Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
We moved from monoliths to microservices a decade ago, and there has been a swing back to either consolidating microservices or moving to a modular monolith. This isn’t surprising. Why is this happening? I will explain why logical boundaries don’t have to be physical. Once we finally make this distinction, it opens up many possibilities.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Physical Boundaries
One of the good things that came from microservices is defining boundaries. Good fences make good neighbors, as the saying goes. Defining boundaries is a good thing, but how exactly are we defining them? Microservices, as defined by Adrian Cockcroft
Loosely Coupled service oriented architecture with bounded contexts
This means that we have services defined by a bounded context, which comes from Domain Driven Design, and these services are loosely coupled between them. Typically, this would imply an event-driven or message-driven architecture.
I typically define services (not the micro part) as the authority of a set of business capabilities.
What does a service do? What are the capabilities the service provides? At least with all the baggage of microservices came the idea of defining boundaries.
Unfortunately, microservices, as developers have implemented them, have forced boundaries to be physical boundaries. But when talking about what capabilities a service provides, I’m talking about logical boundaries. They aren’t the same thing. Physical boundaries are not logical boundaries.
Forcing this idea can cause a lot of issues and is not flexible. Typically you’d have a logical boundary (what a service provides) also be in its own source repository (git repo), which is built and turned into a deployment artifact run in some environment as process, container, etc.

Or you might have a mono repo where all the source is under a single repository, but the end result is still the same where a logical boundary is built and turned in its own deployment artifact.
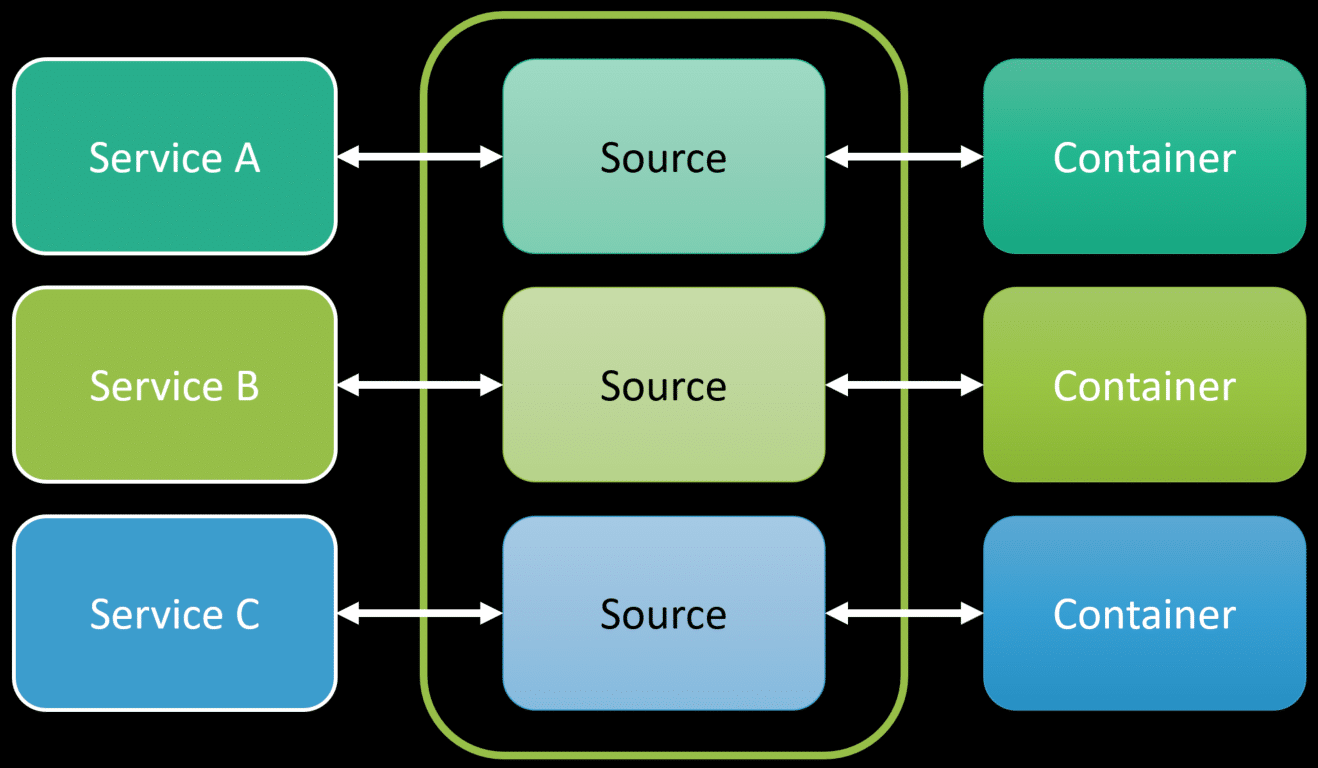
If you’re logical boundaries are also physical boundaries, you likely end up having service-to-service communication that happens over the network.
