Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
So, you adopted event-driven architecture because your system was a rat’s nest of coupling, and events were the answer to decouple it.
But now debugging is a nightmare.
You have events coming in out of order. You have retries causing duplicates and multiple different side effects. Local development is a pain. It’s frustrating, right?
But we use events for a reason.
YouTube
Check out my YouTube channel, where I post all kinds of content on Software Architecture & Design, including this video showing everything in this post.
Events can help us reduce temporal coupling within our system. We can have a publisher publish events for downstream services or other parts of our system that consume those events, process them how they need to, when they need to.
The producer doesn’t care who’s consuming them.
There’s real value there around workflows, integrations, and scaling, when you need it. There’s real value there when you have the right problems.
But here’s where things start going wrong. You think everything needs to be independently deployable. Or that everything has to be asynchronous. Or you start publishing events that aren’t really business facts.
And when you really start to feel the pain of this, that’s when you start blaming event driven architecture.
But events aren’t really the problem. Misunderstanding is.
The Pain Is Real
I ran across a post titled something along the lines of, “Our event driven architecture created more problems than it solved.”
As I was reading it, I thought, okay, this is somewhat relatable.
But then, as I continued, I realized that no, this was really poor design. Things related to debugging, local developer experience, retries, ordering, and a lot of the problems they were having, they really didn’t need to be having.
I’m not here to tell you event driven architecture is a silver bullet, because it is not.
It has complexities. There are trade offs.
But the pain they were experiencing came from the wrong conclusions.
This Is Not Eventual Consistency Hell
The first pain point they brought up was what they called eventual consistency.
Their example was sales and orders being placed in their system, and they had different parts of the system that needed to do different things.
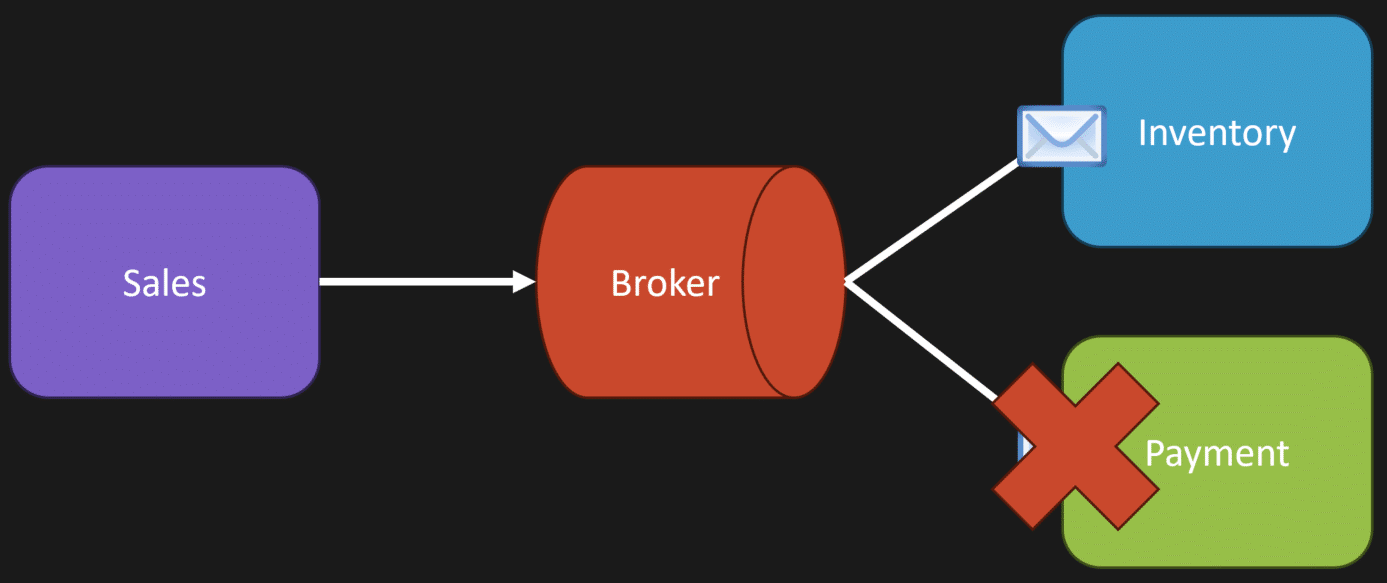
Shipping needed to create a shipping label.
