Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
McDonald’s uses Event-Driven Architecture! Luckily for us, they’ve written a couple of blog posts providing some details of their journey into event-driven architecture. I’m going to go a bit deeper by providing my thoughts on how their system works and why they are doing it so that it can give you some ideas about your systems.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
McDonald’s Event-Driven Architecture
It’s always interesting to see companies post details of the architecture of various systems they have. It can be insightful to see what they are doing, why, and their challenges. McDonald’s posted behind-the-scenes and how-it-works blog posts detailing their journey to event-driven architecture. More specifically, it’s not that they are new to event-driven architecture but rather have a standardized way to implement it with distributed teams of developers with different skill levels.

There are many different components to their platform. Their infrastructure is within AWS, and they use MSK (Managed Streaming for Kafka) along with ECS, DynamocDB, and API Gateway.
Here’s how everything works together.
Schema Registry
One of their challenges was related to data quality. Likely because there was no set definition (schema) for data within events. If multiple producers produce the same event type, they might not be composing them exactly the same. I believe an event should have a single publisher, the owner of that schema, to avoid this issue. However, this could be applicable in a message-driven architecture that’s also using queues and commands.
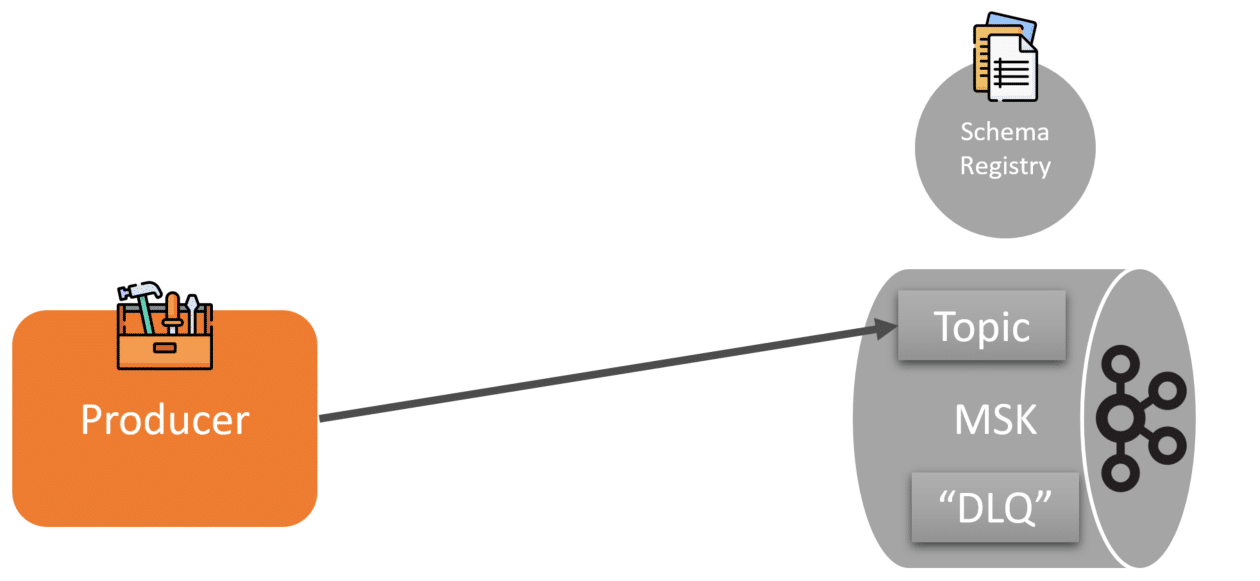
Producers at startup use a custom SDK that retrieves all the event schemas from the registry. This allows the producer to validate the event being produced against the schema.

If validation passes, the producer can publish this event to the appropriate Kafka topic using the SDK at this point.
As you can expect, on the consumer side, the same thing occurs. Consumers at startup use a custom SDK that retrieves all the schemas from the registry, just like the producers do.
