Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
What’s Event Choreography Workflow? Let’s back up a bit to answer that. Event Driven Architecture is a way to make your system more extensible and loosely coupled. Using events as a way to communicate between service boundaries. But how do you handle long-running business processes and workflows that involve multiple services? Using RPC is going back to tight coupling, which we’re trying to avoid with Event Driven Architecture. So what’s a solution? Event Choreography.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
RPC
So why not just use RPC via an HTTP API or gRPC? Well, the point of using asynchronous messaging and an event driven architecture is to be loosely coupled and remove temporal coupling. Temporal coupling matters because a long-running business process or workflow that involves many different services means that all services need to be available, and there can be no failures. You can add retries for transient failures, but if a significant issue with a service or data causes the workflow to fail, you have no recourse to resolve the issue. You can be stuck in an inconsistent state.
For example, if we had many service-to-service RPC calls, and far down the call stack, there is a failure, how do you handle that?
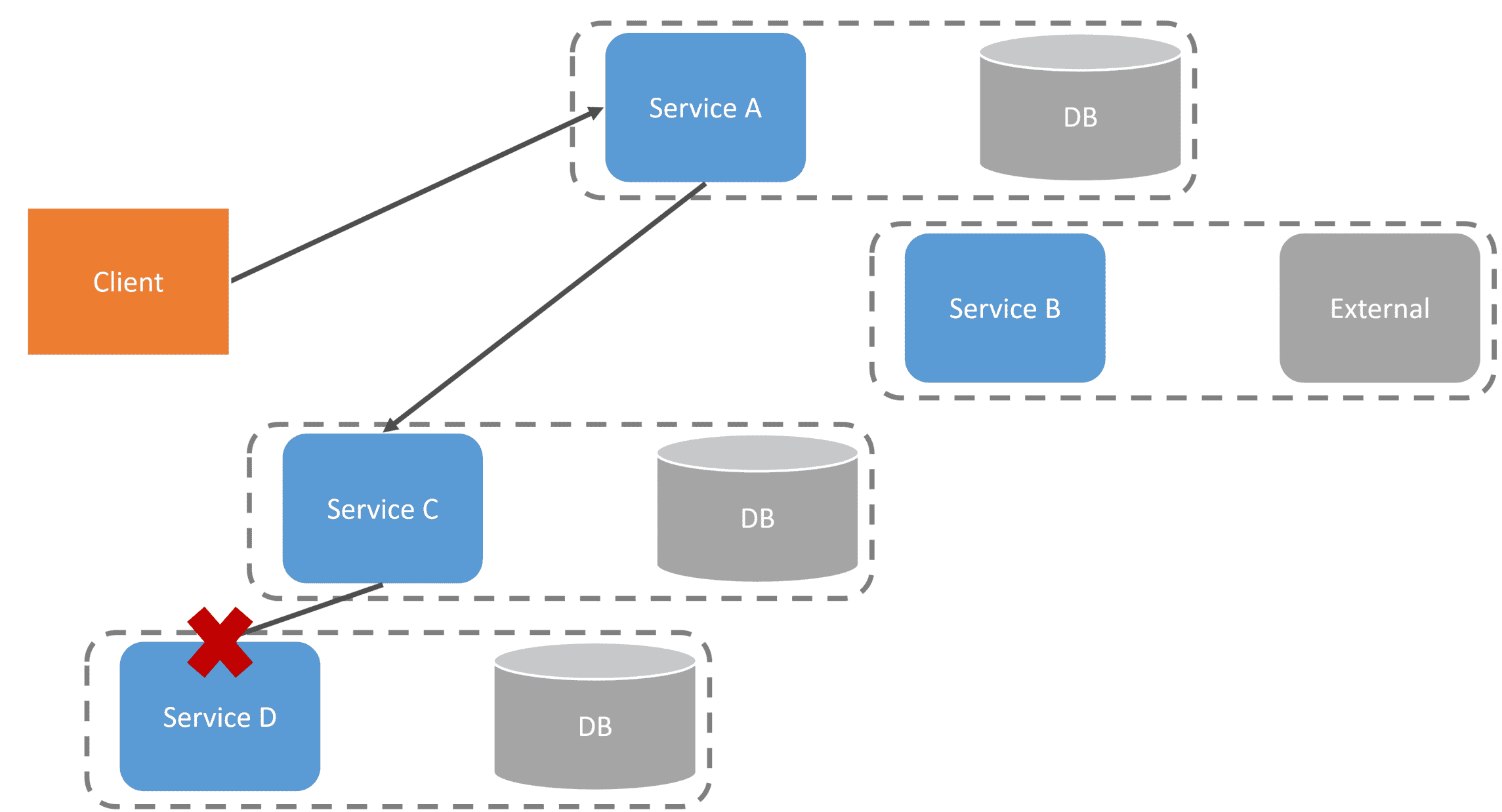
If Service A and Service C made state changes, they would need to have some type of compensating action to reverse the state change. There is no distributed transaction; you can’t just roll back the state of each service database. You need to deal with failures in each service that makes a service-to-service RPC call.
When all services are working correctly, there are no issues. But the moment you have a service that becomes unavailable, any workflow that involves that service will be immediately affected, likely causing the entire workflow to fail and leaving your system in an inconsistent state.
