Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Event Sourcing is seemingly constantly being confused with Event Driven Architecture. In this blog/video I’m going through a popular blog post that explains various points that are very valid, however, they are conflating Event Sourcing with Event Driven Architecture. Event Sourcing is about using events as the state. Event Driven Architecture is about using events to communicate between service boundaries.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything that is in this post.
Event Sourcing vs Event Driven Architecture
There is a blog post that keeps making its round over various news or social media sites every year or so that gets a lot of attention. The issue is it conflates Event Sourcing and Event Driven Architecture.
To be clear, Event Sourcing is about using events to represent state. In Event Driven Architecture, events are used to communicate with other service boundaries.
Event Sourcing
Event Sourcing is a different approach to storing data. Instead of storing the current state, you’re instead going to be storing events. Events represent the state transitions of things that have occurred in your system. If you want more details on exactly what Event Sourcing is, check out another post I’ve written Event Sourcing Example & Explained in plain English
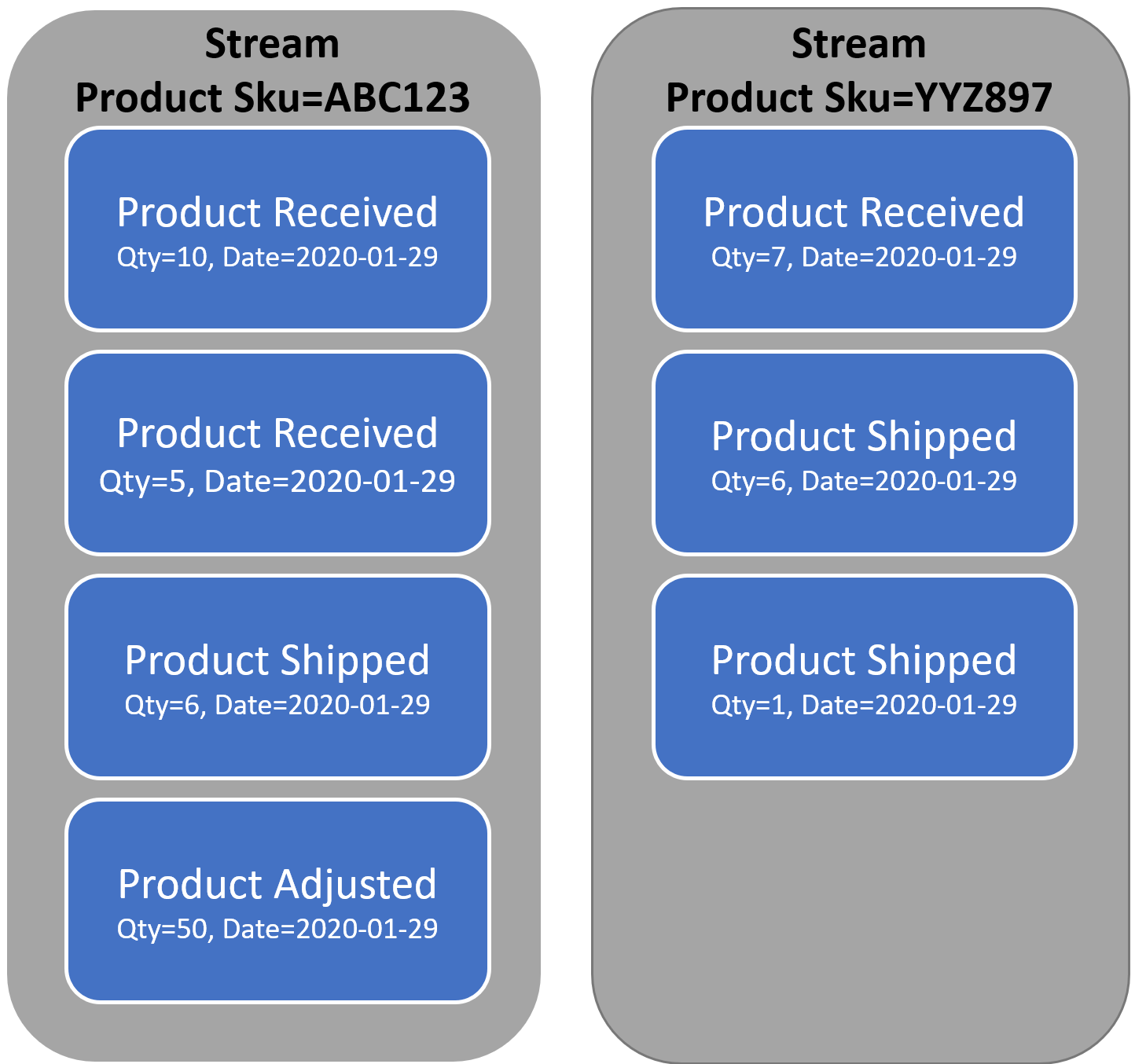
Event Driven Architecture
Event Driven Architecture is about using events as a way to communicate with other service boundaries. Generally, leveraging a message broker (or event log) to use the Publish/Subscriber pattern. Publish events and consume events asynchronously within other boundaries. When publishing an event, there may be zero or many consumers. The publisher is unaware of who is consuming an event. Consumers are unaware of each other. Event Driven Architecture is a way of loose coupling between service boundaries.