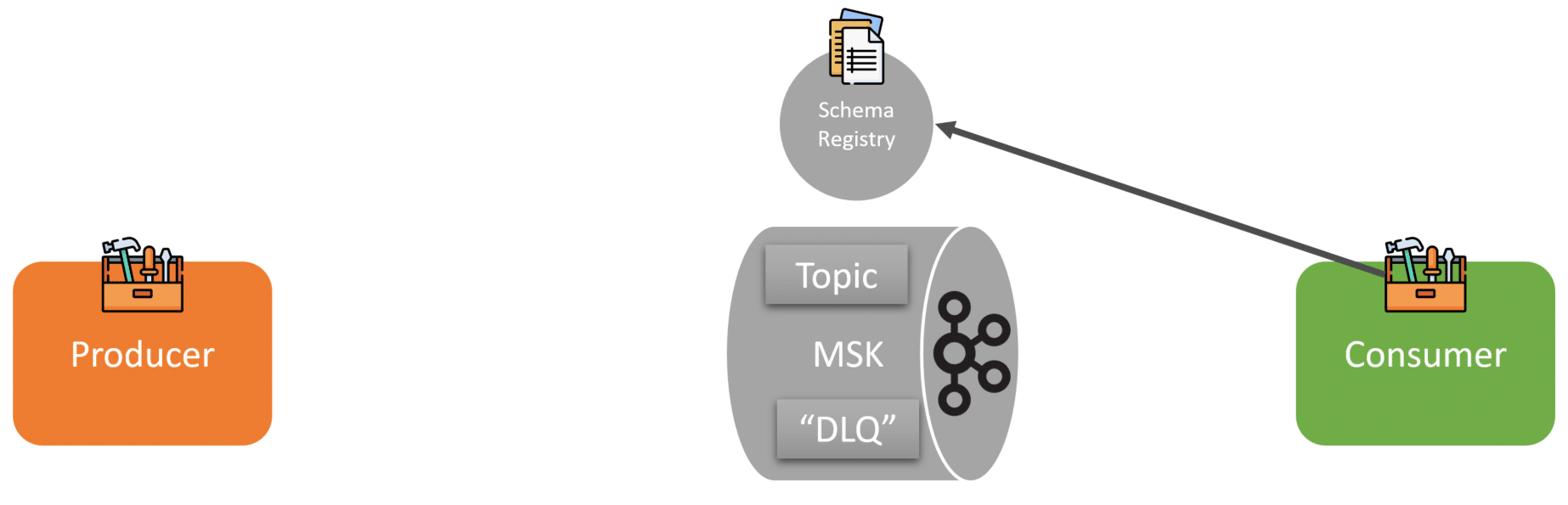
Then the consumers can process messages from the Kafka topics and understand how to deserialize them from the schema and version of the schema.
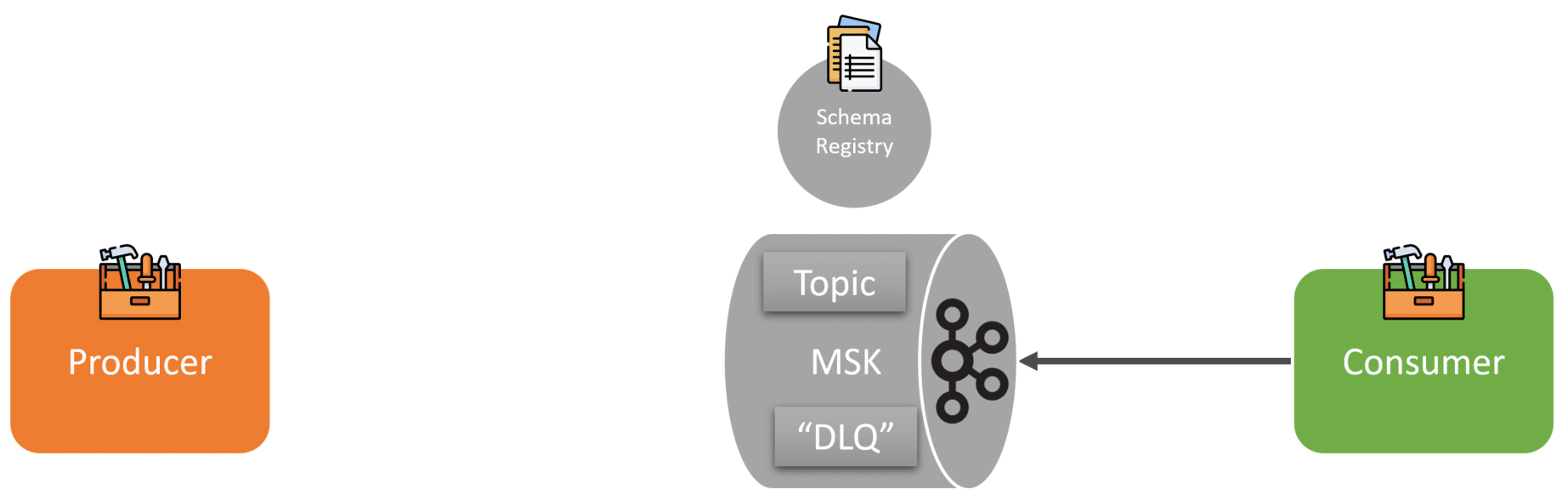
Everything within any Kafka topic should be valid based on all the schemas (versioned) within the registry. Data quality issues are solved!