Inventory needed to reduce the quantity on hand.
Payments needed to charge the customer’s credit card.
The issue they mentioned was, what happens if there’s a failure?
Before, in a monolith, they said they could just roll back the transaction. But now they needed all these compensating actions. For example, they had to publish a different event so inventory could undo what it did, or shipping could undo the label creation.
And if it was in a monolith, they said, you would just roll back the transaction.
I’m not so sure it’s actually that easy.
They called this eventual consistency hell.
This isn’t eventual consistency hell. This is workflow modeling hell.
When they mention rolling back a transaction, in this exact use case, it doesn’t really work that way.
If you’re interacting with some shipping system to create a label, typically that’s going to a carrier. That is not something you just roll back in your database.
Same thing if you have some type of payment issue or timeout. Did it actually go through? You might need to reconcile that.
There aren’t just multiple systems where you can roll everything back together and magically have some distributed transaction. That’s not likely going to happen.
This is more of a modeling problem.
You should be modeling actual business workflows using events that the business actually cares about.
Events Should Represent Business Facts
Events represent business facts. Things the business actually cares about and refers to in a particular way.
Not CRUD.
One example from the post was that a customer places an order, so they publish an OrderCreated event.
But was that really what happened? Was the order submitted? Was inventory reserved? Was a payment authorized?
Those are actual business events. Those are things that are really happening within a boundary.
Naming matters.
Don’t get too caught up in the exact domain here, but I want to illustrate the point. There isn’t just some massive rollback of all of this because you probably wouldn’t want that anyway.
If a payment failed, you’d probably be contacting the customer.
You don’t have to roll back inventory because maybe you didn’t actually reduce it to begin with. That’s not when it happens. You might be reserving inventory instead.
There are completely different business cases related to inventory, payments, shipping, and ordering. The example was framed as, “We had all these compensating actions and we were better off with one giant rollback.”
