Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
How do you handle processing large payloads? Maybe a user has uploaded a large image that needs to be resized to various sizes. Or perhaps you need to perform some ETL on a text file and interact with your database. One way is with a Message broker to prevent any blocking from calling code. Combined with the Claim Check Pattern to keep message sizes small to not exceed any message limits or cause performance issues with your message broker.
The pattern is to send the payload data to an external service or blob storage, then use a reference ID/pointer the blob storage location within the message sent to the Message Broker. The consumer can then use the reference ID/pointer to retrieve the payload from blob storage. Just like a Claim Check! This keeps message sizes small to not overwhelm your message broker.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything that is in this post.
In-Process
As an example, if a user is uploading a large file to our HTTP API, and we then need to process that file in some way, this could take a significant amount of time. Let’s say it’s simply a large text file where we need to iterate through the contents of the file, extract the data we need, then save the data to our database. This is a typical ETL (Extract, Transform, Load) process.
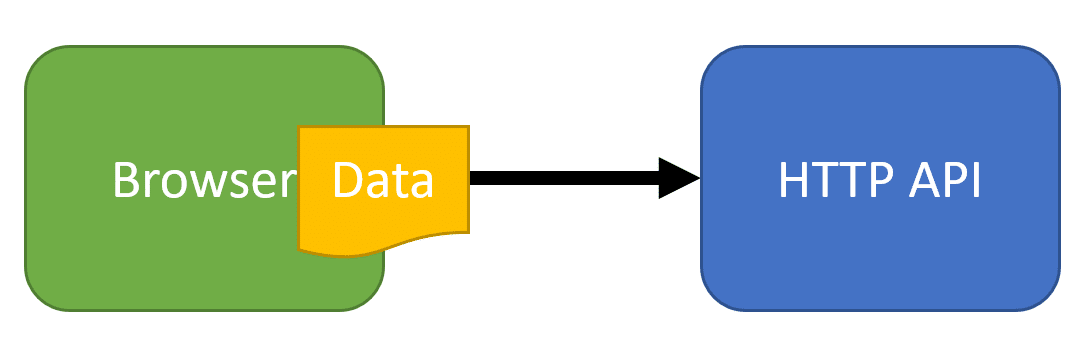
There are a couple of issues with doing this ETL when the user uploads the file. The first is that we’ll be blocking the user while the ETL occurs. Again, if this is a long process the could take a significant amount of time. The second issue is that if there are any failures throughout processing, we may partially process the file.
What I’d rather do is accept the file in our HTTP API, return back to the user/browser that the upload is complete and the file will be processed.
Out of Process
To move the processing of the file into another separate process, we can leverage a queue.
First, the Client/Browser will upload the file and our HTTP API.

Once the file is been uploaded, we create a message and send it to the queue of our message broker.

Once the message has been sent to the queue, we can then complete the request from the client/browser.
Now asynchronously a consumer can receive the message from the message broker and do the ETL work needed.

Large Messages
There is one problem with this solution. If the file being uploaded is large and we’re putting the contents into the message on our queue, that means we’re going to have very large messages in our queue.
This isn’t a good idea for a few reasons. The first is that your message broker might not even support the size of messages you’re trying to send it. The second is that large messages can have performance implications with the message broker because you’re pushing a large amount of data to them, and then also pulling that large message out. Finally, the third issue is that your message broker may have a total volume limit. It may not be the number of messages but rather the total volume that has a limit. This means that you may only be able to have a limited number of messages because the messages themselves are so large.
This is why it’s recommended to keep messages small. But how do you keep a message small when you need to process a large file? That’s where the claim check pattern comes in.
First, when the file is uploaded to our HTTP API, it will upload the file to shared blob/file storage. Somewhere that both the producer and consumer can access.
