Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Do you need a message broker, or can you use your database as a queue? Well, as in most cases, it depends. Let me explain how it’s possible and some trade-offs and things to consider, such as volume, processing failures, and more.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Database as a Queue
There was a blog post about ditching RabbitMQ for Postgres as a queue. TLDR: They claimed they had issues with prefetching with RabbitMQ and it was causing issues because they have long-running jobs. When they process a message, it can takes hours to complete. Another note is they are doing manual acknowledgments once a message is processed.
Invisibility Timeout
Acknowledgments are important because of the invisibility timeout of a message. When working with a typical queue-based broker, you need to send an acknowledgment back to the broker that you’ve finished processing a message.
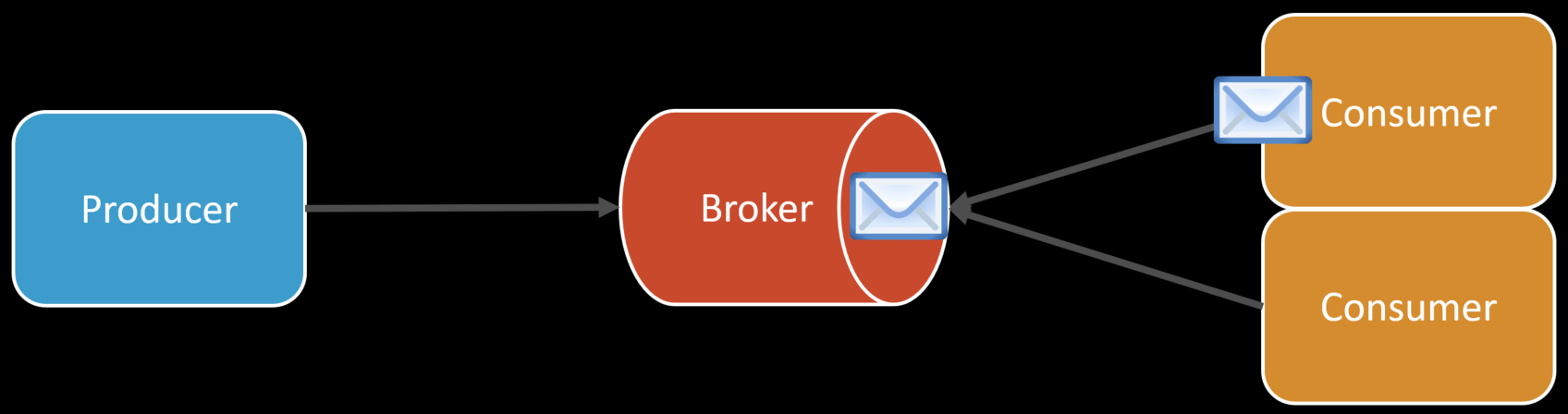
The reason for this is there is a length of time (timeout) before the broker deems the message processing as incomplete so it will then allow that message to be processed again. Imagine if your process fails or you have some exception that occurs. You’d want the broker to allow the message to be re-processed. If your processing of the message was successful, you return to the broker to tell it that it can remove the message from the queue.
This time period is called the invisibility timeout. The message is still on the queue but it’s invisible to any other consumers until it’s either acknowledged or the timeout occurs.
Now you may hear people say you shouldn’t use a message broker for long-running jobs because of this. You’d have to make your invisibility timeout longer than the total processing time it takes. Otherwise, you’d potentially re-process messages. This is often the reason why those claims are made. There are other reasons as well as throughput considerations and more, but generally having long-running has implications you need to be aware of.