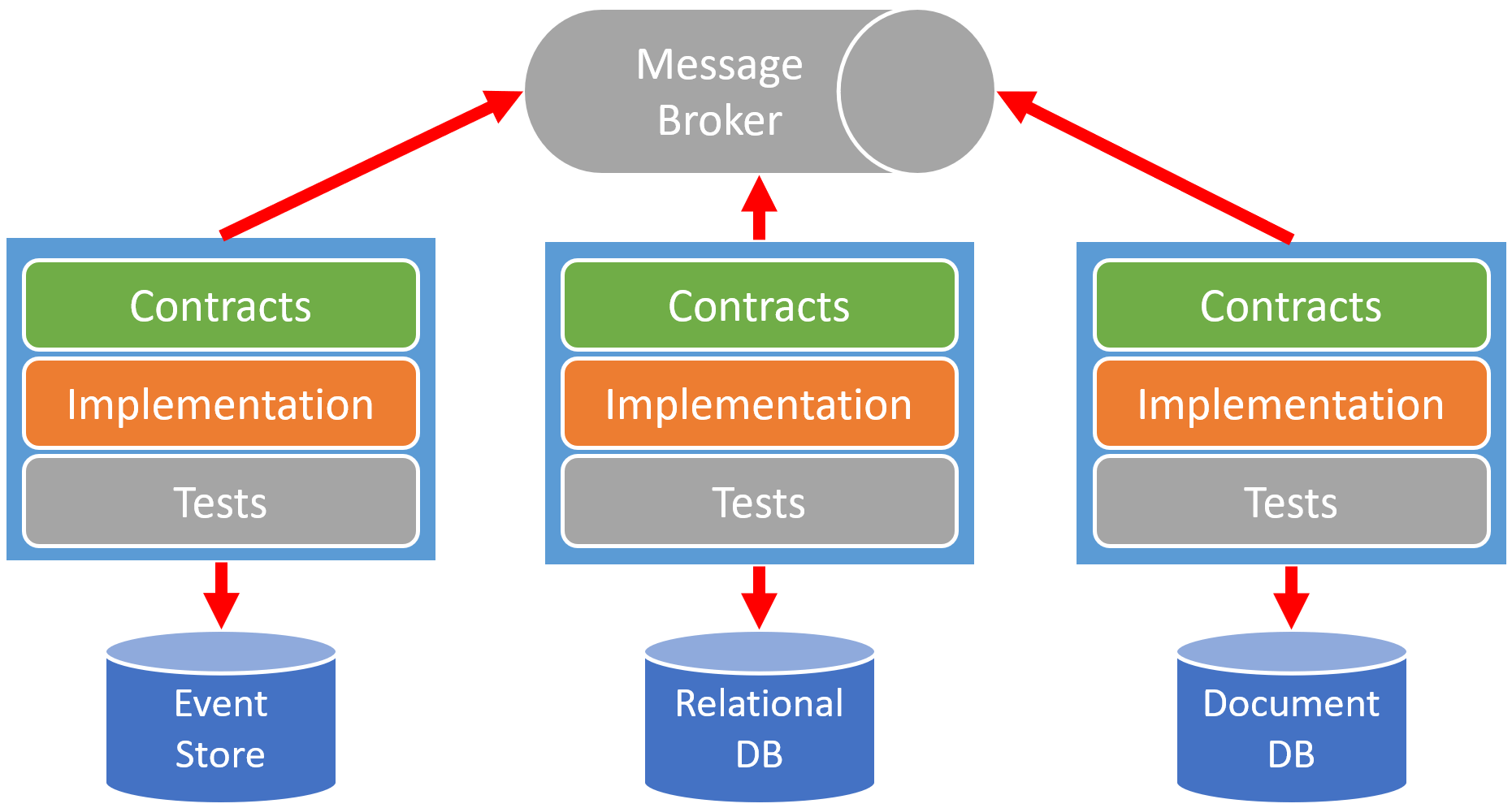
Purely based on these two definitions, you might already start to see why Event Sourcing vs Event Driven Architecture isn’t even a valid comparison.
Counterpoints
The blog post illustrates having multiple services both publish and consume events from an event log (I’m going to assume Kafka).
The idea of a keeping a central log against which multiple services can subscribe and publish is insane. You wouldn’t let two separate services reach directly into each other’s data storage when not event sourcing
Yes, that’s insane. Don’t do that. If you’re using the event log for communication between service boundaries AND to represent state within boundaries, that’s a terrible idea. But that’s has nothing to do with Event Sourcing but rather mixing two concepts: state persistence and communication.
