Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Is a shared database a good or bad idea when working in a large system that’s decomposed of many different services? Or should every service have its own database? My answer is yes and no, but it’s all about data ownership.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Monolith
When working within a monolith and generally a single database, you can wrap all database calls within a transaction and not think too much about failures. If something fails, you roll back. You can get consistency by using the right isolation level within your transaction to prevent dirty reads (if needed).
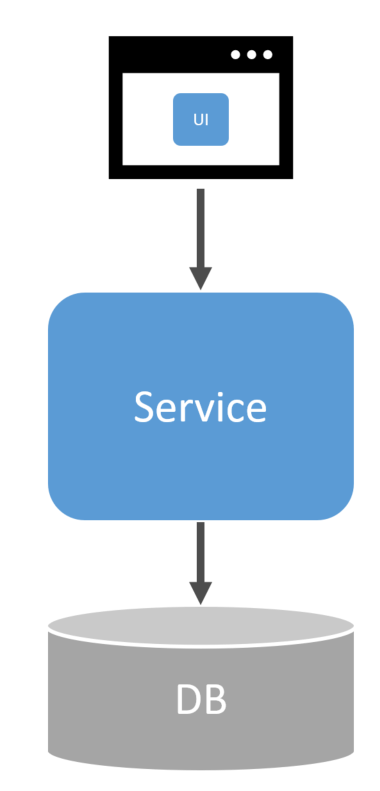
One challenge with a monolith is that it’s a single database; it’s often a free for all data access. Reads and writes are performed from anywhere within the monolith. Most often, a monolith for a large system will have a pretty large overall schema of hundreds of tables/collections/streams.
Because this leads to so much coupling, people tend to then go down the route of trying to define services that own certain parts of functionality within the system. However, they don’t separate the underlying data and keep a shared database.
Distributed Turd Pile
This often leads to what I call a Distributed Turd Pile. Or also known as a distributed monolith or a distributed big ball of mud.
The application has been split up into multiple services, but there is still a shared database where both services perform reads and writes. There is no schema or data ownership.

If you need to change a table/document and add a new column/property, which services do that? If different services are owned by different teams, which team is responsible for doing so? If you make a change, every other service now needs to be aware of that change, so it doesn’t break them.
Ultimately in a distributed turd pile, you’ve siloed the functionality but still have a massive schema that’s a free for all with no ownership.
Physical vs. Logical
When I originally asked, can you share a database between services? You’d guess my answer based on the above would be no, which is correct when talking about it from a logical perspective. Services should logically own their schema and data.
Physical boundaries aren’t logical boundaries, however. This means that you can have ownership of schema and data but still keep that within the same physical database instance as another service.
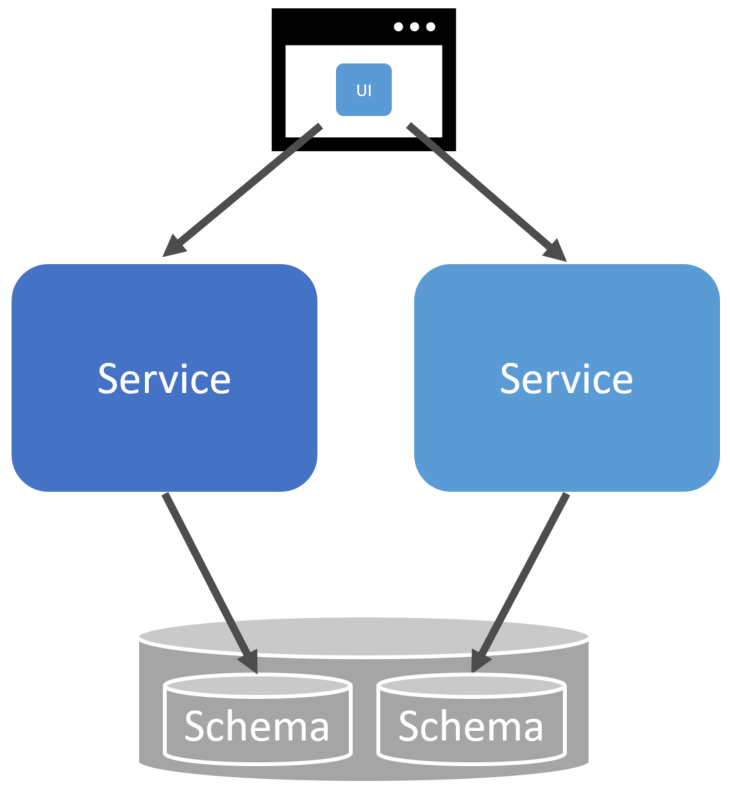
This means that a single shared database instance can hold the schema and data for different services. This isn’t free for all of data access. Only the service that owns the schema can access it and perform reads and writes.