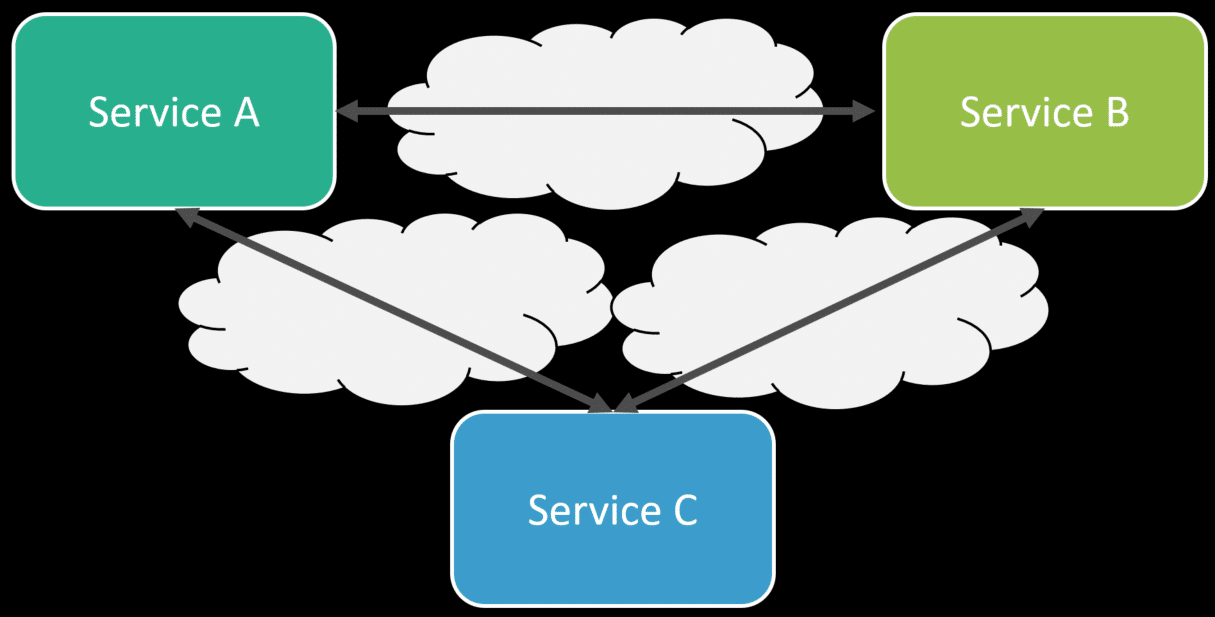
This could be HTTP, gRPC, or any other type of synchronous request/response via network calls. What’s the problem with that? A lot. Check out my post REST APIs for Microservices? Beware! as I explain some of the pitfalls including, latency, failures, and more. This ultimately is a distributed monolith. check out the fallacies of distributed computing which is still very relevant. If you were to go back to Adrian’s definition, he mentioned loosely coupled, which this is not. Making RPC/network calls does not make anything loosely coupled.
