Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
If you’re developing a Monolith or using a Monolithic Architecture doesn’t mean it needs to be a big ball of mud. Most people equate a Monolith with a Big Ball of Mud because it’s highly coupled and difficult to change. However, you can combat it by defining strict boundaries and logically decoupling those boundaries and the data that each boundary owns. To go even further you can loosely couple by leveraging asynchronous messaging between boundaries. Does this sound familiar? Like Microservices where each service has its defined capabilities and database?
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything that is in this post.
Coupling
When people think of a Monolith or Monolithic Architecture they call it a tangled, spaghetti code mess that’s really difficult to make changes. What is really the issue is that the majority of the system is tightly coupled.
Below is a dependency graph that illustrates how each component/class/module is connected to others.
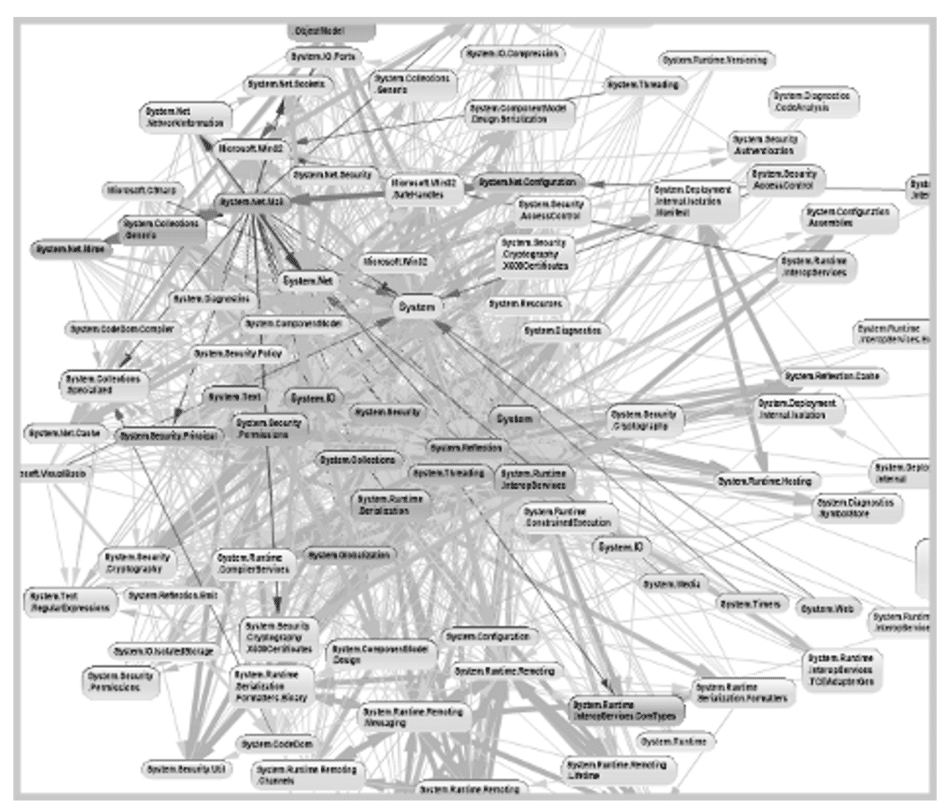
Systems that have many modules that have a high degree of afferent and efferent coupling are bound to be brittle. Changes to one module can have cascading effects on all dependant modules. Coupling is a necessary evil but can be managed.
Coupling exists equally with a microservices architecture. If you’ve developed a microservices architecture that relies heavily upon RPC to communicate between services, the coupling is no different than a monolith that communicates in process. Adding the synchronous calls over the network between services doesn’t magically make coupling go away. You’ve simply developed a distributed monolith, not microservices. If anything, communicating over the network via RPC makes things worse. Why? Check out my post REST APIs for Microservices? Beware!
Boundaries
Defining service boundaries is one of the most important aspects of designing a system, yet getting them “right” is incredibly difficult. There are a lot of tradeoffs that determine where those boundaries should lie.
Services should own a set of business capabilities and data. You may have services that other services boundaries need for query purposes, but a single service should own that data because of the capabilities it provides.
If you think about an existing monolithic architecture or a distributed monolith (bad microservices), let’s represent it by this large turd pile (poop emoji).


What you want to develop are smaller turd piles. Decomposing a large coupled system into smaller units. Each is a service boundary.
Another way to visualize this is to think of a piece of cake as a large high coupled system. The cake may be using a layered architecture but still has a high degree of coupling. To decompose you want to cut out a piece of the cake.

For more info on defining services boundaries, check out my post Context is King: Finding Service Boundaries
Loosely Coupled Monolith
The structure of a monolith that has well-defined service boundaries means that each boundary must first own its own data. If you’re developing a monolith this means that you may still have a single database instance, but the schema (tables, collections, etc) is only accessed by that boundary. No other boundaries are able to access them directly from data storage.

