Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Concurrency in a multi-user collaborative environment can be challenging. However, understanding the use case is crucial in picking a solution for handling concurrency. Let’s dive into different solutions for concurrency control in various situations.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Last Write Wins
The first strategy is that there is no strategy. That might sound odd, but not all situations require concurrency controls.
“Last write wins” means whatever the client writes to the database will succeed. If you’re using a relational database, this means if you’re updating data, you’re overwriting the previous state. If you’re Event sourcing with an append-only log, you’re appending regardless of the previous state.
If two users make a call to your API, which interacts with the database, the User1 interaction might occur first and update data in your DB.
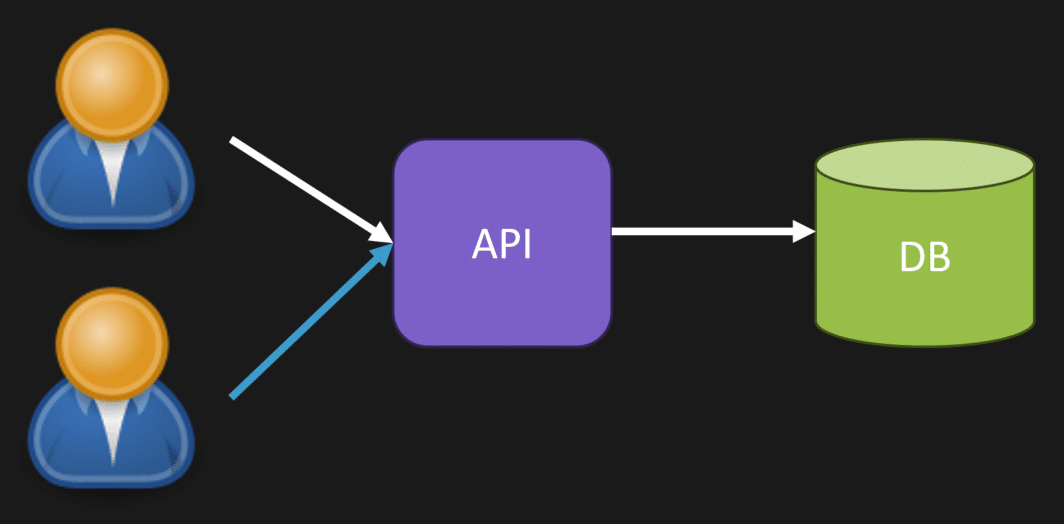
However, milliseconds later, the User2 interactions might hit the same DB, overwriting the User1’s changes. The last user/write won (User2).

Locking