It’s about logical separation, not physical separation.
You don’t have to have a physically separate database instance for each service. This can be helpful in various scenarios, from a local developer to staging to even production if you have limited resources. Should use share the physical instance, maybe not if one service could consume a lot of the resource/capacity of the instance (noisy neighbors). Context matters; your situation matters. The point is, don’t confuse physical and logical boundaries as being the same.
I touch on this more in a blog post Microservices gets it WRONG defining Service Boundaries.
Query & UI Composition
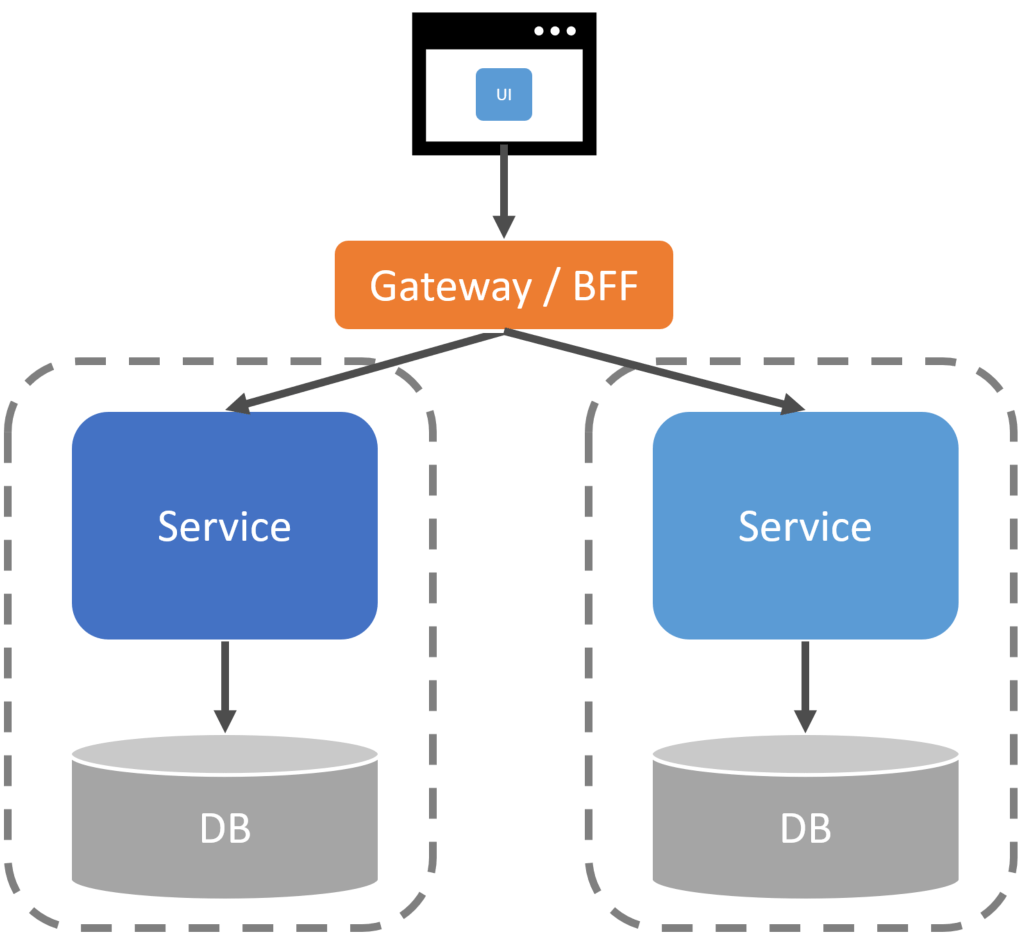
If services have schema and data that can’t be accessed directly by other services, how do you do any type of UI or Query Composition?
