Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Why would you want data partitioning? Data keeps growing. Hopefully, you’re working on a system with active customers with a good lifespan! If so, the amount of stored data will keep growing over time. The challenge can be managing data growth, which can start to impact performance. I will discuss ways to use this data and strategies to avoid it affecting performance.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Multi-Tenant
In a multi-tenant application, there are multiple ways to silo data. First, you can use the same database instance, but a partition key indicates which data belongs to which tenant.
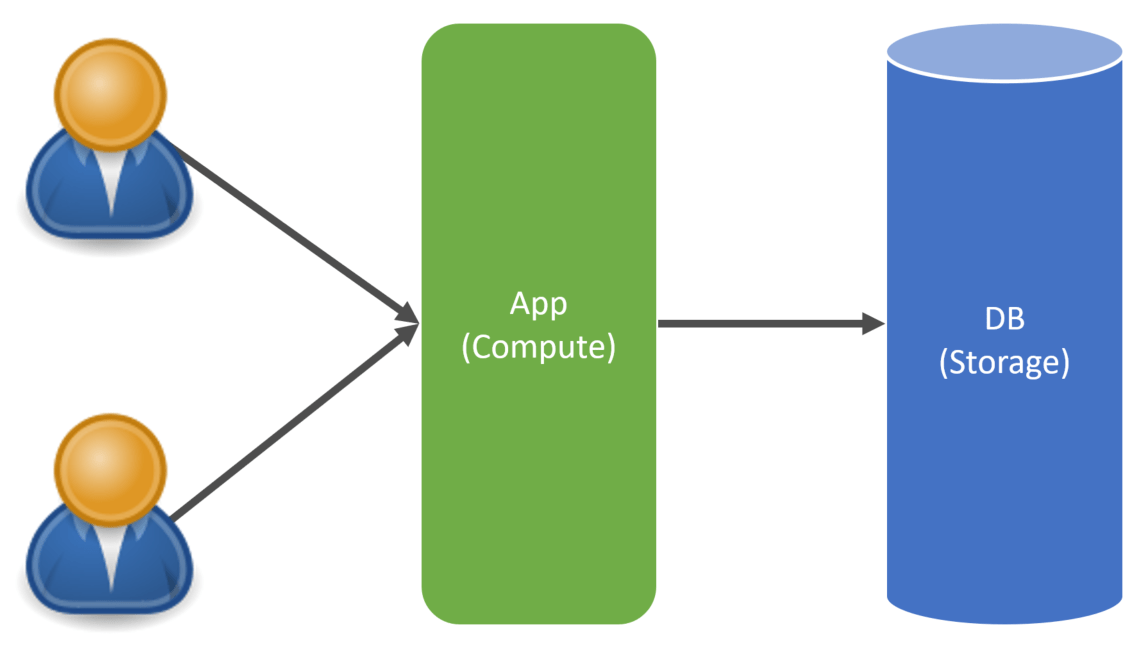
For example, tables in a relational database would have a TenantId, allowing you to query and retrieve data for a specific tenant.

For various reasons, data growth is one of them; you may choose to instead silo data in its database instance per tenant.
