Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Cache invalidation is often said to be a hard problem to solve. I don’t think this is true in the context of software systems. Regardless of which caching strategies you use (Write-Through or Cache Aside), the key is to have well-defined boundaries. Other boundaries cannot be modifying data within another boundary directly at the database level. They must access it via the exposed API that forces cache invalidation or updating. Cache Invalidation doesn’t need to be a difficult problem.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything that is in this post.
Caching Strategies
There are two common caching strategies: Write-Through and Cache Aside. I’ll explain how they both work and how a key aspect of cache invalidation is defining boundaries.
Write-Through
The Write-Through caching strategy is about writing to the cache immediately when you make a state change to your primary database.
For example, a client makes an HTTP request to your App Service that is an HTTP API. Our Application calls our primary database and makes some type of state change. In a relational database, this could be an UPDATE/INSERT/DELETE statement, or in a document database, this could be adding an item or updating an item from a collection.
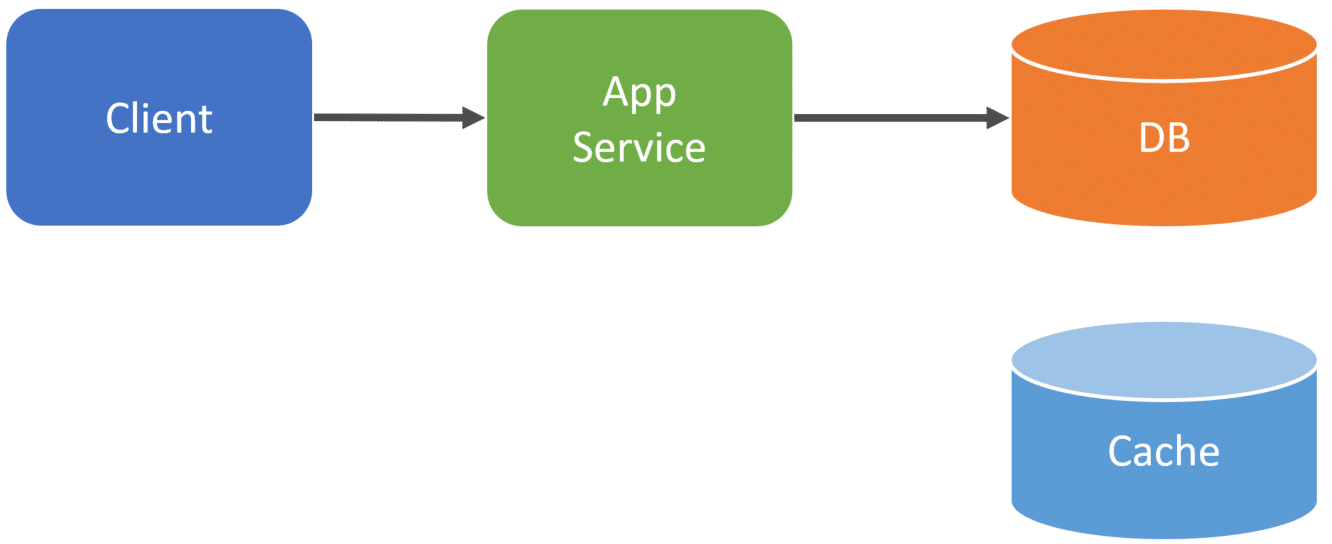
Immediately after within the same process, we update our cache with the latest version that reflects the state change we just made. Again, this is all done within the same process of the initial HTTP request to our App Service.