But you probably wouldn’t have had one giant rollback to begin with.
Asynchronous Does Not Mean Everything Is Eventually Consistent
Another pain point they mentioned was performance. Their API response times went from 150 milliseconds to 2.5 seconds. Why? Network hops.
They mentioned a customer saying, “I updated my profile, but the change doesn’t show up for 30 seconds.”
And the response was basically, “That’s eventual consistency for you. Eventually.”
Hang on. What?
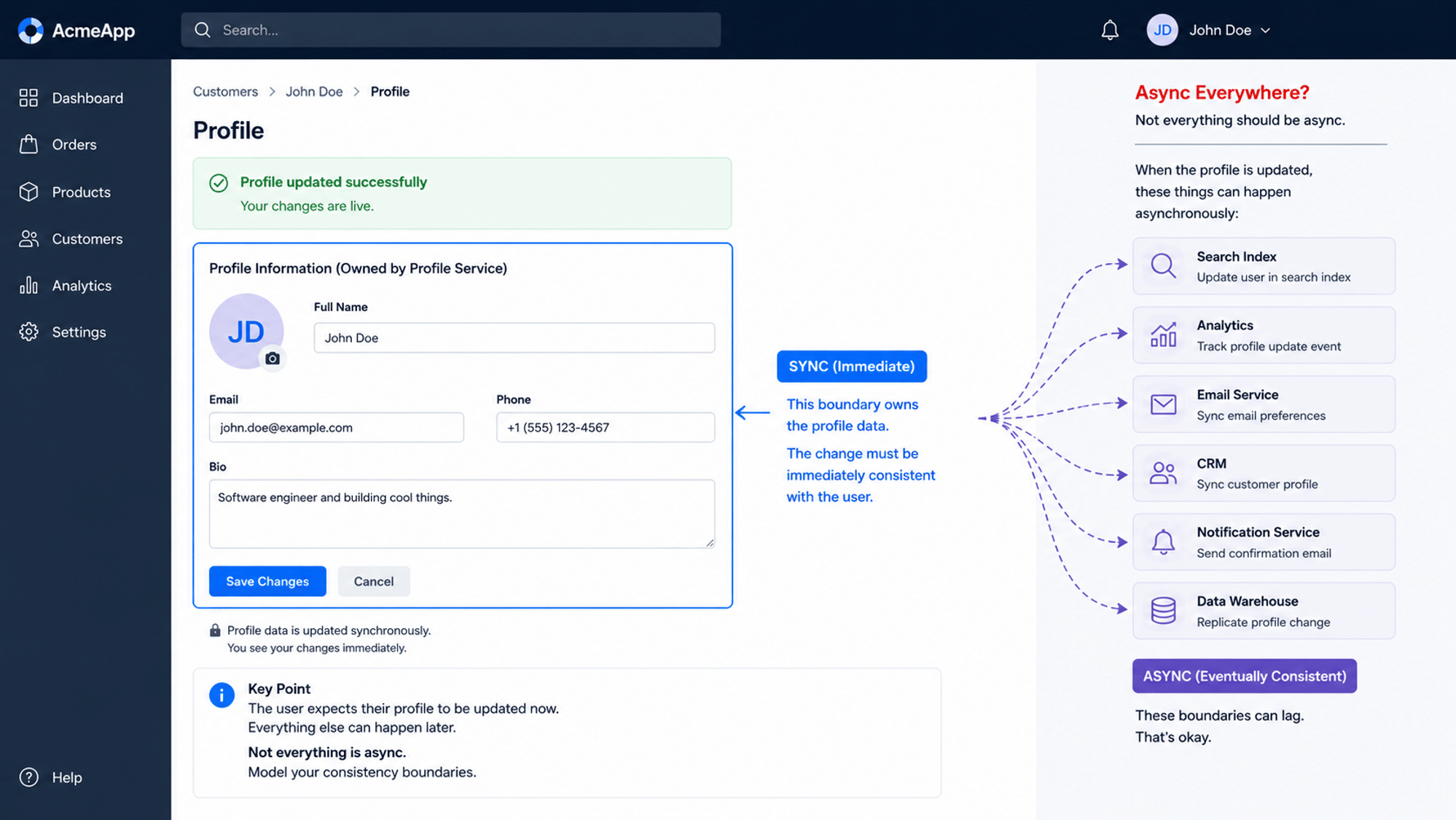
The conclusion they landed on was that asynchronous isn’t fast. It can be fast, but it doesn’t have to be. The better question is, why is a user updating their profile and having to wait for anything?
Not everything has to be asynchronous.
If a user is trying to change their profile information, that should be synchronous. It should be immediately consistent, and it should be something the user immediately sees.
You want to be able to read your own write.
Does that mean you can’t have events involved? No. You absolutely can.
You can have different boundaries that care about when a profile has its phone number updated. Maybe CRM cares because you have some external CRM that you keep updated. Maybe analytics cares. Maybe some other part of the system cares.
Whatever handles the profile update can publish an event.
It doesn’t really care what other parts of the system care about that event. Those parts can be asynchronous.
That’s a good use case for asynchronous processing.
But updating the information so the user sees it immediately? Why would that be asynchronous?
It should be synchronous, just like you’d expect it to be in any other type of system.
Kafka Being Down Is an Infrastructure Problem
Another issue they had, and I’ve heard this before, was the single point of failure.
They mentioned a Kafka cluster incident where everything depending on events stopped working.
Which was everything.
They couldn’t create users. They couldn’t process orders. They couldn’t update inventory.
In the monolith days, they said, if the database went down, everything stopped, but at least they had one thing to fix.
Here was the glaring thing they mentioned: With Kafka down, they couldn’t even fall back to synchronous processing because they had removed all that code.
Well, first, we already established that not everything should be asynchronous.
