Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
You start with a simple entity. Then, over time, you add more and more properties. The next thing you know, you have a god object sitting at the center of your system. Everything touches it. Everything depends on it. Every workflow flows through it.
And whenever you need to make a change, you hope it doesn’t break something else.
At some point, you start wondering: how did we end up here?
YouTube
Check out my YouTube channel, where I post all kinds of content on Software Architecture & Design, including this video showing everything in this post.
For a lot of systems, this approach makes perfect sense early on. A shared model/godobject is simple. You don’t have to worry about duplication. You don’t have to synchronize data across different parts of the system.
But as the system grows, the trade-offs start showing up.
The problem isn’t that different parts of the system care about the same thing. The problem is assuming they care about the same model.
Let’s walk through a practical example where multiple parts of a system can function without a god object, without shared data, and without shared behavior.
What they share is identity.
The Shipment That Became Everything
I’ll use a Shipment as the example, but don’t get hung up on the domain. This could be a Customer, Account, Order, Reservation, or whatever large entity you’re struggling with in your own system.

At first glance, that seems reasonable. It’s all related to a shipment, right? Not exactly.
This is what happens when we group things by data rather than by behavior. If you look at any large entity, it’s easy to say, “Well, it’s all related to a shipment.”
But that completely ignores behavior. And once you ignore behavior, things start going sideways.
Different Parts of the System Care About Different Things
Let’s start with dispatch.

Dispatch is responsible for executing shipments. It assigns drivers, trucks, trailers, and carriers. It cares about routes, stops, pickups, deliveries, and the workflow involved in moving freight.
Its capabilities define the data it owns.
It doesn’t care about everything.
Now look at compliance.

Then there’s billing.

