Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Consistency is critical when working with an event-driven architecture. You must ensure that when you make state changes to your database, the relevant events you want to publish are published. You can’t fail publishing events. Events are first-class citizens, and when events drive workflows and business processes, they rely on this consistency between state changes and published events.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Atomicity
Here’s an example of placing an order. At the very bottom of this method, we publish an OrderPlaced event and then save our state changes to the database.
These last two lines are problematic. The first reason this is an issue is that we have a race condition. We could process the event before the stat is saved to the database. This is more true if there was any code between publishing and saving the database changes.
To illustrate this, on line 24, we publish the event to the message broker.
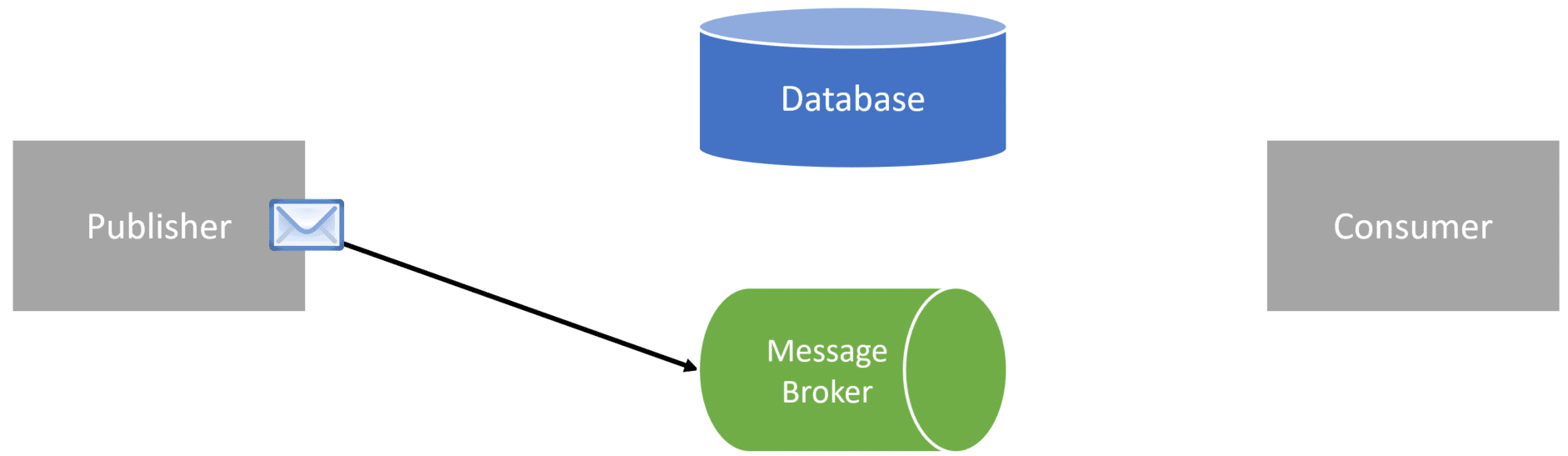
Once the event is published to the broker, we could have a consumer immediately process that message.
