Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Many applications are more read-intensive than write-intensive. Meaning your application performs more reads than writes. However, we often persist data optimized for writes making querying and composing data intensive at runtime. What’s a solution? I will review different ways of creating materialized views and some trade-offs.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Materialized Views
If you have a large system decomposed into many different boundaries, you’ll have data spread across many different databases. When you need to perform any query, often for a UI, you need to do some type of UI/View Composition by composing all the data from various sources.
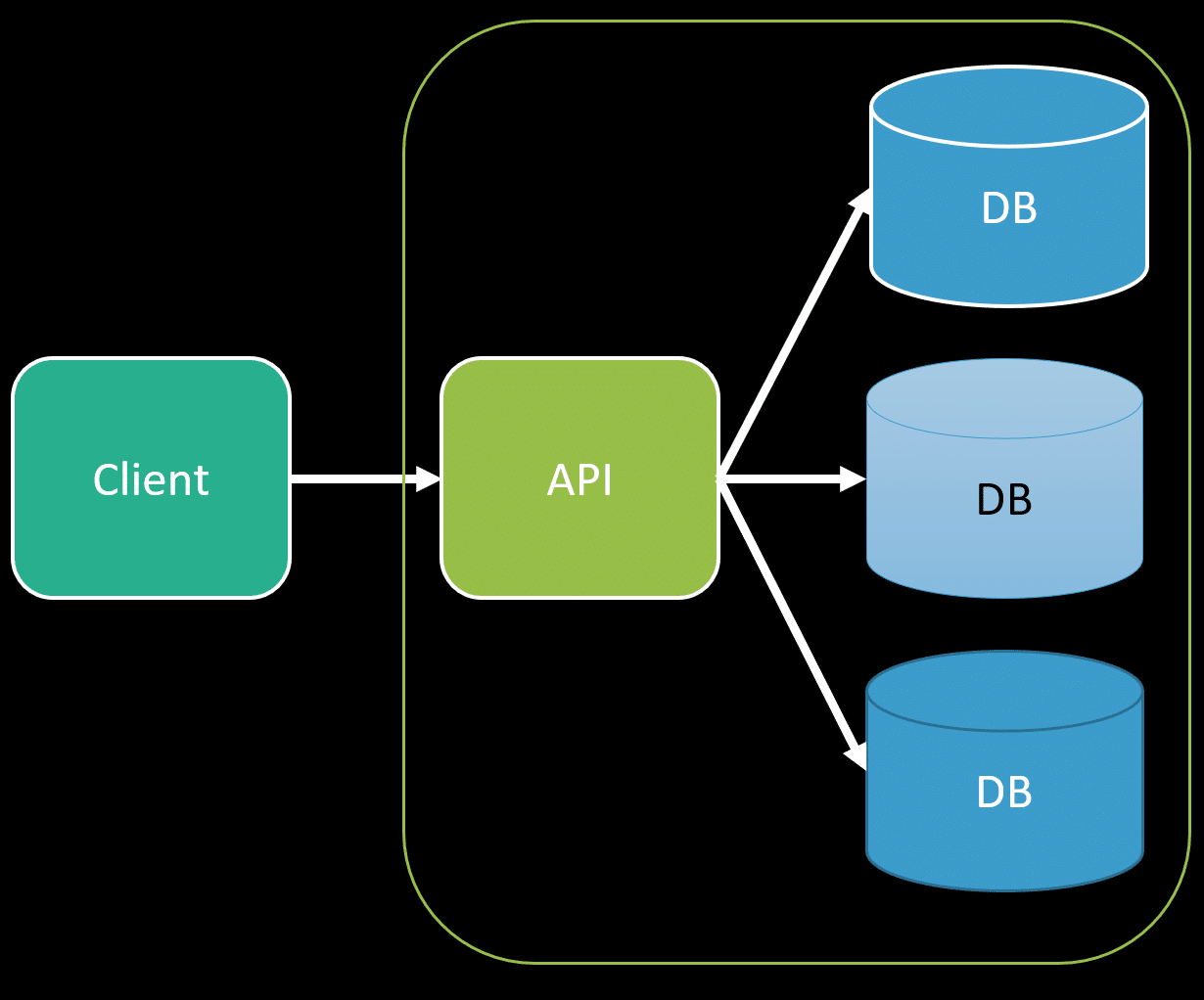
This is one of the most common challenges when working in a large decomposed system. Check out my post on The Challenge of Microservices: UI Composition for various ways of handling this.
One issue with this composition is often performance because even if you’re querying each database concurrently there is often a lot of computation that has to occur to transform into the file result back to the client.
A solution to this is to do that computation ahead of time so that when a client makes a request, you already have all the data composed exactly as you need it or to query it.
This sounds like a cache, right? It is, but we’re not caching exactly the same structures as what we have in our database, rather, we’re caching the end result that’s already done all the composition and transformation in it’s final for we want to return to the client.
Meaning, we’re storing a data structure that’s optimized for specific queries or use cases.
As an example, let’s use the typical Sales Order in a relational database.