One option is to create an API Gateway or BFF (Backend for Frontend) responsible for making the relevant calls to the required services and doing the composition to return to the client.
Another option is to use Event Carried State transfer to give services a local cache copy of reference data that can be used for UI composition.
When a service makes some type of state change, it will publish an event containing the state of the entity that changed.
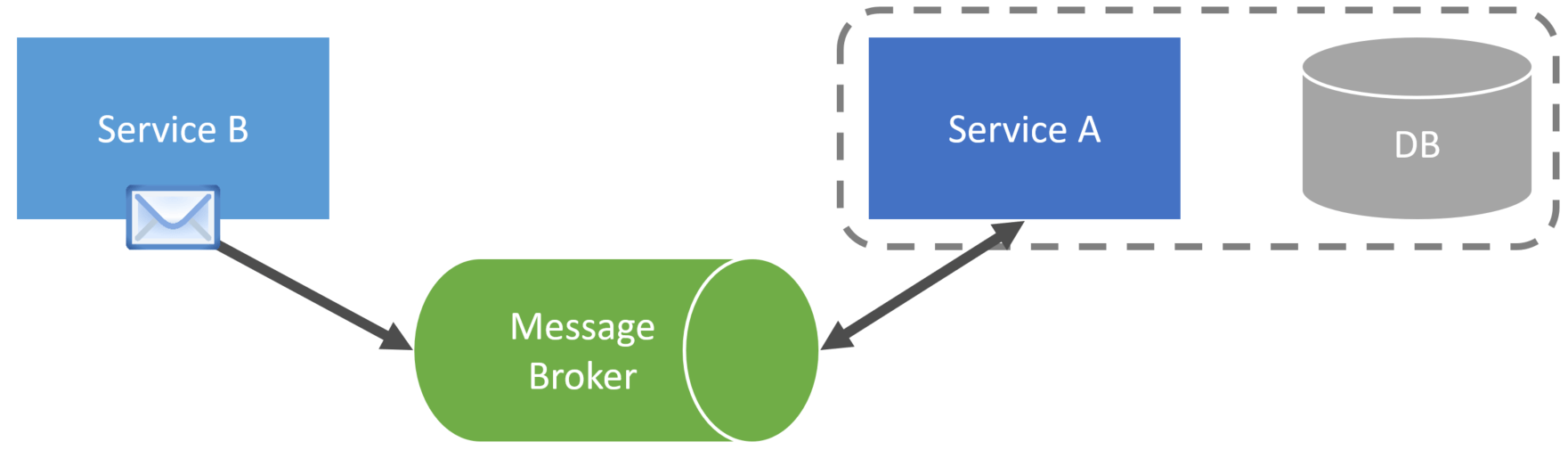
Other services can consume that event, update their local database, and use it as a cache.

I do not recommend doing this for workflow or any business process. This isn’t for transactional data. This is for reference data that is often more in a supporting role of your system. This data isn’t volatile and fits well to be cached for this reason.
Lastly, another option for UI composition is to do it on the client itself. Each service can own a piece of the UI.
Consistency
It’s important to touch on consistency. Using a local cache when executing a command means using stale data. There is no difference between making an API call from service to service to get data to perform a command and getting it from a local cache. They are both going to be inconsistent when executing a command. Why? Because the moment you get back a result from a service-to-service call or a local cache, the data is stale.
If you need consistency, you need data owned by the boundary that requires consistency.
I often find that some ownership confusion is due to how workflows are thought of. I often see workflows created to a single boundary when it may involve many different boundaries.
As an example, let’s say you have an ordering checkout process. The first call from the client would be to the ordering service. This likely would return a CheckoutID if it wasn’t already defined by the client.