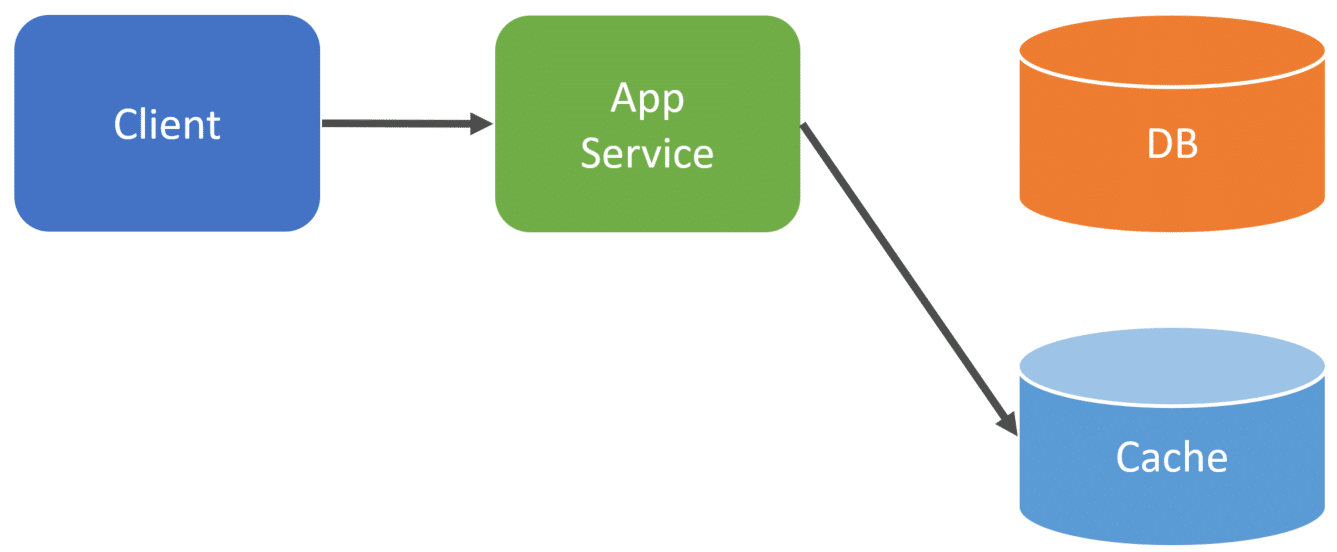
The benefit of this strategy is that you’re always keeping your cache up-to-date as soon as you make any changes to your primary database. The drawback is since your cache is constantly being updated, you’re caching data that may not be read/accessed very often as time goes on.
A pitfall with this strategy (and others) is that you must run all state changes through your Application or Service. This is because it is the one handling updating your cache. You cannot bypass your App/Service and manually update data directly to the database, otherwise, your cache will be out of sync and not up to date.
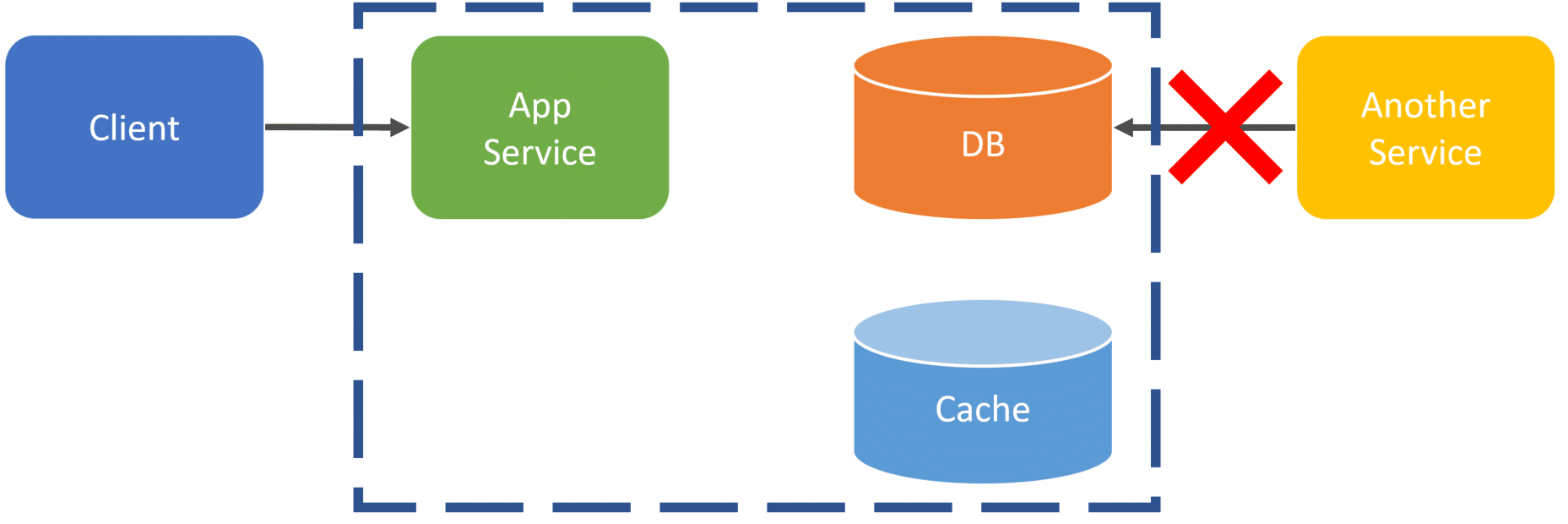
This means you cannot have another application or service make any state changes to your database without going through your API. I think most developers are used to using a client tool to manually connect to a database and make some type of data changes. Again, this cannot happen as you will not be updating the cache.
