Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
One primary reason for a data access layer or abstraction is your ability to change underlying databases easier. Have you ever replaced the underlying database of a large system or service? For example, moved from one relational database like PostgreSQL to MySQL. Or perhaps went from a relational database to a document or event store? There seem to be two groups of people. Those that have will say that abstracting the underlying database is crucial.
In contrast, the other group has never moved the database and questions abstracting or creating a data access layer because you likely won’t replace the database. Like many things in software architecture, it’s about coupling. If you limit coupling, this isn’t much of a hot topic.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Free for All
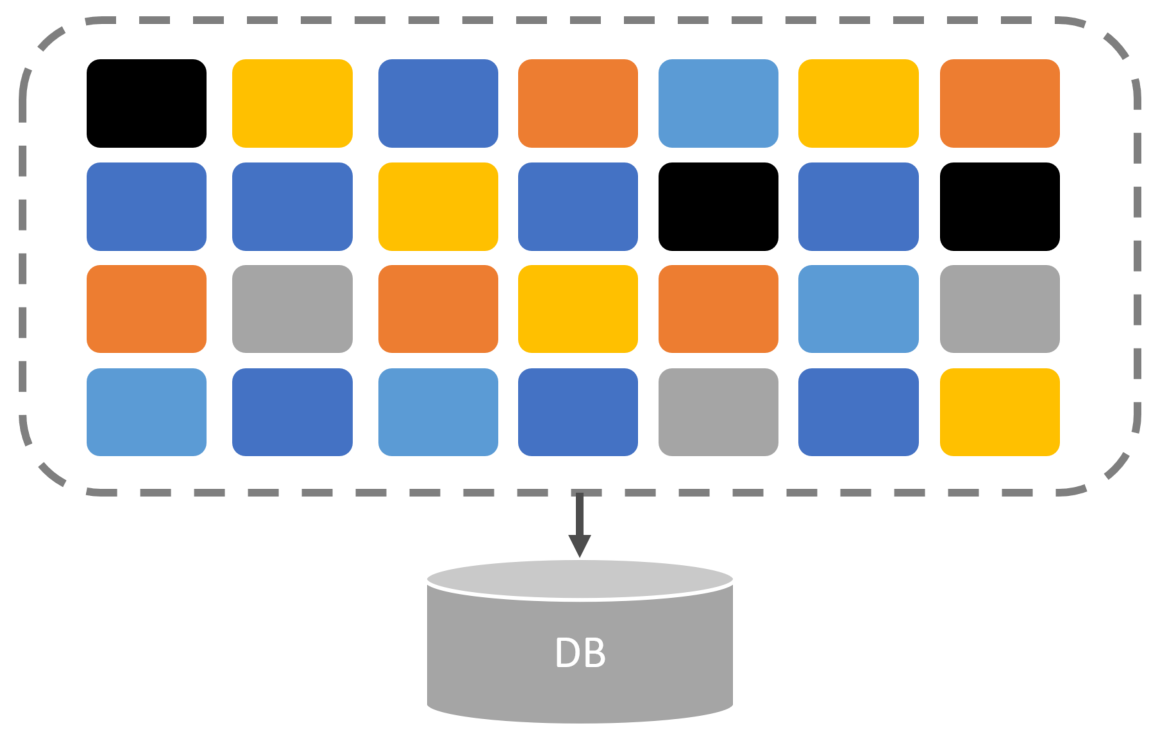
Let’s assume you have a large system or service with a lot of functionality that interacts with a single large database schema.

A block represents a piece of functionality. They all have direct access to the entire database schema. It’s a free for all. Any piece of functionality can access anything in the database. If the database was a relational database, this means all the tables. If you were using a document store, this could be all the collections. If you were using an Event Store, this is all the different event streams. Regardless of the database type, it’s free for all data access without data abstraction.
