Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
How do you design an aggregate in domain-driven design? An aggregate in a cluster of related objects and used to manage the complexity of business rules and data consistency. Designing aggregates often incorrectly because of the focus on the relationship between entities.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Relationships
I believe most developers designing aggregates are thinking about data, hierarchy & relationships. As an example, here’s an aggregate diagramed by its relationships. It has an entity that is the Aggregate Root which any consuming code calls, and the relationship from the root to to other entities and value objects.
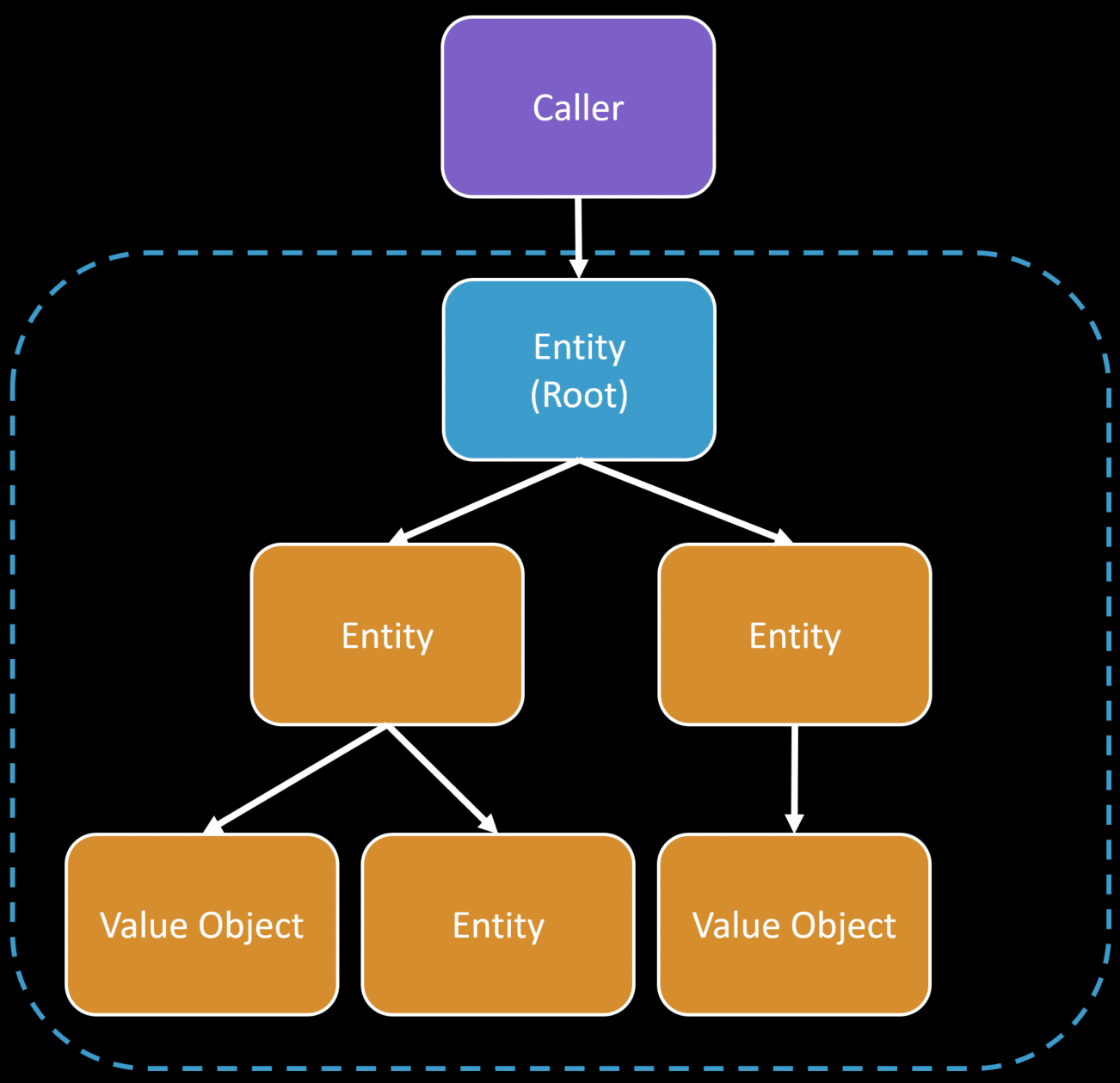
To put more context to this, I’ll be using an example in this post that came from a member of my Patreon that was asked on my private Discord. The scenario was you have a Route and many different locations for a Route. You can think of this as a bus route, and all the locations are bus stops. A location (bus stop) has a single vending machine.