Obviously, boundaries will need to communicate so they can interact with each other. If you want to minimize coupling between boundaries, then a solution is to use asynchronous messaging. This means introducing a message broker that your monolith is sending messages to and also receiving.
Messages are contracts. They are simple DTOs that represent Commands and Events. This is why in the above diagram you see that the implementation for any service boundary is only coupled to the contracts of other service boundaries.
As an example of creating an HTTP API, it would host all the different service boundaries. each defines all its routes and dependencies within it. It can send commands and publish events to the message broker. Simply for scaling purposes, I’ve illustrated another top process as the Message Processor. It’s using the exact same code as the HTTP API. It will be connected to the message broker to consume messages and then dispatch them in-process to the appropriate boundary for the messages to be handled.
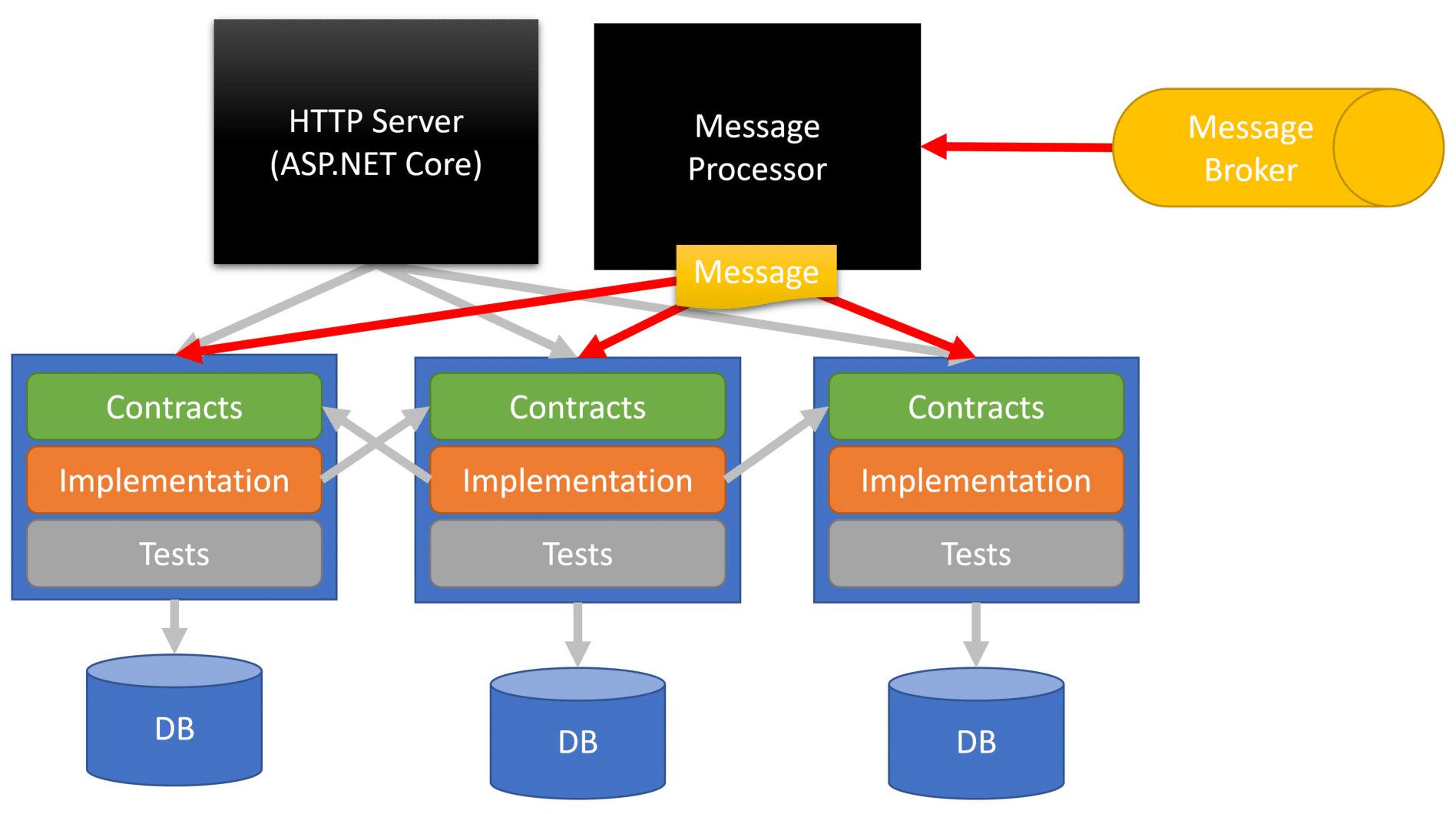
As with any monolith, if you need to communicate synchronously between boundaries, you can do so behind interfaces and functions which live within the contracts projects.
Deployment
The difference between a loosely coupled monolith and microservices at this point becomes a deployment concern. Each has well-defined boundaries and communicates primarily via asynchronous messaging. If you needed to separate a boundary within your monolith because you want to scale it differently or want it to be independently deployable, then you can go down that road, but with added complexity. Check out my post on scaling a monolith horizontally before you go down that road, however.
Monolithic Architecture
A monolith does not need to be a big ball of mud. It does not need to be a highly coupled pile of spaghetti that is difficult to change. Define service boundaries and limit direct synchronous communication as much as possible while leveraging asynchronous messaging.
Source Code
Developer-level members of my YouTube channel or Patreon get access to the full source for any working demo application that I post on my blog or YouTube. Check out the YouTube Membership or Patreon for more info.