Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Many great libraries help to add resilience and fault tolerance by handling failures in a message driven architecture. However, it’s not just as simple as adding retries, timeouts, circuit breakers, etc., globally to all network calls. Many implications are specific to the context of the request being processed. And in many cases, it’s not solely a technical concern but rather it’s a business concern.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything that is in this post.
Handling Failures
Transient Faults are happening randomly. They are failures that happen at unpredictable times and could be caused by a network issue, availability or latency with the service you’re trying to communicate with. Generally, these aren’t failures you run into very often but when they do happen how do you handle them in a message driven architecture when processing messages from using queues and topics?
The first question isn’t a technical one but rather if there is a failure apart of a long-running business process, what does the business say? What kind of impact would it have if there was such a transient failure? This isn’t just a technical decision of adding a retry and hoping for the best but rather is likely more of a business decision.
But because we’re developers, we love the technical aspect, so let’s jump into some technical concerns, and then you’ll see how this tails back into how it affects the business.
Immediate Retries
If you have a transient failure, the most common solution is to add an immediate retry. For example, if we’re processing a message in a consumer and it needs to make a synchronous call to an external service. This could be a database or some 3rd party service.

When we immediately retry, if it was a transient failure, then we make the request again and possibly the request succeeds.

This may add a bit of latency to processing our message since we had to make two calls to the external service, assuming the first failure happened immediately.
Exponential Backoff
Immediate retries don’t always solve the problem. If you notice that your immediate retry is also failing then you may want to implement an exponential backoff. This means that after every failed retry, we wait for a period of time and try again. If the failure occurs again, we wait even longer before retrying.
The implication now is your adding more and more latency to the processing of a message. If you have an expectation about how long it takes to process a message, adding an exponential backoff could have a negative impact on the overall throughput.
Another negative implication, depending on the broker and/or messaging library your using, you could be blocking that consumer from processing any other messages if you’re using Competing Consumers Pattern for Scalability with a message driven architecture.
Jumping back to the business, does processing the message need to succeed? As developers, we often think that everything must succeed. But the best answer might be to fail fast. That might actually be the best option. Context matters and talking with the business about failures and if they can or cannot happen is important.
An example of failing quickly is a better option is if you have a recurring message that gets processed every 5 minutes. If you have an exponential backoff and that adds 2 minutes of total processing time and it still may fail overall, when in 3 minutes, you’re going to try to process another message to try the same thing again. In this situation, it may be better to fail immediately to free up your consumer to process other messages.
Dead Letter
If we fail to process a message but don’t want to abandon it, we can use a dead-letter queue to store failed messages which is common in a message driven architecture. For example, if we have an immediate try with exponential backoff, and the external service is still unavailable then we can then send the message to a dead letter queue.
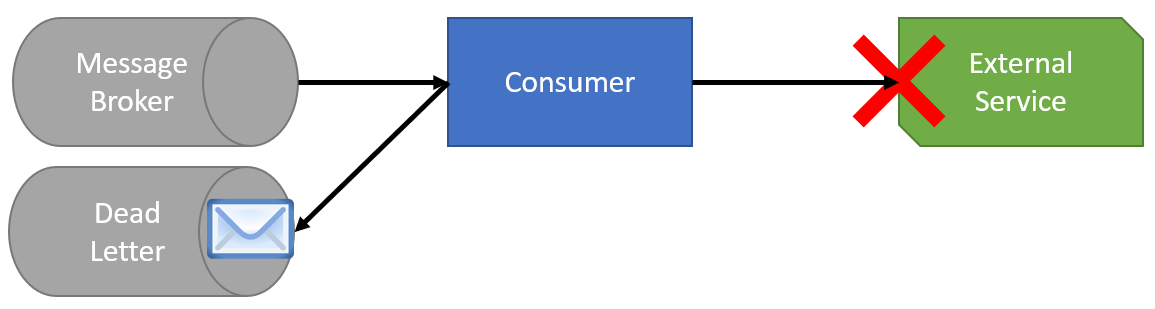
We can monitor this queue for reporting and manually try and reprocess these messages later once we know the external service is available.
Circuit Breaker
Once you have a failure, do you want to keep trying all new messages that are being processed? If the external service is unavailable and you don’t want to have every message that’s being processed go through its defined exponential backoff, then you can use a circuit breaker.
For example, this allows you to immediately send the message to the dead letter queue instead of even trying to call the external service.
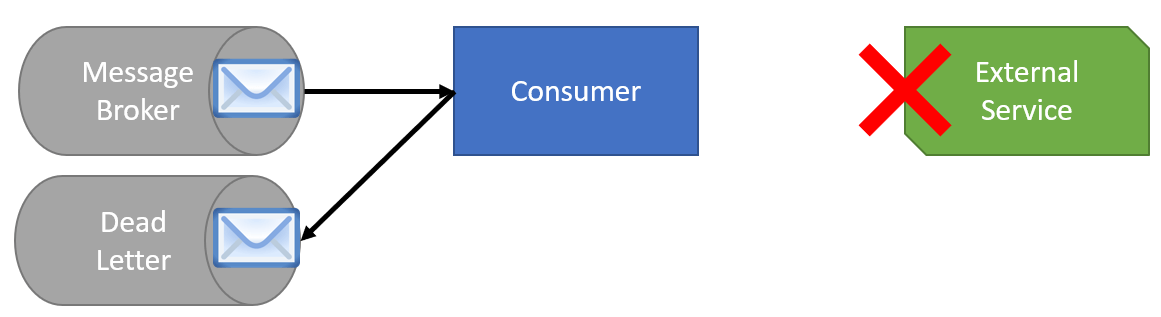
After a timeout period once processing another message, the consumer would try and call the external service again, going through its exponential backoff if a failure.
Handling Failures in Message Driven Architecture
From a technical perspective, there’s a lot to think about when trying to add resilience when processing messages. Do you want to immediately retry? Should you rather fail immediately? Should you move a message to the dead letter queue? Do you want to have an exponential backoff? IF you do, can you tolerate the latency it might cause in processing, which will decrease throughput?
Be aware if you’re increasing processing times from an exponential backoff, this may also backing up your queue if you’re receiving more messages than you’re consuming. You might create a bottleneck. That may be totally fine, that’s the point of a queue, however, if you have an SLA about processing times it may have a serious impact.
Sometimes the right answer is failing fast. You don’t need retries if it doesn’t impact the business. If it does impact the business, maybe you fail fast and move to a dead letter queue. Maybe the process must succeed and it’s low enough volume where you can tolerate a long exponential backoff. The only way to have these answers is to talk to the business. These are not just technical decisions because they will impact the business.