Second, if you have vital infrastructure, you deal with it appropriately. Like anything else.
It’s no different than their database example. Do you want your database to be down? No. If it is down, everything is down.
If it cannot be down because not everything can be down, then what do you have?
You have monitoring. You have high availability. You have failover. You have backup processes.
This is no different than any other piece of infrastructure.
Same thing with a cache. If you have a cache and it goes down, there’s an outcome to that. Often, that outcome is hammering other parts of your system, like your database, because your cache is gone.
So you end up making the cache highly available too.
It’s no different than any other part of your infrastructure that you require high availability for.
Having said that, with messaging, depending on the libraries or infrastructure you’re using, it’s common to have some kind of local mailbox where messages are kept in case they can’t be published. The outbox pattern is one example.
Yes, there is complexity.
But you’re often using this to make the system more resilient.
Event Driven Architecture Does Not Require Microservices
There were two other pain points that were very related.
They mentioned the hidden costs nobody talks about, especially infrastructure costs.
Before, with their monolith, they had two application servers, one PostgreSQL database, and a cache.
With event driven architecture, now they had six microservices, a Kafka cluster, six different databases, a service mesh, and all these different costs.
They also mentioned the developer experience.
With the monolith, you clone one repo, run Docker Compose, and everything is good.
With their event driven architecture, they had all these different repos. You had to install Kafka, Zookeeper, all these databases locally. It became a nightmare to deal with.
These are really the same issue.
The issue is assuming event driven architecture has something to do with physical deployments, different repos, and separate infrastructure.
It doesn’t.
You can use event driven architecture within a monolith.
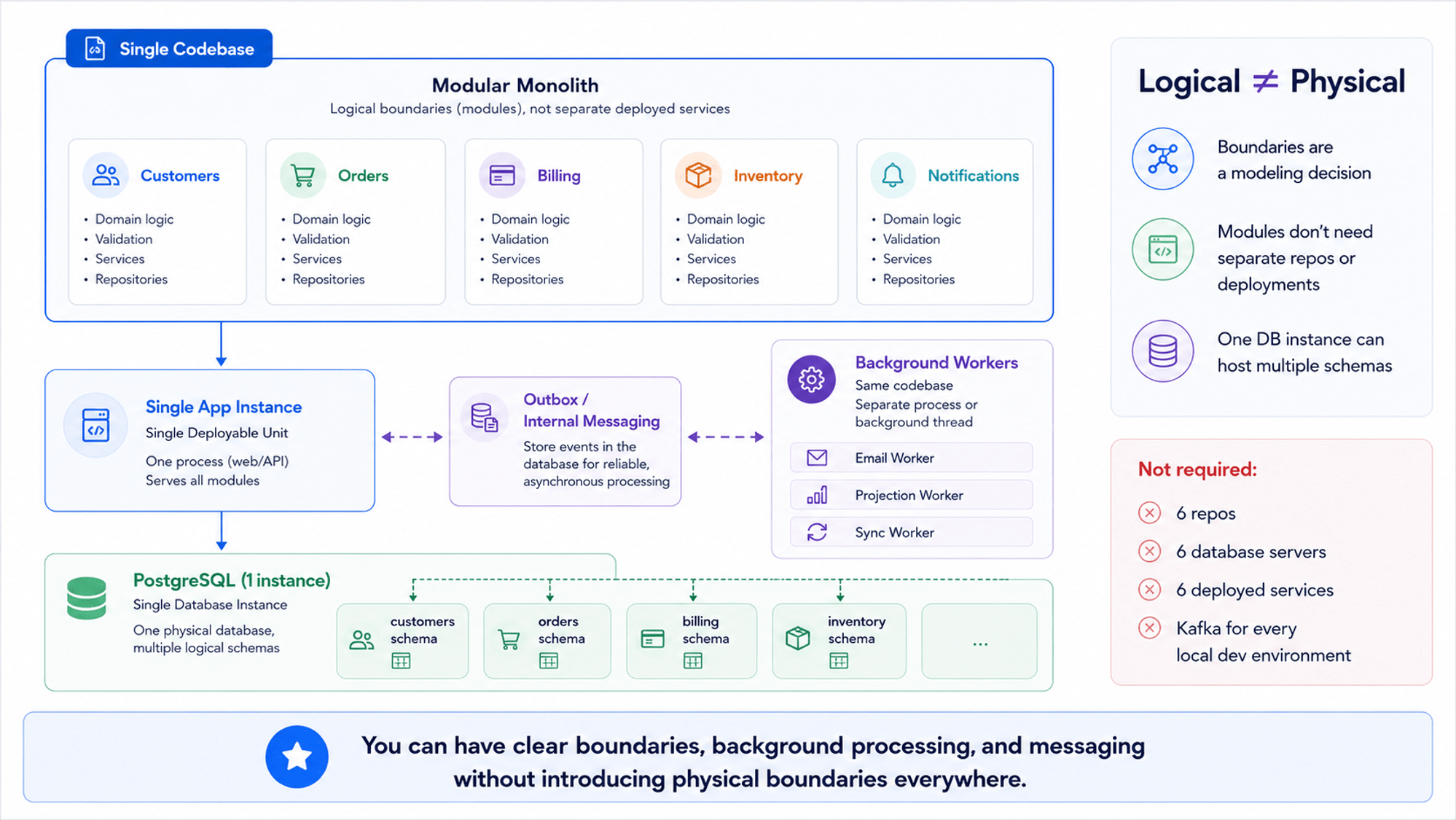
You can have a monolith with different boundaries like customers, orders, billing, inventory, and notifications. That can all be deployed in a single instance. Or multiple instances if you are scaling out. It can use a single PostgreSQL database or whatever database you’re using.
But each boundary owns its particular schema.
Physical boundaries are not logical boundaries.
I will keep saying this every possible chance I get until people figure it out.