Does this sound like a nightmare? It would be. Because if you did need to change your underlying database technology, you’d have to go to every place that is doing data access and potentially rewrite it completely or modify it to work with the new database. This is much more involved if you change the database from relational to non-relational.
What’s most people’s answer to this problem? Abstraction. Create some layer of abstraction for your database to provide all the database access logic.
This could be a data access layer, using the repository pattern, or maybe just an ORM. Your application code and features then rely on this abstraction rather than coupling with the database directly.
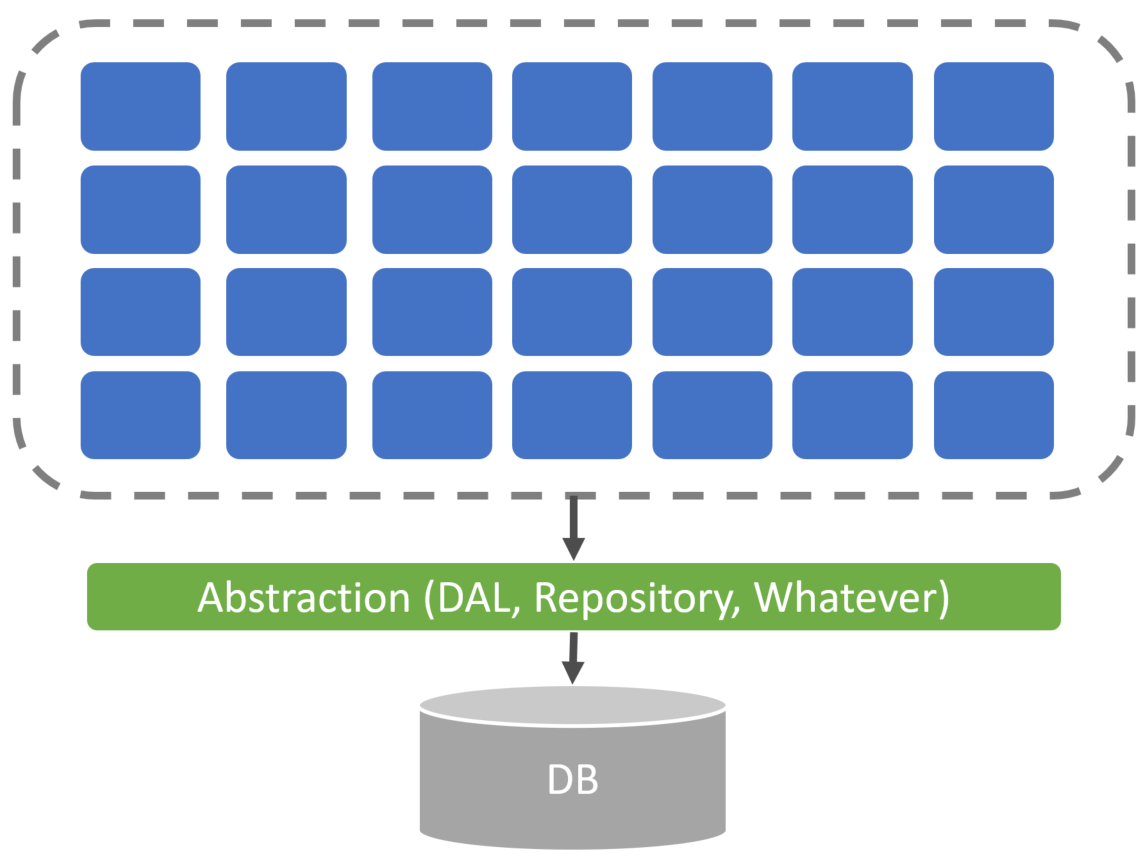
So now, if we need to change the database, we’re rewriting the data access abstraction that we created, and all of our application code, in theory, should stay the same.
Coupling & Cohesion
While adding the abstraction can be helpful, I don’t think that’s the right way to look at the problem. The root of the problem is a coupling. There is a high degree of application code that relies on the database.
While this is true, not all features within the application require access to the same data within the database.