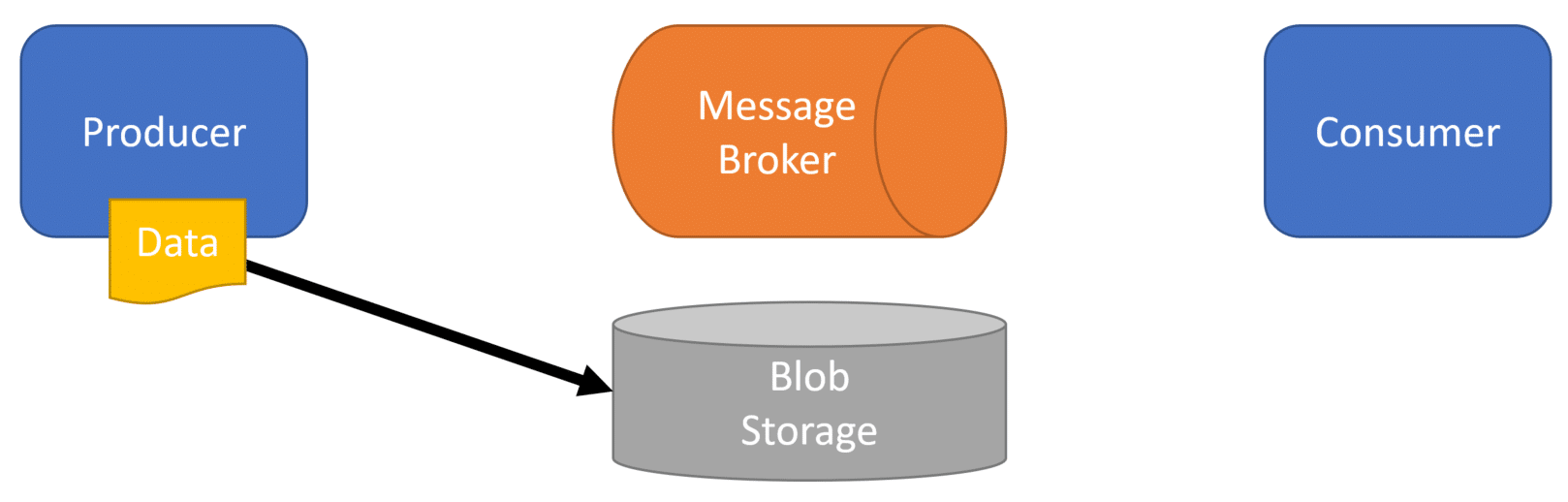
Once uploaded to blob/file storage, the producer will then create a message that contains a unique reference to the file in blob/file storage. This could be a key, file path, or anything that is understood by the consumer on how to retrieve the file.
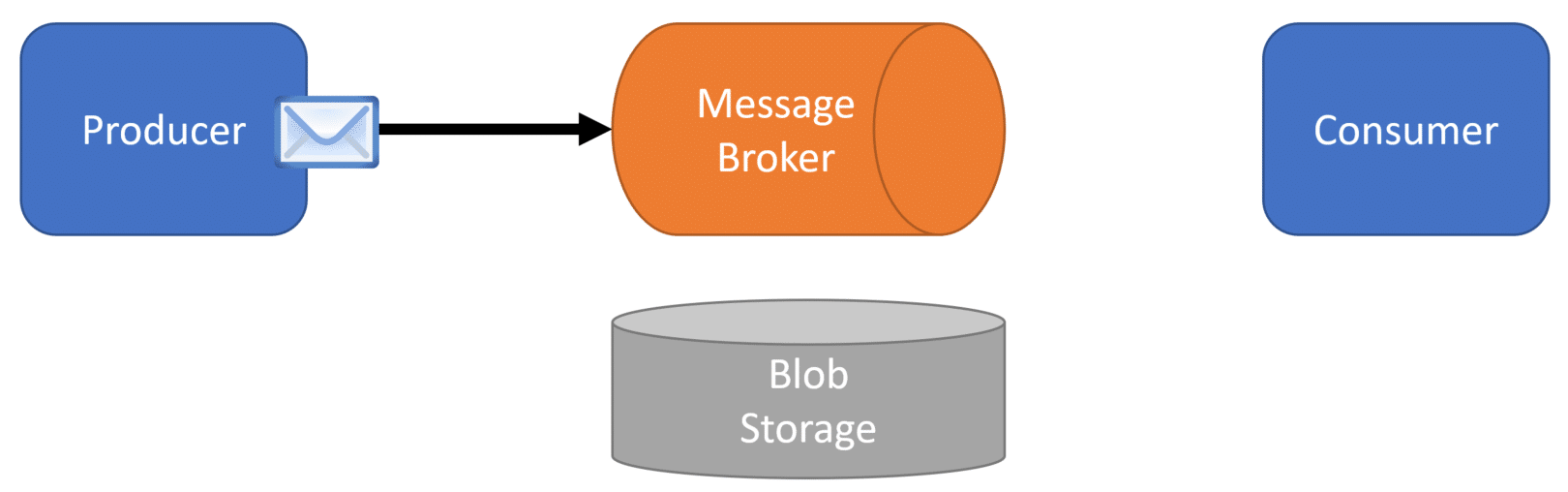
Now the consumer can receive the file asynchronously from the message broker.
