Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
In a system where many users are collaborating concurrently, it can be difficult to manage data consistency between microservices. Do you need consistency? Maybe, maybe not. It’s a discussion to have with the business about the impact of inconsistent data. If it is important to have consistency, then one solution to this problem is by not having it in the first place. When data is required from another service for business logic, then it’s possibly a sign that you have some misaligned boundaries.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything that is in this post.
Commands
To illustrate using inconsistent data, I’ll use the example of placing an Order. The Client/Caller makes a request to our Order/Sales boundary.
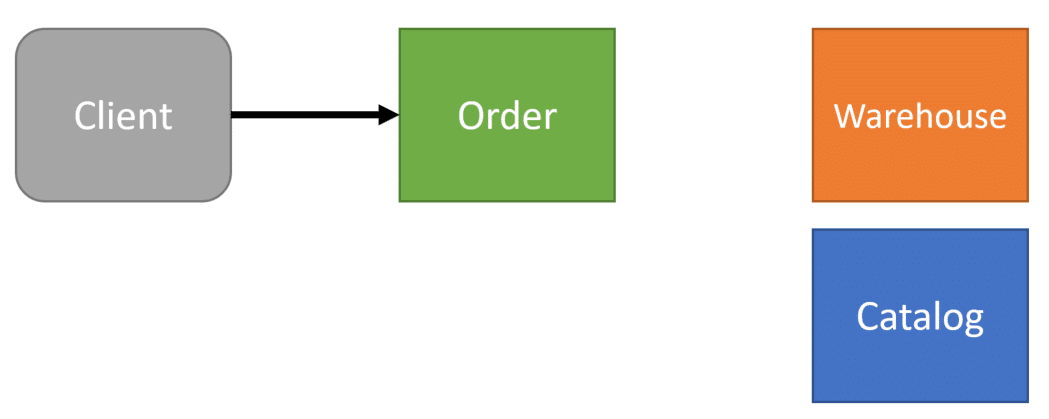
The Order/Sales needs to call the warehouse to get the quantity on hand of the product being ordered. If there is no Quantity On Hand in the warehouse, then we cannot place that Order.
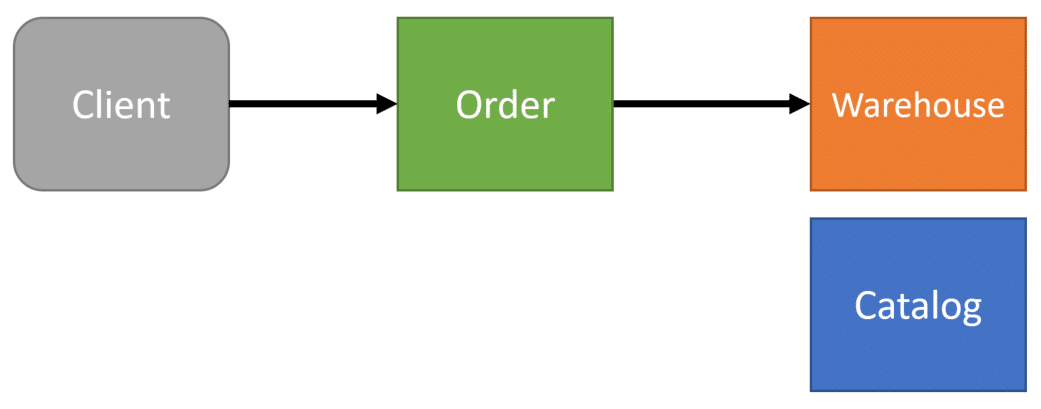
After we get the Quantity on Hand from the warehouse, we then call the Catalog boundary to get the Price of the Product we are ordering.
Here’s a code sample of what that might look like.
Concurrency
The issue with the above is the moment we retrieve the Quantity On Hand from the Warehouse and the Price from the Catalog, we immediately have stale data. This is because there will be no data consistency between those pieces of data and saving our new Order.