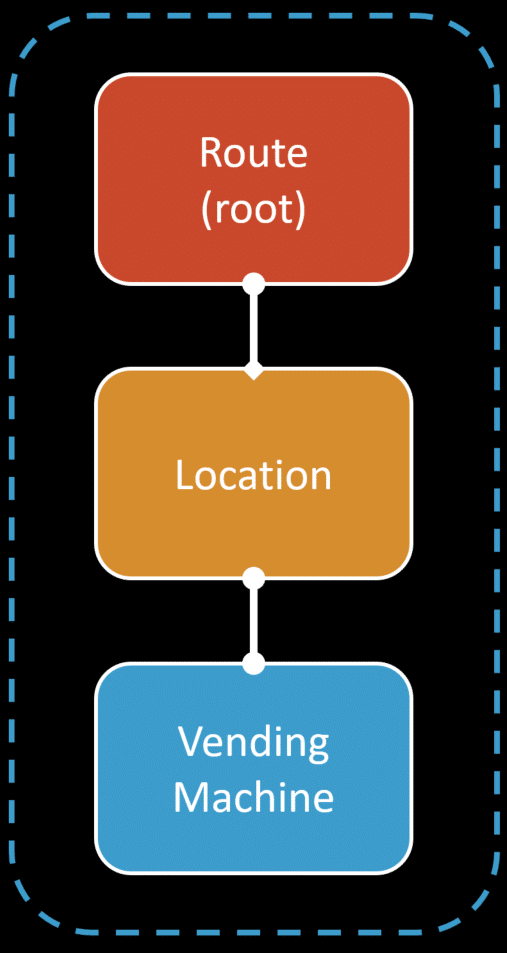
This vending machine would be emitting event and telemetry data, such as temperature and alarming when it is out of a certain range.
Aggregate
Besides just making the statement that someone can purchase something from a vending machine, I’ve only talked about the entities and their relationships. This is precisely where things go wrong, only thinking about entities, data, and their relationships.
Yes, an aggregate is a cluster of related objects, but those objects should contain behavior.
If I were to model the above in code, it might look like this.
The above code only deals with creating the relationships between entities, and the only real behavior is from the vending machine that has the ability to trigger an Alarm.
We don’t have any business logic or any behavior. All the code we have is to build up an object model hierarchy. While this is a simple example, the point I’m trying to get across is that we’re modeling the relationships. Sure you can have “business logic” that is based on the rules of these relationships, but that’s pretty much it.
Do you need an aggregate for that? Well depending on what type of database you’re using, you could be enforcing these relationship constraints at the database level. You could also just be using transaction scripts and data models. For more on transaction scripts, check out my post Domain Logic: Where does it go?
Invariants
Why do you want to use an aggregate? To enforce invariants and to be a consistency boundary. Hierarchy & relationships are an aspect but not only within that context. An aggregate is a cluster of related objects, but related how? Related based on the invariants you need to enforce.
So if invariants are a key part of an aggregate, when do you need to enforce them? Only when you’re making state changes. If data within an entity is not related to any invariants or must be consistent within an aggregate, then it doesn’t serve a purpose within the aggregate.
Taking this further leads you to realize that exposing data such as the AlarmCount and LastAlarmDate serves no value.