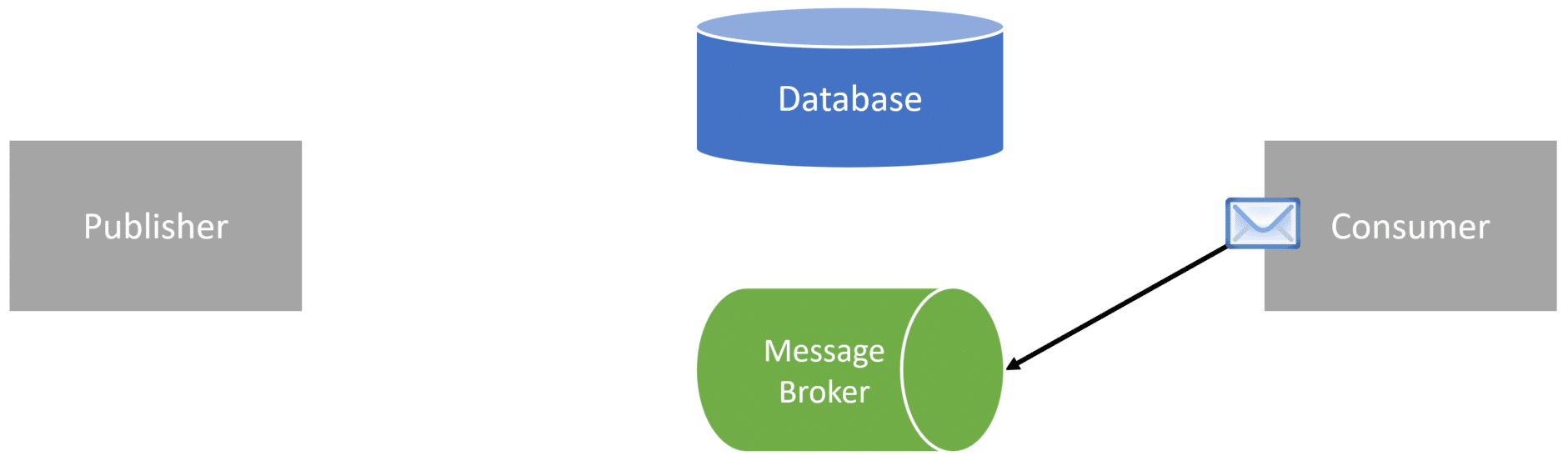
If this consumer was within the same logical boundary as the publisher, let’s say to send out the confirmation email, it might reach out to the database to get the order details.
But since we haven’t yet saved our database changes, the order won’t exist yet in our database.
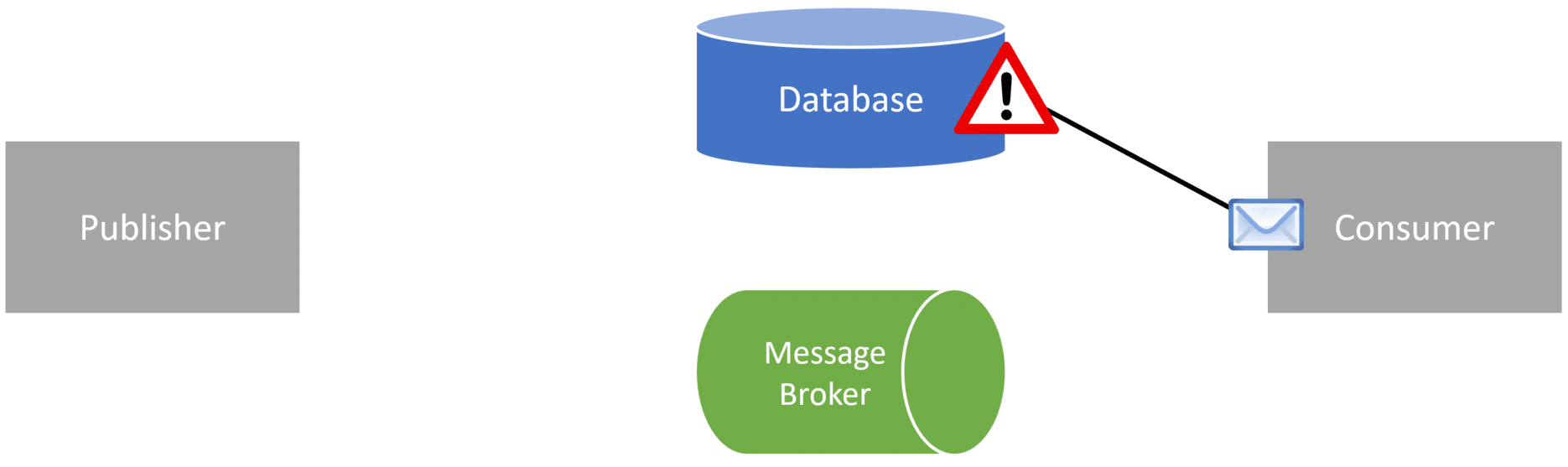
Finally, line 25 is when the order is saved to our database.