Cache Aside (Lazy Loading)
Another strategy for caching is called the Cache Aside or Lazy Loading. The way this works is you query the cache for the data you’re looking for. If there is a cache miss, meaning the data isn’t in the cache, then you then query the primary database. After you get the data from the primary database, you then write that data to your cache. Often times you’ll provide an expiry or time-to-live with the cache value.
To illustrate this, we have a request from our client to the application/service. Our App/Service makes a call to our Cache.

If the data is in the cache, we use it. If not, we then query our primary database to get the data we need.

Now that we have the data, we then write that data to our cache so the subsequent request will get the cached value and not have to hit the primary database.
As mentioned, we might set an expiry on the cache so we only cache it for a period of time. once it expires and is automatically purged from the cache, the next client that requests that data will go through this cycle again.
Now the issue with cache invalidation here is that we must update or remove the item from the cache when any write or state change happens to our primary database. To do this, we can leverage an event driven architecture to publish an event when a state change occurs. We can then subscribe (consume) that event to do the invalidation asynchronously.
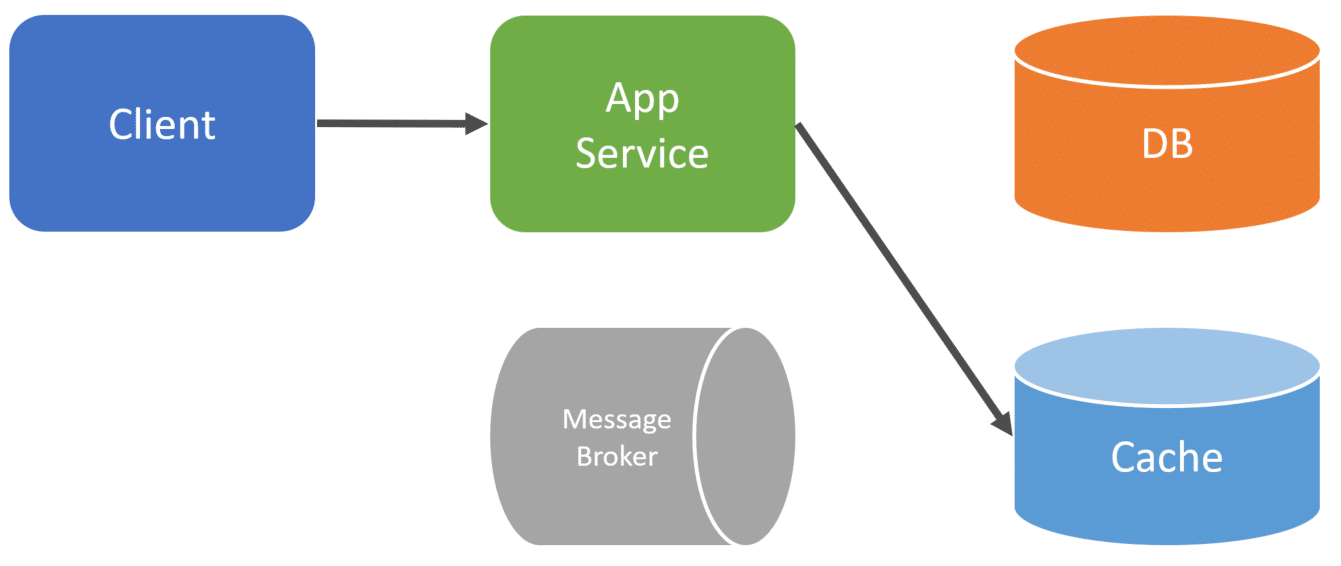
To illustrate this, when the client makes a call to our Application or Service and we make a state change to our database.
