Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Amazon Prime Video moved one of its monitoring services from “microservices” to a “monolith”. I’m using quotes because that’s how they termed it in the post, which did themselves a disservice by making this statement. Almost every blog post or video covering this has missed the mark. All they did was refactor. This has nothing to do with microservices or a monolith.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Original Architecture
You can check out the original blog post from Amazon Prime Video, but here’s a quick summary that sets the stage for what they originally had as an architecture and what they moved to. There are a lot of hot takes about what they did, but most are way off base. So first, what was their original architecture?
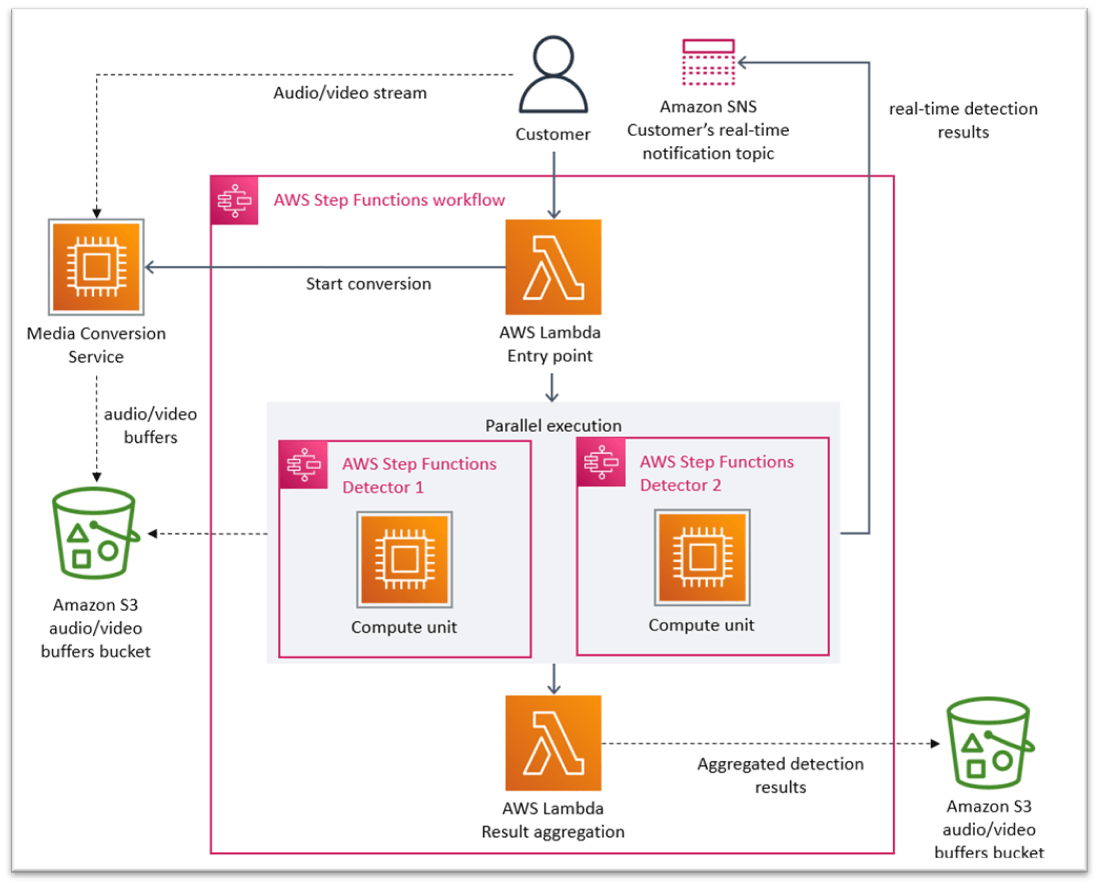
There’s an audio/video stream that goes to a Media Conversion service, which extracts frames from the video and puts those to an S3 bucket. Then, there’s a workflow with step functions that pull those frames (data) from S3 to analyze. They call these detectors that do the analyzing.
They stated that this was fine initially, but as the workload increased, this architecture was no longer viable. They stated that they never intended nor designed it to run at a high scale.
A major issue wasn’t anything to do with execution but cost. Because everything is distributed, each step function has to pull the data from S3 to analyze it. This data transfer does add latency to their processing times, but more so it’s monetarily costly that was an issue.
New Architecture
The architecture they moved to seems logical to me. Instead of using lambdas for analyzing the frames, they instead moved them to be within the same process within an ECS task. The audio/video stream data is going directly to this ECS task. This means S3 is no longer used at all. Since everything is in memory, there’s no pulling data from S3, it’s already in memory.
