Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
When the CrowdStrike incident happened, I was alarmed and notified of a degrading performance in parts of our system. That’s because we were indirectly impacted. I will provide some thoughts about how specific design patterns allow you to build resilient systems, allowing you to keep your system alive and online.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Fallbacks
I mentioned indirectly, and that’s because I’m not a CrowdStrike customer, so I wasn’t directly affected. However, I was indirectly impacted because I leveraged third-party services that were unavailable because of this. We were calling these third-party APIs over HTTP that are integral to our part of our system. They were failing, completely unavailable, or just unresponsive.
One of the resilience parts of our system is that any integral parts—third-party services—generally have a fallback. That means when a request is made from a client to our API, we need to interact with this third-party service. If it’s unavailable we immediately have a standby fallback that we interact with that can get us generally good enough results.
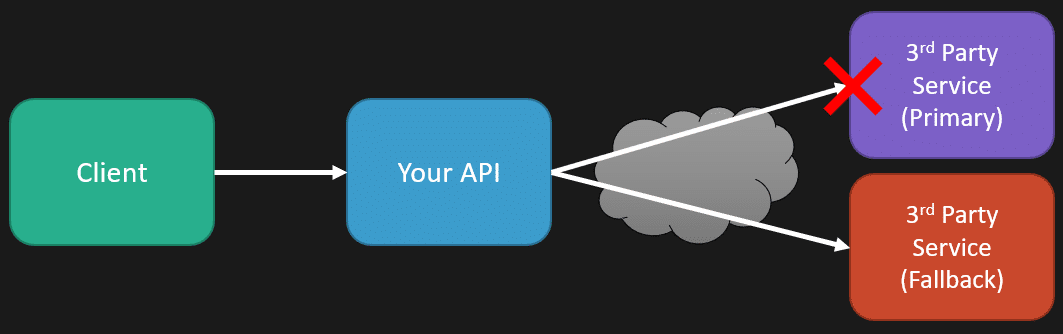
I knew our system had degraded performance because I was alarmed by metrics around these fallbacks. When we were making that API call to that third-party service, and it was failing, we had a metric for that which ultimately we would alarm on in a window of when it was happening too often. That’s why I knew something was up.
Latency & Timeouts
One thing to pay attention to with fallbacks is when you fall back. Sure, if you call that third-party service and it fails immediately, that’s great. But if it has degraded performance—if it usually takes 100 milliseconds—how long are you willing to wait? If you’re willing to wait 5 seconds, that’s still a very long time compared to the happy path in which you’re going to add latency to the overall request. So you’re waiting 5 seconds, nothing gets returned, you fail at this point with your timeout, and then you hit your fallback, realizing the latency you’re adding.
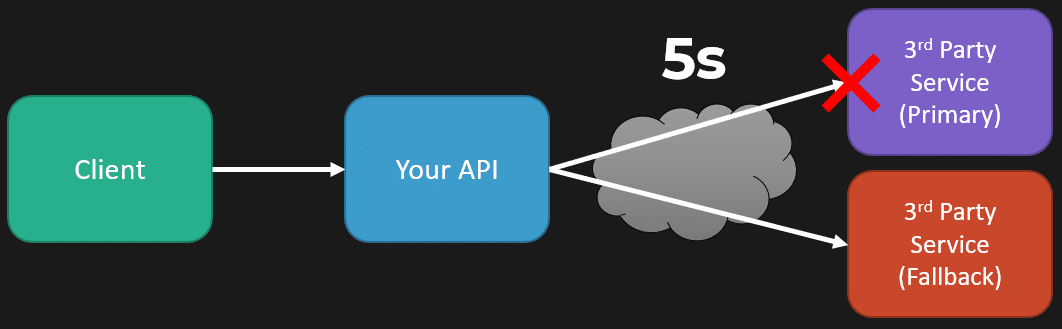
I find it comical when people talk about deign patterns for resilient systems like a retry in isolation without talking about any other patterns because it can be pretty dangerous.
My example here is you’re making that call, it’s hitting your timeout of 5 seconds, but you just slapped a retry on, so you’re going to have a backoff of maybe a second, then retry after a second. It’s still failing because of your timeout, and you could be adding a lot of latency just by slapping on a retry and using it as a form of resiliency in isolation.
It doesn’t make a lot of sense. You need more context, which is important because maybe that call to that third-party service isn’t that important; perhaps it is.
Maybe you have a low timeout because that call generally is safe—sub 10 milliseconds. So even with retries and backoffs, the latency you’re adding is still acceptable. You may also use it with something like the circuit breaker pattern. So that means that we might be using everything: fallbacks, retries, and the circuit breaker. The idea is that if we fail, we can define based on different metrics—the number of failures within a given time window—we may say, okay, we’re just going to use the fallback for this period or different metrics that you’re basing it off of when you know that third-party service is back up.
So, if you get another request, you won’t try the primary; you already know it’s down or degraded performance. You’re just going to hit the fallback. It’s really about the individual context and what kind of resiliency patterns you apply: fallbacks, retries, and circuit breakers, and leveraging all three of them where you need to, specifically to that use case.