If we’re talking about a relational database, not everything in our system needs access to all the tables. Certain pieces of functionality require access to a certain set of tables.
To reduce coupling, we need to look at cohesion. What functionality in our system requires what data? We should then group this functionality.
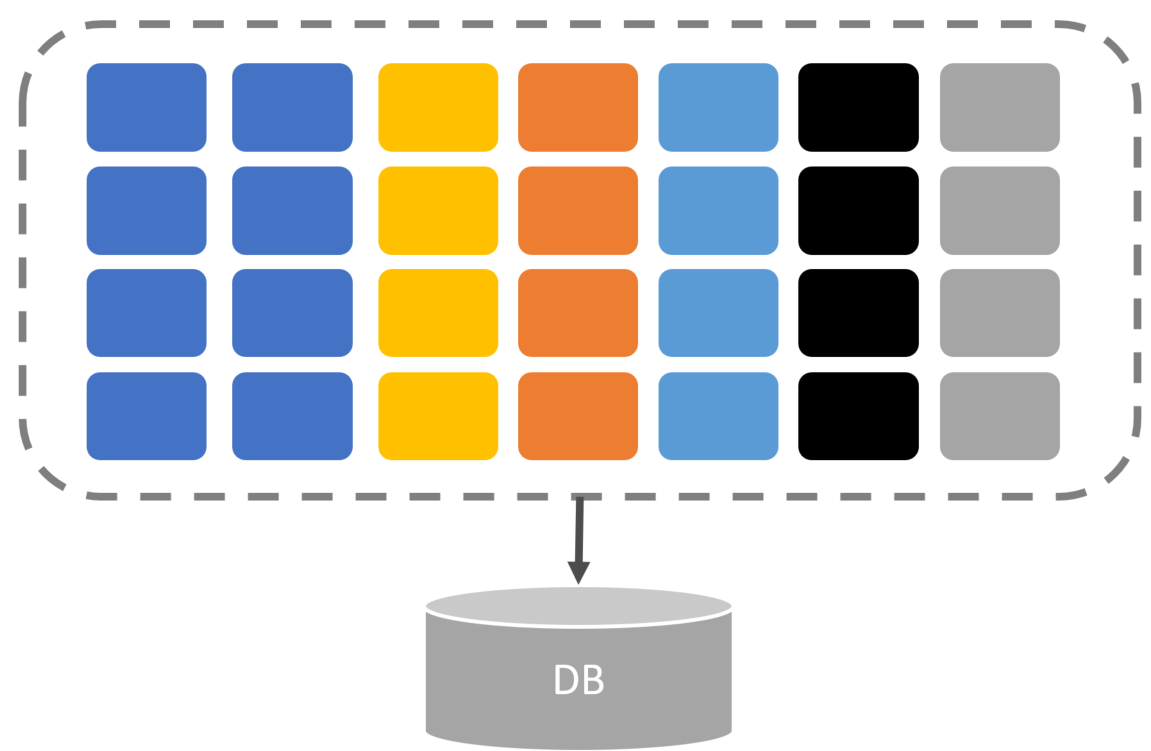
Start segregating functionality by related features working on the same subset of data. Again, not all features need to access the same large schema/data. Define boundaries over data ownership.
Once you start defining boundaries and grouping functionality, you’ll soon realize that each grouping might be able to define how they handle data access. This means that for some sets of features, you decide to use a specific ORM, while for others, you do direct data access without much abstraction.