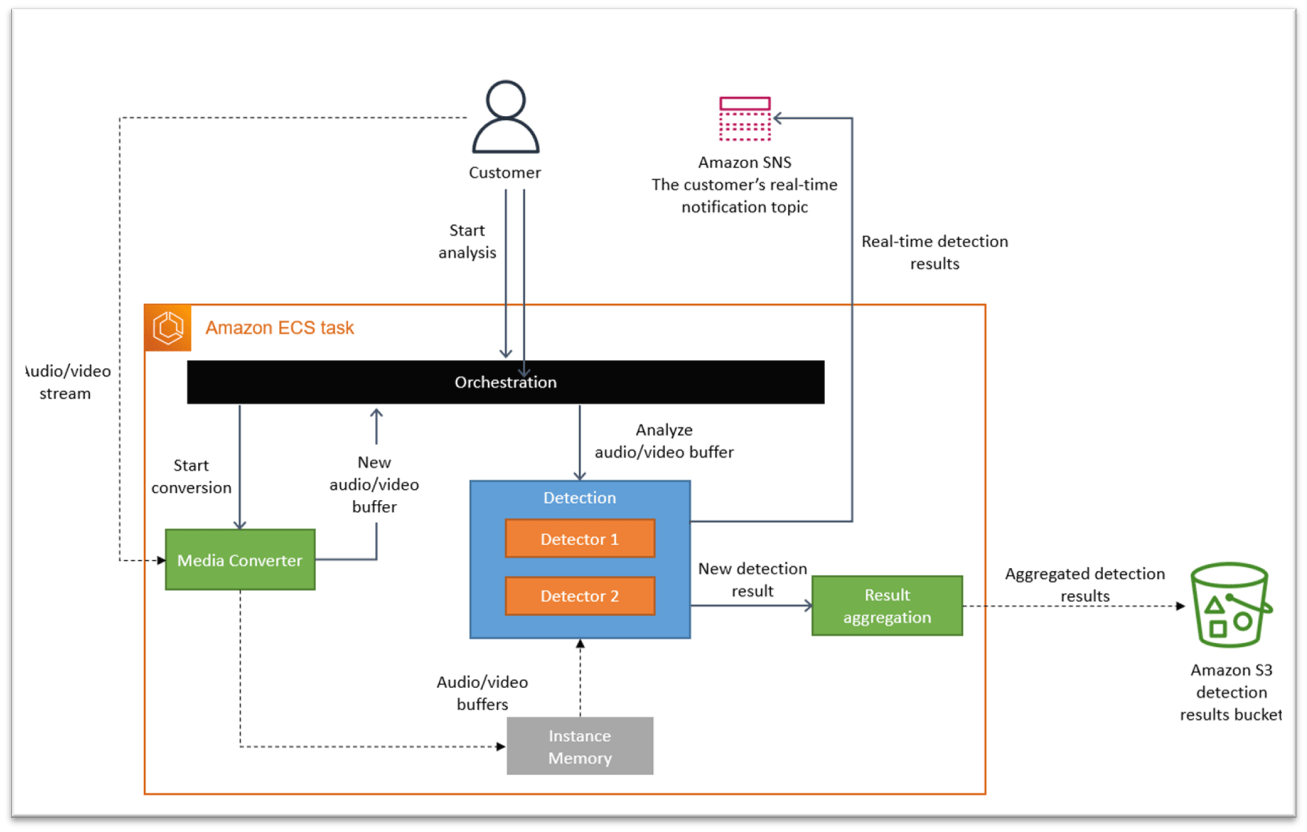
Nothing is distributed anymore. The media converter and the detectors (to analyze the frames) are all within the same ECS task (container).
Hot Takes
Unfortunately, this blog post stated that they moved from microservices to a monolith. There were all kinds of hot takes that seem to of missed the point or just didn’t even read their original post.
I’m not sure if people purely do this for clicks/views or if they just don’t really understand what the architecture change was. Or possibly they just didn’t even read the original post. I’m not sure.
What Amazon Prime Video did was change the physical aspect of their deployment. That’s it. It’s not that serverless sucks or they don’t understand what it is. It’s that given their specific use case, at a higher volume/scale, it wasn’t cost-effective.
They moved their code to be composed into a single process, which elevated the cost of distributing the workload and data. That’s it. As stated in the post, a lot of the code was reused, and it allowed them to quickly do this refactor. It wasn’t a rewrite.
Microservices to Monolith?
Amazon Prime Video said they moved from a microservices to a monolith. But that’s not what they did. They moved from a service… to a service.
