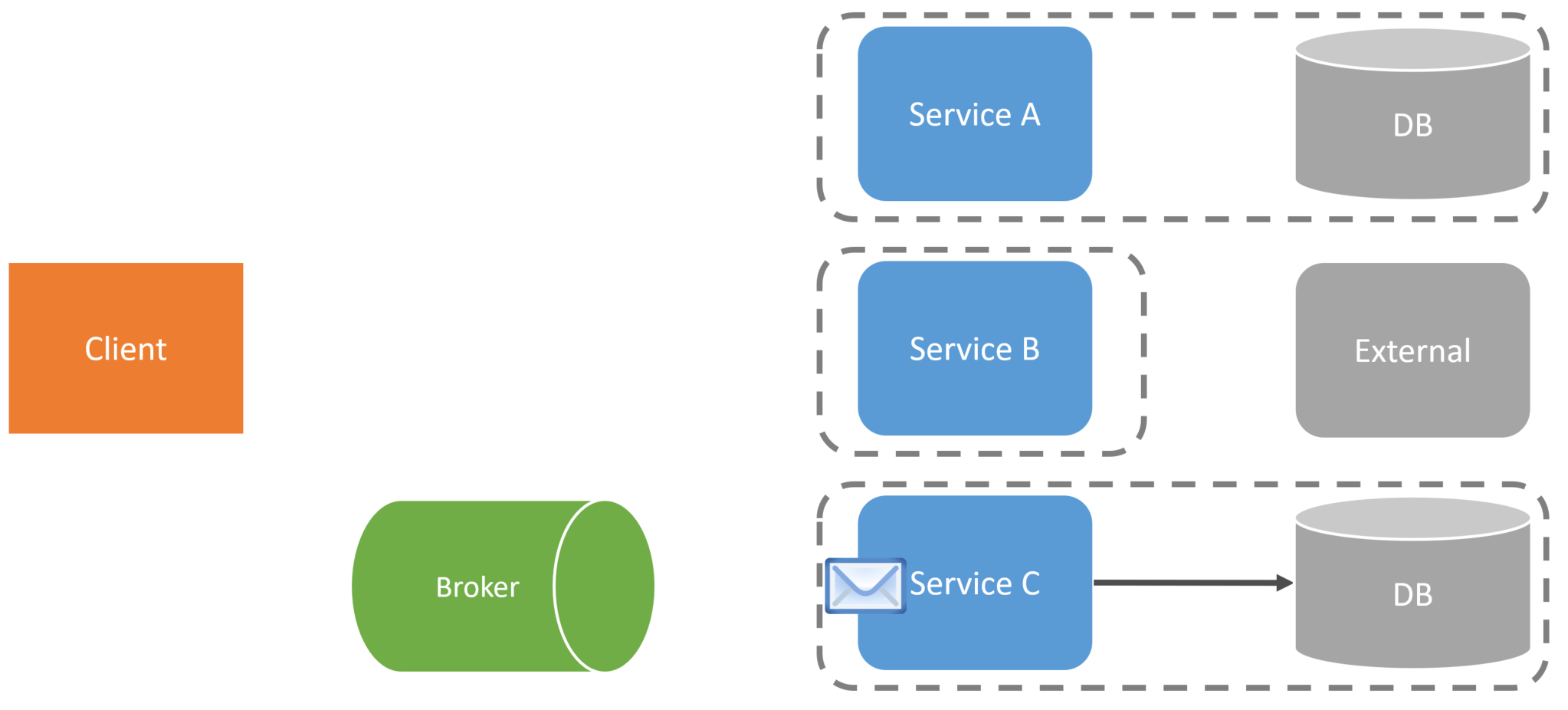
At this point, ServiceA, which started the entire workflow, may consume the last message sent by ServiceA to do some finalization of the entire workflow.