Logical Boundaries
So what’s the difference between a logical boundary and a physical boundary? The best way to describe this is probably thinking about the full scope of a system. You likely have many different aspects to it. There’s probably some Frontend/Client/UI, a backend, and a database and other infrastructure like maybe a cache.
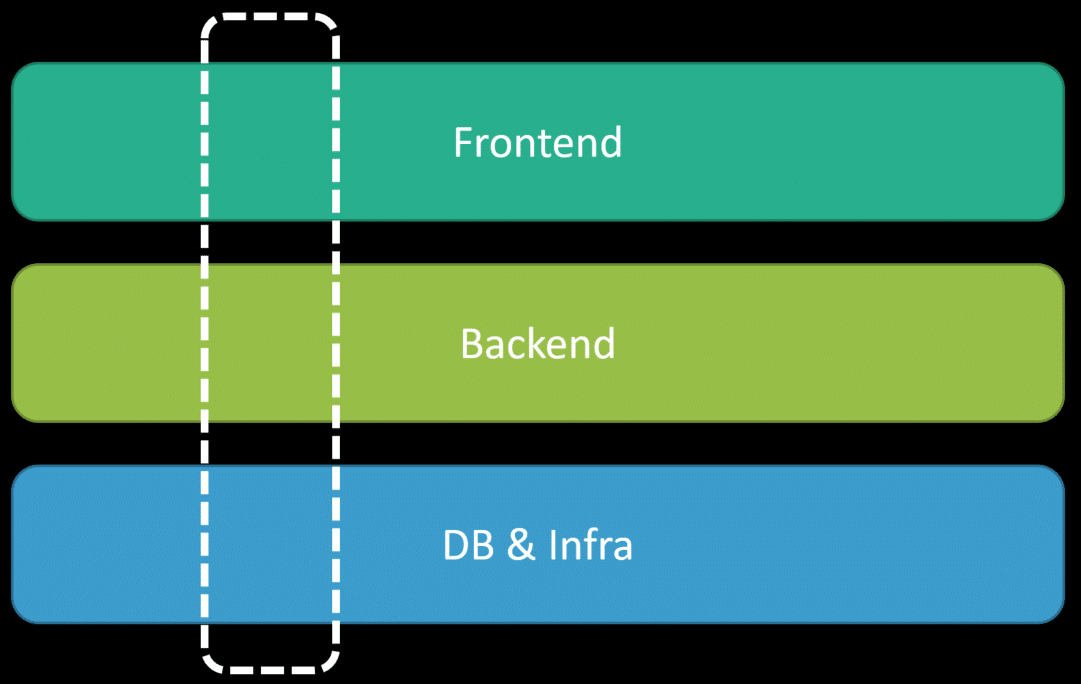
A logical boundary is the vertical slice across all these layers. A logical boundary owns everything related to the capabilities it provides. That includes the UI, the backend API, the database it is persisting to, and any other infrastructure it owns.
There are different ways of thinking about boundaries. A great illustration of this is the 4+1 Architectural View Model by Philippe Kruchten.