With the fallbacks I mentioned earlier, you need a good enough value. What I mean by that is, for example, let’s say you have some e-commerce site where all your base prices are in US dollars, and the customer is logged in and they are Canadian. So you wanted to show them in Canadian dollars. You hit some third-party service to get the current exchange rate, but it’s down. What I mean is your fallback may return you almost like a null value so that you can then show the customer not in Canadian dollars but just kind of fall back to saying, okay, we don’t get an exchange rate because something’s up. So, we’re just going to show you the USD value.
Sure, that’s not the greatest user experience, but you’re still showing them the products and the prices. As a Canadian, I’m generally used to seeing things in USD anyway, so I wouldn’t be overly thrown off that they’re behind the scenes; their exchange rate’s not working right. I’d be none the wiser.
Async
Now, I said by use case, you can take these resiliency patterns, pick and choose them, and use all three, configuring them exactly how you want per use case because that context is really important. Context is king. An example is where the request originates, which is a part of that context. Earlier, I was showing a direct request-response from the client, and you’re adding a lot of latency directly to the client in their request. But maybe it’s not coming from the client but from asynchronous messaging. That means that we have our client initially make that request; instead, we might just be putting a message on the queue, and our request to the client is done. That’s it.
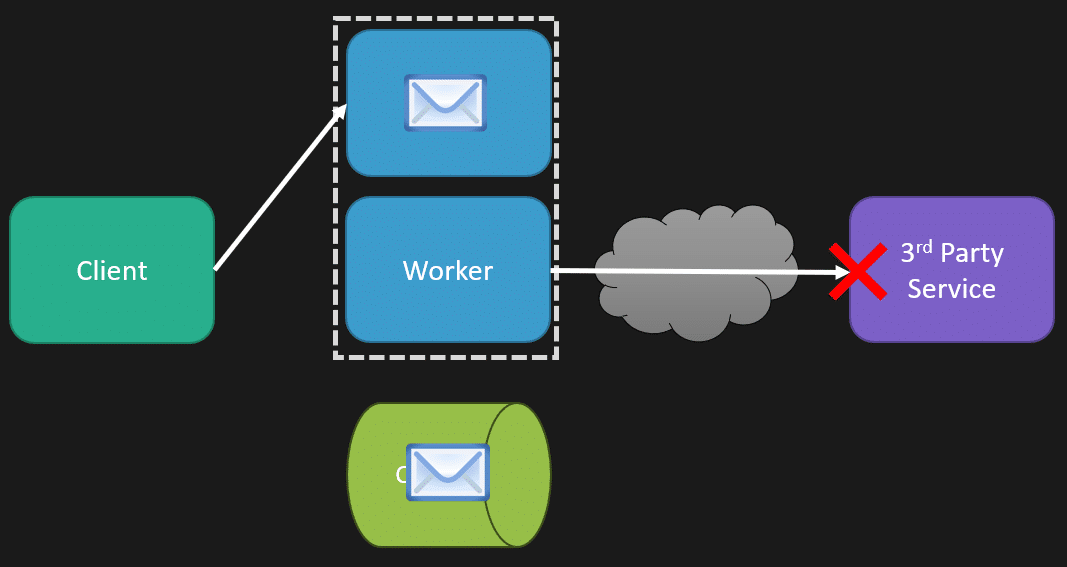
Separately, we have some worker process that’s consuming that message, and it’s the one that needs to call that third-party service. So now our latency concerns are very different and how we might configure this with retries, what those timeouts are, and whether we want to use a circuit breaker or not, how the window of time of that is for that because it’s very different from when it came from our client or when we’re processing that and dealing with that asynchronously.
Just like each third-party service, you may have a fallback for or some default value because it has a particular use case of what it does. It’s the same reason why you do not have a blanket retry where every HTTP call to anything will have this timeout with these retries and backoffs with this circuit breaker. It’s not going to be blanket; it’s going to depend on what the third-party service is, what its performance is, how integral it is to the part of your system it is—really kind of use case driven.
Errors
Another important aspect is being able to handle errors from your client gracefully. You may have some parts of your system that are degrading performance and may be affecting cascading failures everywhere. So that means that when your client requests a specific part that’s working fine, it’s great, but you want to stop immediately what’s causing the fire. That way, you have different load balancing rules that I’ve defined here to say, okay, this part of our system is degrading performance; it’s starting to affect everything else, and it’s cascading failures. We’re just going to stop it so you can’t even make a request to this route because it’s the one causing all the issues.
Having your clients handle that failure to that request gracefully can be incredibly important because then the rest of your system can still work. Maybe some particular routes you’re defining aren’t going to work; some parts of your system will just be unavailable, but it’s not taking down the entire thing. Ultimately, what I’m talking about there is bulkheads. For more on bulkheads, check out my post The Bulkhead Pattern: How To Make Your System Fault-tolerant
Resilience
Now, while the CrowdStrike incident didn’t directly affect me, it sure did indirectly because I knew about it right away from the alarms based on metrics. When used correctly within context, design patterns allow you to build a resilient system.
Now, everything we had in place for resilience helped; they worked. But as always, when something like this happens, it makes you re-evaluate specific individual contexts. Everything I mentioned about whether we have the proper timeouts, the right amount of retries, and where the request is coming from. Is it from a user? Is it asynchronously processing a message? Each one of those, depending on the service, has different needs.
When an incident like this happens, you re-evaluate all the different parts of your system where you’re building that resilience.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.