Sponsor: Using RabbitMQ or Azure Service Bus in your .NET systems? Well, you could just use their SDKs and roll your own serialization, routing, outbox, retries, and telemetry. I mean, seriously, how hard could it be?
Here are my top 5 patterns and concepts (Outbox, Idempotent Consumers, Event Choreography, Orchestration, Retry/Dead Letter) for Event Driven Architecture that you’ll likely implement. Why? Well if you’re new to Event Driven Architecture there are many different problems that you’ll encounter. Most of the issues have well-established patterns or concepts you can leverage to deal with them. Here are the most common patterns for Event Driven Architecture that you’ll likely use.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything that is in this post.
Outbox Pattern
Generally, you’re publishing events because you want to notify another boundary that something has occurred within your boundary. There was likely some type of state change that you want to want to notify other boundaries about. This could be from a long-running business process or for state propagation.
The issue is your state changes are likely to be stored in a database while your publishing messages to a message broker. You cannot reliably do both without a distributed transaction.
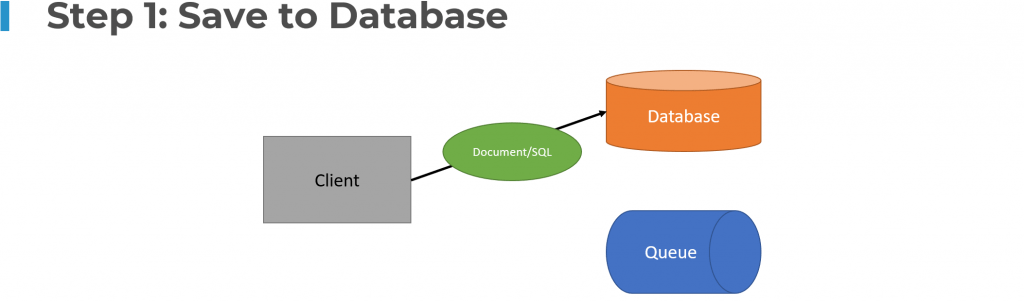
If you’re successfully writing to your database, but then for some reason, the message broker or queue you’re publishing a message to is unavailable or there is a failure, then you’re never going to publish the event.
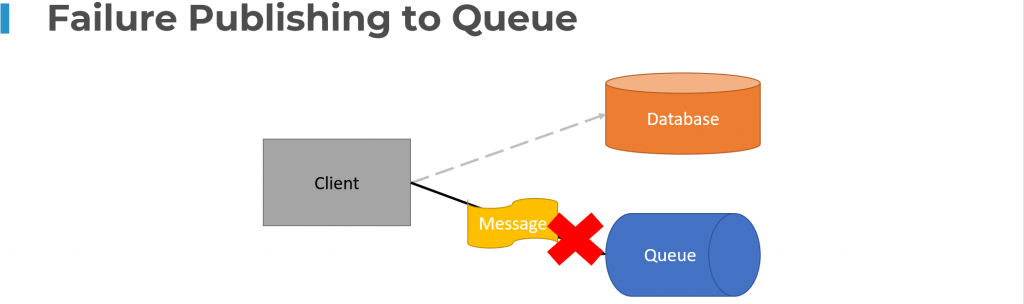
This could have some serious implications and cause inconsistencies or breaks of workflow between services in a long-running business process.
The Outbox Pattern solves this problem by writing the messages to be published to the database with your state changes within the same transaction. Separately a “Publisher” process will pull the messages from the database and then send them to your Message Broker or Queue.
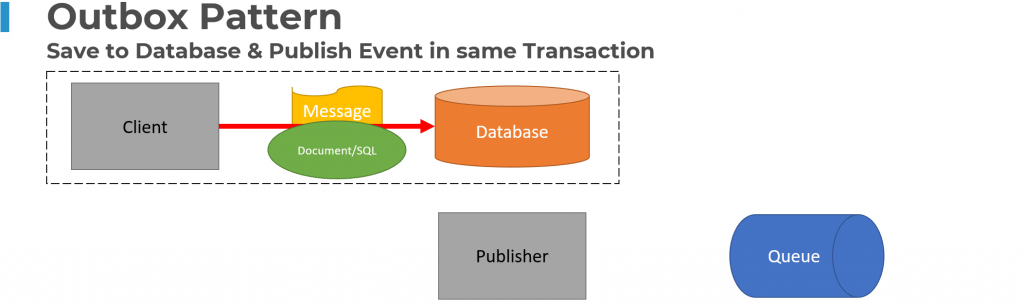
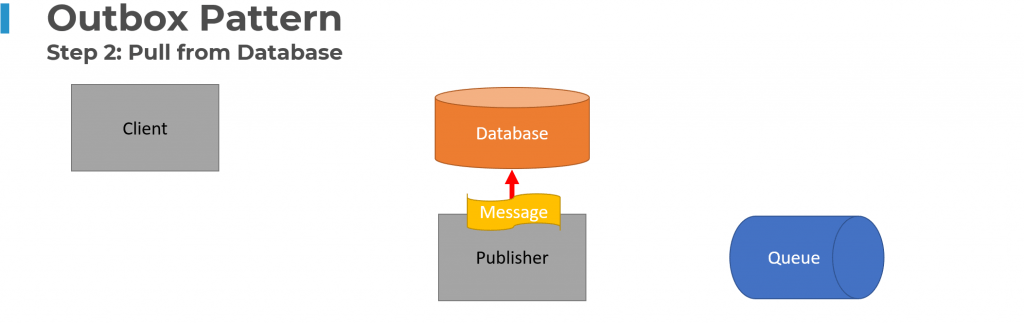
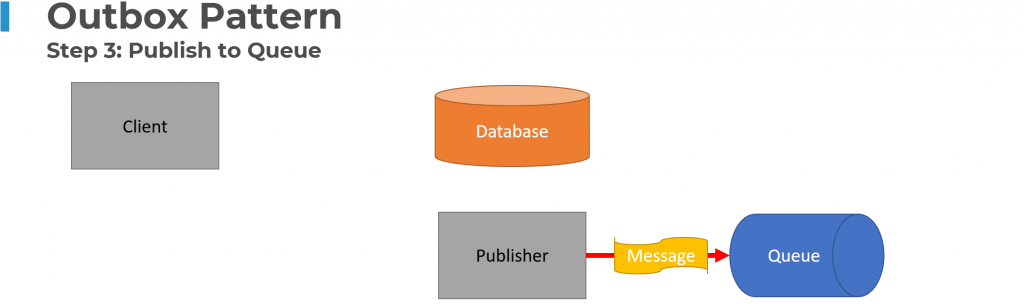
The outbox pattern is one of my top patterns for event driven architecture if you need to reliably publish events.
For more in on the Outbox Pattern, check out my post and video with code samples of how it works.
Idempotent Consumers
Most Message Brokers support “at least once messaging”. This means that a message may be delivered to a consumer at least once. In other words, it could deliver a message to a consumer more than once.
Processing a message more than once could have a negative effect that what is intended.
There are many different reasons why a message could be delivered more than once, but as an example, one reason is using the Outbox pattern described above. When the Outbox Publisher pulls a message from the database, publishes it to the Message Broker or Queue, it then must delete the record from the database. If for some reason this fails, then the record will still exist and the Outbox Publisher will ultimately send the message again to the broker.
Idempotent Consumers are able to handle processing the same message more than once without any adverse side effects.
Some consumers may be naturally idempotent. Meaning how they react to consuming a message can occur multiple times and they do not have any side effects.
