Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
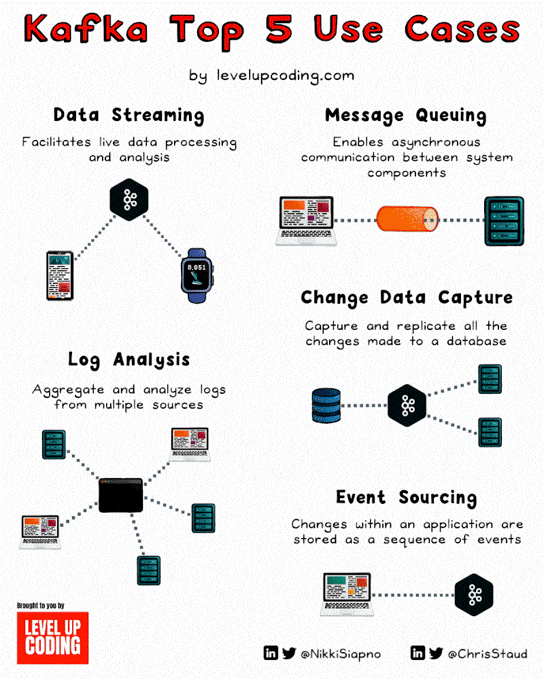
Infographics are easy and quick to look at and they are posted everywhere. But are they actually correct? Not really. Here’s an example of the “Top 5 use cases for Kafka” that aren’t actually valid use-cases at all.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Kafka Gone Wrong
LinkedIn is full of shiny animated infographics, and I came across one about “Top 5 Use Cases for Kafka”. While some of these use cases make sense with Kafka, others, particularly message queuing, change data capture, and event sourcing, aren’t at all.
Kafka is often described as an event streaming platform. But at its core, it’s a distributed log with publish-subscribe capabilities. Trying to go outside of that is forcing a round peg in a square hole.
Kafka is Not a Queue
Kafka is not a traditional message queue. Queues typically operate on a first-in, first-out (FIFO), where messages are consumed and removed from the queue once processed. In contrast, Kafka retains messages in a log for a predefined retention period (or forever), allowing multiple consumers to read the same message independently. Or even the same consumer to read the events multiple times.
In Kafka, when a producer appends events to a topic, those events remain available for any consumer to reprocess at any time as long as they have not exceeded the retention limit.
Commands vs. Events
Another important distinction to understand is the difference between commands and events. In a typical queue, commands are used to invoke behavior within a single service, where exactly one consumer processes each command.
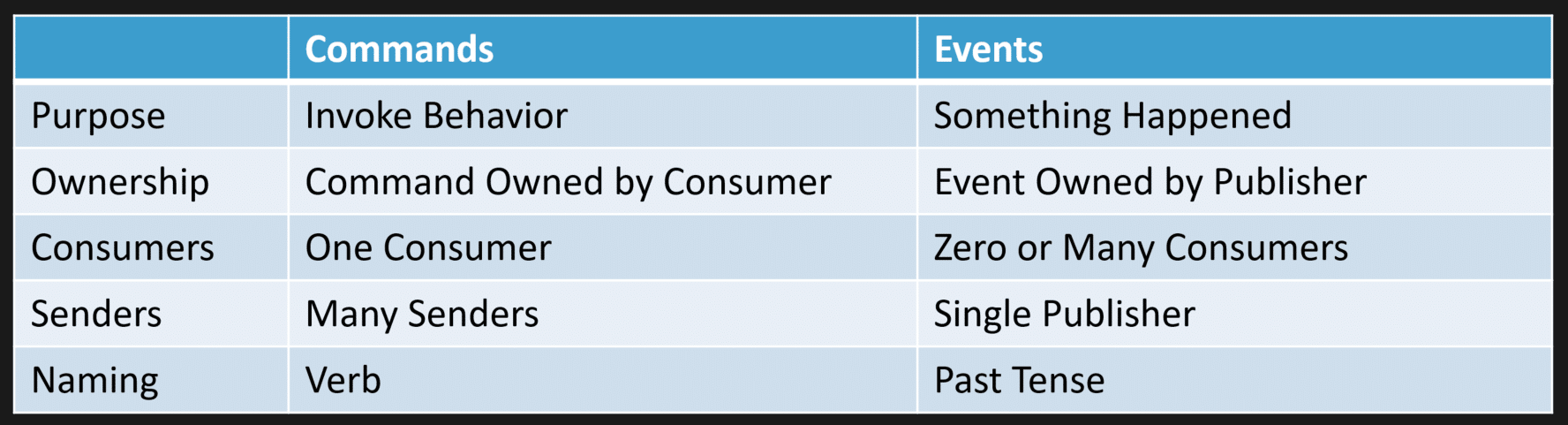
Kafka is built around the publish-subscriber pattern, which decouples the producer and the consumers. An event can have zero or many consumers, and the producer has no idea who the consumers are, if any.