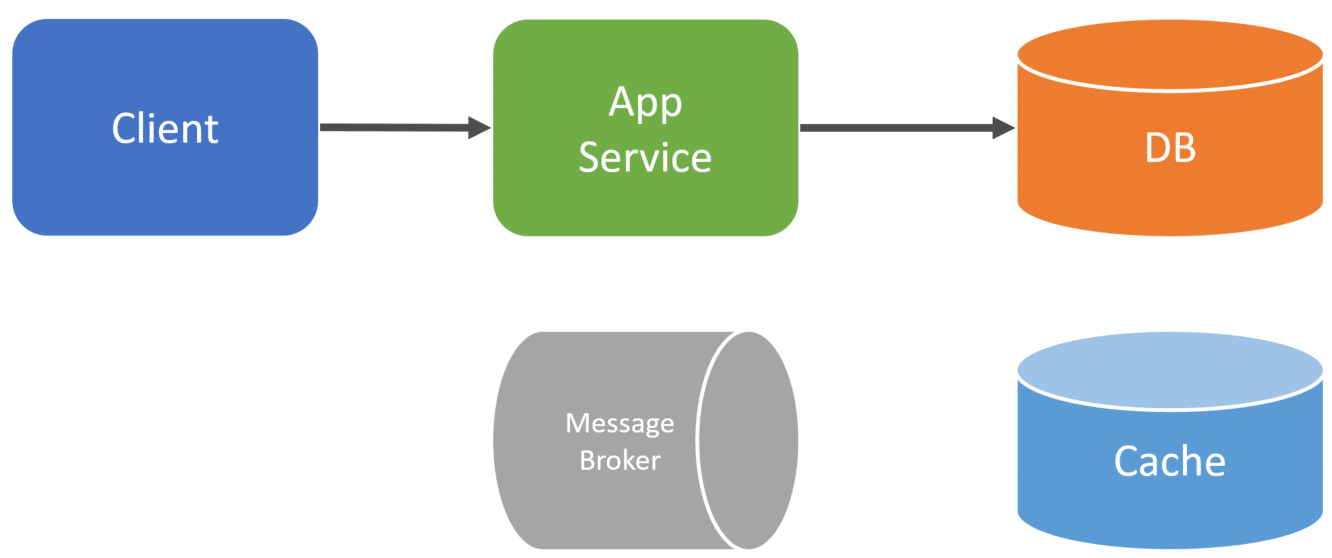
Within the same process of the request, we will also publish an event to a message broker.
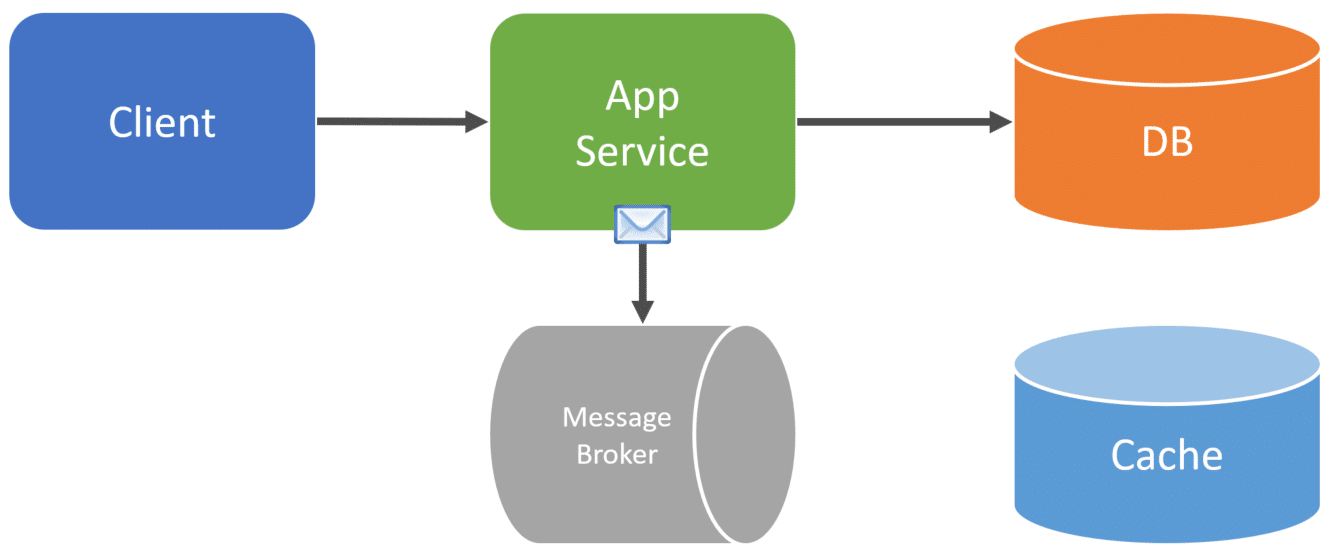
Now the request is ended with the client, asynchronously in another thread or another process entirely, we can consume that message from the broker.