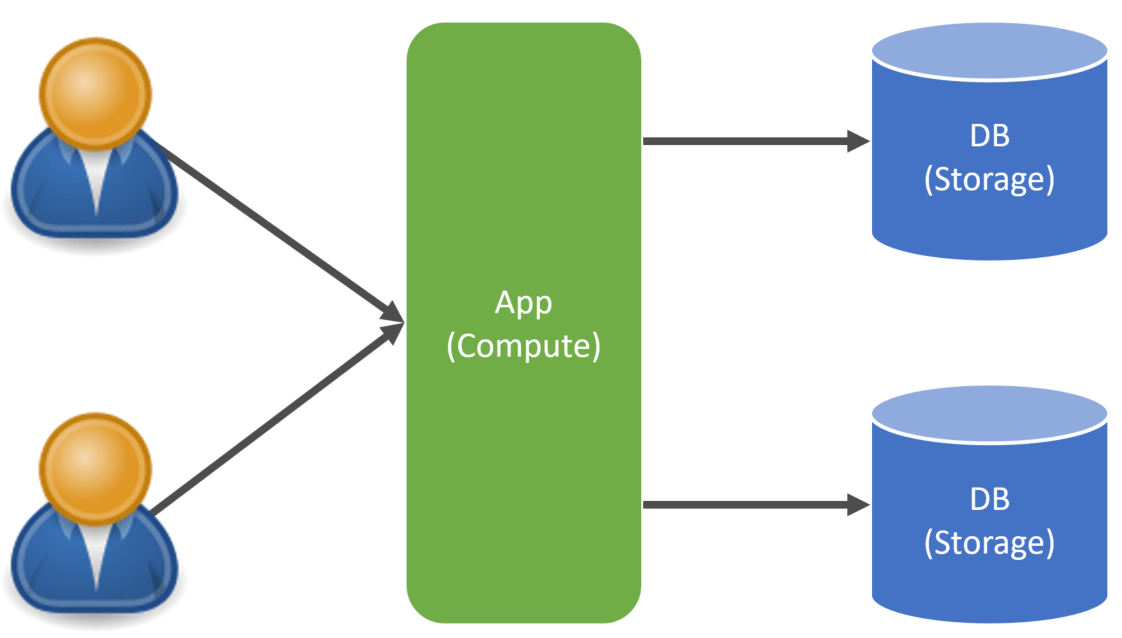
There are many reasons to silo data; check out my post on Multi-tenant Architecture for SaaS for more on various aspects of sharing compute, identity, and more within a Multi-Tenant SaaS architecture.
Regardless of if you use a partition key or silo data, hopefully, you’re working in a system where data is growing! Ultimately this would mean you’re building a system with a lot of activity and users! Congrats!
The issue is over time; more users means more data.
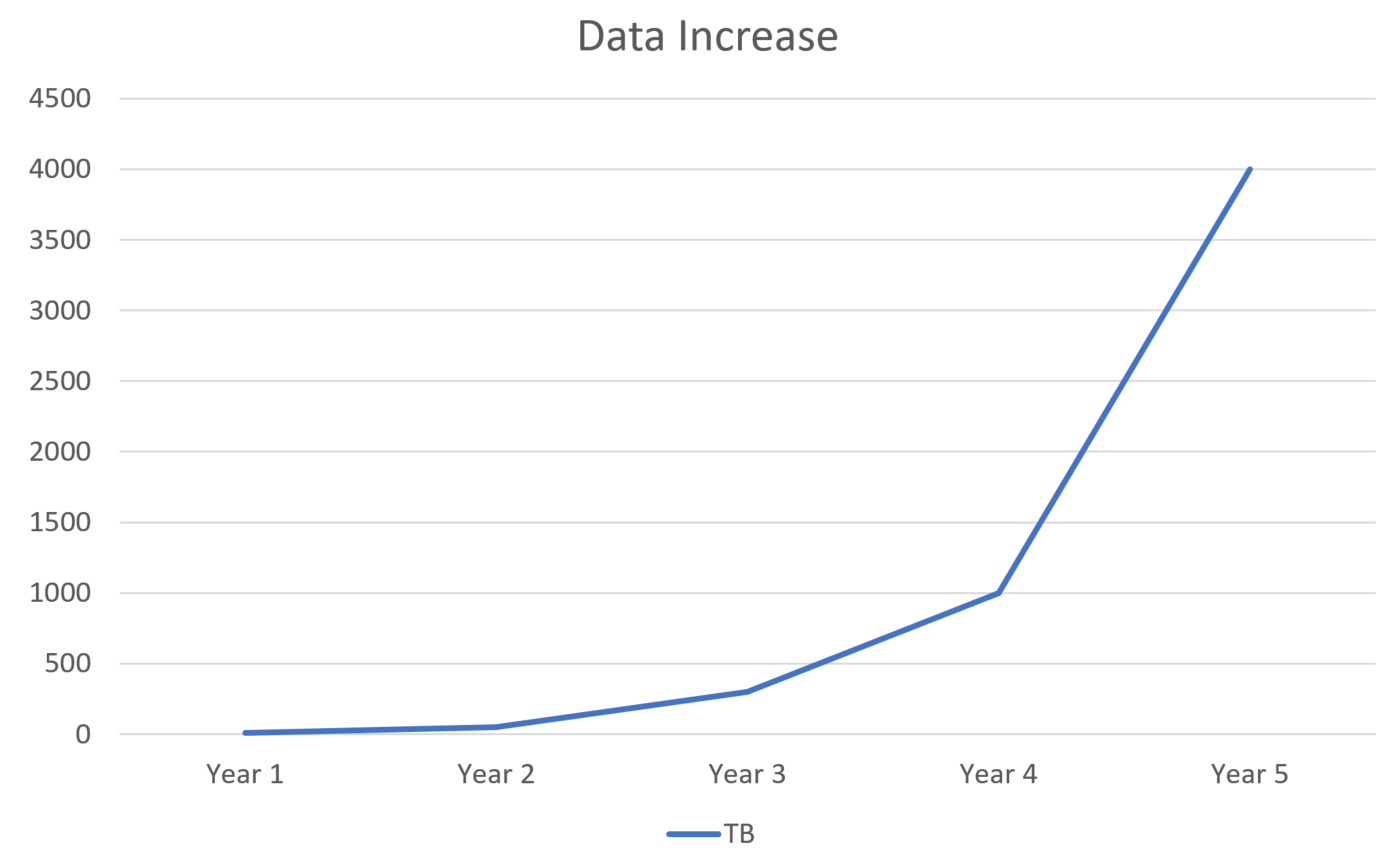
How you initially wrote your system to query specific data may not be ideal now that you have a vastly