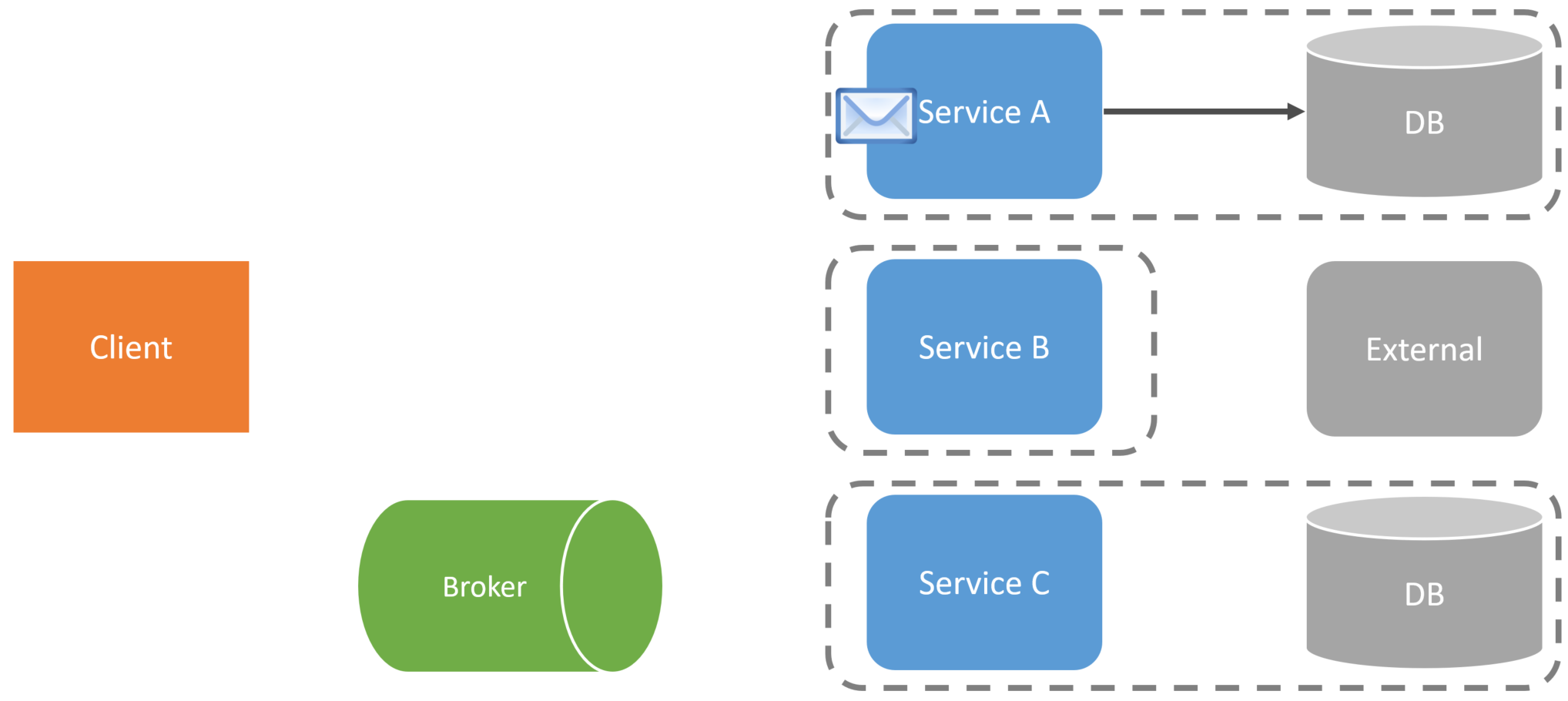
Because this entire workflow was executed asynchronously and has removed the temporal coupling, each service doesn’t have to be online and available. Each service will consume and produce messages at its rate and availability without causing the entire workflow to fail.
OpenTelemetry & Zipkin
I’ve created a sample app that uses OpenTelemtry with NServiceBus for an asynchronous workflow that can then be visualized with Zipkin. If you want access to the full source code example, check out the YouTube Membership or Patreon for more info.
As an example with ASP.NET Core, I’ve added OpenTelemery packages and added the registration for them in the ConfigureServices of the Startup. This will add tracing for NServiceBus, any calls using the HTTPClient, and ASP.NET Core itself.
With NServiceBus I have a saga that is orchestrating sending commands to various logical boundaries to complete the workflow.
