Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Do you want to use Kafka? Or do you need a message broker and queues? While they can seem similar, they have different purposes. I’m going to explain the differences, so you don’t try to brute force patterns and concepts in Kafka that are better used with a message broker.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Partitioned Log
Kafka is a log. Specifically a partitioned log. I’ll discuss the partition part later in this post and how that affects ordered processing and concurrency.
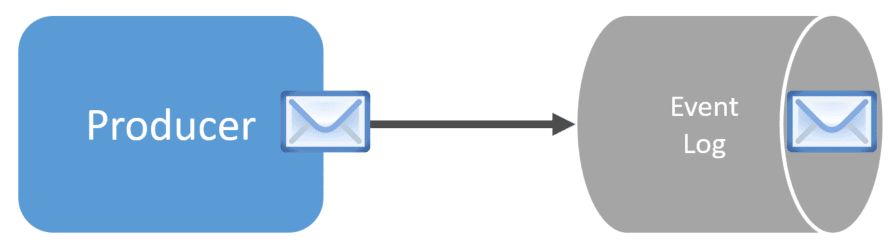
When a producer publishes new messages, generally events, to a log (a topic with Kafka), it appends them.
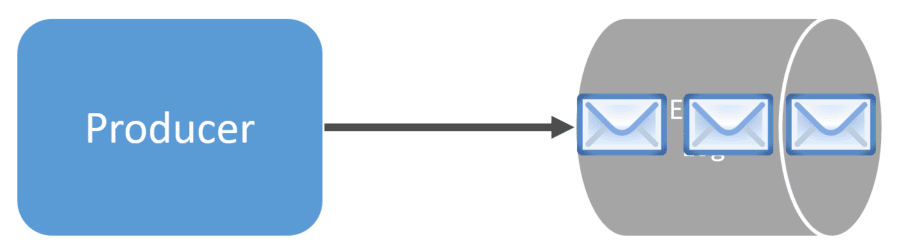
Events aren’t removed from a topic unless defined by the retention period. You could keep all events forever or purge them after a period of time. This is an important aspect to note in comparison to a queue.
With an event-driven architecture, you can have one service publish events and have many different services consuming those events. It’s about decoupling. The publishing service doesn’t know who is consuming, or if anyone is consuming, the events it’s publishing.
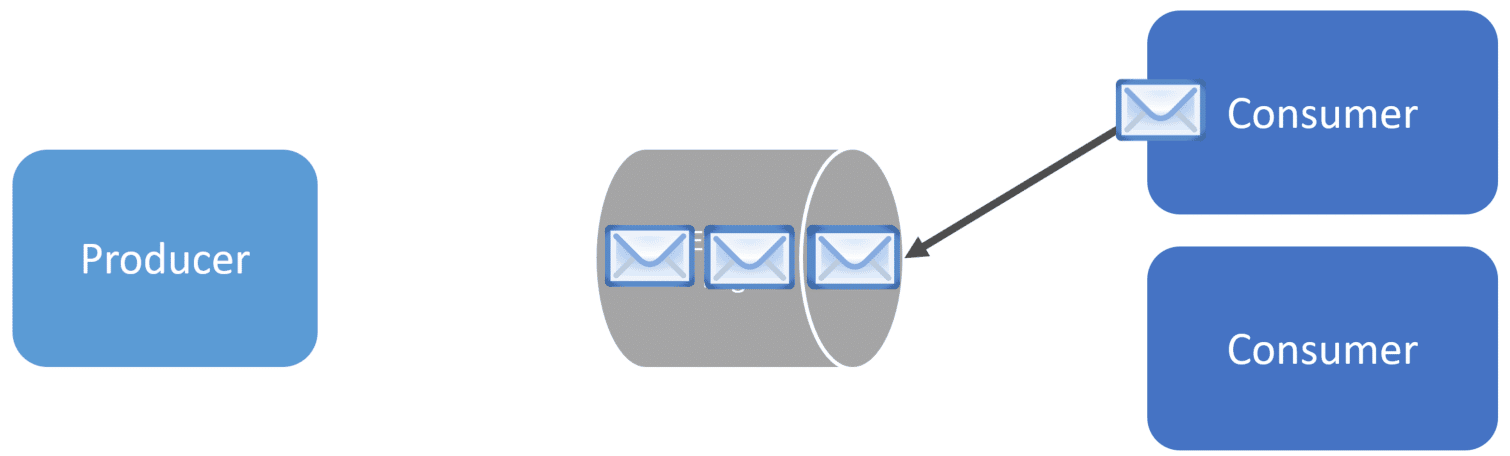
In this example, we have a topic with three events. Each consumer works independently, processing messages from the topic.