A great example of locking exists in the real world for concurrency control. I placed an online order to a local store. They had one of the items available, and I placed my order for in-store pickup. An hour or so after my order was placed, I received this email.
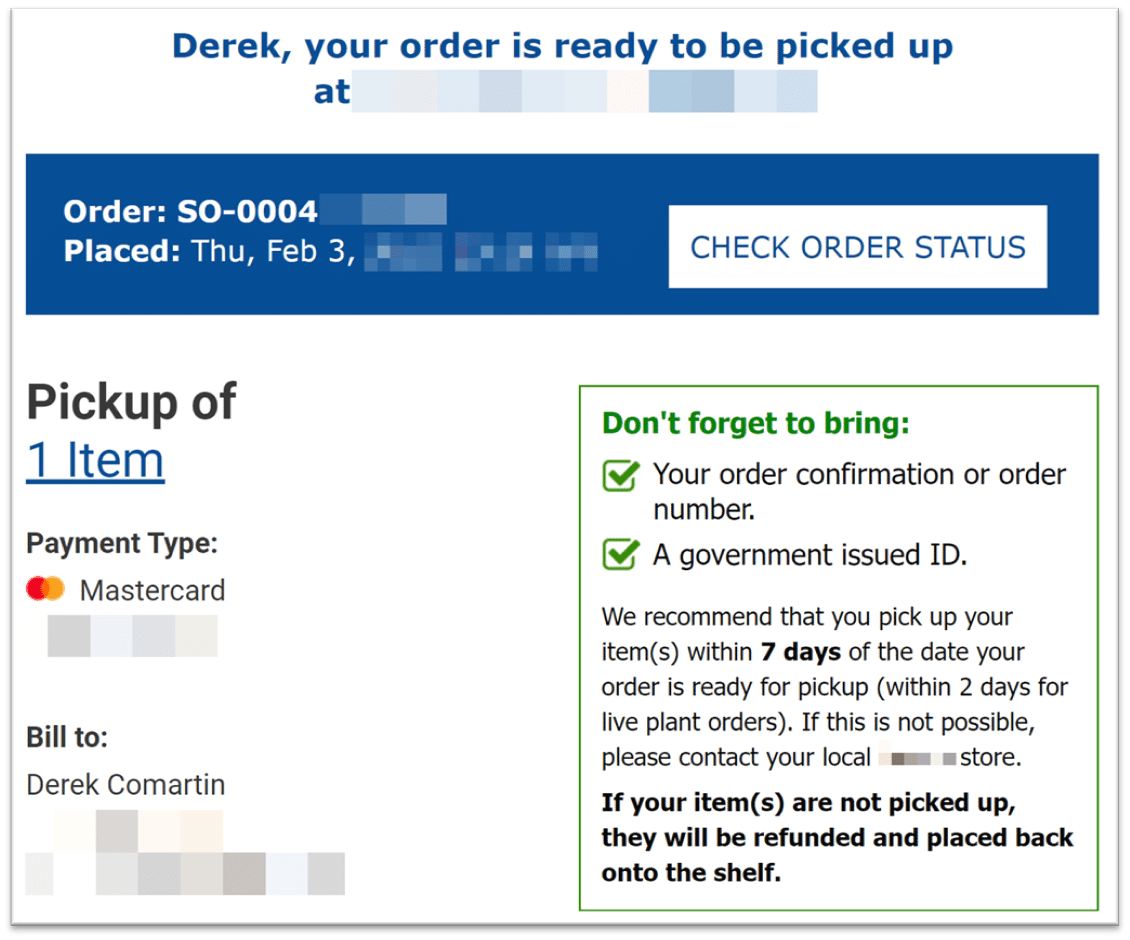
This email is showing us a real-world limited time-bound guaranteed lock. Someone in the store had to physically take the item I ordered off the shelf and bring it to a separately location so other customers couldn’t purchase it. Once that happened, I received this email saying my item was available for pickup. The email states that I have 7 days to pick up the item otherwise my order will be refunded and the item will be placed back onto the shelf.
This means that they create a lock on the item for 7 days. After 7 days, if not picked up, the lock is released.
You might think this is pessimistic locking. We can lock the database record within a database transaction and then release the lock with a commit/rollback.

However, in a situation like this, we can’t solve it by having database transactions, as we likely can’t keep the database transaction open for seven days. We can apply this same pattern in code without holding a transaction.
Here’s how this works. Step 1 is our order is placed.