different volume of data. Queries may have performed fast a couple of years ago, but the volume of data now those queries could be much slower, impacting overall system performance.
Lifecycle
In many line-of-business and enterprise systems, not all data is actively relevant. Many business processes and workflows related to data have a finite lifecycle.
There is generally some initial beginning creation, some work in process, and finally, some completion.
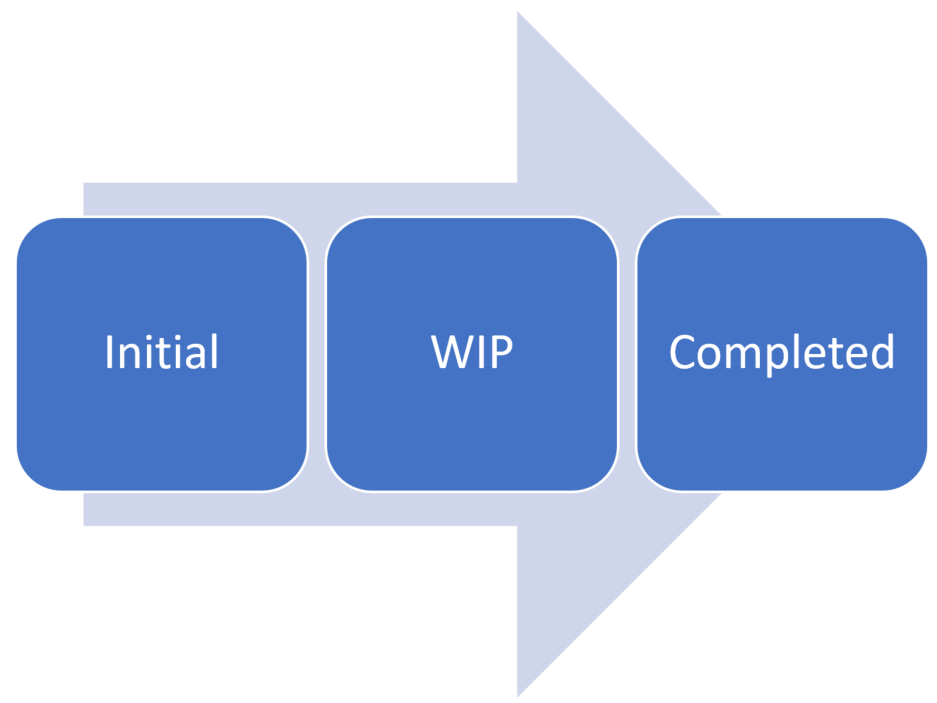
As an example, let’s use a support ticketing system. When a user opens a support ticket, it goes through a lifecycle till the support ticket is finally closed.