This is an important aspect because when you’re trying to force the paradigm of a command, that doesn’t fit in a publish-subscribe model. Events fit in publish-subscriber and topics, not commands. Topics are for events, and Queues are for Commands.
Change Data Capture (CDC)
While CDC is often mentioned in conjunction with Kafka, it’s important to note that Kafka does not inherently perform CDC. Instead, tools like Debezium can capture changes from databases and leverage Kafka to distribute that data. Kafka serves as the transport mechanism, not the capture tool itself.
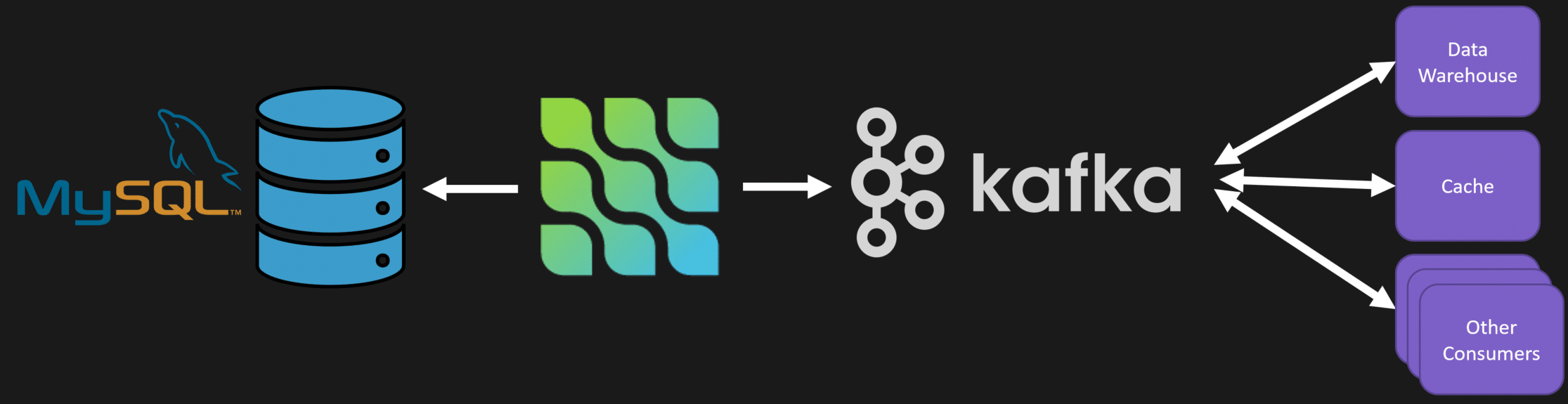
Using Kafka for CDC can lead to confusion if one expects it to replicate database changes directly. If your goal is to maintain a synchronized state across services, consider using built-in database replication features instead. Kafka should be seen as a complementary tool that aids in the distribution of the already captured changes.
It’s also worth pointing out the distinction between an event as a notification and an event as a means for state propagation. CDC events are not explicit about why data was changed. They only imply that data changed.
There’s a big difference between ProductChanged and InventoryAdjusted. Using CDC and events as a means for data propagation should pose the question of why you’re distributing data that a logical boundary should own.