In a collaborative environment, you will have many users/processes interacting concurrently with various parts of the system.

When we placed the order, we might have had another client at the same time do an inventory adjustment which then set the Quantity on Hand to 0. We could also have another client change the price for the product we’re ordering.
There is no data consistency.
If you’re in a monolith or share the same database where you can have all statements (selects & insert/update/deletes) be using the same database transaction with the correct isolation level (serializable), then you can prevent performing dirty reads to get consistency.
The code sample above, modified to use a serializable isolated transaction now looks like this:
Data Consistency
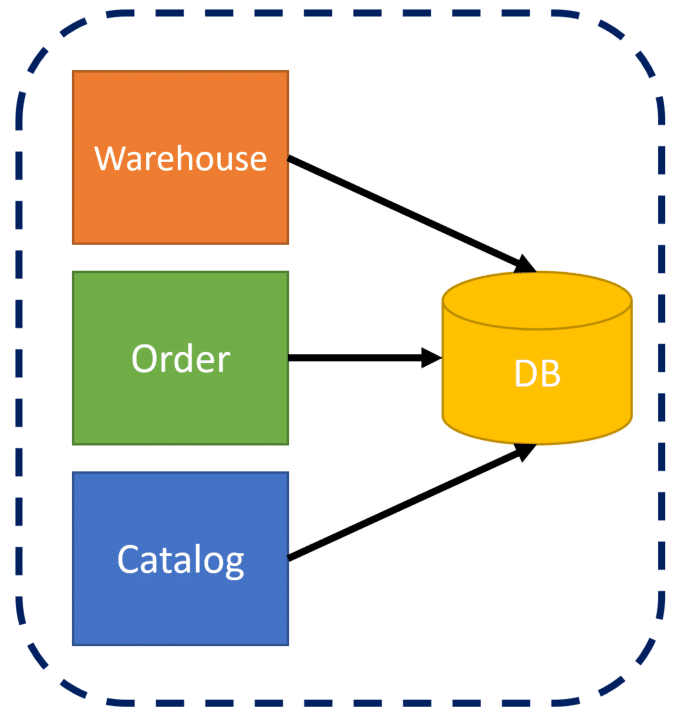
If you’re not using a single database and have a database per service, which I recommend, then how is having data consistency even possible? It’s not without a distributed transaction, which you likely won’t.
The root of the problem is querying data from other boundaries that will be immediately inconsistent the moment it’s returned, just as in my first example without a serializable transaction. If you’re making HTTP or gRPC calls to other services to retrieve data that you require to perform business logic, you’re dealing with inconsistent data. If you store a local cache copy that’s eventually consistent, you’re dealing with inconsistent data.
Is having inconsistent data an issue? Go ask the business. If it is, then you need to get all relevant data within the same boundary that’s required.
There are two pieces of data we ultimately needed.
We required the Quantity on Hand from the warehouse. In reality in the distribution/warehouse domain, you don’t rely on the “Quantity on Hand”. When dealing with physical goods, the point of truth is actually what is actually in the warehouse, not what the software/database states. Products can be damaged, stolen, and lost which the system does not know about in real-time. The system is eventually consistent with the real world.
Because of this, Sales has the concept of Available to Promise (ATP) which is a business function for customer order promising based on what’s been ordered but not yet shipped, purchased but not yet received, etc.
The catalog boundary also contained the price of the Product. But why? Why would the Catalog service own the selling price? Wouldn’t the Sales boundary own the selling price?

If we re-align where data ownership belongs within various boundaries, we can get back to having consistency with the right level of transaction isolation.
In the code below, we can go back to using a serializable transaction because our Sales boundary has the Price and Available to Promise (ATP) that we can use within this boundaries database. No longer are we using inconsistent data or relying on querying other boundaries.
Source Code
Developer-level members of my CodeOpinion YouTube channel get access to the full source for any working demo application that I post on my blog or YouTube. Check out the membership for more info.