Competing Consumers
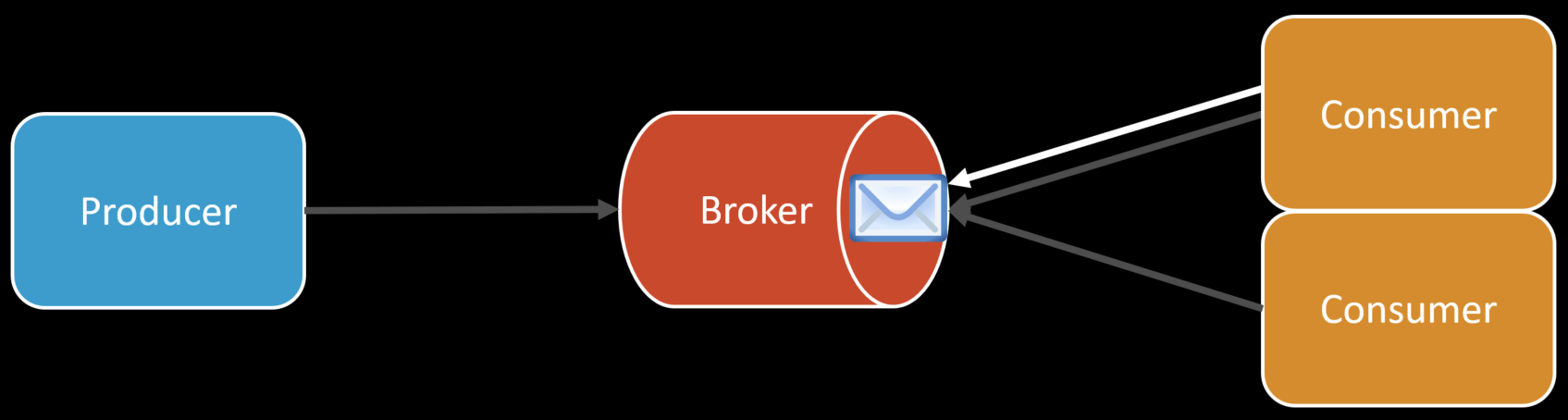
I mentioned throughput because one way to increase throughput, when required is using the competing consumers pattern. This means having multiple instances of the same application processing messages from the same queue. It’s basically scaling out horizontally.
So if you have two instances running, they can both be consuming messages from the same queue. This allows you the not process messages concurrently, increasing throughput.
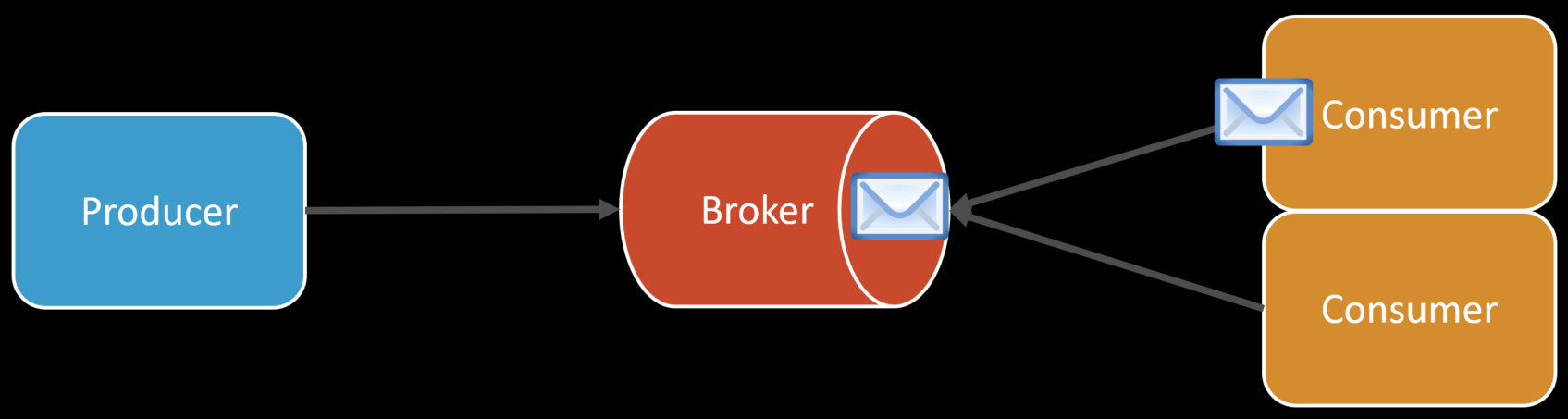
The issue they described in the blog post was that they were prefetching multiple messages together from RabbitMQ. This means that if there were two messages available, a single consumer would pre-fetch 2 messages, not one.