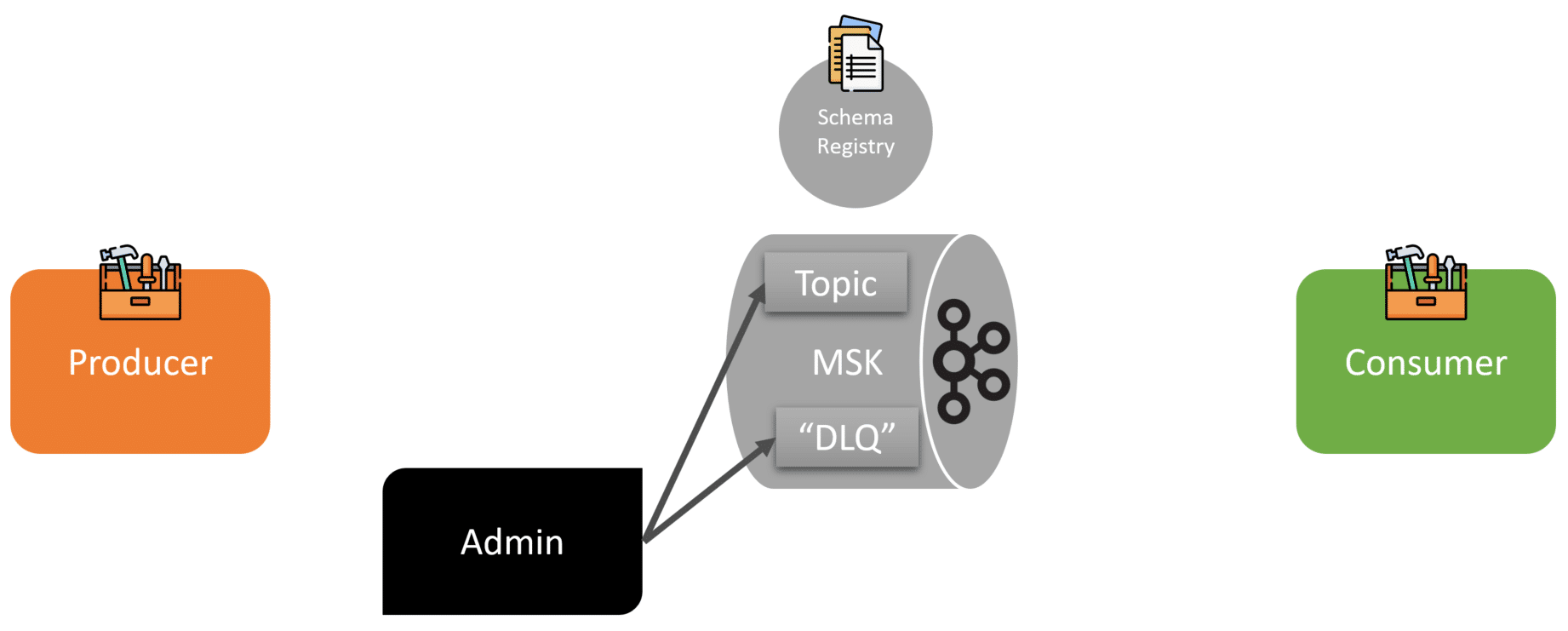
Validation
Of course, not everything goes through the happy path. What if a producer tries to publish an event, but it fails to validate against the schema? The producer then publishes the message to a Dead Letter Queue. Kafka isn’t a queue, so this is a Dead Letter Topic.