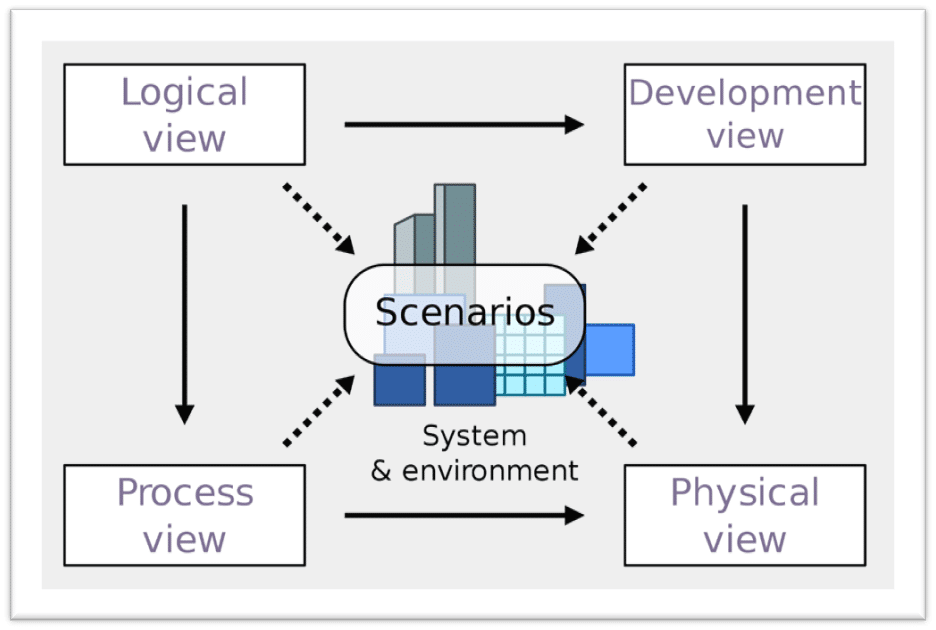
There are different ways you can look at a system. As I’ve been mentioning, there is a logical view, a development view (source code, repo), and a physical view (deployment).
A logical view can be the same as a physical view, but the point is they don’t have to be. Meaning, that a logical boundary doesn’t have to be deployed independently.
Composition
Once you realize this, you can see that you can compose things differently depending on your needs.
You could have multiple logical boundaries, within a single mono repo, which is built as a single unit of deployment. That single unit of deployment could be single process.
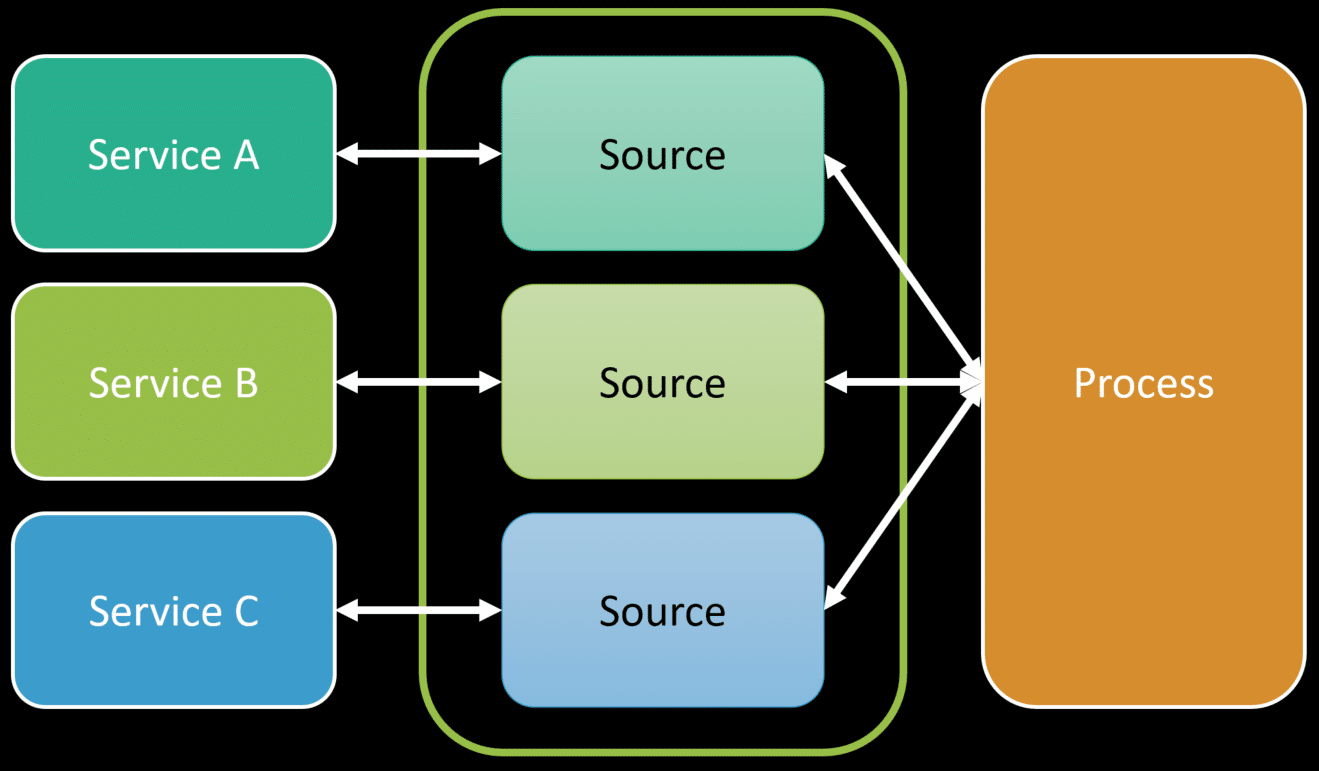
That means that if we were communicating synchronously between logical boundaries, we could be doing so in-process and not be making network calls. It’s just functions calling functions in-process.