CQRS
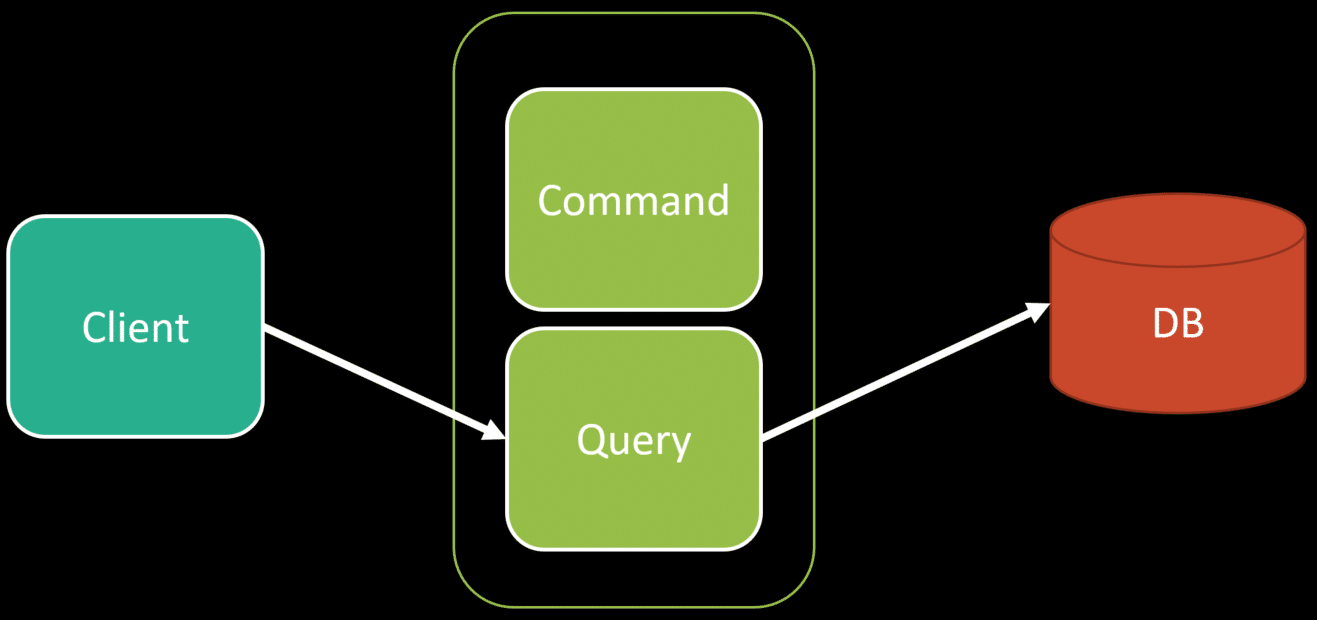
Now you’ve landed on CQRS because the model for commands and the model for queries are different. The model for your commands to make state changes can be an aggregates, and your queries can choose a completely different path.
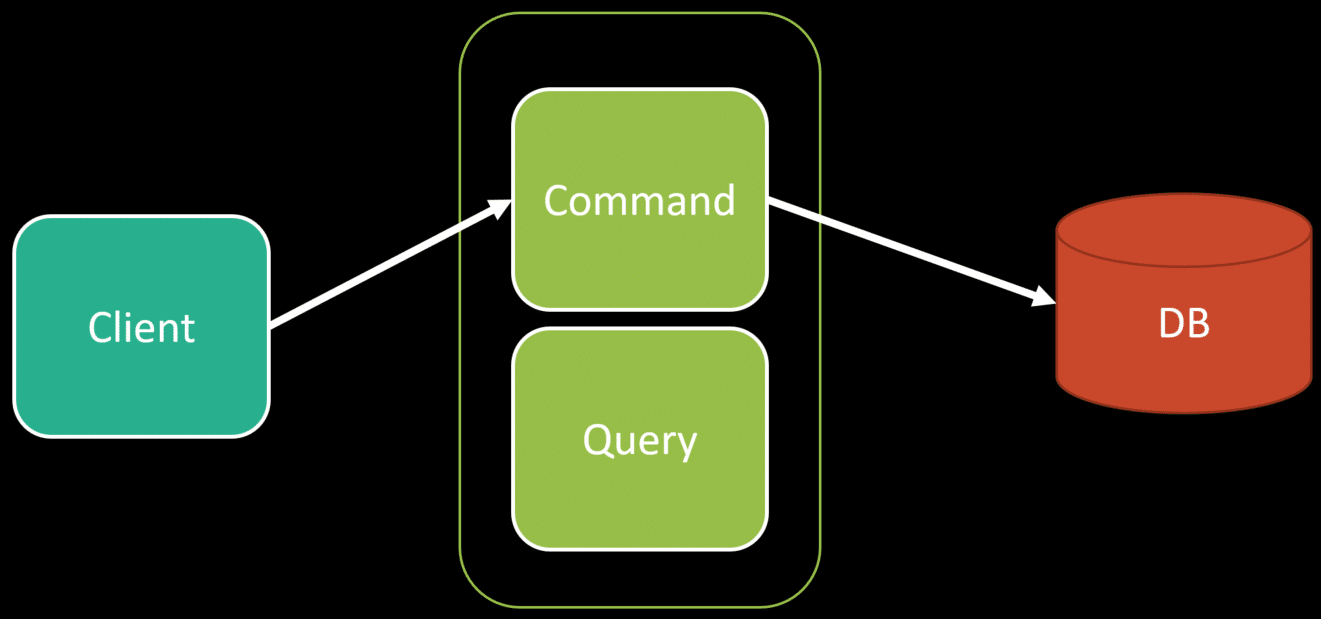
As mentioned many times, CQRS isn’t about different data stores, it’s about different paths for reads and writes. Your queries can use the same underlying database, but they might not use an aggregate, rather they could query the data store directly.