There are a whole other set of issues with RPC between services that I’m not even mentioning here, one of them being latency. Check out my post REST APIs for Microservices? Beware!
RPC Orchestration
Now you might think instead of making service-to-service RPC calls, is to make some type of orchestration that would make the RPC calls.
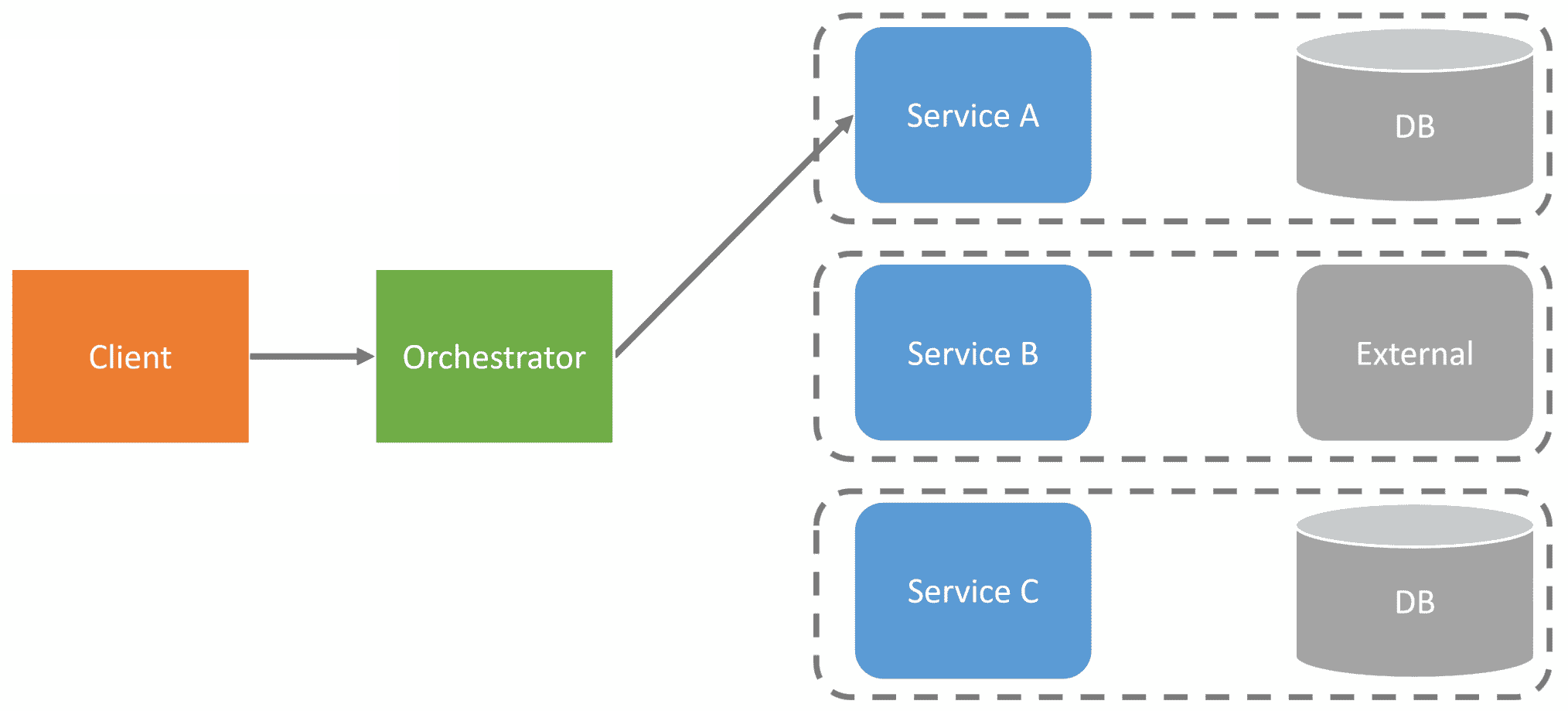
After it makes the first RPC call to the first service, it would make the following subsequent calls to other services in order.