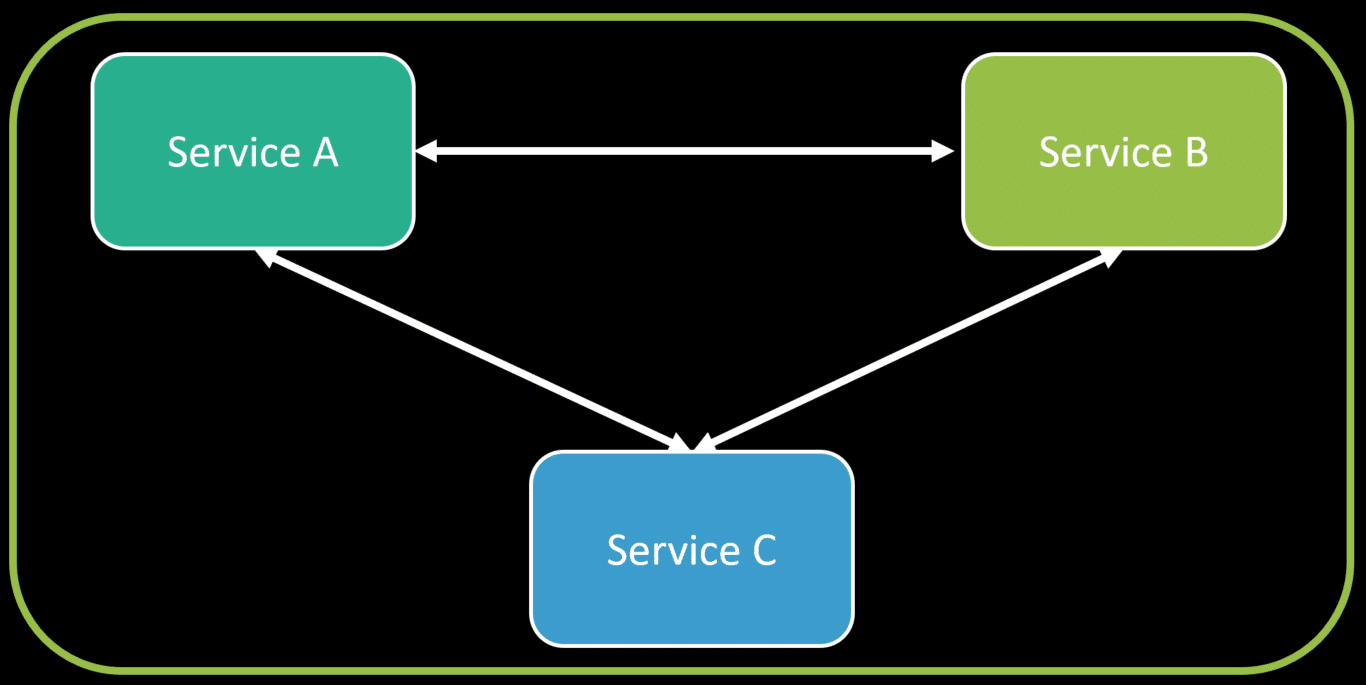
I’m not suggesting to compose all your logical boundaries into a single deployable unit. I’m illustrating that logical boundaries aren’t physical boundaries. They don’t have to be one-to-one. You have options.