These are all different concerns.
They all care about a shipment, but in different ways. They don’t share a model. They don’t share behavior. They don’t even necessarily share data.
What they share is identity.
Once you realize that, you stop trying to build one model that rules them all.
Workflow Makes Ownership Easier to See
Workflow is often a much easier way to understand ownership than looking at data.
Let’s look at a typical shipment lifecycle:
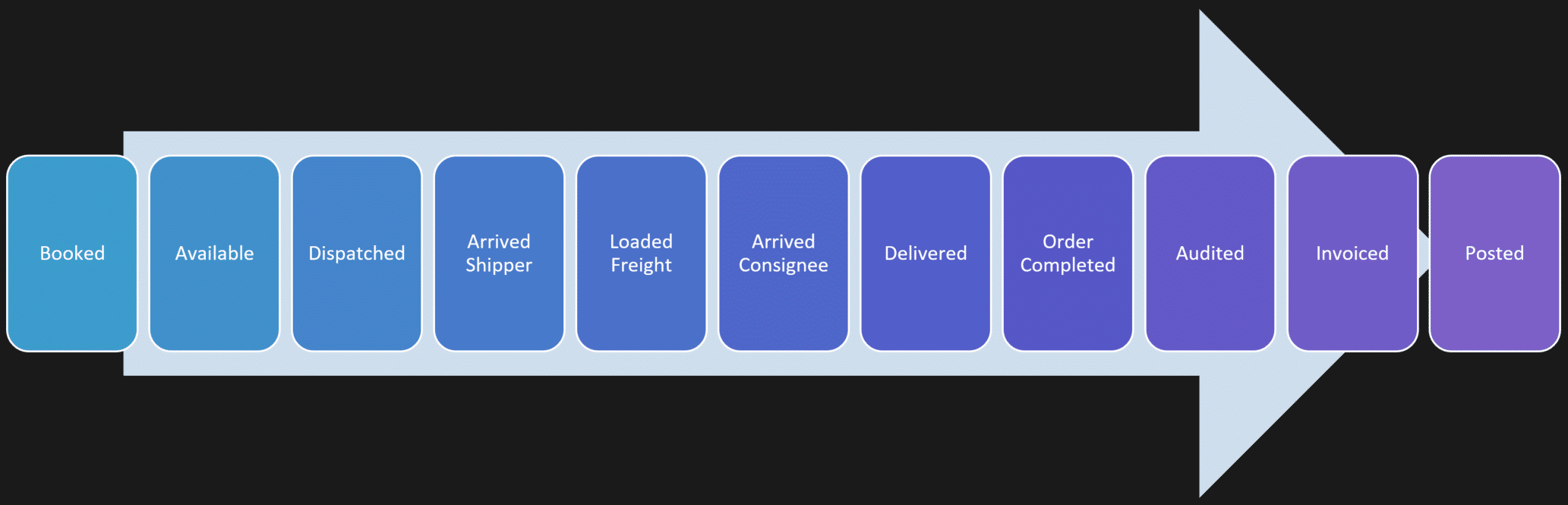
At first glance, that looks like one giant workflow. It isn’t.
It’s really a series of workflows connected by handoffs.
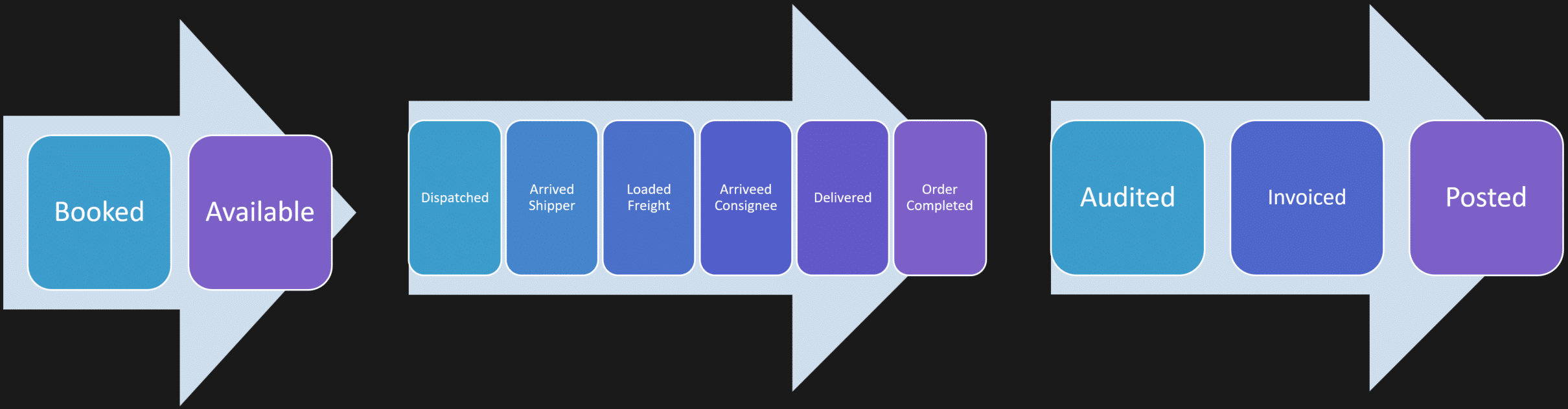
The sales side of the system books the order, enters details, rates it, and makes it available.
That’s a handoff to dispatch. Dispatch assigns resources, tracks execution, records arrival and delivery events, and completes the shipment.
That’s a handoff to billing. Billing audits paperwork, creates invoices, and posts to accounting.
Each workflow belongs to a different part of the system. Different responsibilities. Different rules. Different ownership.
So why would they all share the same model?
Sharing Identity
At some point, a shipment gets created.
For example, an Order Dispatched event might occur.
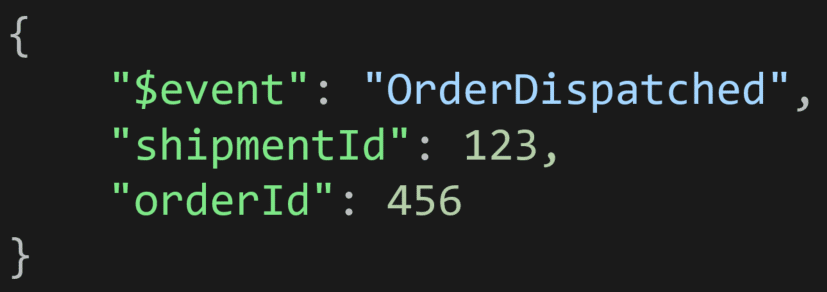
That’s enough. The event is notifying other parts of the system that a business fact occurred.
What it is not doing is distributing all shipment data.
One of the biggest mistakes people make when they start separating models is turning events into data distribution mechanisms.