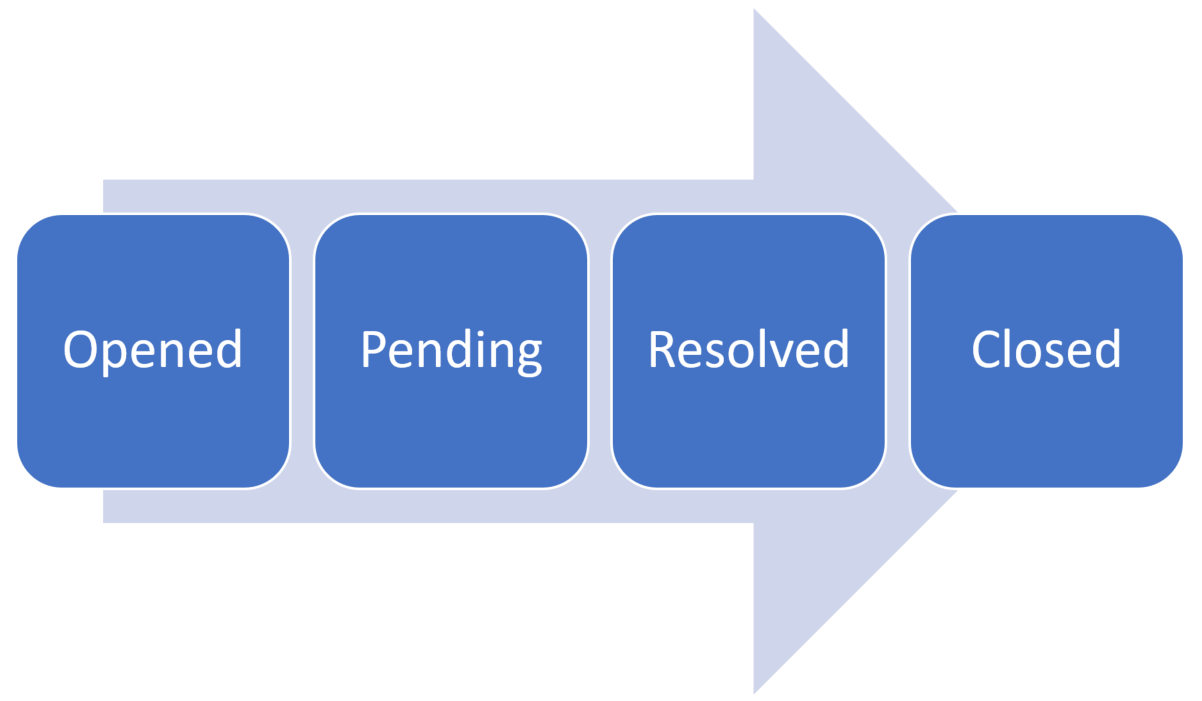
At this point, this support ticket is not likely very active in terms of interactions. A support ticket that was closed 2 years ago is not likely active at all, and users aren’t viewing them.