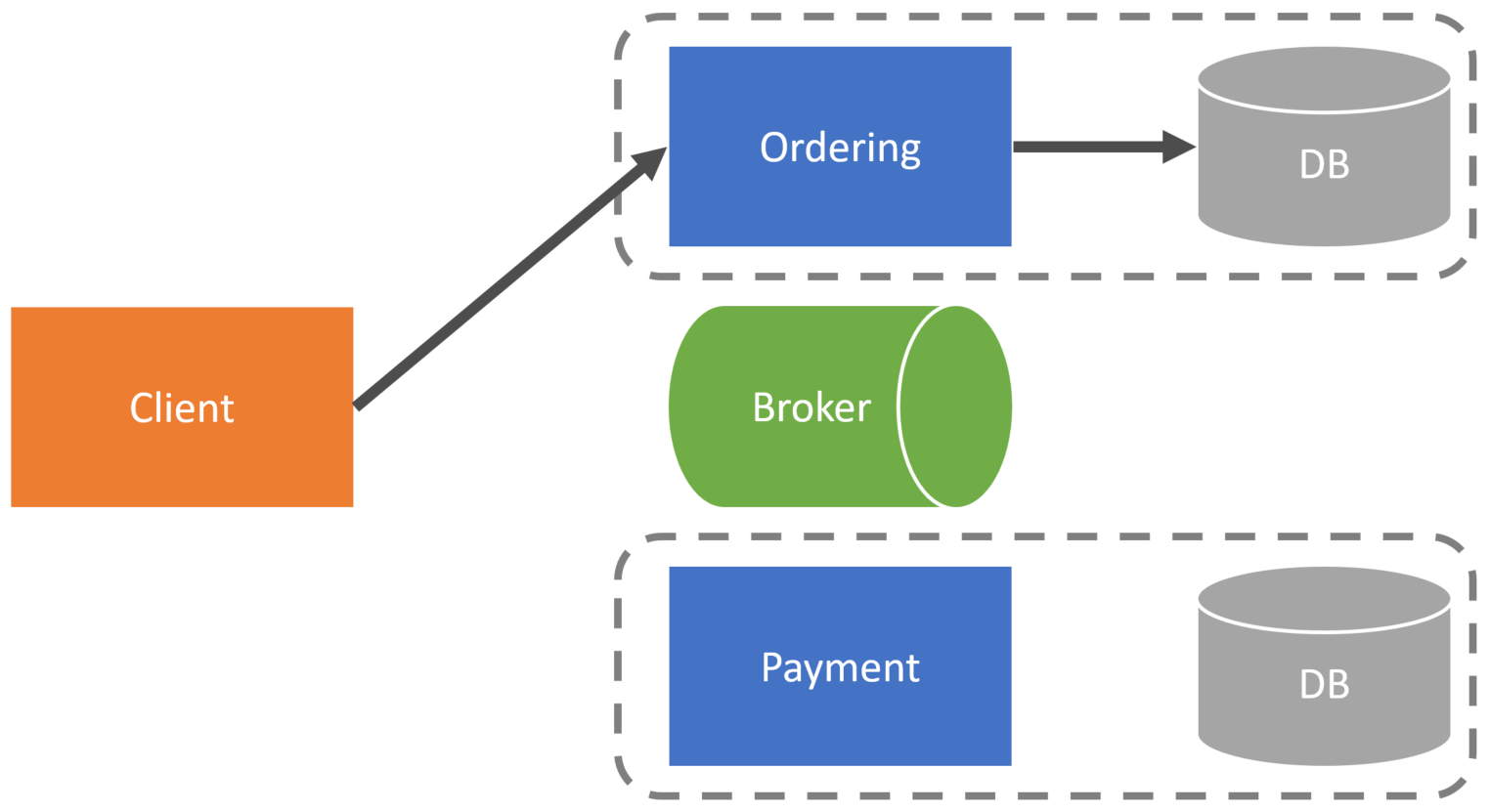
Next, the client would send the credit card information to the payment service with the same CheckoutID.