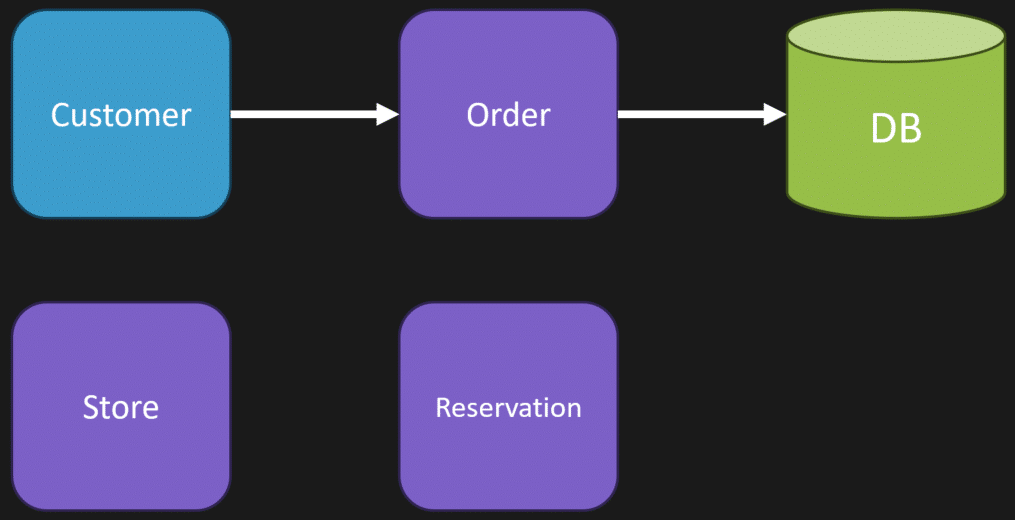
Once the store gets the item off the shelf, they’ll create a reservation. We can record that reservation
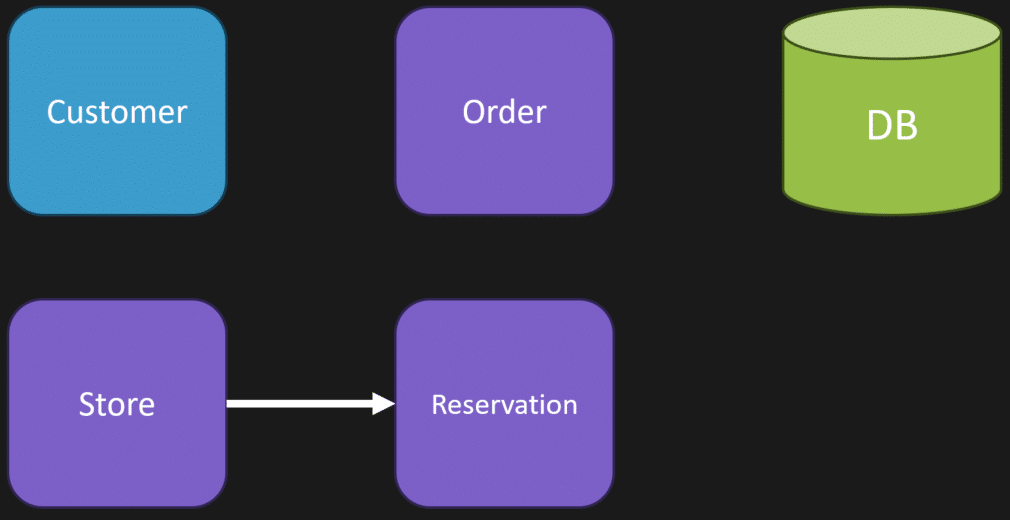
Then, when I come into the store to pick up the item, we can clear the reservation and update our order as complete.