Using an event-driven architecture to distribute or propagate data imposes coupling that EDA is trying to remove.
Event Sourcing
This is a really common and highly debated topic around Kafka and Event Sourcing. While event sourcing involves persisting state as a series of events, it should not be conflated with Kafka’s role in event streaming. Kafka is designed for communication between services, while event sourcing focuses on how a service internally manages and stores its state.
To quote Greg Youg on Event Sourcing:

This is a big distinction between communication and state.
Event Sourcing: State
Kafka: Communication
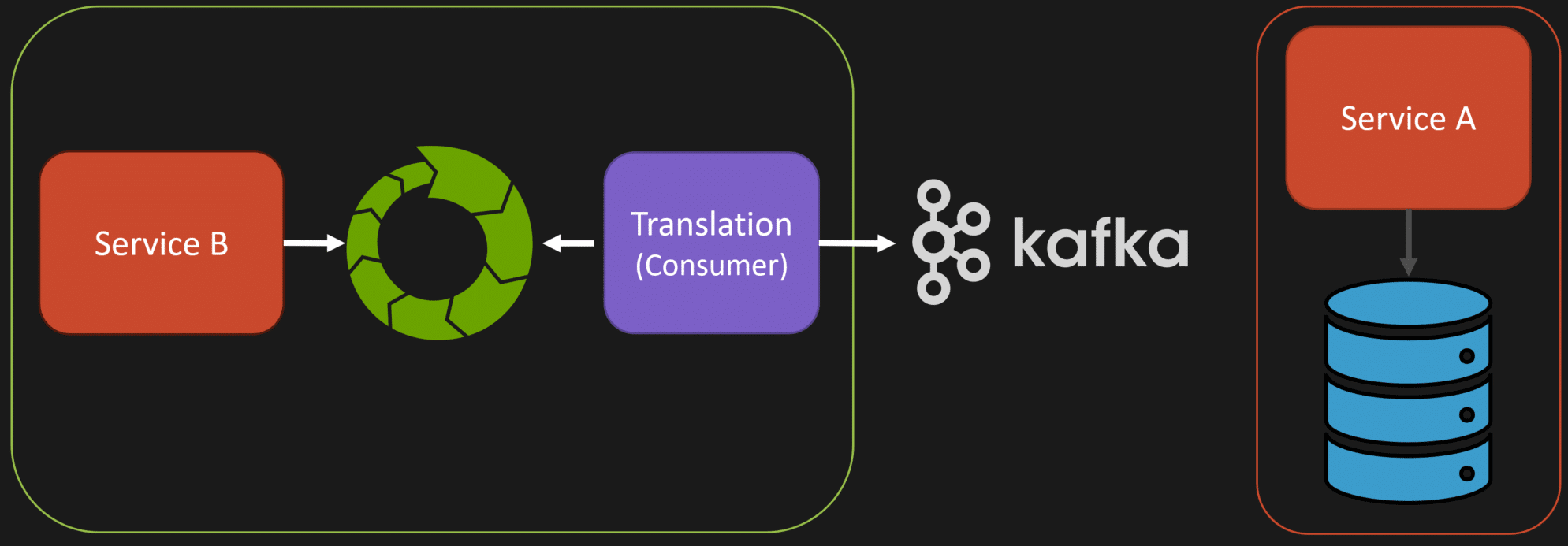
When implementing event sourcing, a service might choose to store events in an event store. Kafka can then be used to publish those events to other services that need to be informed about state changes. However, avoid exposing the internal event structure directly to external services, as this creates tight coupling between them, just like you would be with CDC.
There needs to be some translation between events you’re persisting as state and events you expose to other boundaries for communication.
Kafka
Kafka is a great communication tool built around a distributed log and publish-subscribe pattern. But take the shiny animated infographics on social media with a grain of salt. Just because you can doesn’t mean you should. You can use Kafka as a queue or for event sourcing, but that doesn’t mean it’s ideal for it or that you should. Round peg, square hole.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.