Under “normal” development flows, you operate within the safe, cozy little walls which make up your service. You’re free to make choices about implementation and storage and then, when you’re ready, deal with how those things get exposed to the outside world.
Exactly! This is exactly what you should be doing. A service boundary owns its data and defines how it exposes it. If you’re conflating Event Sourcing (state) with Event Event Architecture (communication) you can see how this would violate that.
For one, you’re probably going to be building the core components from scratch. Frameworks in this area tend to be heavy weight, overly prescriptive, and inflexible in terms of tech stacks.
Now it depends on which side of the question they were referring to. If we’re talking about Event Sourcing, there really isn’t any “framework” required. For example, if you’re using EventStoreDB, you can use their SDK directly. In many of the examples I use, I’m creating a Repository that is reading from an event stream and replaying the events to build up an Aggregate Root to the current state. From there the Aggregate Root generates new events and those are persisted back to the Event Stream from the Repository. There isn’t any framework or library code required other than the SDK Client from the Event Store.
With Event Driven Architecture, you absolutely want to use a library for messaging. I say this because there has a lot of patterns and concepts that come with using Event Driven Architecture. Messaging libraries provide these patterns and concepts for you so that you don’t have to implement them yourself. In the .NET space, libraries like NServiceBus, MassTransit, Brighter all come to mind that handles things like the Outbox Pattern, Process Managers, Fault Tolerance, Retries, Dead Letter Queues, and more.
If you have a UI, it generally needs to play along with the event driven aspect of the back end. Meaning, it should be task based.
Absolutely. Task-Based UIs will guide the end-user to perform specific tasks usually in some type of workflow. Tasks (or actions, commands) are explicit and allow you to then derive what intend to do where you can then generate the appropriate event from that task. CRUD isn’t explicit. You do not know the intent of the end-user when you provide them with a CRUD-based UI. For more on task-based UIs, check out my post Decomposing CRUD to a Task Based UI.
A super common piece of advice in the ES world is that you don’t event source everywhere *. This is all well and good at the conceptual level, but actually figuring out where and when to draw those architectural boundaries through your system is quite tough in practice.
Defining boundaries is one of the most important things to do when developing and designing a system. Yet it’s one of the hardest things to do. In my experience, the real core of your solution space is where the complexity lies. On the outer edges, there are boundaries that are often in a supporting role. These supporting boundaries may either be very generic and can be something you buy off the shelf and integrate with, while others you may want to develop but can simply be CRUD. Each boundary defines how it persists state best on the requirements and what may fit best. Some boundaries might be best suited for a relational database, others a document database, or some an Event Store. But again that is about persistence and state. Each boundary decides its persistence. For communication, you can still leverage an Event Driven Architecture even though some boundaries are using a relational database. Again, don’t conflate needing to do Event Sourcing for persisting state in order to communicate via events.
We made it about a month before a shift in focus caused us to hit our first “oh, so these events are no longer relevant, at all?” situation. Once you hit this point, you’ve got a decision to make: what to do with the irrelevant / wrong / outdated events.
With Event Sourcing, the concern about versioning events is done within a single boundary that owns and uses those events for state. There are different strategies for versioning with event sourcing and how you want to handle “old” events.
One thing I’ve noticed however is that “no longer relevant” doesn’t actually happen all that often. If you’re using established business concepts, they don’t often become irrelevant. Usually, events that become irrelevant are because the developers defined the events and are generally based more on technical concerns rather than business concepts.
Once your data grows to the point where you can no longer materialize from the ledger in a reasonable amount of time, you’ll be forced to offload the reads to your materialized projections. And with this step comes materialization lag and the loss of read-after-write consistency.
This is a valid concern when you’re using Event Sourcing and creating Projections (a read model) that is generated asynchronously. There are various strategies to handle this that I’ve talked about in a video about Event Consistency. However, to point out, this isn’t specifically about Event Sourcing Projections but any type of system where you don’t have a read-after-write consistency. This can include using a database that is eventually consistent and has replication lag.
Event Sourcing vs Event Driven Architecture
Hopefully, this clarifies the differences of Event Sourcing vs Event Driven Architecture. While the original blog post has some valid points, the issue is it’s pointing those problems at Event Sourcing, when in many cases it’s because it’s conflating the two.
Event Sourcing is about using events as state. Event Driven Architecture is about using events to communicate. That’s not to say that Event Sourcing or Event Driven Architecture don’t have their difficulties, they do. However, if you treat them for what they are, you eliminate a whole set of problems the original post had because you’re not conflating the two. They are completely orthogonal from each other.
Source Code
Developer-level members of my YouTube channel or Patreon get access to the full source for any working demo application that I post on my blog or YouTube. Check out the YouTube Membership or Patreon for more info.