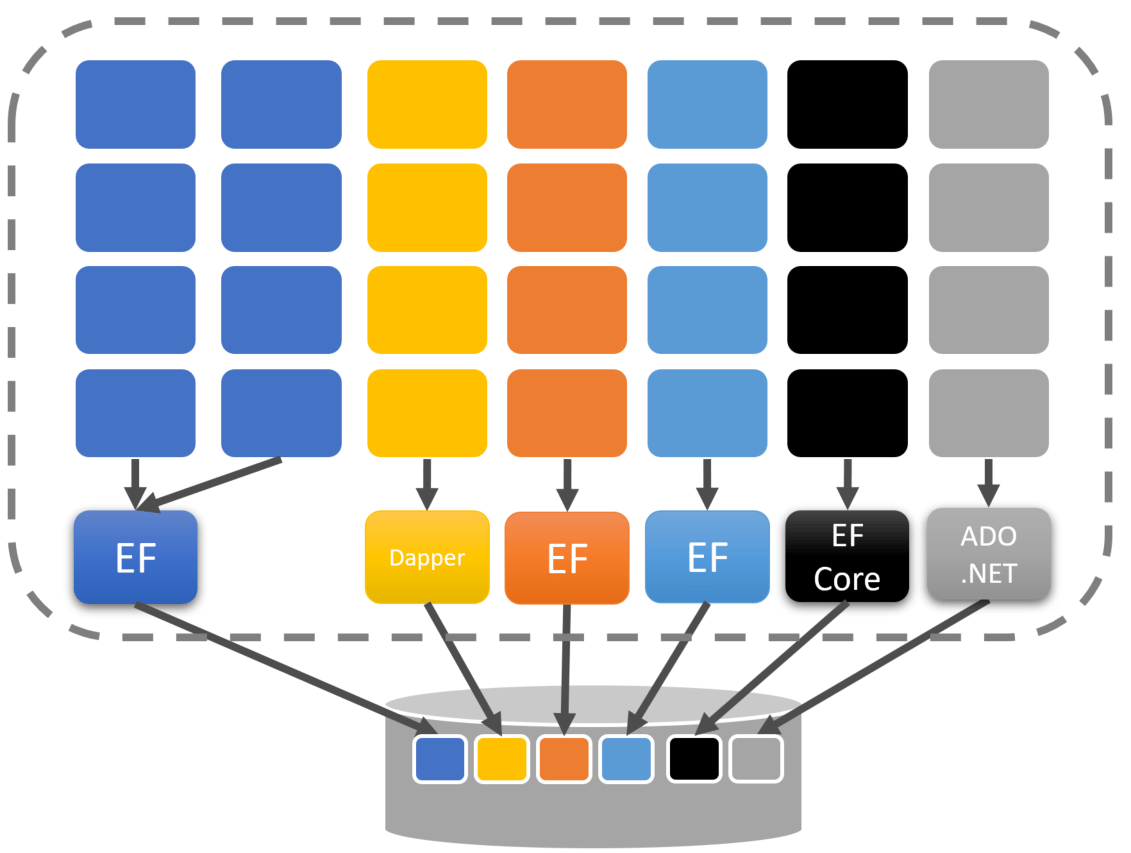
You’ve reduced coupling by increasing cohesion. This allows you to decide how you want to perform data access per set of features.
There is no more free-for-all of data access. Each set of features only access parts of the database it owns. One set of features should not access the data owned by another set of features.
You might start to see now that each feature set can also decide how data is persisted in which type of database. Maybe some feature sets use a relational database, while others use an event store. You can make these localized decisions per feature set (boundary)

Since the entire application/system is now split and grouped into boundaries defined by functionality and data ownership, you don’t have free-for-all of data access. Often you do need to query other boundaries to get reference data. In the free-for-all scenario, you simply query the database to get that data. However, now you must expose an API that other boundaries can consume, like a contract.