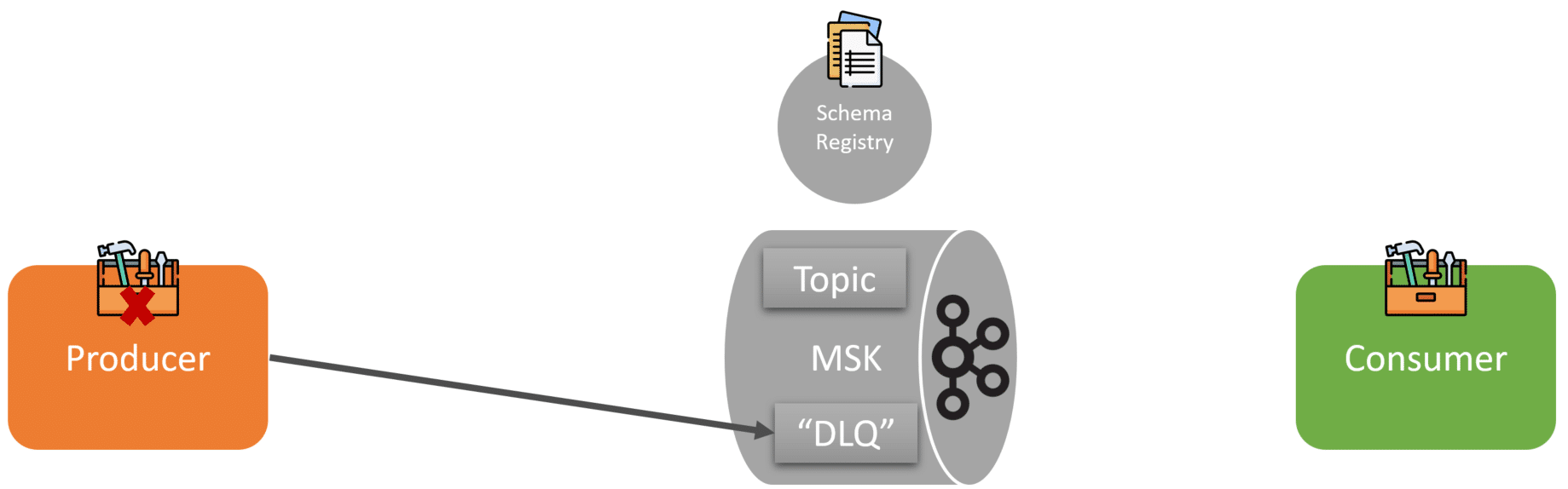
Once a message is in the “DLQ” there needs to be a way to view, modify and fix the event so it can be re-published to the correct topic.
For this, an Admin/Utility UI provides this functionality for them.