Behavior
If we stop thinking about relationships and start thinking about behaviors and the invariants we need to enforce, the consistency we need within an aggregate, our model would look different.
The Vending Machine is the one that had the ability to create an alarm. It can be on its own and when an alarm is triggered it could be publishing an event.
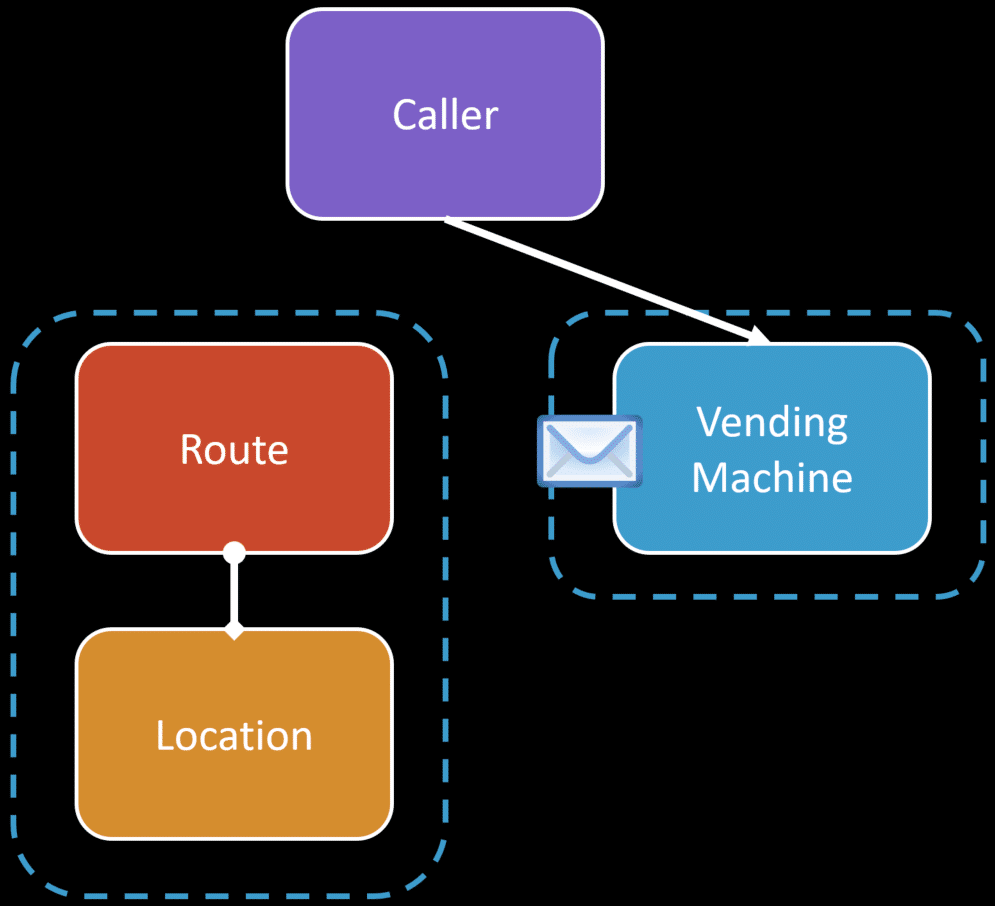
We could have another aggregate that contains the Route and the Location that could consume that event if it actually needs to know the alarm was triggered.