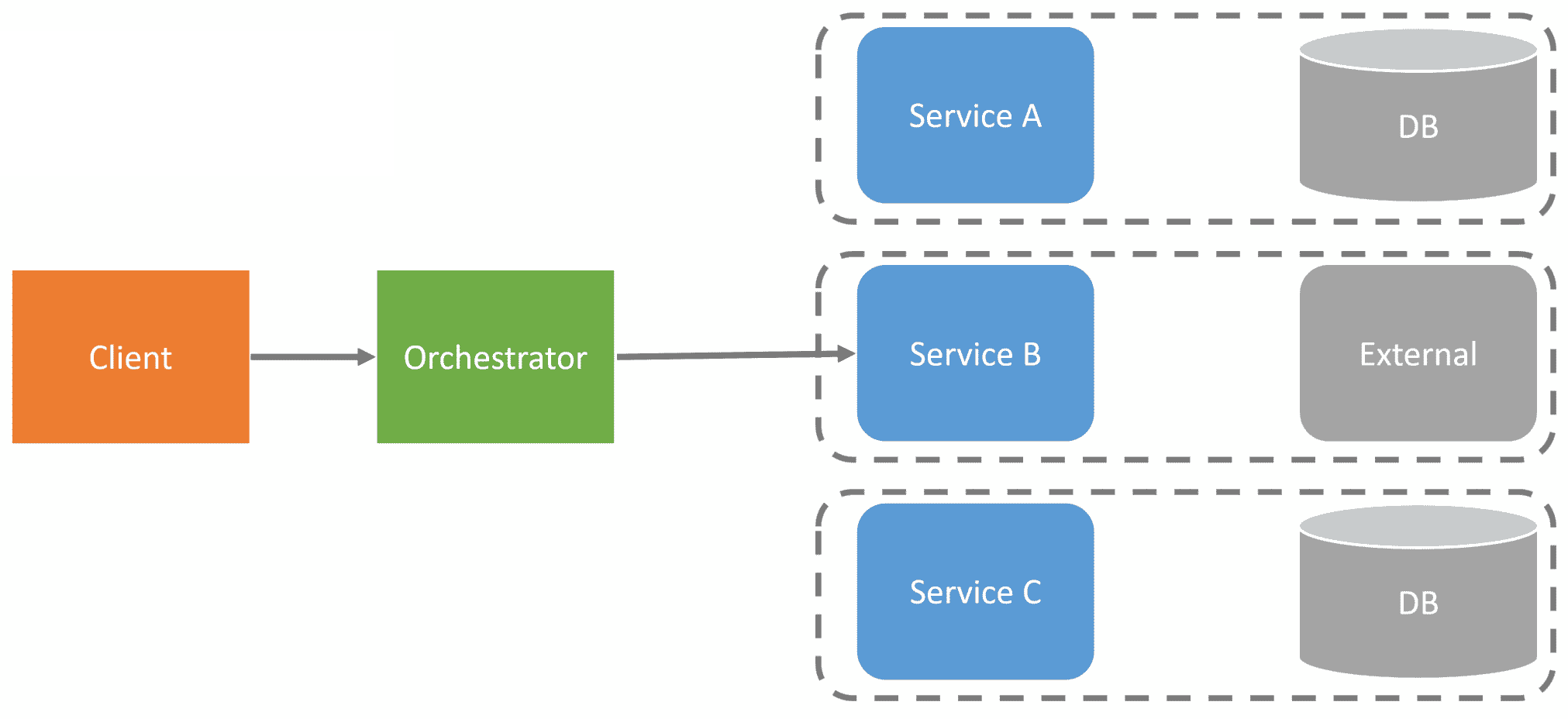
This would address the failures as the orchestrator could handle the retries upon failures. If there is a more extended failure/outage, it will make a request for a compensating action to void/undo a call to a previous service.
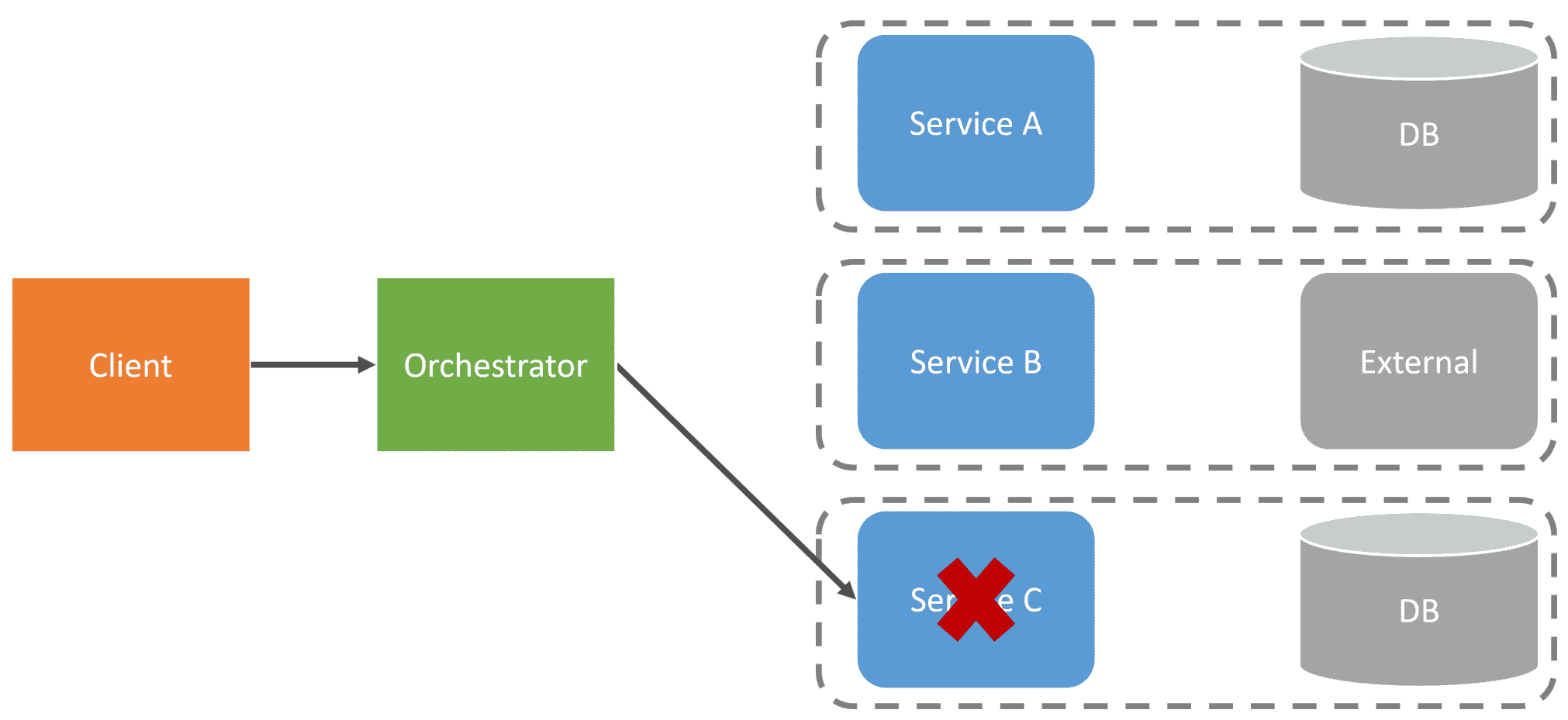
While this orchestrator sounds better than service-to-service RPC, we haven’t solved much. We still have a high degree of coupling, and our workflow will fail if a service is down or unavailable. If we have a failure and we need to make a call back to a previous service to perform some type of compensating action, what happens if that call fails? Again, we’re back to being in an inconsistent state.