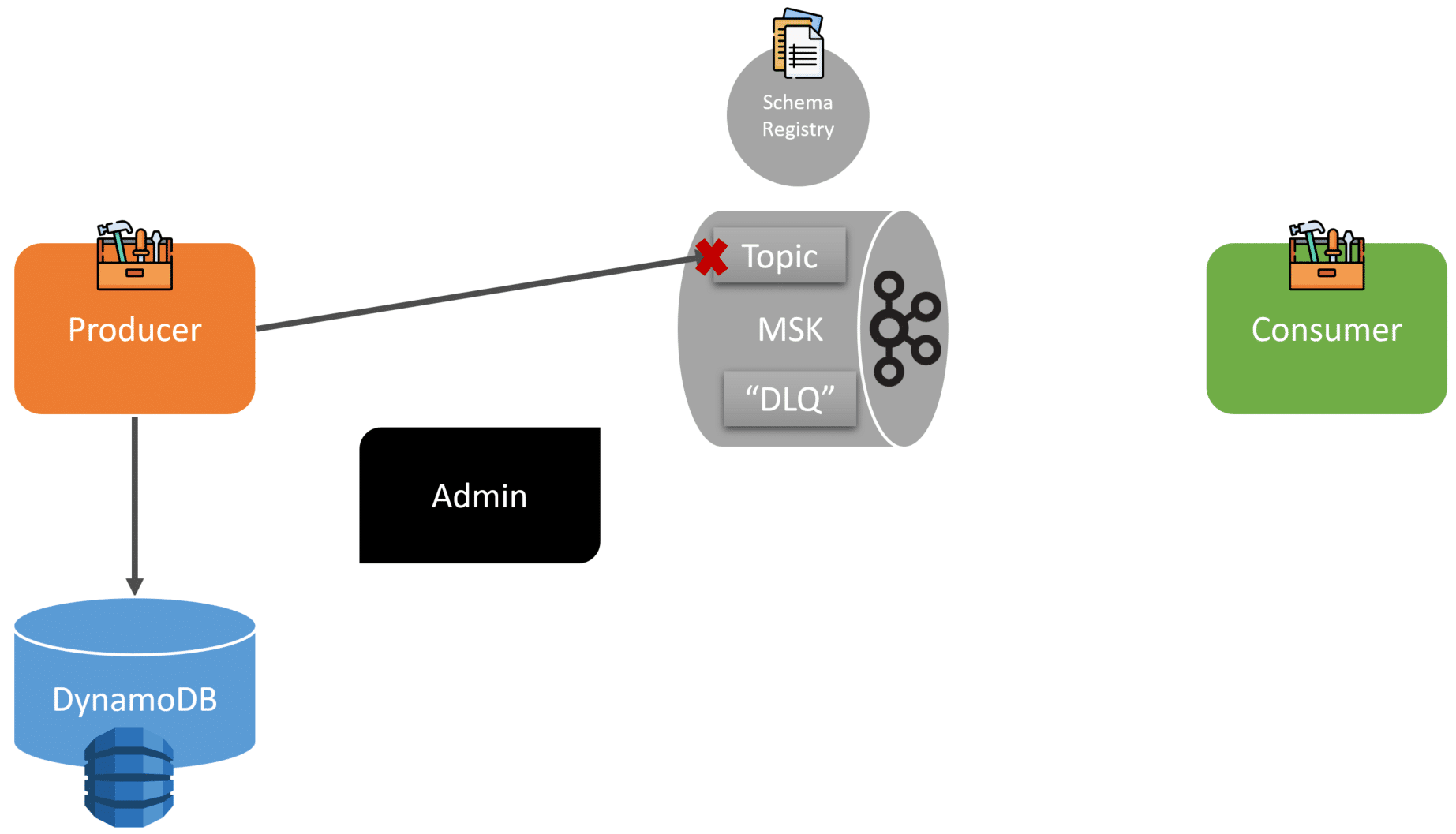
Reliable Publishing
The second failure that can occur is failing to publish to Kafka (MSK). Anyone getting involved in Event-Driven Architecture is bound to run into this. It would be best if you had consistency between making state changes to your business data and publishing your event. When events become critical to your system and possibly workflows, you need guarantees that you publish the relevant events when you make some state change to business data.
Mcdonald’s chose to use DynamoDB to persist any events that cannot be published to Kafka. This means their Publisher SDK will fallback to storing the event data within DynamoDB if it cannot publish to Kafka.