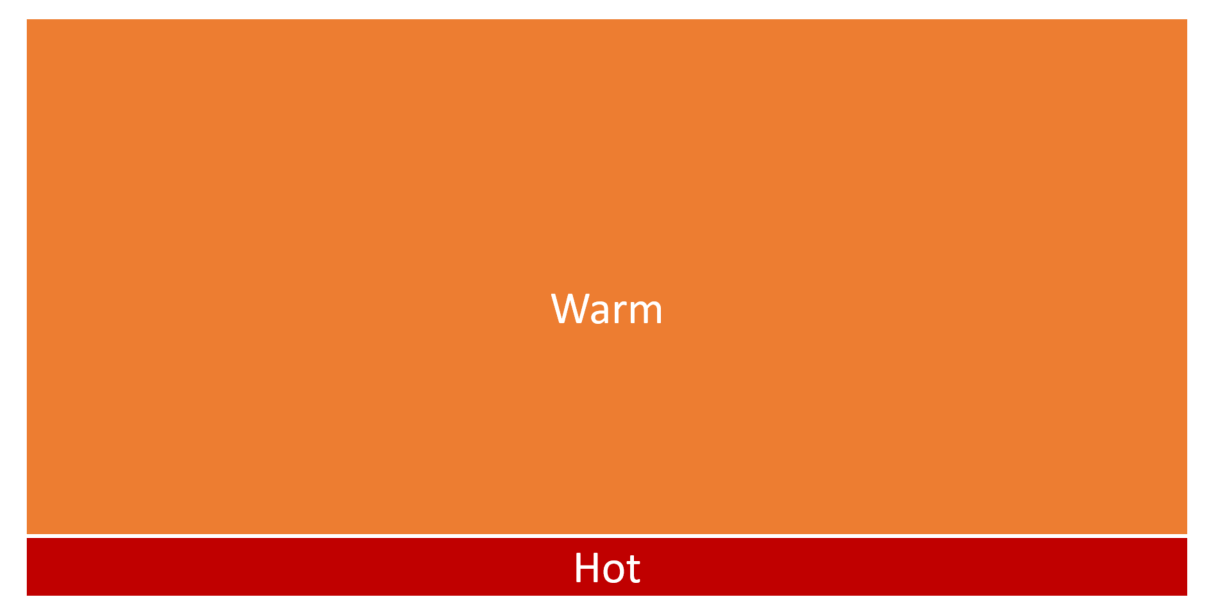
A small portion of the total data we store in our database is likely active/hot. Older data that its lifecycle has completed is still available to be queried or changed however; it’s more considered warm data that isn’t active.
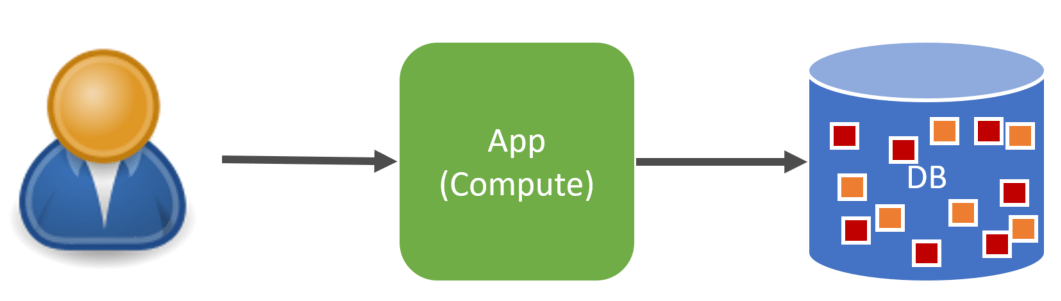
Without any type of partitioning, we have a mix of hot and warm data in our database.
Instead, we can organize our data by whether it is warm or hot and increase system performance because we deal with a much smaller dataset when performing actions against hot data.