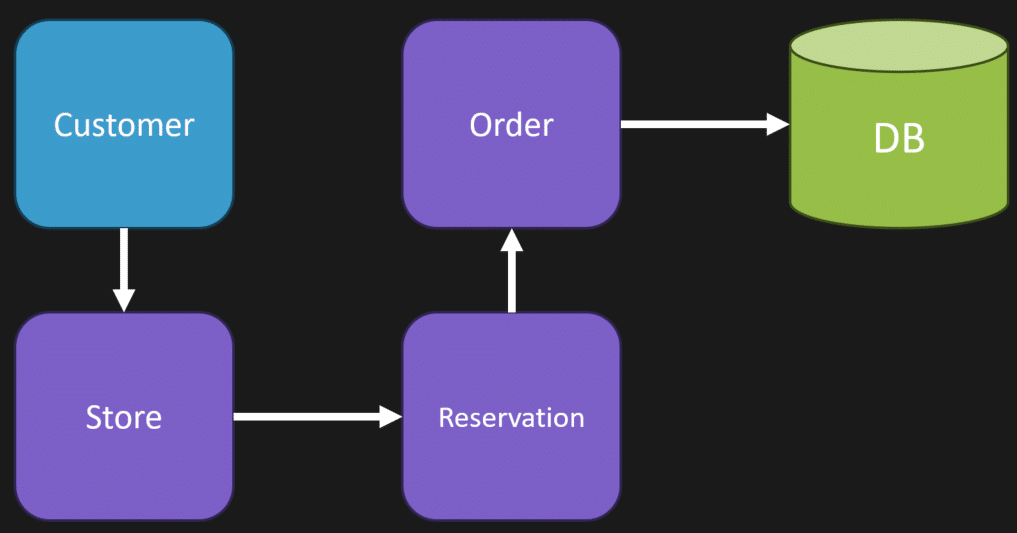
If I do not pick up the item after 7 days, we can release that reservation, and the item will be available for someone else to purchase. If you’re interested more about this concept, check out my post Avoiding Distributed Transactions with the Reservation Pattern
Optimistic Concurrency
Most people are probably familiar with optimistic concurrency for concurrency control. This means that when a user/client attempts to make a state change, they must provide some information along with the change to indicate what they think the current data should be. Often this is done with versions or date/times associated with the data being changed.
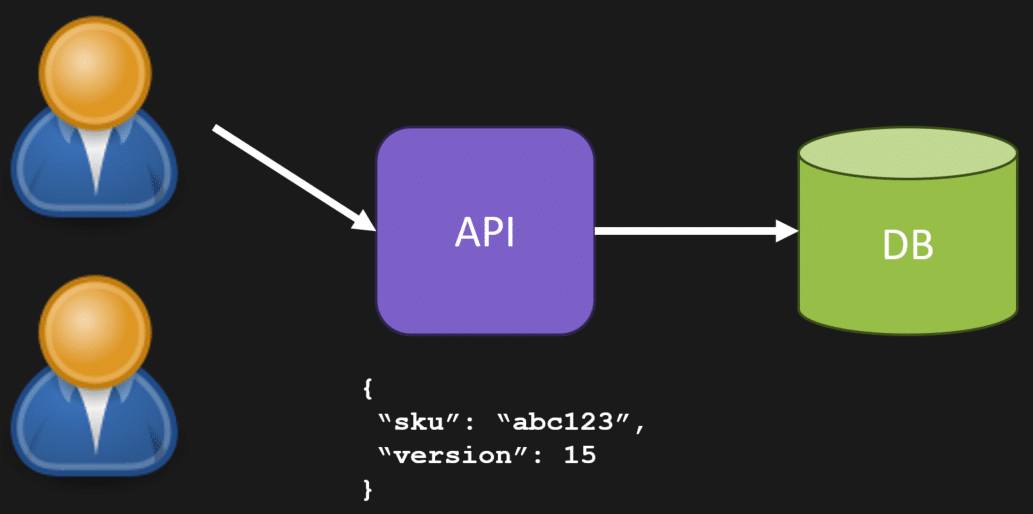
As an example, if a user selects data, it also gets the current version (15). When it sends an statement to modify the state, it also indicates that the version it last new about was 15. If the current version is 15, then the call succeeds. If the version is not 15, then it fails because another client/process has since changed the state and other is a new version.
If you want more details on implementation with examples, you can check out my post Optimistic Concurrency in an HTTP API with ETags & Hypermedia
Single-Threaded
Instead of using a database or some external source, you can also use a single-threaded model, even if you’re in a distributed environment. Actors or actor-based solutions fit this as a solution for concurrency control.
Actors are single-threaded. So, if a user executes a request, it only executes that single request until it finishes. This can be a strategy if you partition work by how you want to handle concurrency. For example, if you have an actor handling all interactions in a unique product/inventory, you’ll only be able to execute a single action at a time for a specific product.
In a distributed environment, tools like Microsoft Orleans execute the actor where it resides in memory, regardless of where the request is coming from.