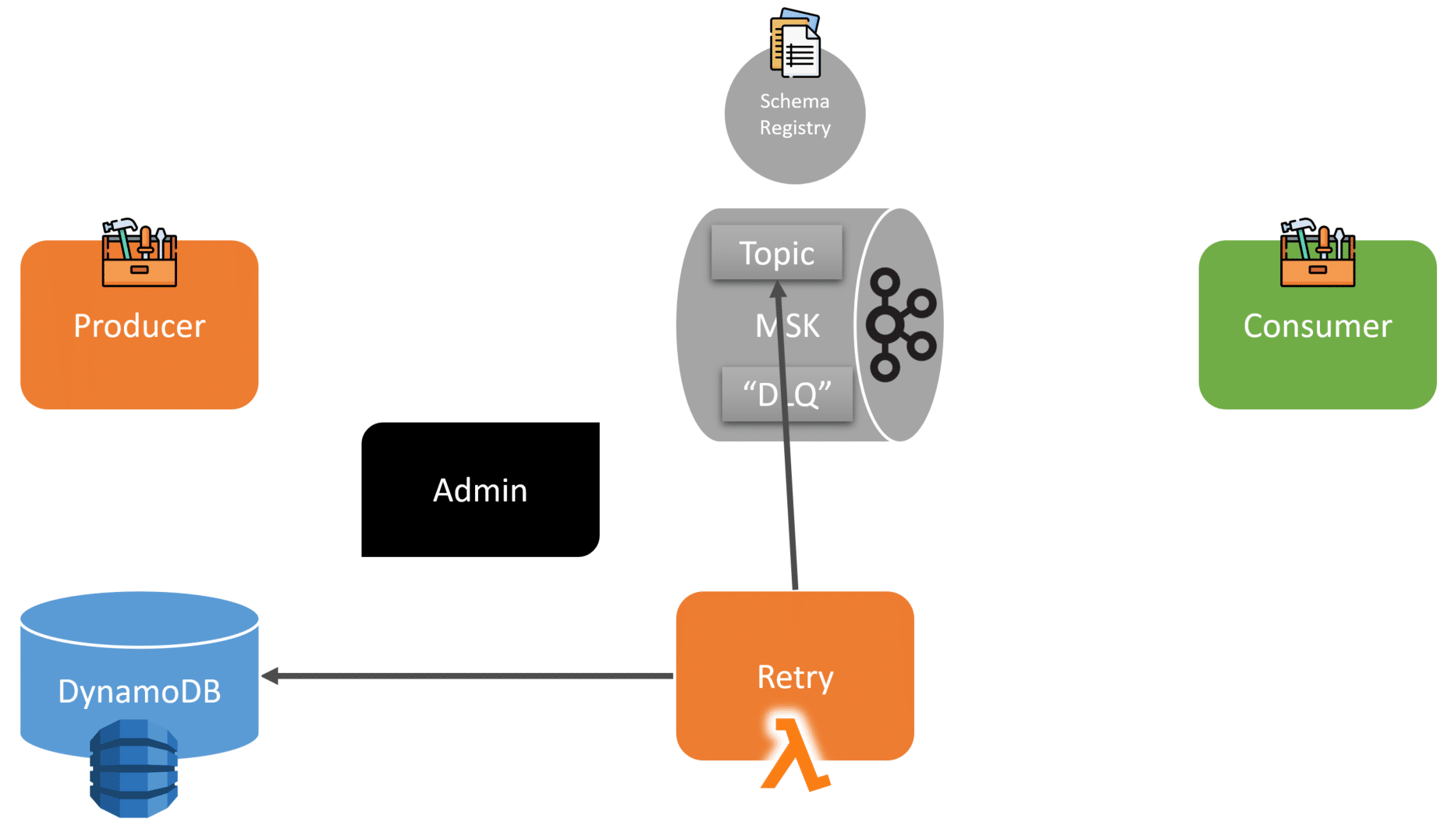
Using a fallback to some durable storage is a common approach. However, the Outbox Pattern is another common solution. I discussed this and other common issues in a post about the 5 Pitfalls of EDA.
Once the event data is in DynamoDB, they use Lambda to pull it from DynamoDB and then retry and publish it to Kafka. I’d assume they have different retry intervals/backoffs.
Gateway
Lastly, if you’re integrating with 3rd parties or even within a large organization, you’ll need to have them publish events. However, they won’t have direct access to your SDK and Kafka. For this, they use API Gateway as an HTTP interface to convert HTTP requests that will communicate with the Producer that has the SDK and can publish to Kafka.

That way, we go through the same validation against the schema in the registry just as if any of our client code is using the producer SDK. This allows external 3rd parties to publish events without using our SDK directly. We can instead have them use our Event Gateway (HTTP API).
Technical Blog Posts
I love when companies have technical blog posts that give insights into their architecture and design. It’s hard to know the full context, but seeing how they solve these issues they run into is interesting. Companies face many common issues when using Event-Driven Architecture, but all have unique constraints.
If you have any recommendations for other technical blog post analyses, please let a comment!
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.