Event Choreography
We can loosely couple between services with an event driven architecture and the publish-subscribe pattern and remove temporal coupling by publishing and consuming events.
For example, Service A receives a request from the client that kicks off the workflow.
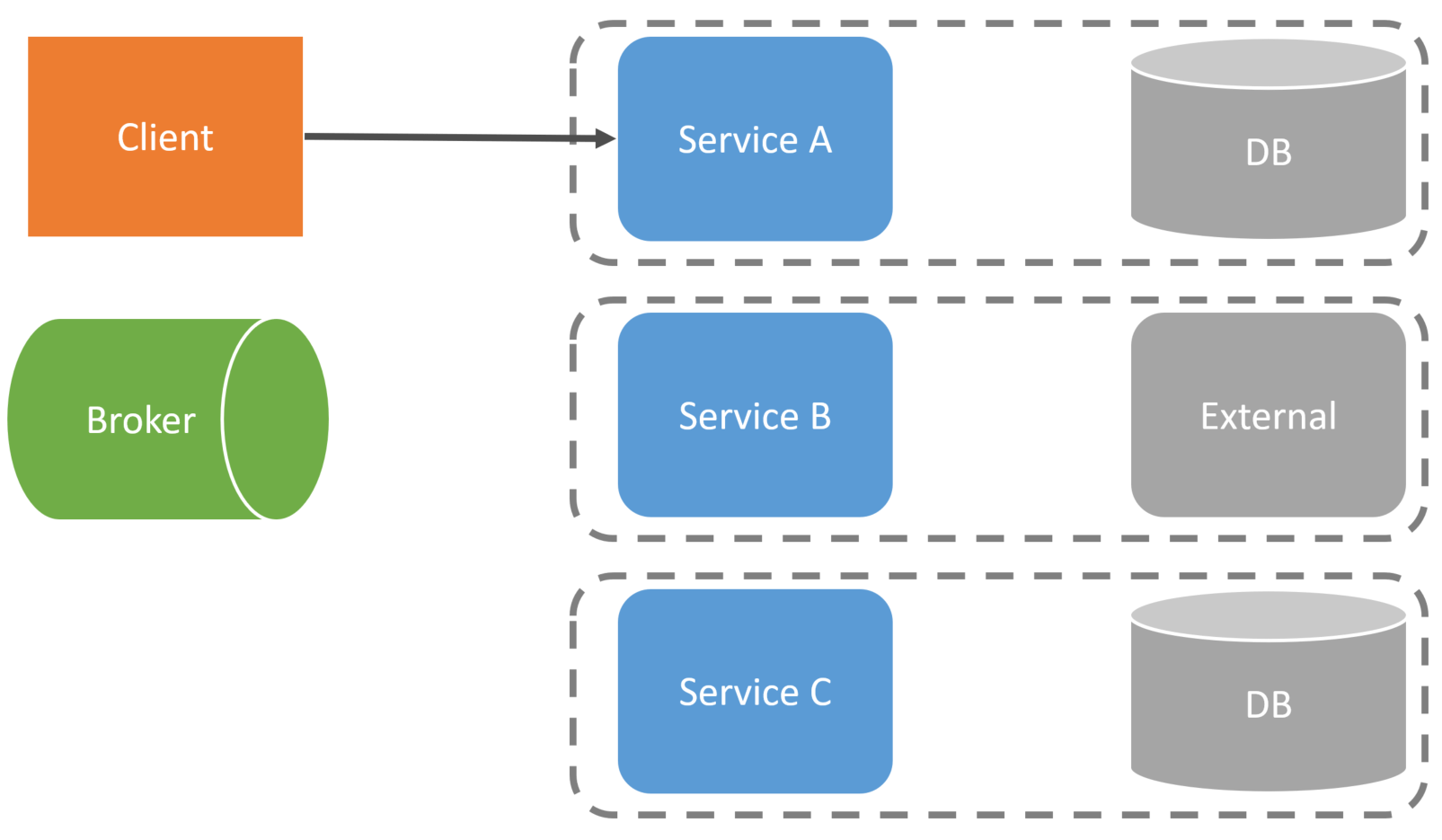
After making its state change to its database, Service A would publish an event to our message broker.