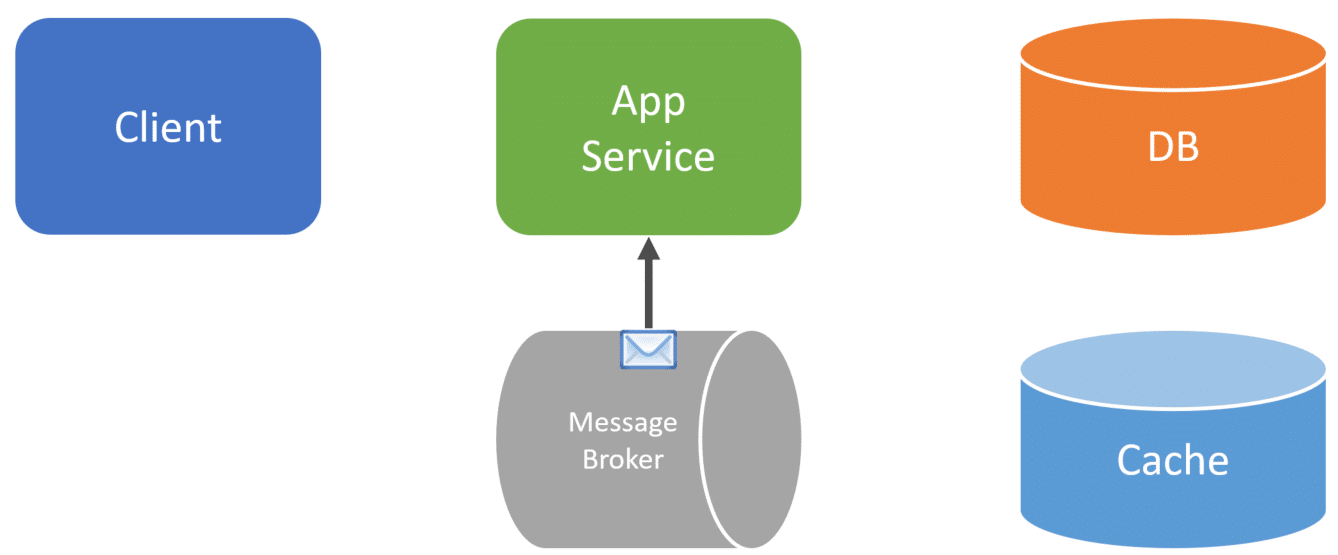
When we consume that message, we can then call our cache to remove the data. Or we could also call the primary database and update the cache.

Since we’re using the cache aside method, you could simply remove it from the cache, and the next call that tries to get it with a cache miss will get it from the database and write it to the cache.
Just as with the write-through, you cannot bypass your application/service since it is the one publishing the message that will cause the invalidation. Depending on your requirements, if you have defined a short expiry for the cache item, it may be acceptable to do so, but this is entirely dependent on your context.
Boundaries
The key is boundaries and having your application or service do the invalidation. If you have many different applications or touchpoints that hit your database or integrate at the database level, then yes I can see how cache invalidation in a software system can be difficult.
However, if you’re defining strict boundaries, cache invalidation doesn’t need to be a difficult problem.
Source Code
Developer-level members of my YouTube channel or Patreon get access to the full source for any working demo application that I post on my blog or YouTube. Check out the YouTube Membership or Patreon for more info.