One logical boundary could have a single source repo that when built creates two different deployment units, let’s say a container.

One logical boundary could be across multiple source repos that each get built into their own separate containers.

You could have a single logical boundary that is spread across multiple source repos that gets built into a single container.

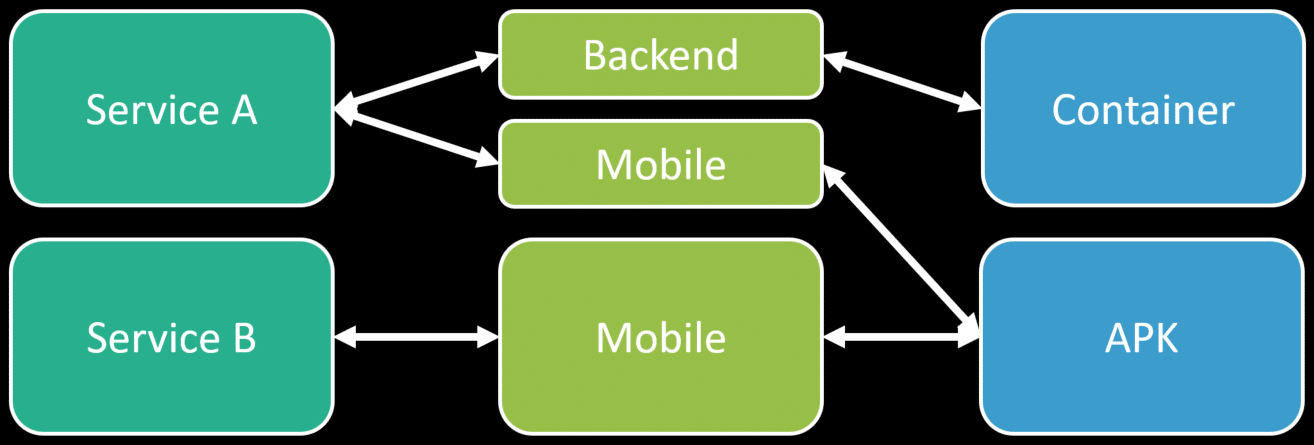
A better illustration of this would be if you have two different logical boundaries for a mobile app with a backend. Service A could provide a backend and a mobile front end. That same friend might be composed of another logical boundary to build the APK for Android.
This applies to infrastructure. Each service should own its own data, but that does not mean it needs to own the infrastructure. You could share infrastructure without sharing data. A single database instance could host different schemas owned by each logical boundary.