But what happens if saving the order to our database (line 25) fails? Now we’ve published an event (which is a fact) that an order was placed, but really, an order wasn’t placed because we didn’t save it.
If we have downstream services that are apart of the workflow, this is misleading and could have many different implications and failures in different services.
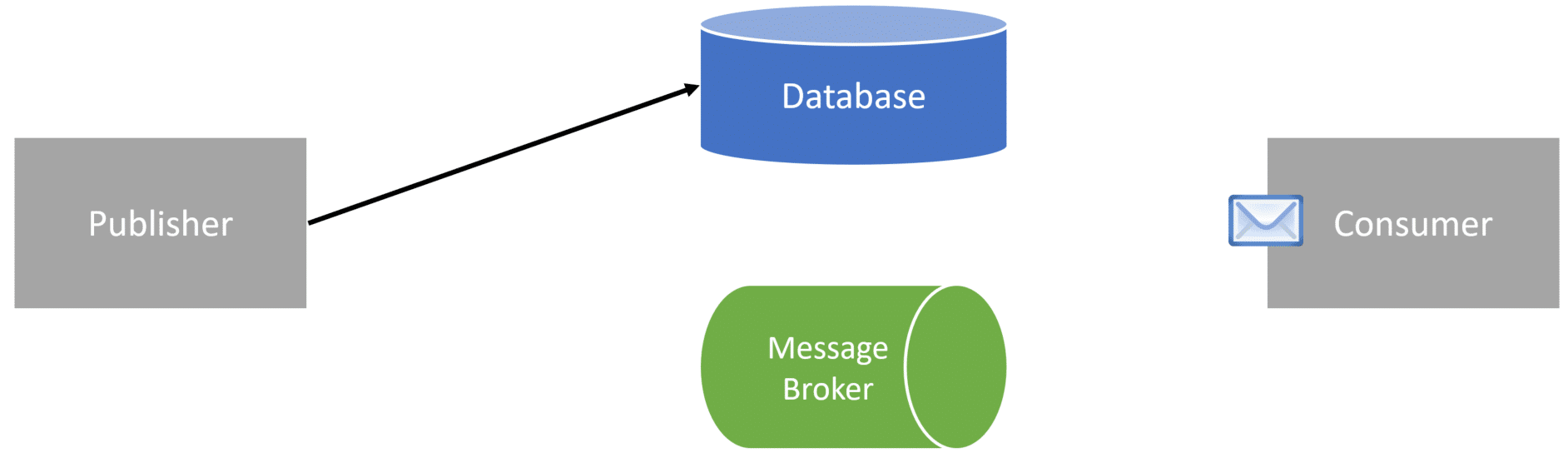
We need to flip the two lines around to avoid a race condition and not publish an event without saving the order.
We still have an issue. Suppose we save the order and fail to publish the OrderPlaced event to our broker. If we have downstream services that are part of a workflow, they’ll never know an order was placed.
We can’t fail to publish an event if we have a state change.
Fallbacks
One solution is to have a fallback. If we can’t publish to the message broker, we have another place to store the event durably.
In my post on McDonald’s Journey to Event-Driven Architecture, they used a fallback for this.

In the example with McDonald’s, they used DynamoDB as their fallback storage. So if they could not publish to their message broker, they would save the event in DynamoDB. I also reviewed Wix.com – 5 Event Driven Architecture Pitfalls, where they used AWS S3 to save events in case of this type of failure.
From there, you’d have some retry mechanism that would pull the data from your durable storage and have it try and publish to your broker.