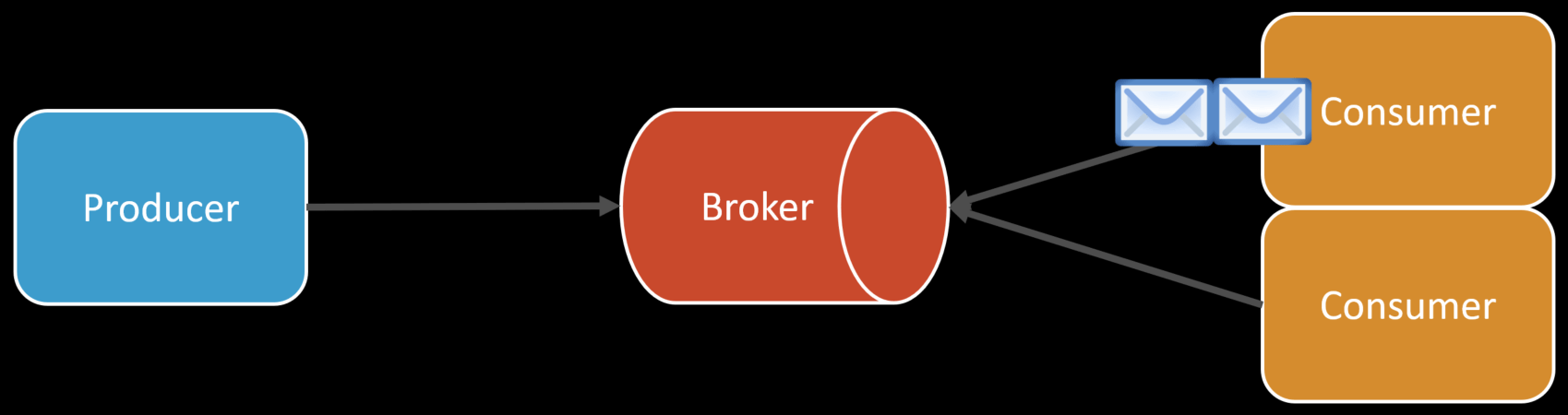
And since consuming a single message could take hours, this would then reduce throughput because the other consumers available don’t see the message. As well as, the invisibility timeout would kick in since the second message that was pre-fetch would often exceed the invisibility timeout because the first message took so long to process. But the consumer would still process it since it fetched it, but the since the invisibility timeout expired, the message would get processed again as well.
Because of all these troubles, rightfully or wrongfully, they decided to ditch RabbitMQ and use Postgres as their queue, which they were already in their system.
Table
So how would you implement a queue using Postgres or a similar relational database? First, it simply starts with a table where you’d be persisting your messages.

The table would have some Primary Key and the message’s data, which is likely serialized.
Any new message would be inserted into the table. As for consumers, you need to be blocking so you can lock any available records for processing. To do this in Postgres, you could use the FOR UPDATE SKIP LOCKED statement and a LIMIT 0,1. This will allow us to select a single record that hasn’t already been locked.
