Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Wix.com migrated from a request-reply RPC style system to an event driven architecture and, not surprisingly, ran into a few issues. One of the developers wrote a blog post outlining five event driven architecture pitfalls they experienced. Here’s my review of that post, and hopefully sheds more light on their problems and solutions.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Reliable Publishing
When using an event driven architecture, you’ll be publishing events as a communication mechanism to other parts of your system. You’re telling other parts of your system that something occurred. That “something” is generally that some state change or side effect has occurred.
Other parts of your system can then become dependent on events being published when certain things occur, mainly if various parts of your system are used in a workflow or business process driven by events.
For example, when a payment is processed in the Payment Service, a PaymentCompleted event is published to Kafka. The Inventory Service consumes the PaymentCompleted event and decreases inventory levels based on the Order.
What happens if you make a state change to MySQL, but fail to publish an event to Kafka?
In their example, they process a payment and persist it in MySQL, but it fails to publish the PaymentCompleted event. This means that now the inventory is inconsistent with paid Orders.
One solution to this is using the Outbox Pattern. I’ve covered it in another blog post, but the gist is that you persist your events with your business state in the same transaction into your primary database. Then separately, often in another process or thread, you publish the event. If the event is published successfully, you then delete that event from your primary database.
Another option they chose is to have separate durable storage for the events in case of a failure to publish to Kafka. Then you would publish the events from that fallback durable storage. It’s a similar concept, except it’s not guaranteed since saving state and your event to separate durable storage isn’t atomic (no distributed transaction).
Event Sourcing
One widespread misconception is that Event Sourcing involves using the events as a mechanism for state and for communicating with other service boundaries. Conflating these two ideas can cause a whole lot of complexity.
Event Sourcing is about using events as a way to persist state. Using events that represent state transitions. This has nothing to do with publishing these events as a mechanism for communication with other services.
Events in Event Sourcing are implementation details within a single service boundary. They are internal.
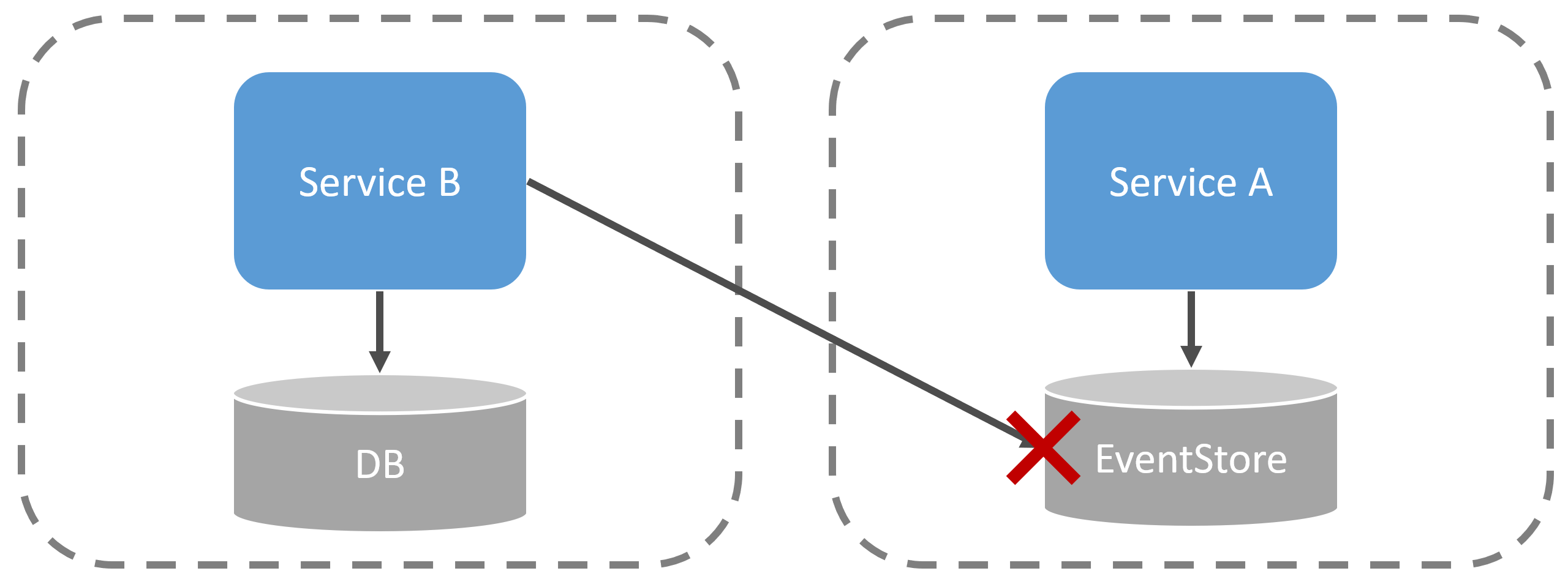
This means you can choose to use event sourcing and not publish events for other services to consume.
You could also choose not to use event sourcing for any service and publish events for other service boundaries to decouple.
Don’t conflate the two concepts of state and communication.
Distributed Tracing
Another challenge, which is getting better over recent years, especially with OpenTelemery, is a visualization of a workflow when in an even driven architecture.
It isn’t easy to understand all the different services involved when you’re decoupled through publish/subscribe. The entire point is decoupling, which makes it difficult to see the causation and correlation. You have services consuming events and publishing events.
When event choreography is involved, it can be challenging to see the start and end of a workflow. What if something failed mid-way through? How do you know some business process isn’t completed or is in a “hanging” state? You need visibility. Check out my post on Distributed Tracing using OpenTelemery and Zipkin.
Claim Check
Large messages aren’t good. They can be a problem because they can overwhelm your broker or event log, such as Kafka. Meaning you don’t want to have to transfer large message payloads over the wire for every consumer from the broker. Generally, you want to keep event/message payloads small, but how would you do that if you have a message that contains a large image?
The Claim Check Pattern solves this by having the message/event reference where the full contents are.
As an example, a large image may be persisted in blob storage. The event/message will contain an identifier that the consumer will use to know where to locate the file in blob storage. This way, the consumer can retrieve the large payload (image) from blob storage rather than from the message itself.
Check out my post on the Claim Check Pattern for more.
Idempotent Consumers
Duplicate events will occur. This means that consumers need to be prepared that might consume the same event more than once. There are various reasons for this happening, including a different event with the same payload published. Another reason can be the Outbox Pattern mentioned above.
Using my outbox pattern example, if the PaymentCompleted event is consumed by the Inventory service more than once, it will deplete the inventory levels more than they should.
You want your consumers to be idempotent. You want to handle the same event without having a negative side effect.
How you implement this greatly depends on the types of events you publish. If you’re publishing Change Data Capture (CDC) or “Entity Changed” events, you’d want to have a versionId on each event that indicates which version of the entity was when the event was published. This way, consumers can keep track of which version they have and only process the event if it’s newer than their current version.
I generally try to avoid these style events and focus more on domain events involved in workflow. A unique ID associated with every event can be tracked to know if you’re processing an event more than once.
Check out my post on creating Idempotent Consumers for more.
Event Driven Architecture Pitfalls
While Event Driven Architecture is a great way to build a robust system that is decoupled, it has a lot of gotchas and pitfalls that you need to be aware of. Hopefully, this post provides some more insights so you don’t have to figure it out all on your own! All of the problems you’ll run into have solutions/patterns have are well-established and have been around for a long time.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.