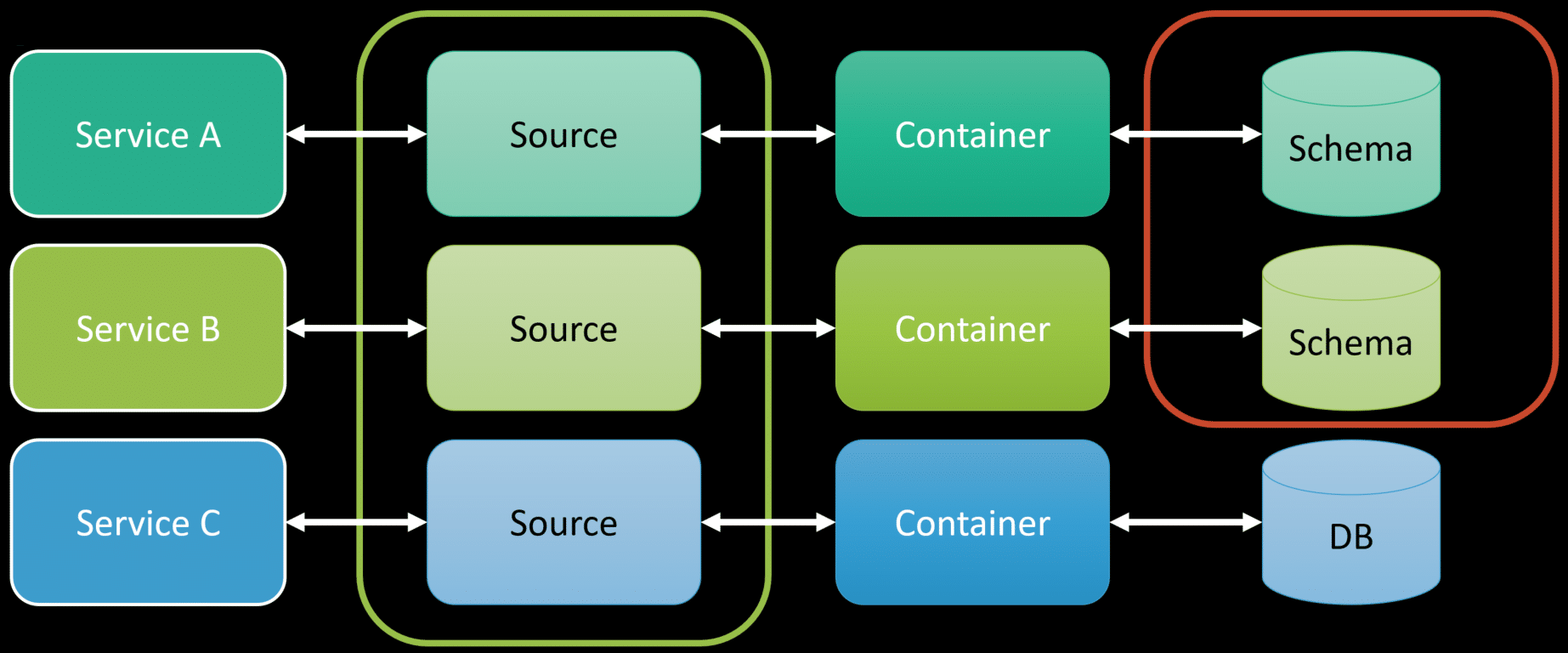
Could you have “noisy neighbors” where one service is consuming too many resources on your single database instance? Yes. At which point you could separate that out and use a different physical instance. The point is you don’t have to right from the get-go.
Jumping back to Adrian’s definition, he mentioned loosely coupled. If we leverage an event-driven architecture or messaging, we can remove any rpc or in-process calls. Even within a single process, we can use messaging to loosely couple between logical boundaries.
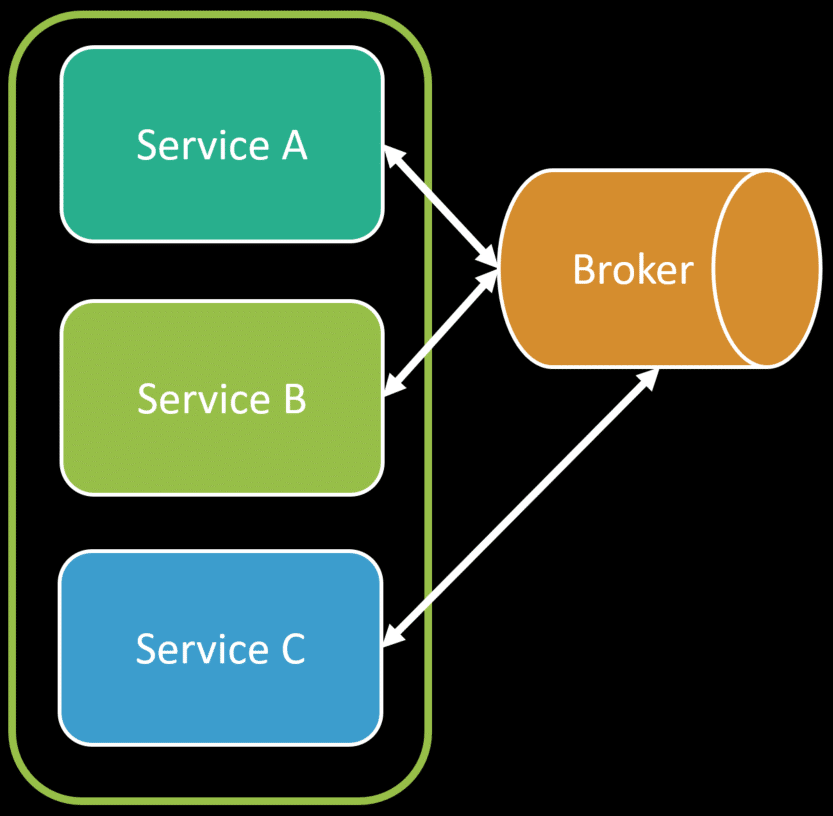
We have the option of changing our physical aspect by deploying logical boundaries independently if we need to for various reasons (deployment cadence, etc).