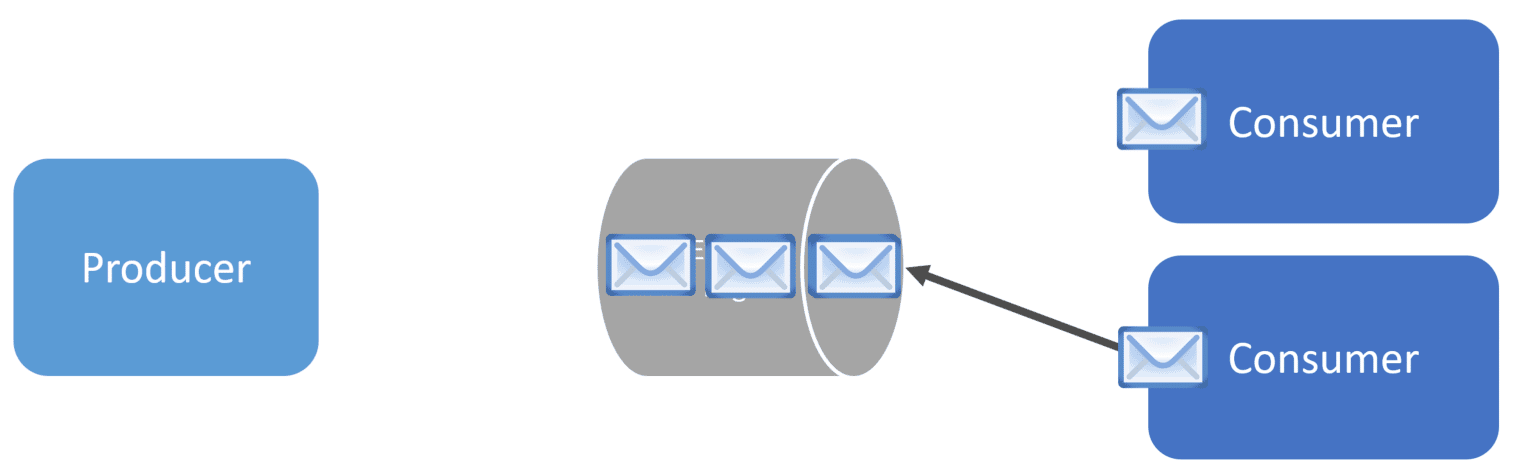
Because events are not removed from the topic, a new consumer could start consuming the first event on the topic. Kafka maintains an offset per topic, per consumer group, and partition. I’ll get to consumer groups and partitions shortly. This allows consumers to process new events that are appended to the topic. However, this also allows existing consumers to re-process existing messages by changing the offset.
Just because a consumer processes an event from a topic does not mean that they cannot process it again or that another consumer can’t consume it. The event is not removed from the topic when it’s consumed.
Commands & Events
A lot of the trouble I see with using Kafka revolves around applying various patterns or semantics typical with queues or a message broker and trying to force it with Kafka. An example of this is Commands.
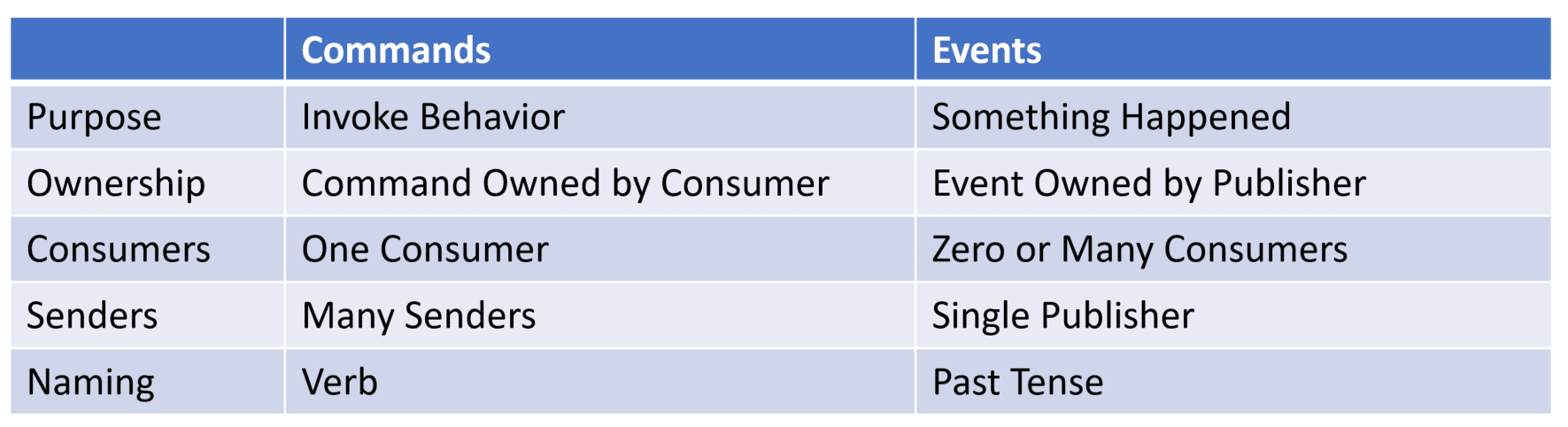
There are two kinds of messages. Commands and Events. Some will say Queries are also messages, but I disagree in the context of asynchronous messaging.
Commands are about invoking behavior. There can be many producers of a command. There is a required single consumer of a command. The consumer will be within the logical boundary that owns the definition/schema of the command.