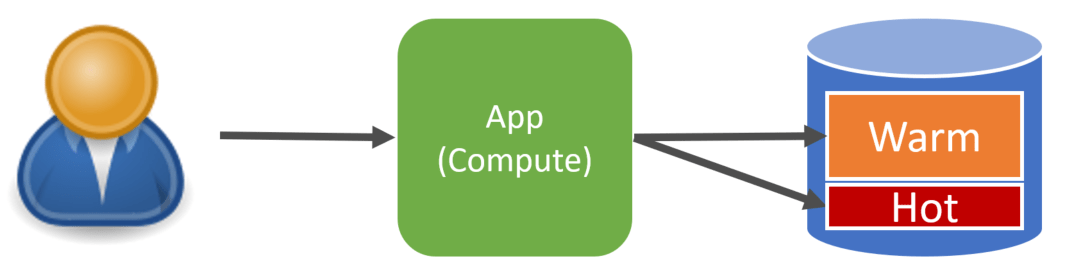
As for implementation, this could mean that when a ticket is closed, we move it to a separate table/collection or even a separate database. The strategy of when is up to you, but the gist is to segregate between hot and warm data.
Time
Another strategy which is often also hot/warm, is to partition by time. It is very typical in many different domains to have a time-bound partition. An excellent example is fiscal or calendar years for finance or employee pay periods, often weekly or bi-weekly.
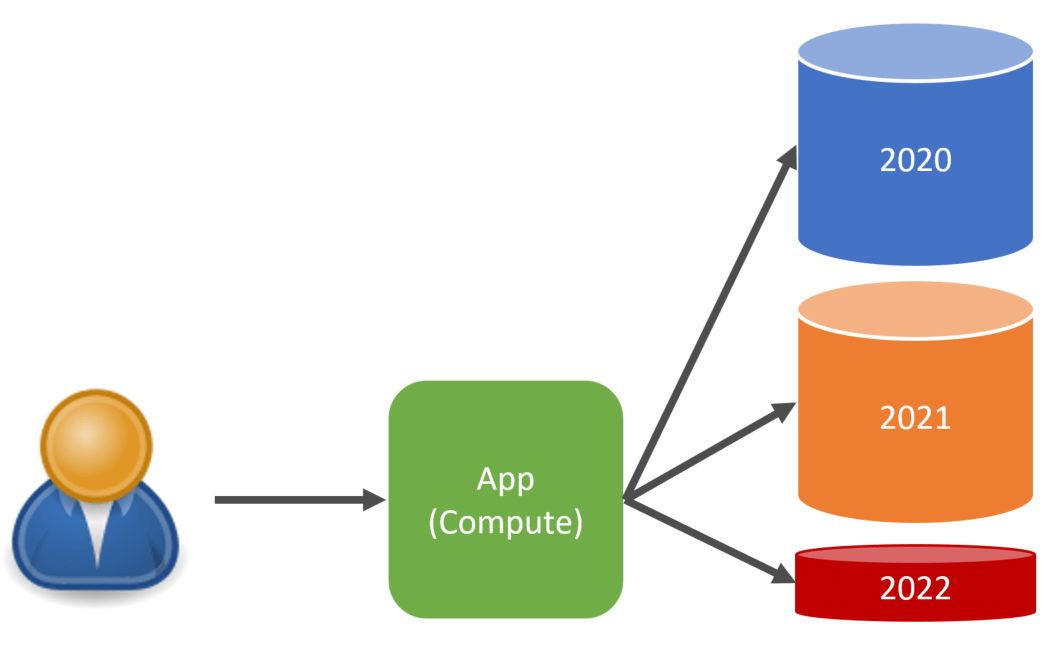
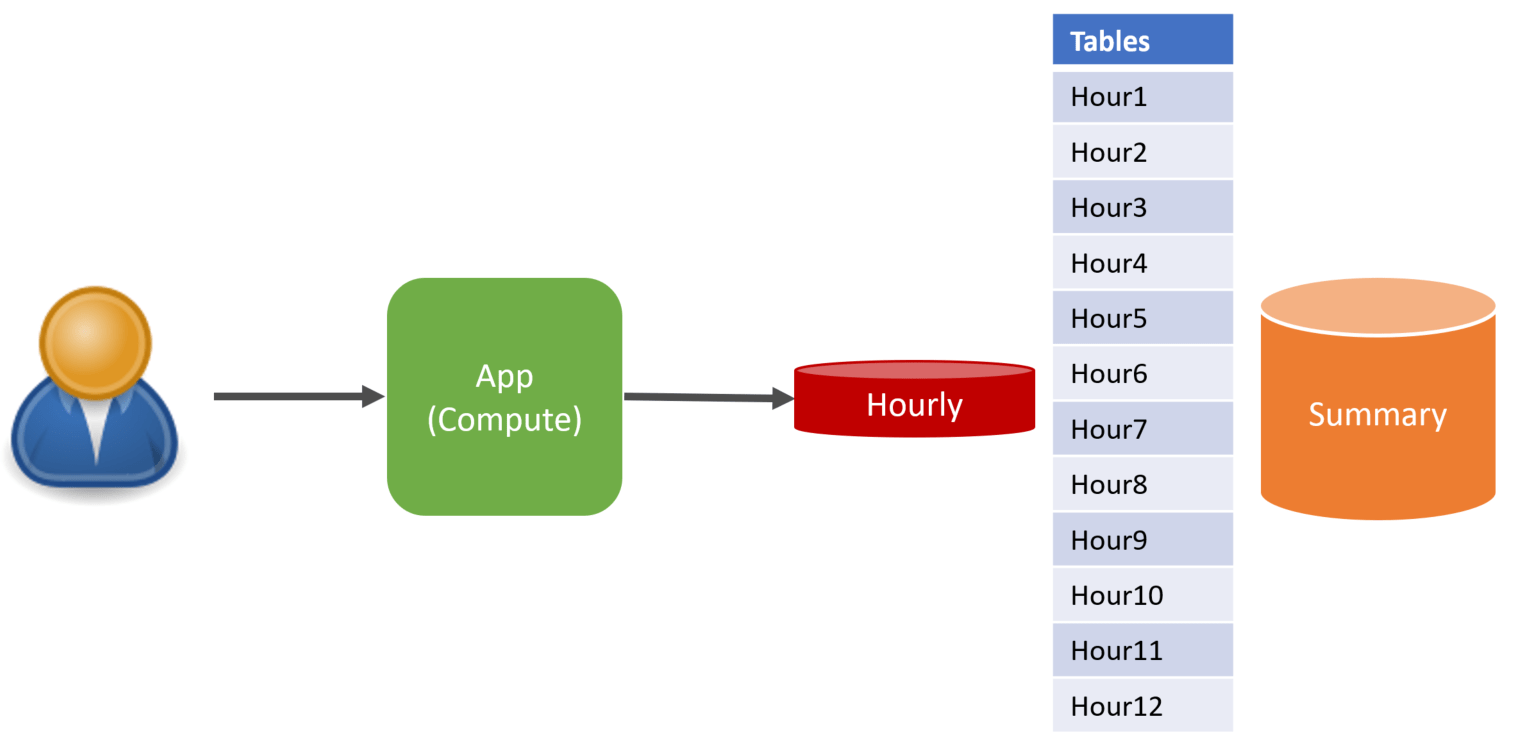
Summary
Often transactional data is only needed to summarize it, at which point the summary becomes the truth. I worked in a system with a high volume of transactional data partitioned by the hour of the day it was received. After each hour, the data were summarized and removed from the hourly table.
Often these are actual business concepts that you can capture. A warehouse with physical goods performs stock counts to confirm the actual quantity on hand that is recorded within the system. The database/system is not the point of truth; the warehouse is. Just because the database shows a quantity of 10 for a product does not mean there are 10 in the warehouse. A product could be damaged, stolen, or can’t be located. The transactional data of products received & shipped “should” be the quantity on hand. But it’s not. That’s why stock counts exist to reconcile what is in the warehouse.