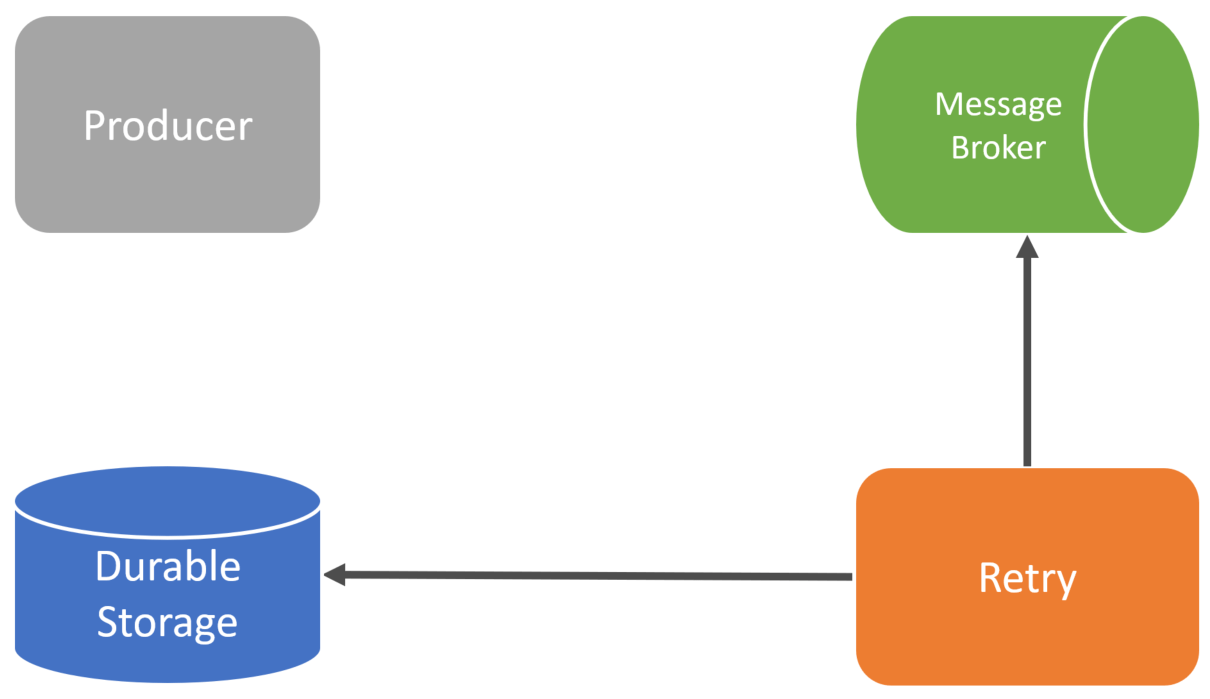
As an example, you could use a retry and fallback policy.
The downside with a fallback is you have no guarantee that you’ll even be able to save that event to durable storage if there’s a failure to publish the event to your broker. There’s no guaranteed consistency.
Outbox Pattern
Another solution, which I’ve talked about before, is the Outbox Pattern: Reliably Save State & Publish Events.
This allows you to make state changes to your database and save the event to the same database within the transaction. Your event data would be serialized in an “outbox” table/collection within the same database as your business data.