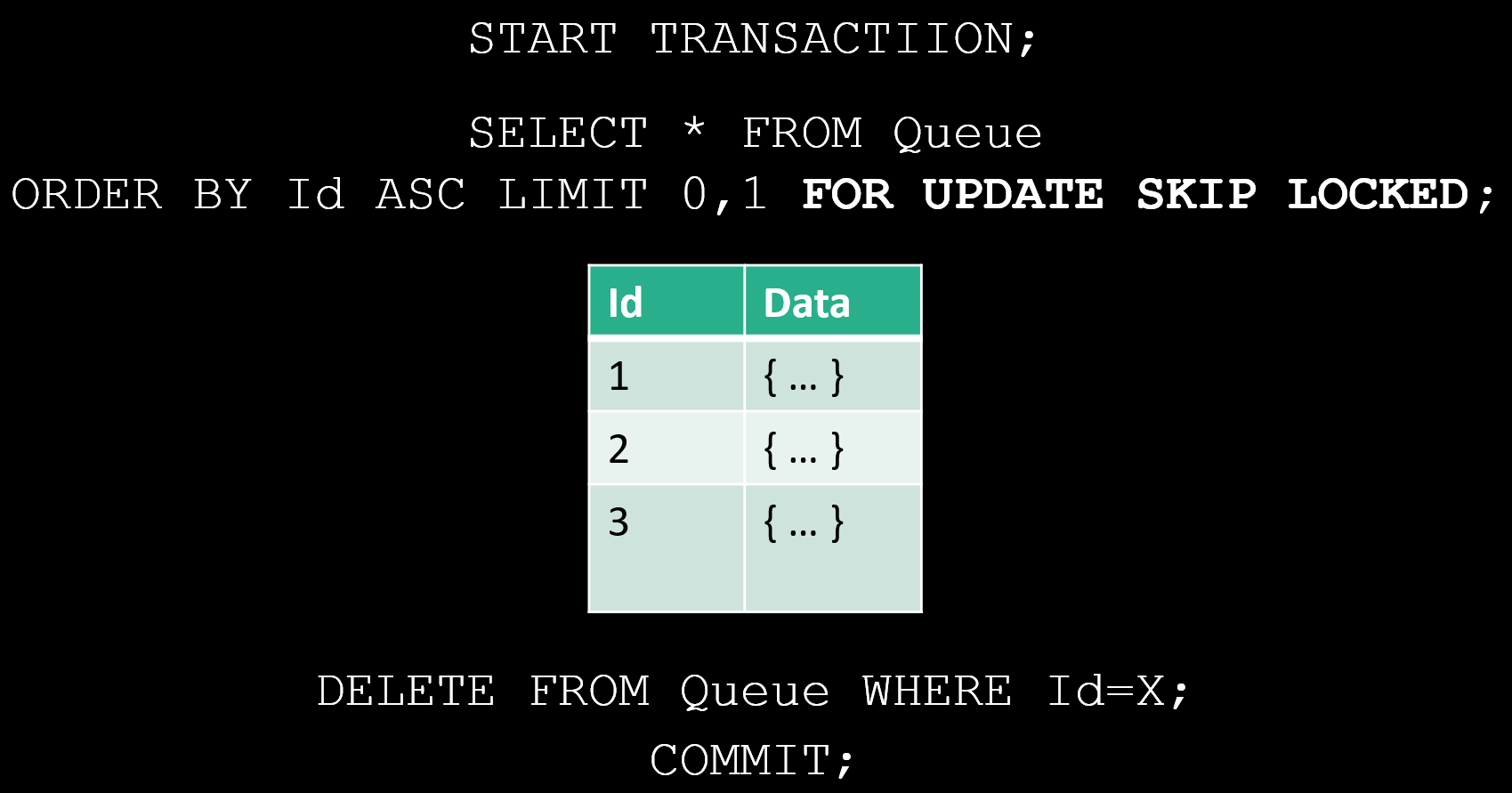
Then once the message has been processed, you’d delete the message from the queue and commit the transaction.
While you don’t have an “invisibility timeout” you do have the same type of mechanism with a database, often called a wait timeout. You can only have a transaction or connection open for so long before the timeout occurs and it automatically does a rollback of the transaction or closes the connection. You’re still in the same situation where you might still be processing the message and now will end up re-processing it.
Trade-offs
So what’s the issue with using your database as a queue rather than a queue-based message broker? As you can see, it’s feasible to use a database. In some situations, you maybe simplify your infrastructure by using a database you already have. However, as always, context is king!
You need to know what you’re trying to accomplish and the limitations. Once you get out of the simplest scenario that I showed above, you will end up implementing a lot of functionality on top of your database that out-of-the-box queue-based brokers support (dead letter queues as an example).
You also need to understand your use case. If you’re going to have a lot of consumers, they need to be polling (querying) the table periodically. This can add a lot of load but also can decrease total throughput and increase latency because you’re polling your database.
When you have failures, how are you handling that with your queue if its in your database? Are you implementing retries? Creating another table as a dead letter queue? Do you need to implement different queue tables for different levels of priority of messages? The list goes on and on that out of the box you can do with your typical queue based broker.
So what’s the issue with using your database as a queue? None until you actually need a message broker.
Join!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.