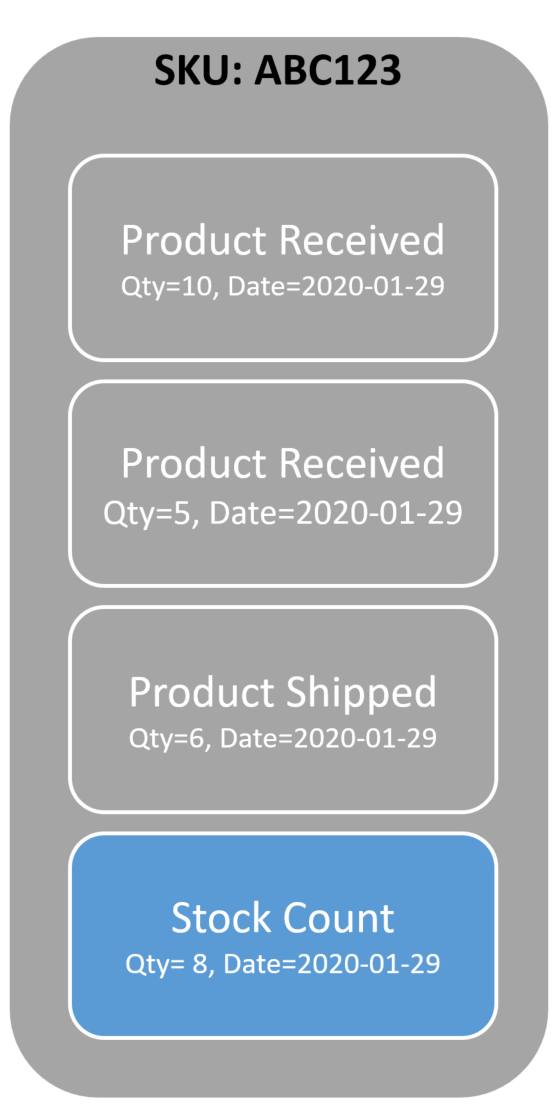
We can use these business events as a summary. The stock count is the summary event we can use. The other transactional events could be archived.
Cold Data
Speaking of archived, you do not need to delete data if you’ve summarized it. You can archive it as cold data. Data that is archived can be restored for compliance or regulatory reasons.
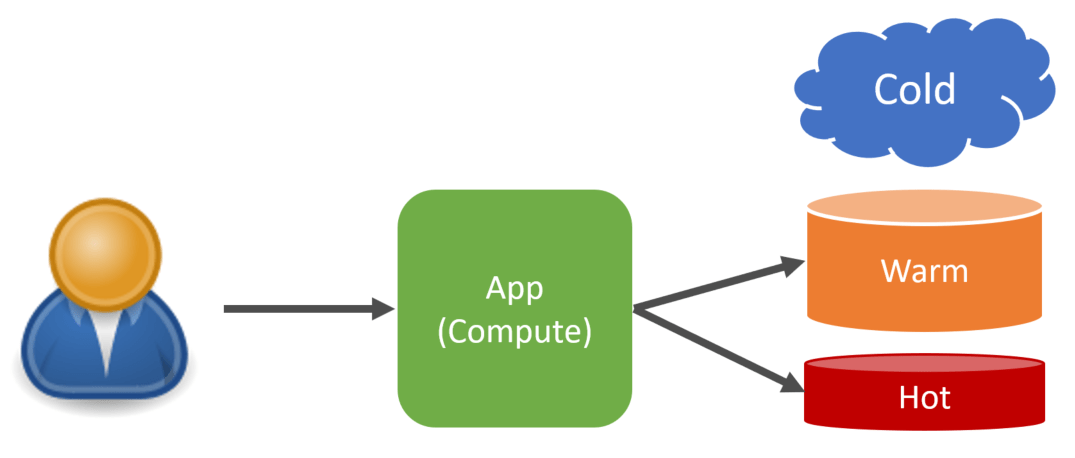
This data isn’t immediately available as it’s archived, and it is removed from warm and hot data storage.
Data Partitioning
Hopefully, this gave you some ideas about how can partition data over time as it grows. Time is a key aspect, as most business data is time-bound or goes through a finite lifecycle or lifespan. You can also leverage business concepts that inherently are summaries of a point in time where previous transactional data can be archived.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out the YouTube Membership or Patreon for more info.