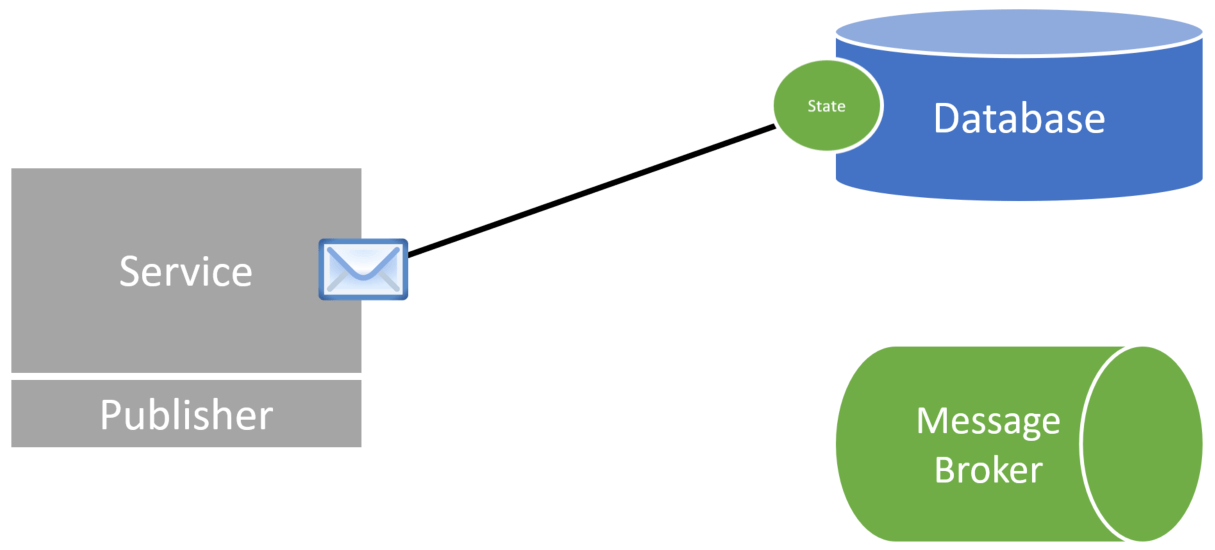
Then you have a separate process that reads that “outbox” table/collection and deserializes it into an event.
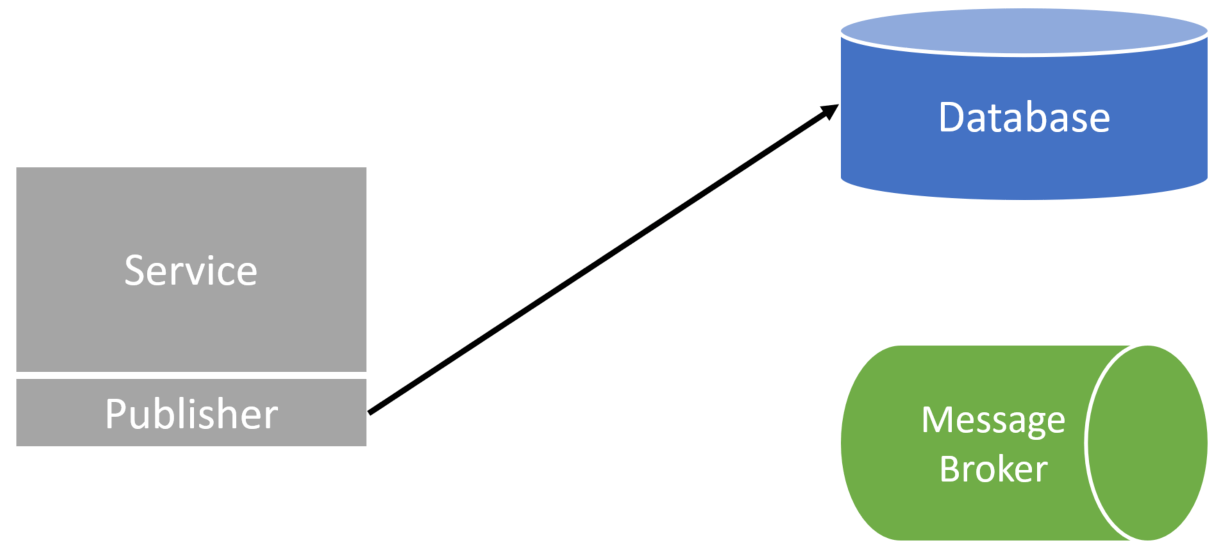
Then it can publish that event to the message broker. If there are any failures in publishing the event, the publisher would simply keep retrying.

Once the event is successfully published, the publisher must update the database to mark that event in the outbox table as being published.