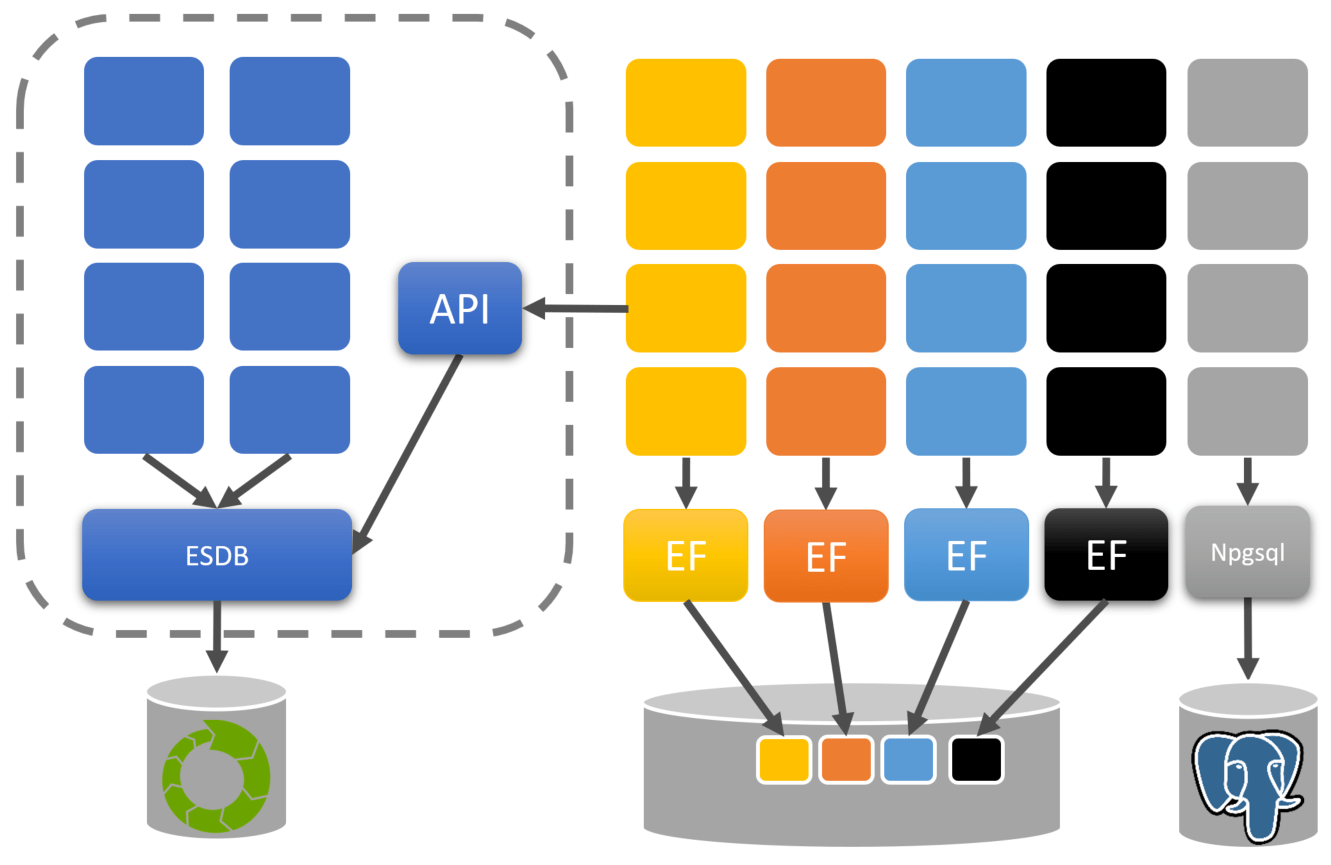
This can be an interface, delegate, function, etc., in which you’re coupling between boundaries. However, the data returned from this API isn’t mutable. It’s purely used as reference data. All state changes to any data must occur within the boundary that owns the data.
Data Access Layer
This has nothing to do with creating a data access layer or abstracting data access. It has everything to do with coupling and cohesion. If you limit coupling and prevent integration at the database (as in data access free-for-all), then needing to change the underlying database is a matter of changing a narrow set of features within a boundary.
Will you change your underlying database? It doesn’t matter. A high degree of coupling will make any change difficult in a large system. Defining boundaries by functional cohesion and limiting coupling will allow a system to evolve.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out the YouTube Membership or Patreon for more info.