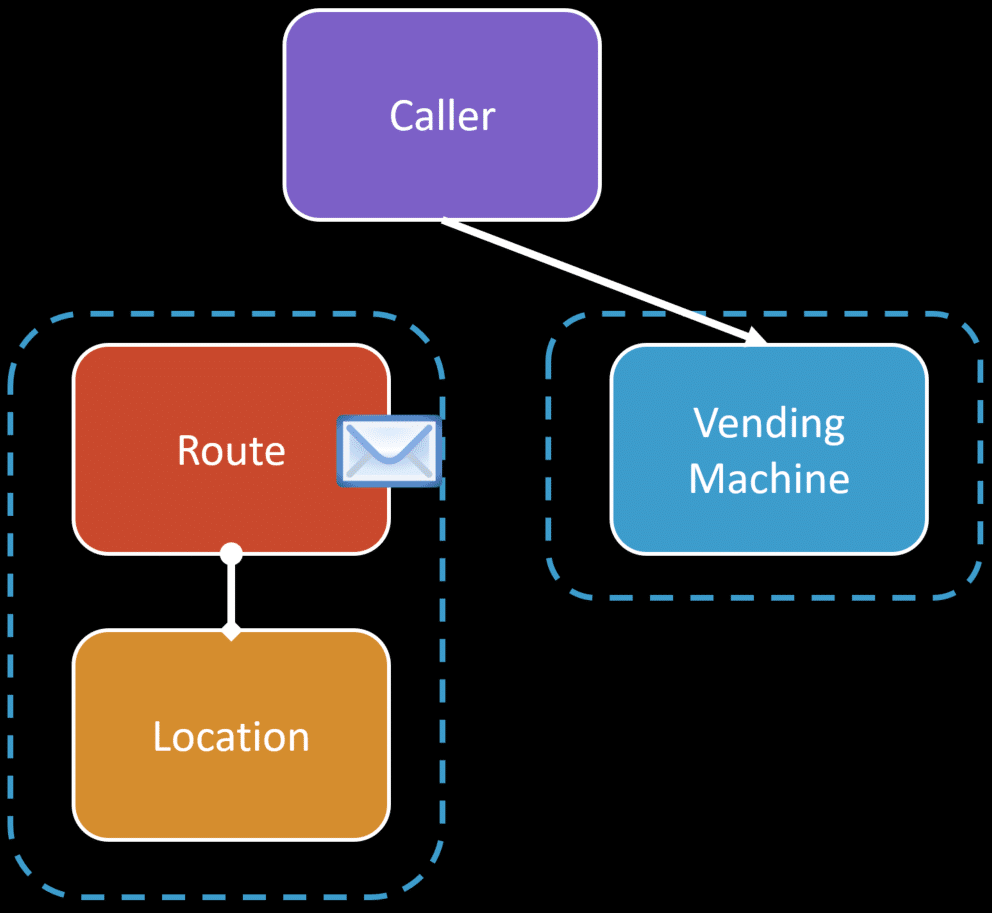
What it likely cares about the event is for query purposes to know if there are routes that have any locations with vending machines that are in an alarmed state.
Aggregates
It’s typical to think about aggregates based on their hierarchy & relationships between entities. I think this comes from the nature of thinking about data first and not behaviors. But the point of an aggregate is a consistency boundary and enforcing invariants. The data that drives those invariants is what you care about based on the behaviors being exposed. If you don’t know what the behaviors are, you can’t know what invariants to enforce. If you don’t know that, then you’re just building an object model hierarchy, not an aggregate. Don’t add unneeded complexity when you simply can use a data model and a transaction script.
Join!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.