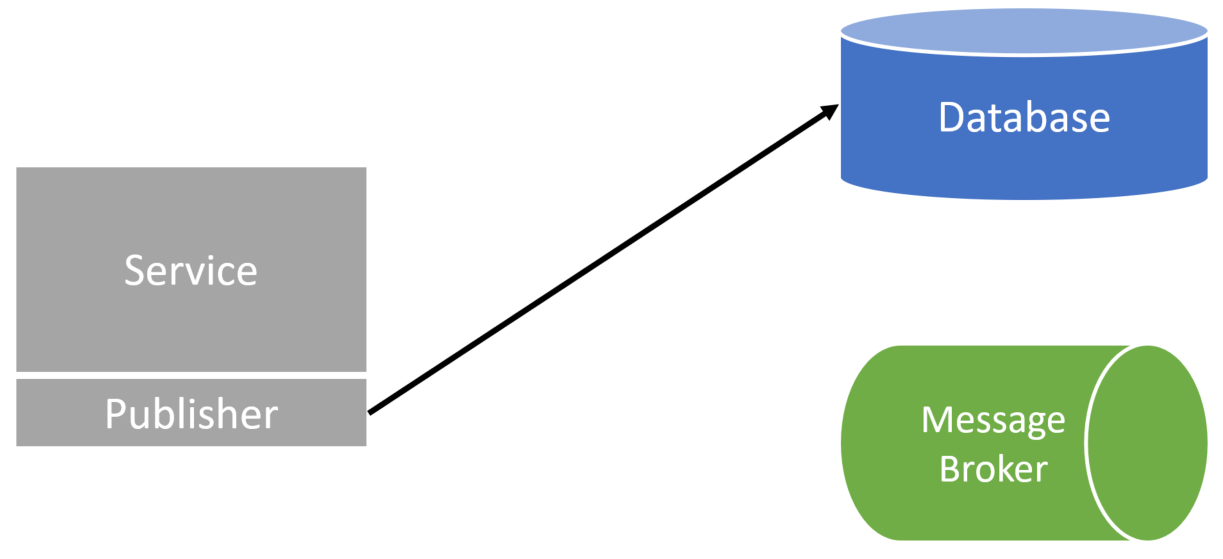
If there is a failure to update the outbox table, this will result in the publisher publishing the same event more than once, which requires consumers to be idempotent.
The downside to the outbox pattern is your adding more load to your primary database since the publisher.
Workflows
There are also workflow engines that provide guarantees of the execution of parts of a workflow. Let’s say workflow with 3 distinct activities: Create Order, Publish OrderPlaced Event, and Send Confirmation Email.
Each one of these activities is executed independently in isolation and the first to execute would create and save our order to the database.
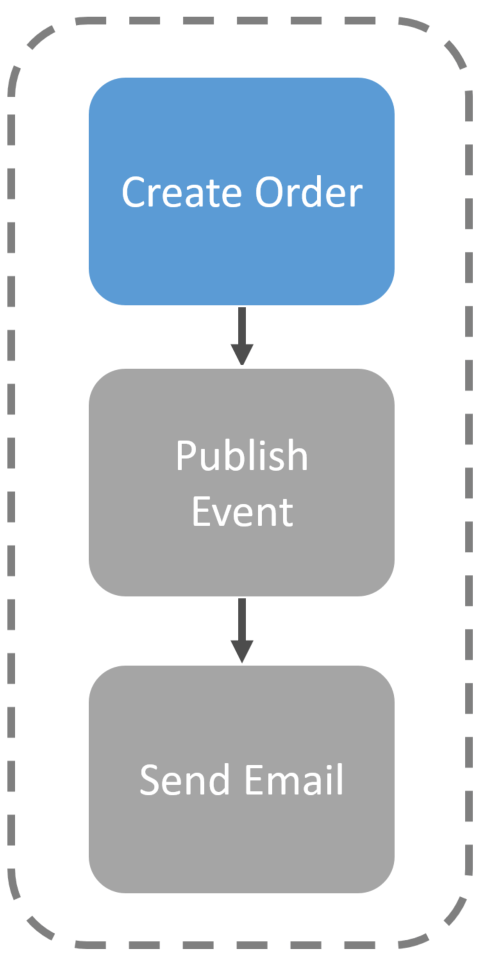
After the create Order activity completes, the Publish Event activity will execute to publish the OrderPlaced event to our broker.