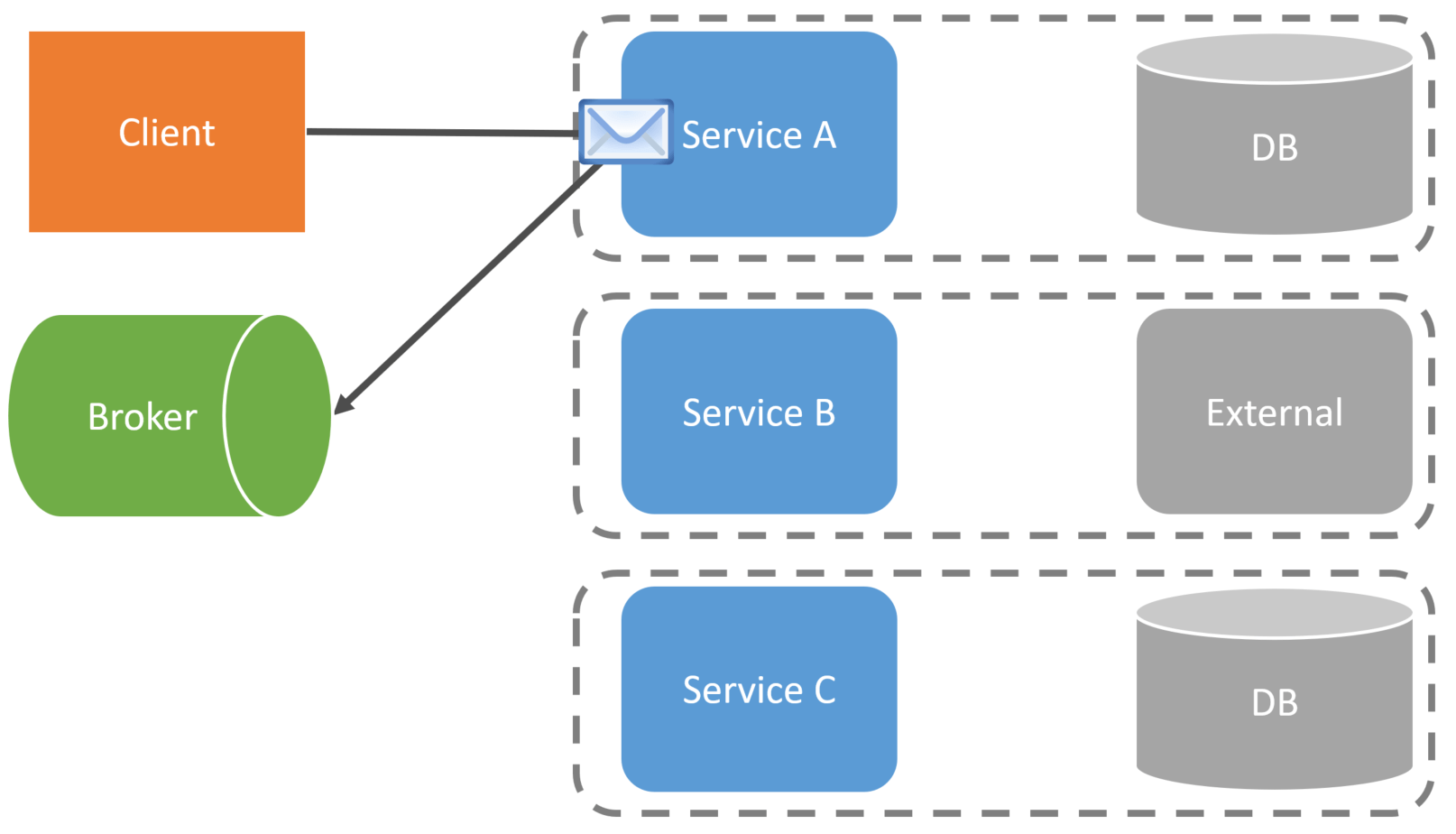
At this point, the request from the Client to Service A is complete. Service B will consume the message/event published by Service A. Service B consumes this message to do its part of the workflow.