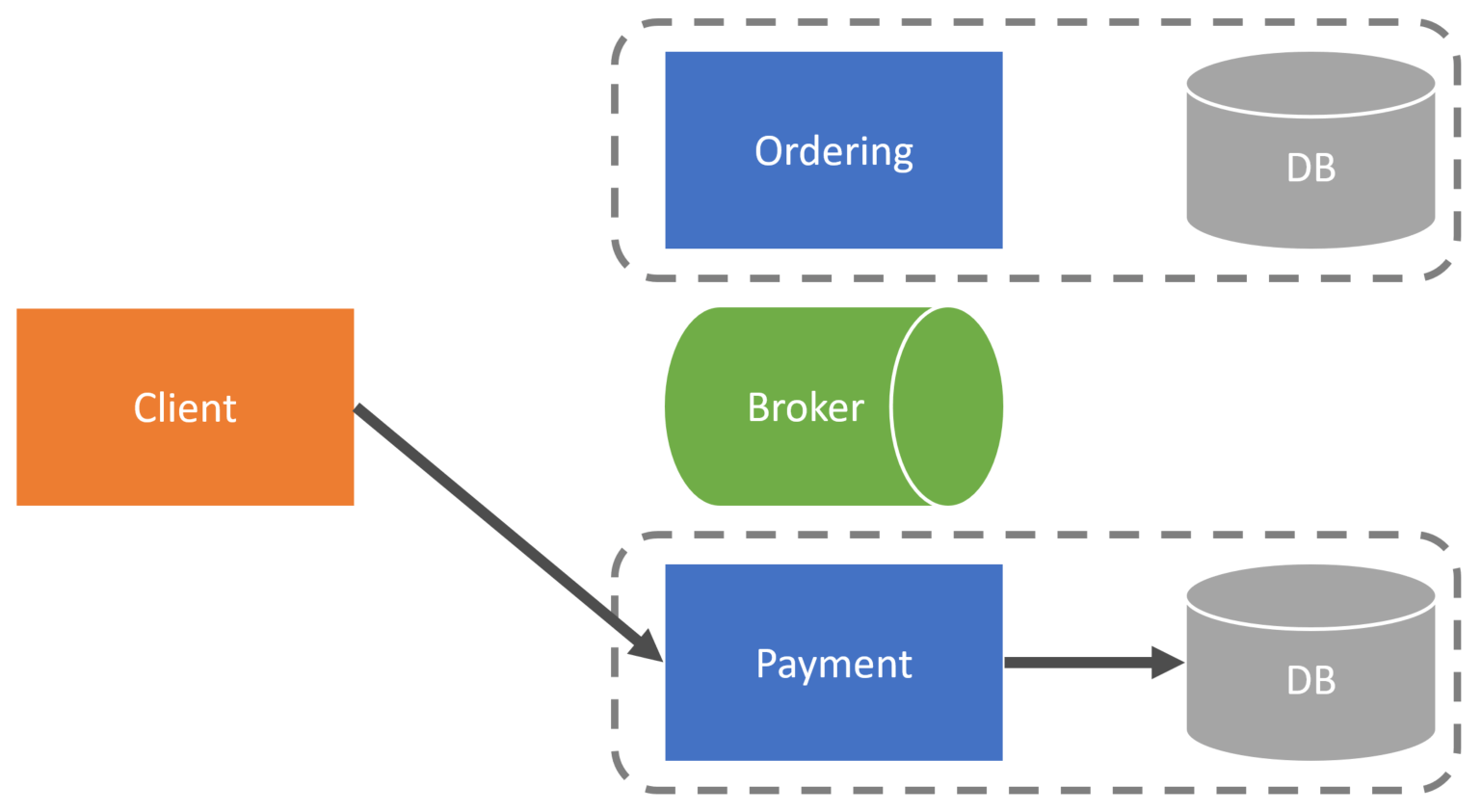
Finally, the client reviews their order by sending a request to the Ordering service to Place Order. The ordering service would make relevant state changes to its database and then publish an OrderPublished event or perhaps send a ProcessPayment command.

The payment service would consume this message and then use the credit card data it already has within its database to charge the customer and hit a payment gateway.