Event driven architecture does not require six different repos, six different database servers, six different deployments, and Kafka all over the place.
You do not need that.
You can be using event driven architecture within a monolith.
You do not need microservices.
You do not need Kafka.
It’s about publishers and consumers. It’s about decoupling in time.
That’s the point of event driven architecture.
Not all the infrastructure.
Messaging Can’t Fix Bad Boundaries
The pain they felt was real. That’s why they said event driven architecture caused more problems than it solved.
But the reality is that misunderstanding and misapplying event driven architecture is why they felt that pain.
The better lesson is this:
Messaging can’t fix bad boundaries.
I think this is why people experience all this pain and then blame event driven architecture.
My solution is to start with logical boundaries.
Start by defining what your boundaries are.
From there, choose how those boundaries communicate.
Is the communication synchronous?
Is it asynchronous?
Then choose how you’re going to deploy.
Are you deploying one particular boundary by itself?
Are you deploying everything together?
That’s the order.
- Define logical boundaries.
- Choose communication patterns.
- Choose deployment model.
I think most people do this in reverse, and that’s how they get into trouble.
They start by thinking, “We need to deploy this independently for scale.”
Then because of that, they decide they have to always communicate through events or always communicate asynchronously somehow. Or they introduce HTTP APIs everywhere and now they have more network hops.
Then, after all that, they try to decide what should go where.
That’s backwards.
Start with logical boundaries.
Then choose how they communicate.
Then choose how they deploy.
In that order.
Events Are Not the Problem
Event-driven architecture is not the problem.
Events have complexity. Messaging has complexity. Asynchronous workflows have complexity.
But a lot of the pain people attribute to event-driven architecture comes from misunderstanding what it’s actually for.
Not everything needs to be asynchronous.
Not every event is a business event.
Not every boundary needs to be independently deployed.
Not every event-driven system needs Kafka, microservices, six databases, and a service mesh.
Use events when they solve the right problem.
Use synchronous communication when that is what the workflow or user experience requires.
Model the business process correctly.
Define your logical boundaries first.
Because events can help reduce coupling, but they cannot fix bad modeling.
And messaging can’t save you from bad boundaries.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.