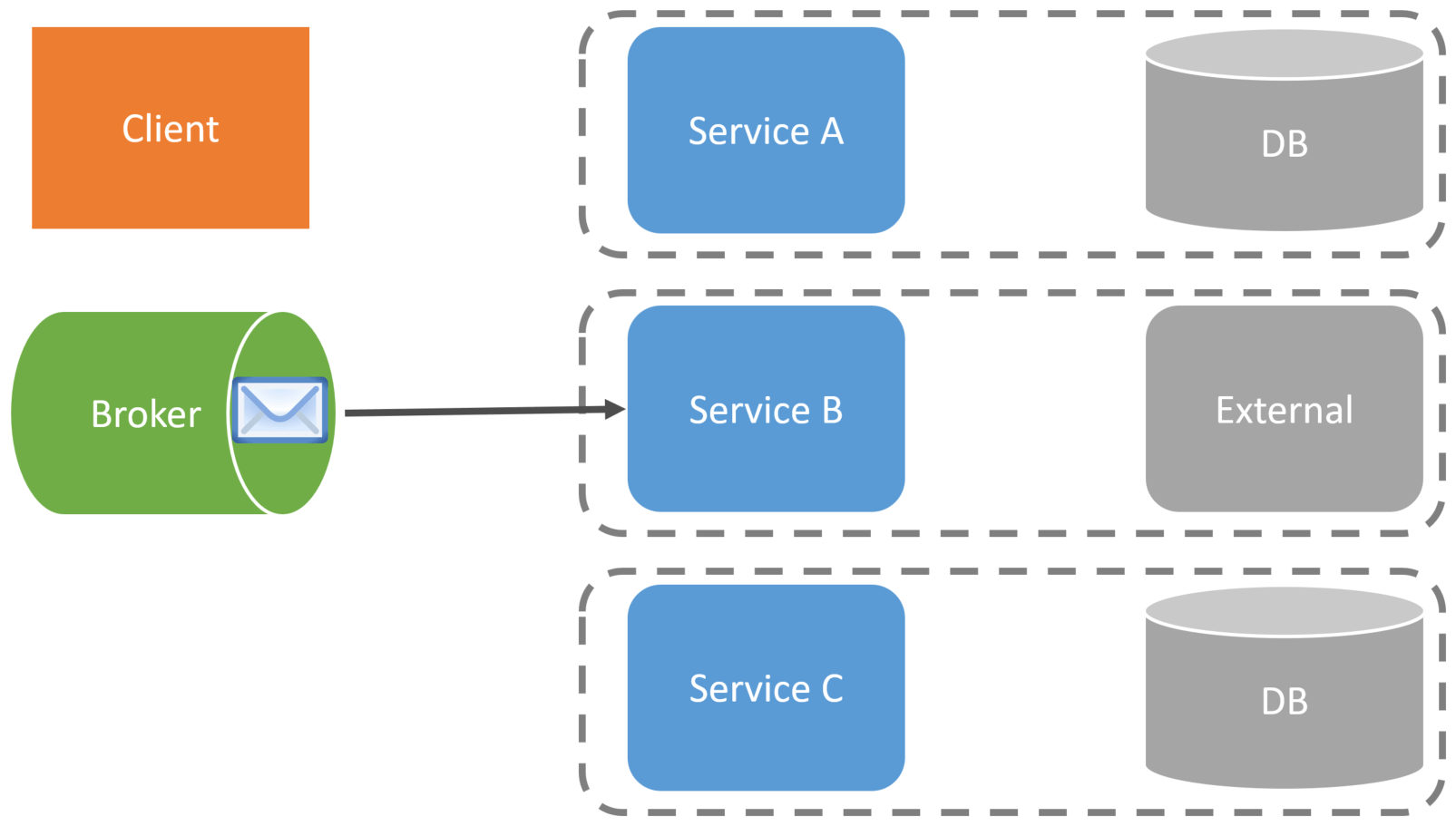
Once Service B has successfully consumed the message, it will publish an event to the broker, which will kick off the next service that is a part of the workflow.
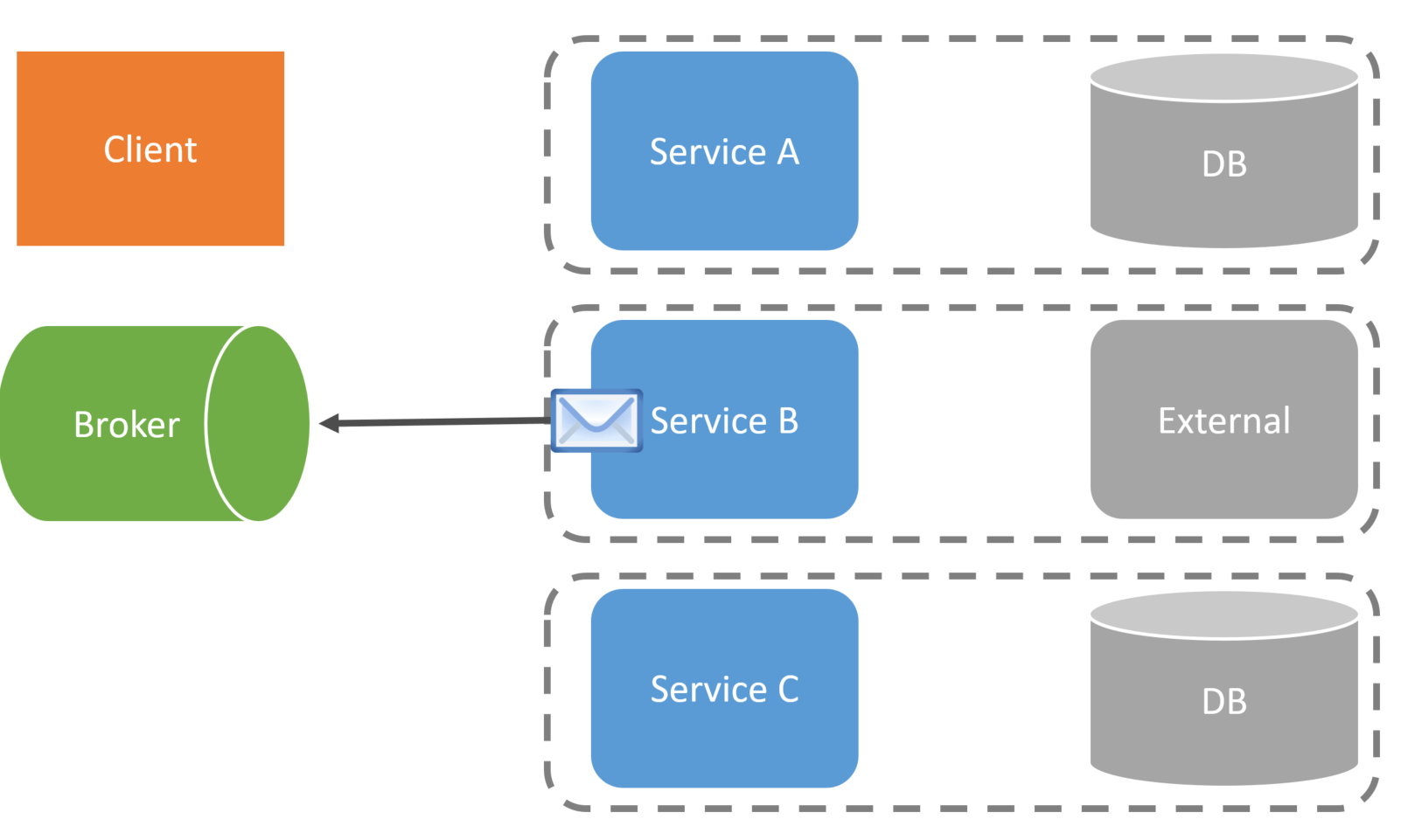