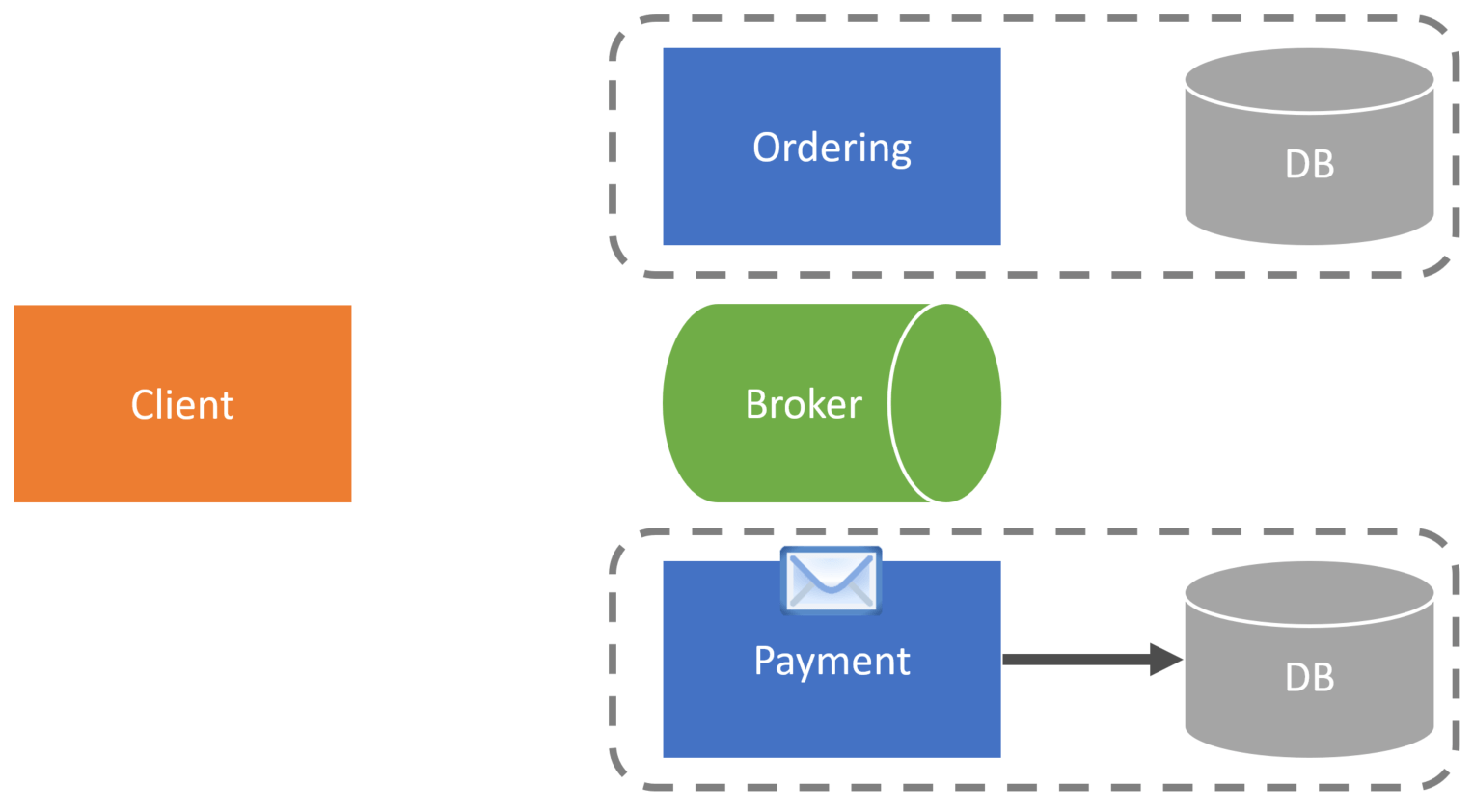
Shared Database
Can you share a database between services? Yes and no. You can share the physical database instance but not the schema and data. A service should own schema and data and only expose it via explicit contracts of an API or Messages. Don’t have data access free for all.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out the YouTube Membership or Patreon for more info.