Events are about notifying other parts of your system that something has occurred. There is only a single publisher of an event. The logical boundary that publishes an event owns the schema/definition. There may be many consumers of an event or none.
Commands and events have different semantics. They have very different purposes, and how that also pertains to coupling.
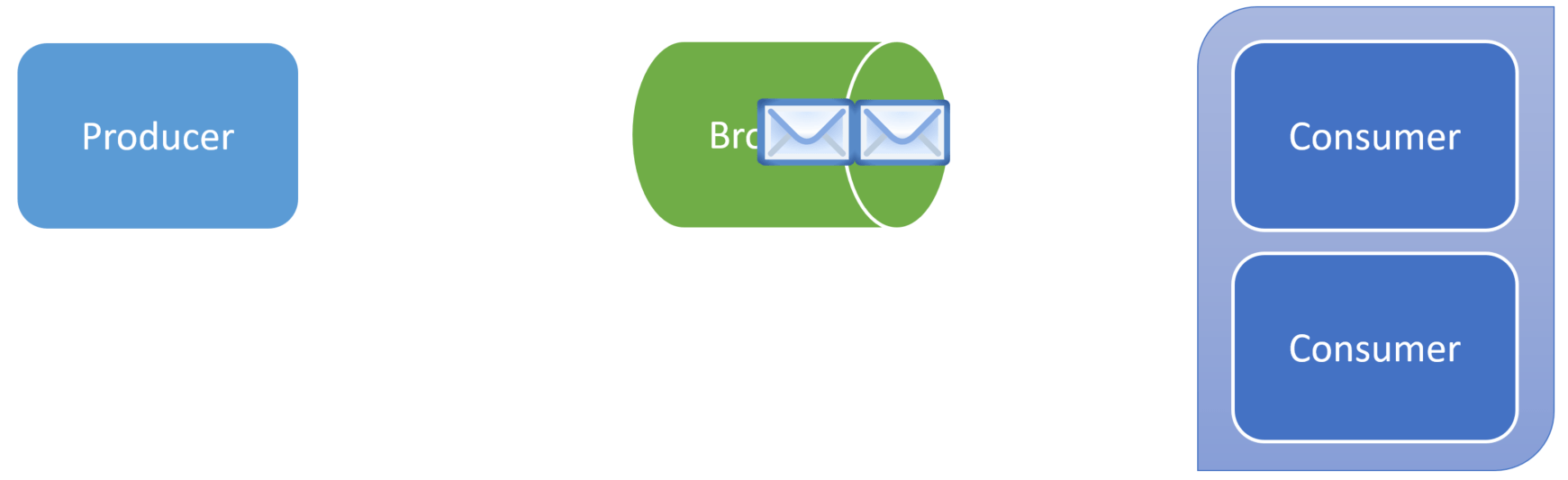
By this definition, how can you publish a command to a Kafka topic and guarantee that only a single consumer will process it? You can’t.
Queue
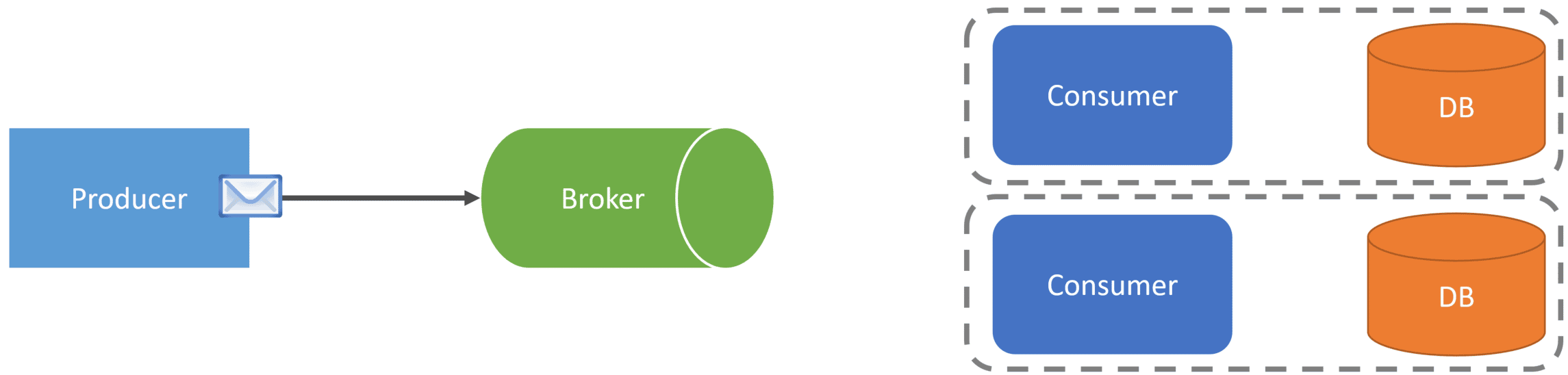
This is where a queue and a message broker differ.
When you send a command to a queue, there’s going to be a single consumer that will process that message.