Service C is the next service involved in the workflow, and it consumes the event published by Service B.
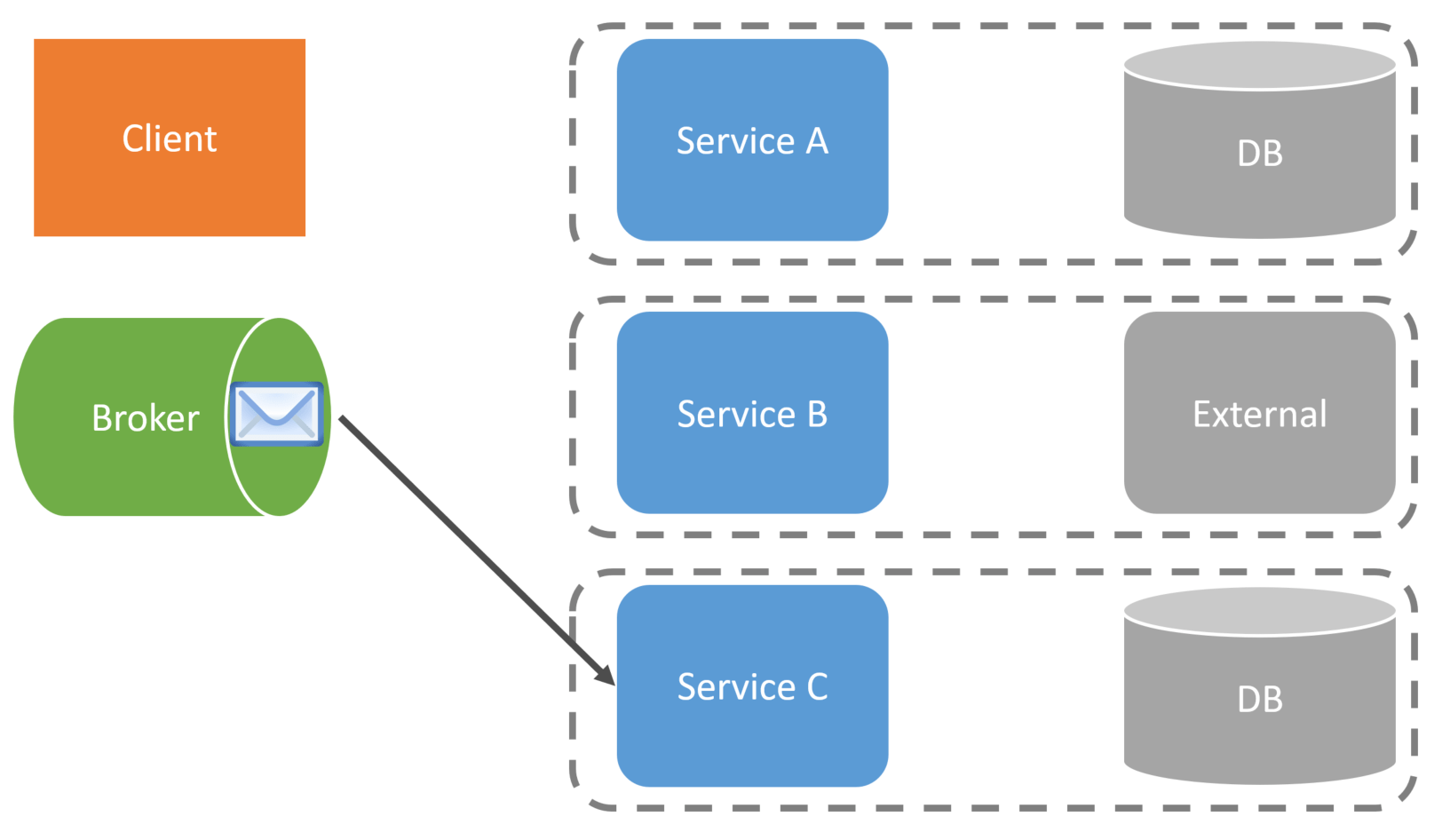
Because we aren’t temporally coupled, each service consumes a message and processes it independently.