What’s a service? It’s the authority of a set of business capabilities. That didn’t change. What changed was the physical boundaries.
Physical boundaries aren’t logical boundaries.
A logical boundary defines what the capabilities are. Their logical boundary is still the same, but their physical boundaries changed.
I think the confusion lies in thinking that the media conversion is its own “service” and the step functions detectors that do the analyzing are their own “service” but that’s not the case. The service is everything.
Using lambdas or having different components distributed doesn’t suddenly make it microservices. And just because you have all components executing in the same process/container doesn’t make it a monolith.
If you have a logical boundary and you have some source repo, that could turn into one container/process that is an HTTP API. You could also have another container/process that executes as a background worker service. You can also be scaling out and deploy multiple instances of both of these.
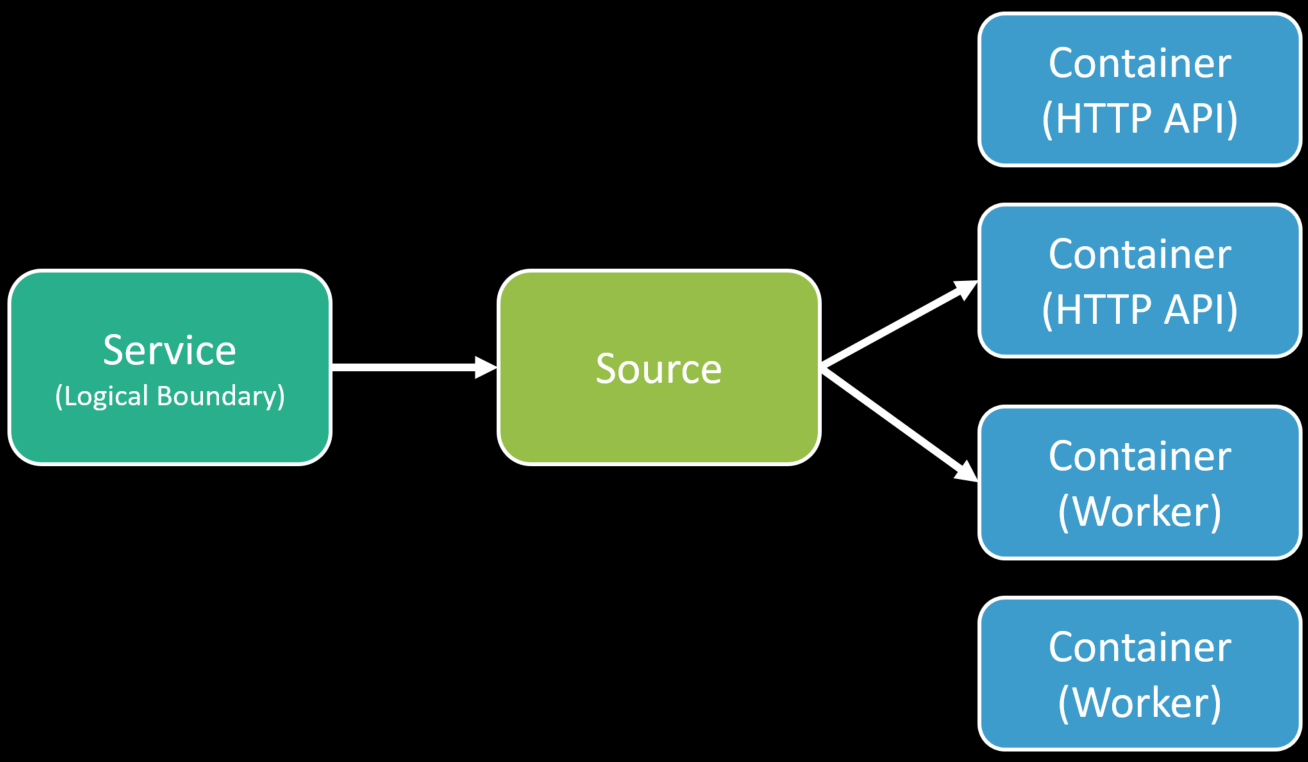
One more time for those in the back. Physical boundaries aren’t logical boundaries. Check out my post The Pendulum swings! Microservices to Monoliths for more on this.
Refactored
So what did they really do? Did Amazon Prime Video move from a microservices to a monolith? No.
They refactored. That’s it.
They evolved their architecture based on changing load and cost. They realized at the scale they needed that it wasn’t cost-effective to distribute the workload with step functions which then required distributing the data via S3.
They evolved and refactored to move it all within an ECS task so that everything was in memory.
Makes sense.
Join!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.