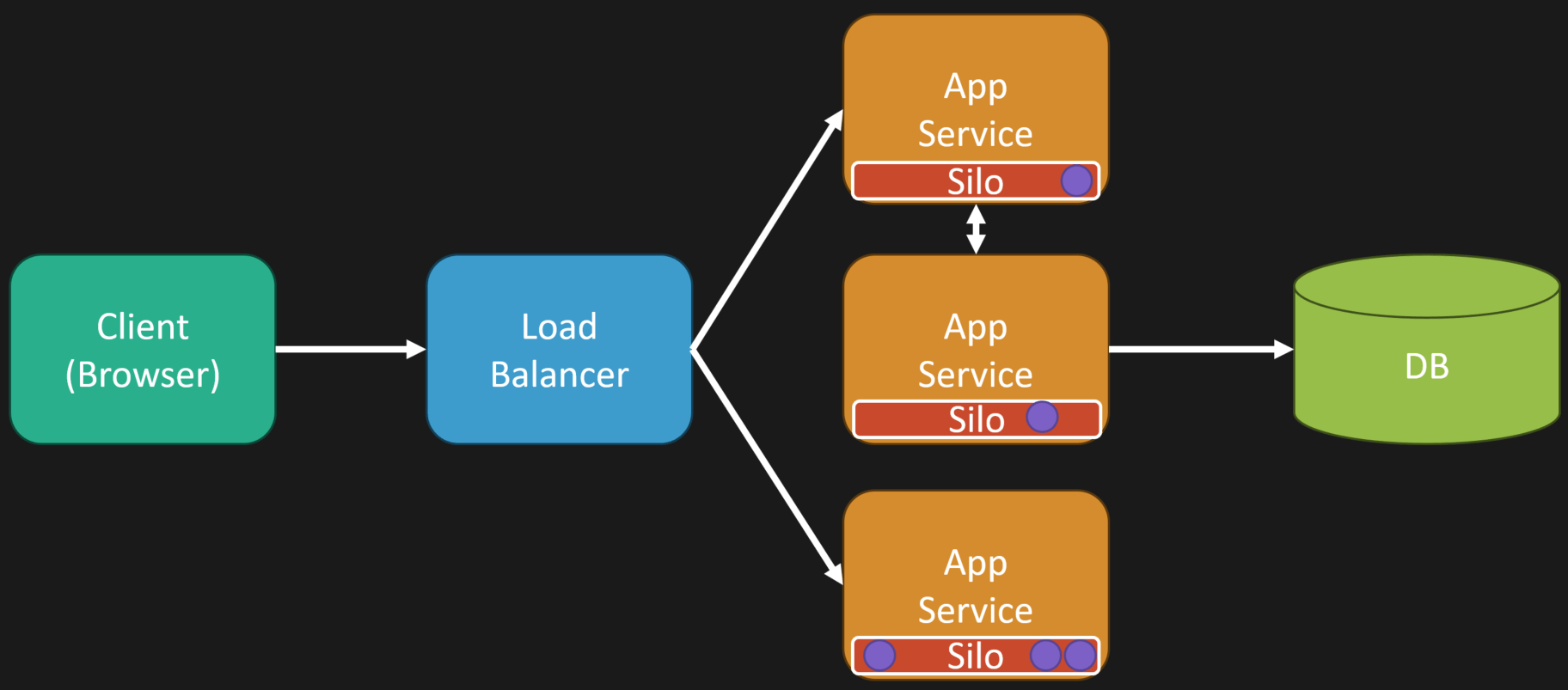
So even in a distributed environment, you might have an app service behind a load balancer that takes the request. However, the interaction it’s having with a virtual actor (grain) might reside on another app service (silo). The interactions are seamless in your programming model and allow for single-threaded nature of actors.
For more on (virtual) actors and Orleans, check out my video Cloud Native Objects for High Scale & Performance
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.