This means if Service C is unavailable or has a backlog of messages to process, that doesn’t break the workflow. Once the service becomes available again, and the message is processed, the workflow continues.
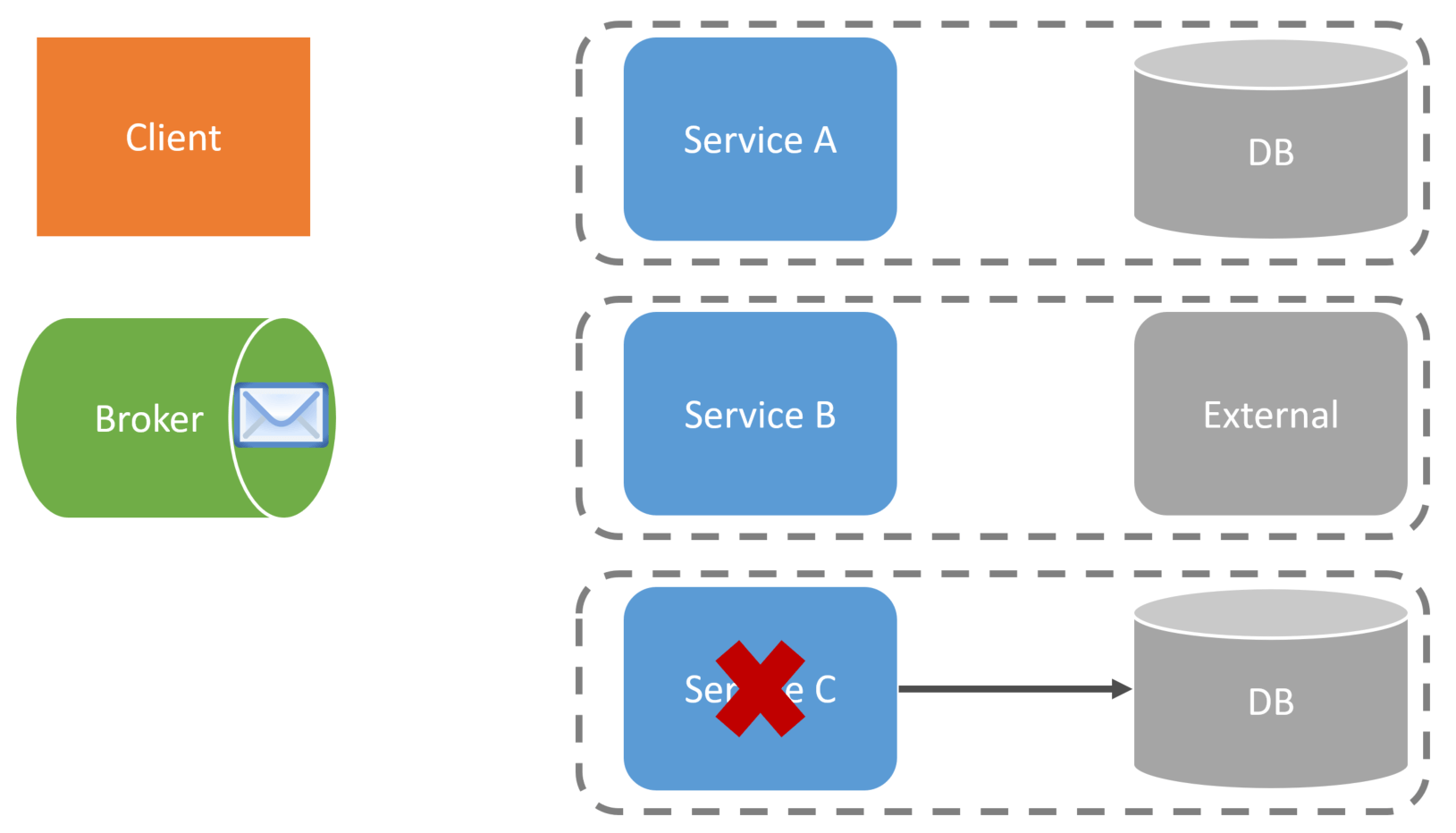
Is Event Choreography a silver bullet for workflow involving multiple services? No. Of course not. The challenge with event choreography for workflow is when you have more extended or complex workflows that involve more than just a few services. It is hard to visualize a workflow because there is no centralized orchestration to understand the entire workflow.
If you have complex workflows that involve many different services, check out my post on Workflow Orchestration for Resilient Systems
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out the YouTube Membership or Patreon for more info.