Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Are you frustrated that you have to open multiple files across multiple layers to make what seems like a simple change? One of the culprits for this is following structure and templates that apply patterns or concepts to solve problems you might not have. One typical case of this is using aggregate from domain drive design. In this video, I’ll give examples of where an aggregate can make sense and where it’s not and adds useless indirection.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Useless Indirection
The idea for this video/blog came from a common I received on a YouTube video on my channel where I was talking about indirection.

The sentiment of this comment is all too common. I have many similar comments and have conversations with developers all the time about this. One of the culprits to this is applying patterns or concepts that are solutions to problems you don’t have in a given context.
One such pattern is the usage of an Aggregate from Domain Driven Design. The purpose of an aggregate is to create a consistency boundary. Unfortunately, the way it’s often explained more illustrates it as an object model or hierarchy.
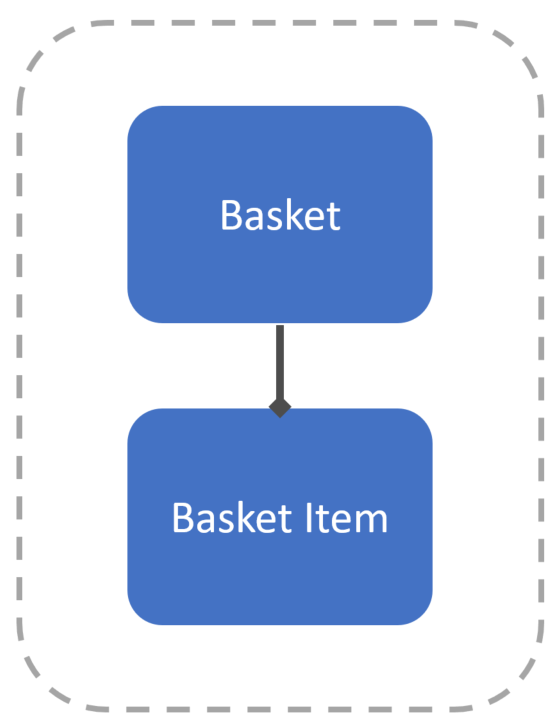
The stereotypical example is to model a shopping basket. You would have a basket that would have many basket items. Many think this is an aggregate because you cannot have a basket item without a basket. In this case, this would be the aggregate, and the Basket would be the aggregate root.
Typically you’d then use a Repository to save and fetch the aggregate out, only exposing the aggregate root (Basket) to consumers.
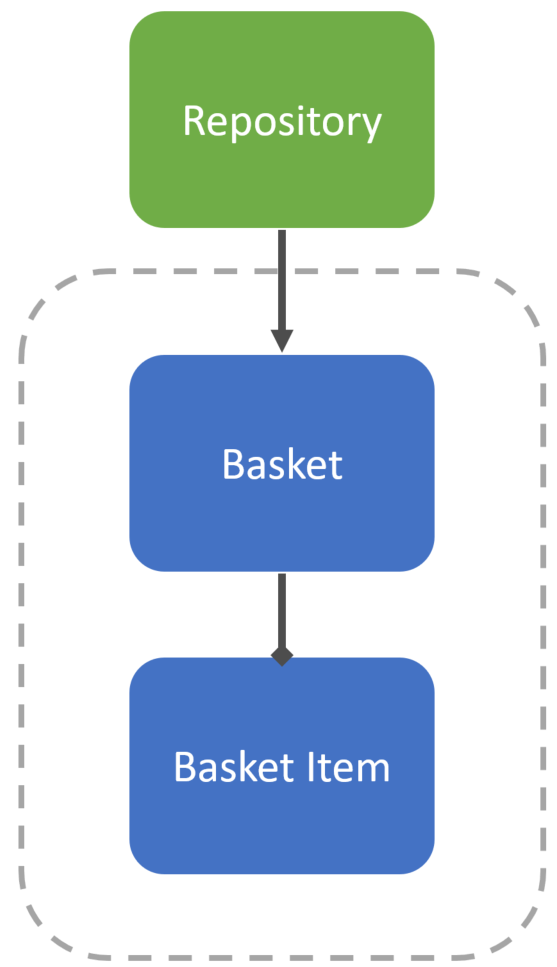
But does this need to be an aggregate?
Most commonly, aggregates are often incorrectly used to model an object/data hierarchy and to old domain logic, which I often think is a more trivial validation than complex domain logic.
However, an aggregate is about creating a consistency boundary. It’s not about modeling a hierarchy.
Do you need consistency within this aggregate?
Useless Setters
Here’s a made-up example of an aggregate based on a sample I found on GitHub.
This is a simplified example. However, you can see two methods for setting the Name and the Price of this Entity. There is also some logic for setting the price: the price must be greater than zero. To do this, it’s using a specification.
What value does the specification serve? What value do the SetName and SetPrice have? None.
The SetName method is just setting the underlying Name property. It’s useless indirection.
The SetPrice contains some validation logic, which is nice. However, the separate ProductNegativePriceSpecification is useless indirection. The SetPrice is also putting our entity in an invalid state even though it’s throwing. The caller could catch the exception and carry on.
We could just put the conditional check directly in the SetPrice method. But we can also use value objects and types to enforce a valid value directly from the caller.
Now, what value do the SetName and SetPrice have? Zero value. They are just setting the underlying properties. We’ve enforced our product price when the caller needs to construct a ProductPrice type.
We don’t have an aggregate (root). We have a data model with useless setters. Remove the SetPrice and SetName, then set the properties directly from the calling code.
Consistency Boundary
So when do you need an aggregate? Well, here’s an example of an Order Aggregate (root)
This slimmed-down version of the Order Aggregate Root illustrates what’s important. When we add an order item, we do it through the aggregate root (Order) because we want to only have a single unique product per order. Also, if we have a discount for the product, we want to use the discount with the greatest value. This is a consistency boundary. We need an aggregate and all operations to go through the root to perform this logic. We don’t want random data access code or transaction scripts managing order items. This gives us consistency.
Lastly, in the SetStockconfirmedStatus method, we’re making a state change, but we’re also publishing a domain event OrderStatusChangedToStockConfirmed. Other parts of our system likely rely on this event when that state changes. We must always publish this event when the order status changes to StockConfirmed. Again, consistency on state change and publishing an event.
Aggregate or Data Model
If you need a consistency boundary, use an aggregate and aggregate root. You’re not getting any of the benefits if you have a data model with just setters. Don’t add useless indirection. Just use a data model with transaction scripts.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.