When the consumer finishes processing the message, it will acknowledge back to the broker.

At this point, the broker will remove the message from the queue.

The message is gone. The consumer cannot consume it again, nor can any other consumer.
Consumer Groups & Partitions
Earlier I mentioned consumer groups and partitions. A consumer group is a way to have multiple consumers consume from the same topic. This is a way to concurrently scale and process more messages from a topic called the competing consumer pattern.
A topic is divided into partitions. Events are appended to a partition within a topic. There can only be one consumer within a consumer group that processes messages from a partition.
Meaning you will process messages from a partition sequentially. This allows for ordered processing.
As an example of the competing consumers pattern, let’s say we have two partitions in a topic. Each partition right now is a single event in each. We have two consumers in a single consumer group. We’ve defined that the top consumer will consume from the top partition, and the bottom consumer will consume from the bottom partition.

This means that each consumer within our consumer group can process each message concurrently.

If we publish another message to the top partition, this means the top consumer again is the one responsible for consuming it. If it was busy processing another message, the bottom consumer, even if it’s available, will not consume it. Only the top consumer is associated with the top partition.
This allows you to consume messages in order, so as long as you associate them to the same partition.
In contrast, the competing consumers’ pattern with a queue works slightly differently as we don’t have partitions.
If we have two messages in a topic, and we have two consumers within a single consumer group.
Messages are consumed by any free/available consumer. Because there are two free consumers, both messages will be consumed concurrently.

Even though messages are distributed FIFO (First-in-First-Out), that doesn’t mean we will process them in order.
Why does this matter? With Kafka partitions, you can process messages in order. Because there is only a single consumer within a consumer group associated with a partition, you’ll process them one by one. This isn’t possible with queues. The downside is that if you publish messages to a partition faster than you can consume them, you can end up in a backlog disaster.
Kafka or Message Broker Queues & Topics?
Hopefully, this post (and video) illustrated some of the differences. The primary issue I’ve come across is people using Kafka but trying to apply patterns and concepts (commands, competing consumers, dead letter queues) that are typical with a message broker using queues and topics, but it just doesn’t fit.
Typically when you’re creating an asyncronous workflow, you’re consuming events and sending commands. While you technically can create a topic for commands, you can’t guarantee there won’t be more than a single consumer. Is this a big deal? To me, semantics matter. If you’re already using Kafka and don’t want to introduce another piece of infrastructure like a queue/message broker, then I understand the reasoning for doing so.
Understanding the differences in how the competing consumers pattern works. If you’re not configured correctly and are publishing to a single partition, then you can’t increase throughput by adding another consumer to a consumer group.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.