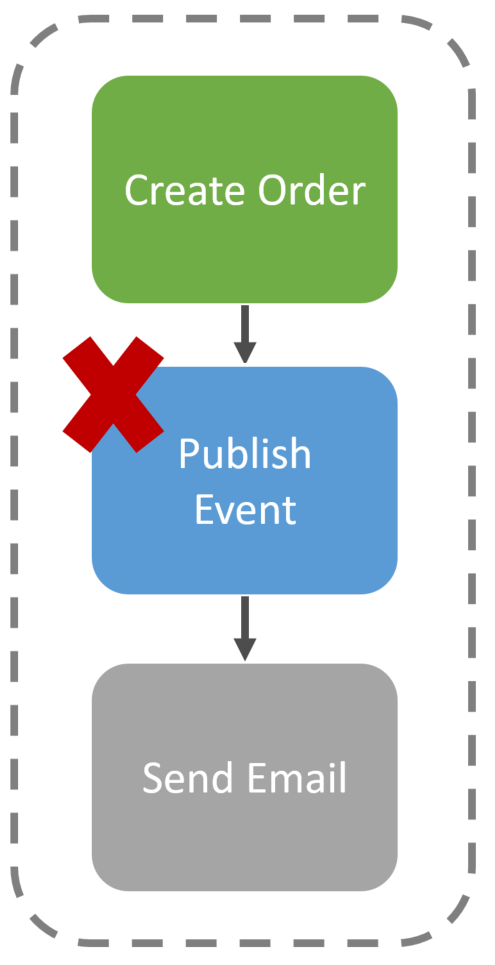
Now, if there’s a failure to publish the event, this activity could retry or have various ways to handle this failure depending on your tooling. Once the activity succeeds, it moves to the next which could send out the confirmation email.
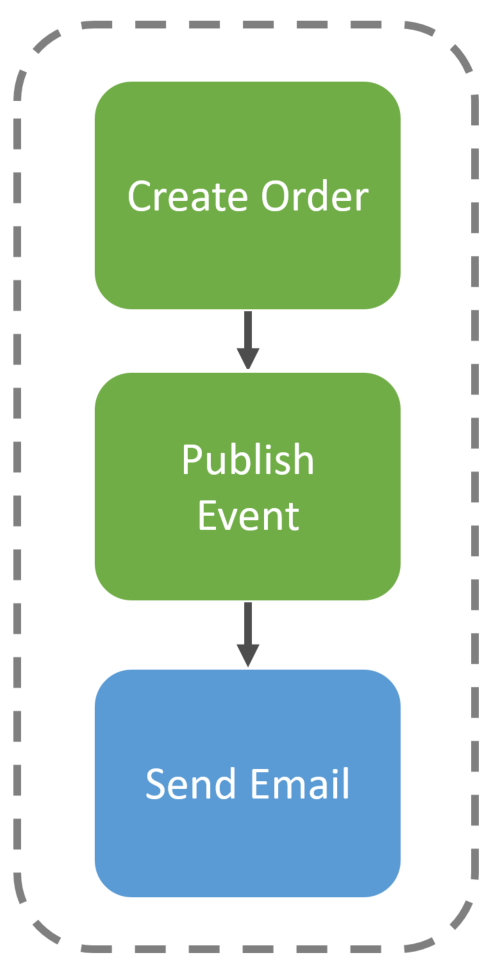
The key is that each activity is guaranteed to run. If the Create Order activity is completed, our Publish Event will execute. This eliminates the need for a fallback or an outbox.
Your Mileage May Vary
Two simple lines of code can have a large impact on the consistency of your system. Don’t fail publishing events! As you can see there are different ways to handle reliably publishing events and saving state changes, and which you choose will depend on your context. Hopefully, you can see the trade-offs for each and which will fit best for you.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.