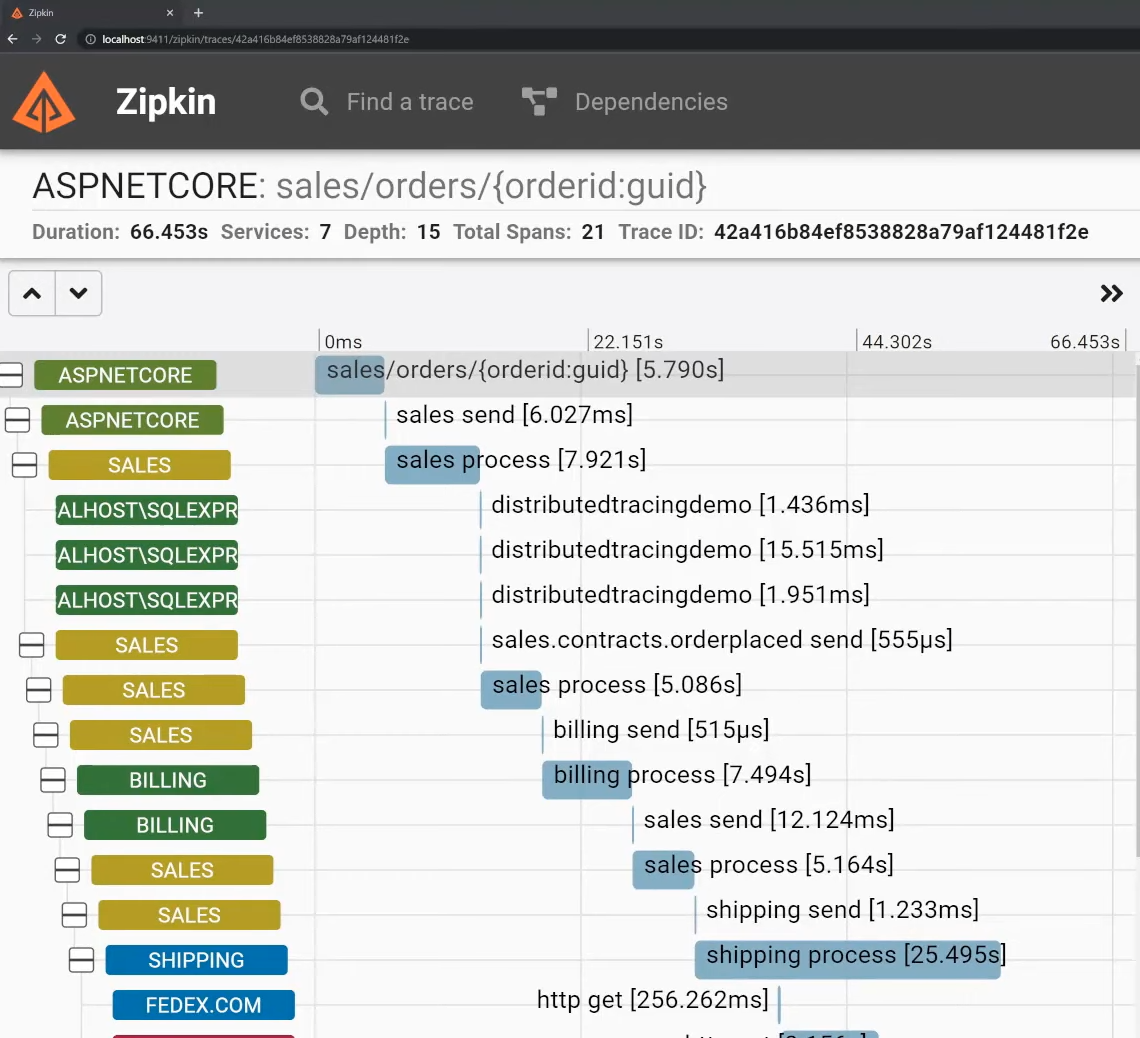
After running the sample app, I can open up Zipkin and see the entire trace that spans my ASP.NET Core app that is going through the various logical boundaries, including the database calls SQL Express, and the HTTP call to Fedex.com
Distributed Tracing
Distributed tracing is great for collecting data and observing the flow of a long-running business process or if you’re doing UI Composition using a synchronous request/response involving many different services. However, don’t use it as a crutch because there is a pile of service-to-service synchronous requests/responses proving difficult to manage. If anything, use distributed tracing to realize you have a high coupled distributed monolith so you can remove some of the temporal coupling making your system more loosely coupled and resilient.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out the YouTube Membership or Patreon for more info.