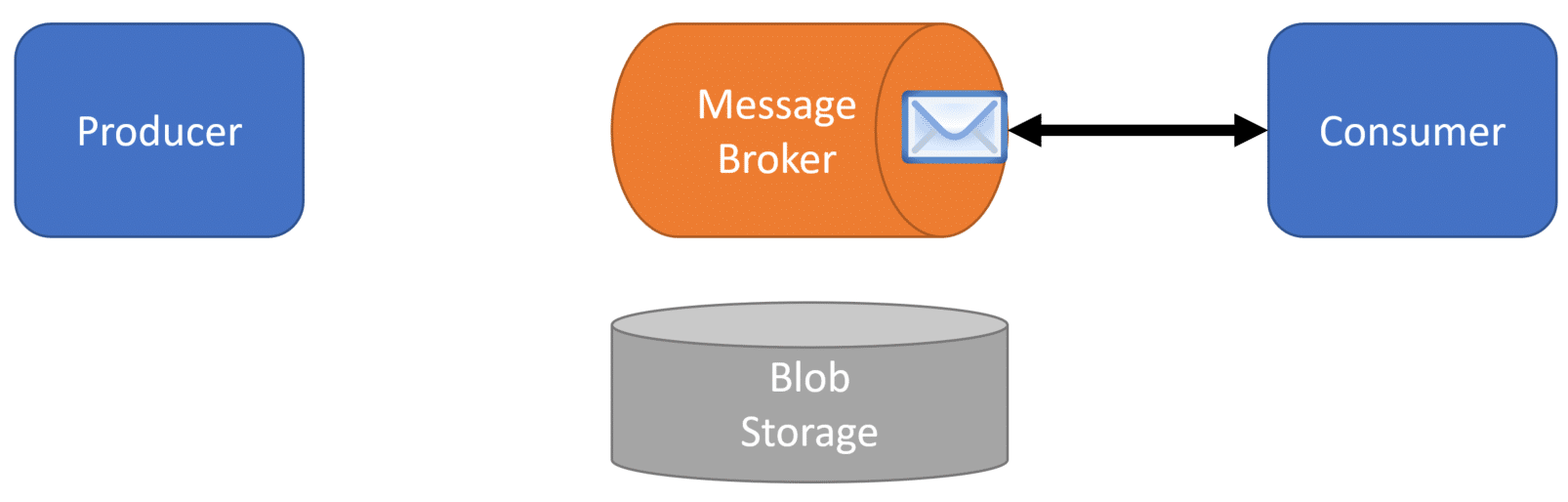
The consumer will then use the unique reference or identifier in the message to then read the file out of blob/file storage and perform the relevant ETL work.

Claim Check Pattern
If you have a large payload from a user that you need to process, offload that work out asynchronously to separate processes using a queue and message broker. But use the claim check pattern to keep your messages small. Have the producer and consumer share a blob or file storage where the producer can upload the file and then create a message that contains a reference to the uploaded file. When the consumer receives the message it can use the reference to read the file from blob storage and process it.
Source Code
Developer-level members of my CodeOpinion YouTube channel get access to the full source for any working demo application that I post on my blog or YouTube. Check out the membership for more info.