Events shouldn’t be dumping grounds for data. Events should communicate business facts.
“But I Need the Data for My Screen”
This is usually where the conversation goes. People want to display information in a UI, so they assume they need to replicate data everywhere. You don’t.
Imagine shipment-related information spread across multiple boundaries:
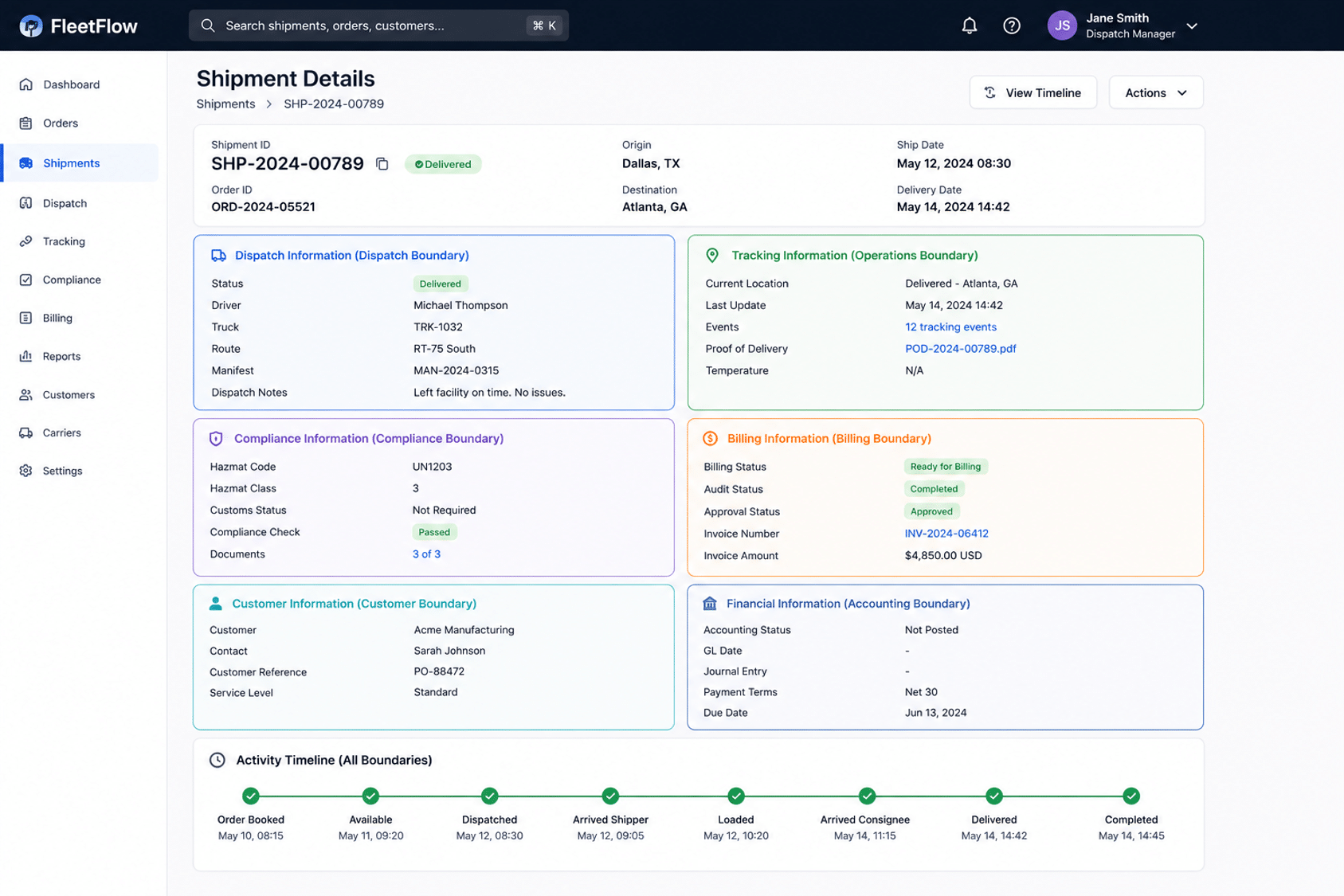
Each owns different data. That doesn’t mean you need one giant model containing all of it. You can compose information for query purposes.
This is a read concern.
You can pull together information from multiple sources to display a screen without distributing all of that data throughout your system.
Just because you need to show information together doesn’t mean it needs to live together.
What About Business Decisions?
Eventually, you’ll hit a situation where you need data from somewhere else in order to make a decision.
That’s when you need to ask a very important question:
Can the decision tolerate stale information?
The answer drives the solution.
Example: Driver Availability
Suppose dispatch needs to know whether a driver is available.
A driver might be out of service because they’re on vacation, suspended, or unavailable for some other reason.
The Assets boundary publishes an event:

Dispatch subscribes to that event and keeps the information it needs locally. Now dispatch can make scheduling decisions independently. There are no synchronous calls to the Assets boundary. Dispatch has the information it needs.
Is it stale? Potentially.
Is it good enough for the decision being made? Probably.
That’s what matters.
Sometimes You Need an Authoritative Answer
Not every decision can tolerate stale information. Imagine billing is about to post an invoice to accounting.
Before posting, it needs to know whether the accounting period is still open.
Maybe you could maintain a local copy. Maybe not.
In this situation, it might make more sense to make a synchronous call to the accounting system and get the current answer.

Even then, there’s no guarantee the information won’t change immediately afterward.
That’s just reality in distributed systems.
The point isn’t to eliminate uncertainty. The point is understanding the trade-off. Can the decision tolerate stale information? If yes, local data and events might be enough. If no, you probably need a more authoritative source.
Maybe the Data Lives in the Wrong Place
Sometimes the real question isn’t how to get the data. It’s whether the data should live where it currently lives at all.
If another part of the system constantly needs information to make decisions, maybe that ownership boundary isn’t right.
Before reaching for replication, APIs, or events, ask who truly owns that information.
Sometimes the answer is that ownership should move closer to where the decisions are actually being made.
Shared Models Aren’t Always Wrong
Can you use a shared model (god object)? Absolutely.
If your system is small and the workflows are simple, it’s often the easiest solution. The pain shows up when systems grow. When workflows start ending and triggering other workflows. When different parts of the system develop different responsibilities.
That’s when separate models start paying off.
The most important takeaway is this: Just because you need to display data together doesn’t mean you need to distribute it everywhere.
Different parts of your system can care about the same thing without sharing the same model. What they often need is shared identity, not a shared model.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.