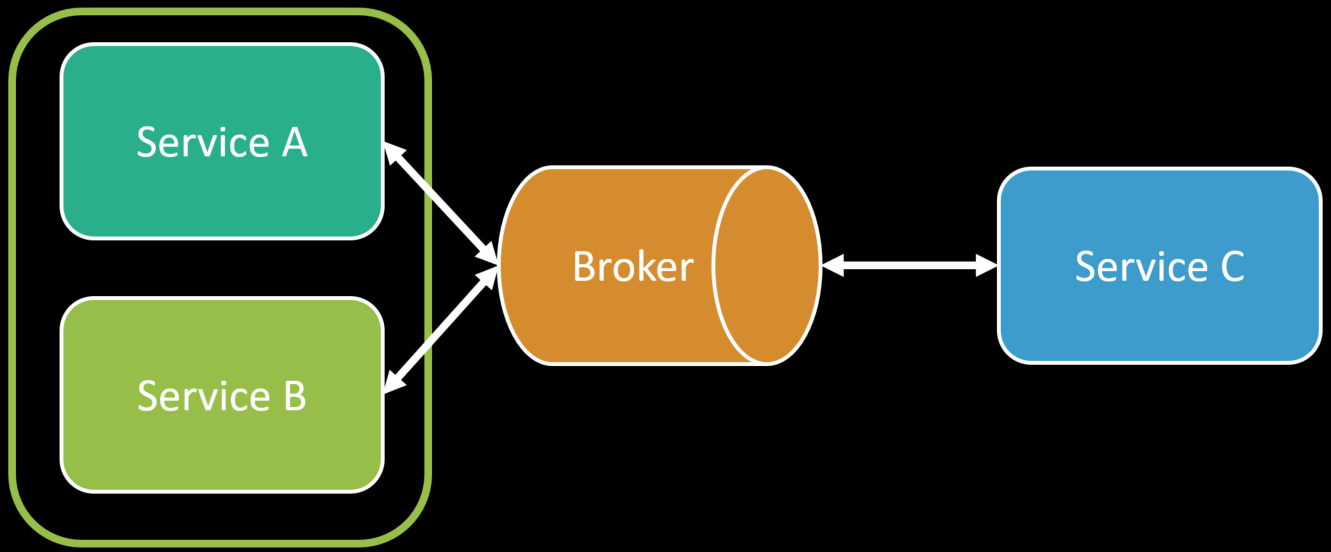
Microservices to Monoliths
Logical boundaries aren’t physical boundaries. They don’t have to be one-to-one. You can choose to compose logical boundaries together into a variety of different physical boundaries. Don’t limit yourself by forcing this restriction. Could you need a logical boundary to be a physical boundary? Sure. Then do it when it’s required. You have a lot of options when you don’t force this one-to-one constraint.
Join!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.