For consumers that would have side effects, in order to handle duplicate messages, the key is to record a unique identifier (Message-ID) for each message that has been processed. Just like the outbox pattern, this means persisting the Message-ID along with any state changes in the same transaction to your database.
For more info on creating Idempotent Consumers, check out my post and video with code samples of how it works.
Event Choreography & Orchestration
Many different boundaries are often used together in a long-running business process. The challenges are that if one part of the process failed,
If each service has its own database, there’s no easy way to roll back changes that have happened in the process prior to the failure. How do you handle the lack of a distributed transaction or two-phase commit?
Event Choreography is driven entirely by events being consumed and published by various boundaries within a system. There is no centralized coordination or logic. A long-running process workflow is created by one boundary publishing an event, another consuming it and performing some action, then publishing its own event. Depending on the workflow there could be many services involved but they are entirely decoupled and have no knowledge about how the entire workflow works.
Orchestration provides a centralized place to define the workflow for a long-running business process. It consumes events but may send Commands to a specific boundary, generally still asynchronous via a message queue. Orchestration is telling other services to perform a specific action. Those services in turn publish events that the orchestrator consumes to start the next part of the workflow.
For more info on Event Choreography & Orchestration, check out my post and video with code samples of how it works.
Failures
Transient Faults are unpredictable and could be caused by network issues, availability, or latency with the service you’re communicating with.
In an event driven architecture, you get the benefit of having various ways of handling failures. The most common for transient failures are immediate retries.
For example, if you’re consuming a message and have to interact with some other dependency. It could be a database, a cache, or a 3rd party service. If there is a failure when consuming a message with that dependency, simply retry consuming the message again.
If the failure continues, using an Exponential Backoff allows more time/delay between retries. You may use an immediate retry and if a failure continues, wait for 5 seconds then retry again. If a failure still occurs, wait even longer for 10 seconds and retry again. You could configure this exponential backoff for different intervals and a total number of retries.
If all retries are failing you may choose to move the message that cannot be properly consumed to a dead letter queue. This allows you to continue processing other messages while not losing the message that cannot be processed. Moving a message over to a Dead Letter Queue allows you to attempt to process the message later or investigate why the consumer is failing. You’re not losing the actual message.
Handling failures with various patterns for event driven architecture is required to be resilient and reliable.
For more info on Handling Failures in a Message Driven Architecture, check out my post and video.
Source Code
Developer-level members of my CodeOpinion YouTube channel get access to the full source for any working demo application that I post on my blog or YouTube. Check out the membership for more info.