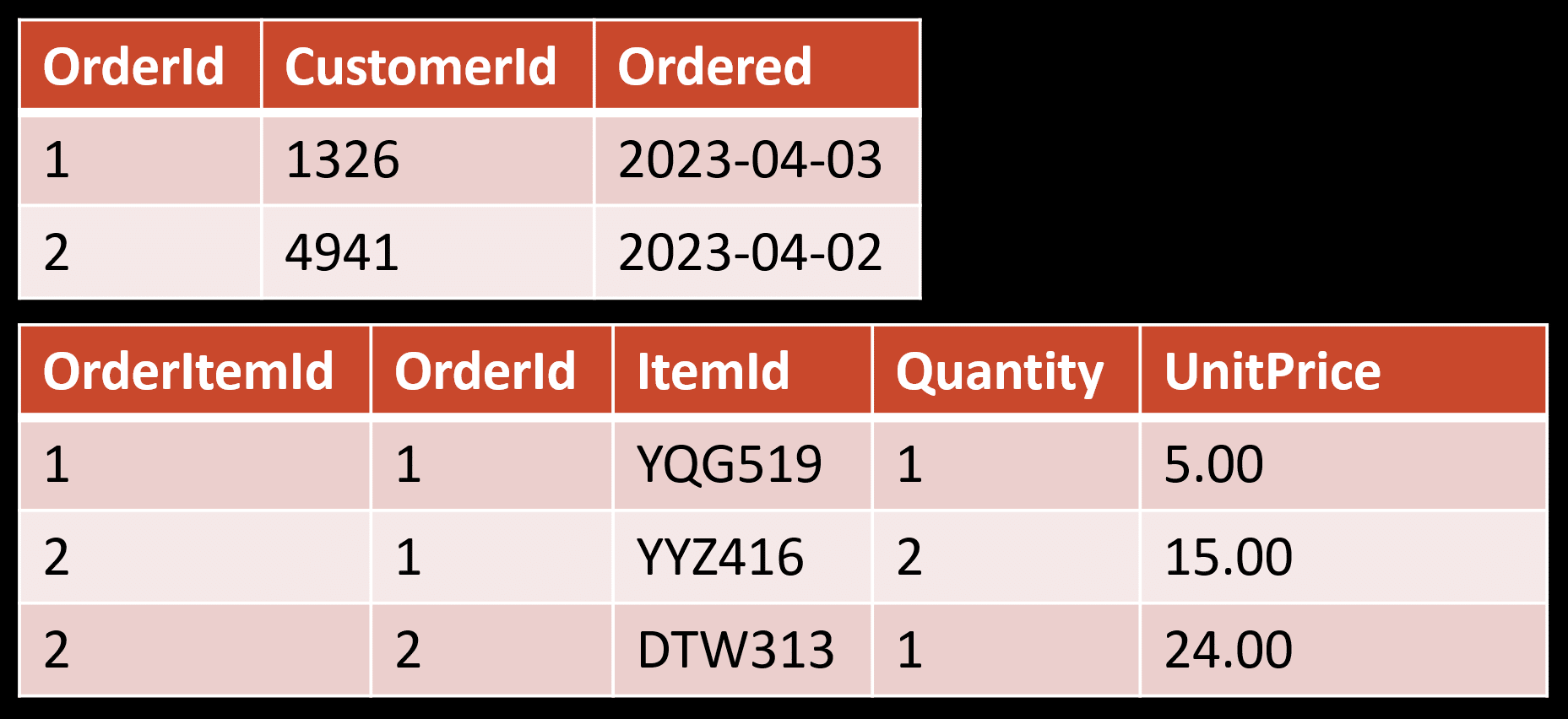
If we want to display a list of Sales Orders and the order total, we can query the order table, joining with the order line items and doing a Sum() of the Quantity and UnitPrice. No problem.
When an order is completed, its state is set and won’t change. Meaning we can do some pre-computation when an order is placed and summarize (denormalize) into a separate table that’s specific to this use case.
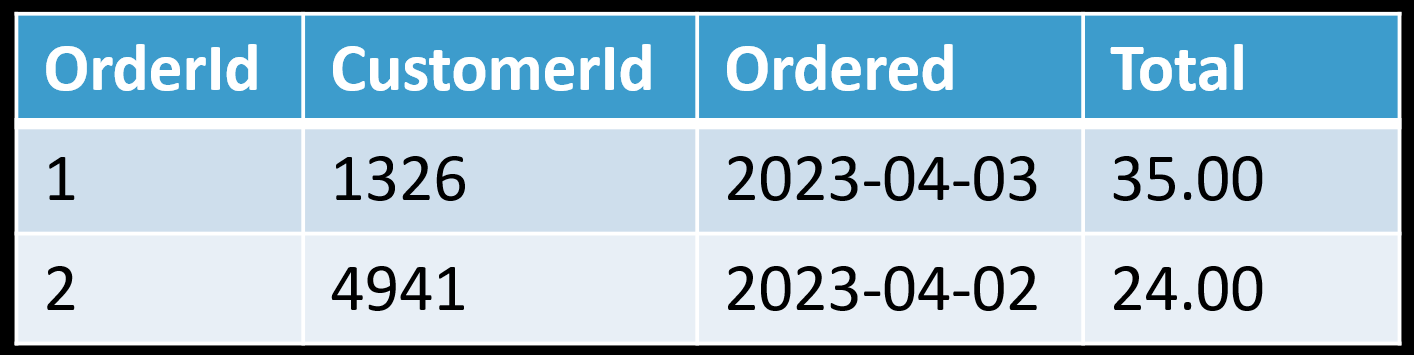
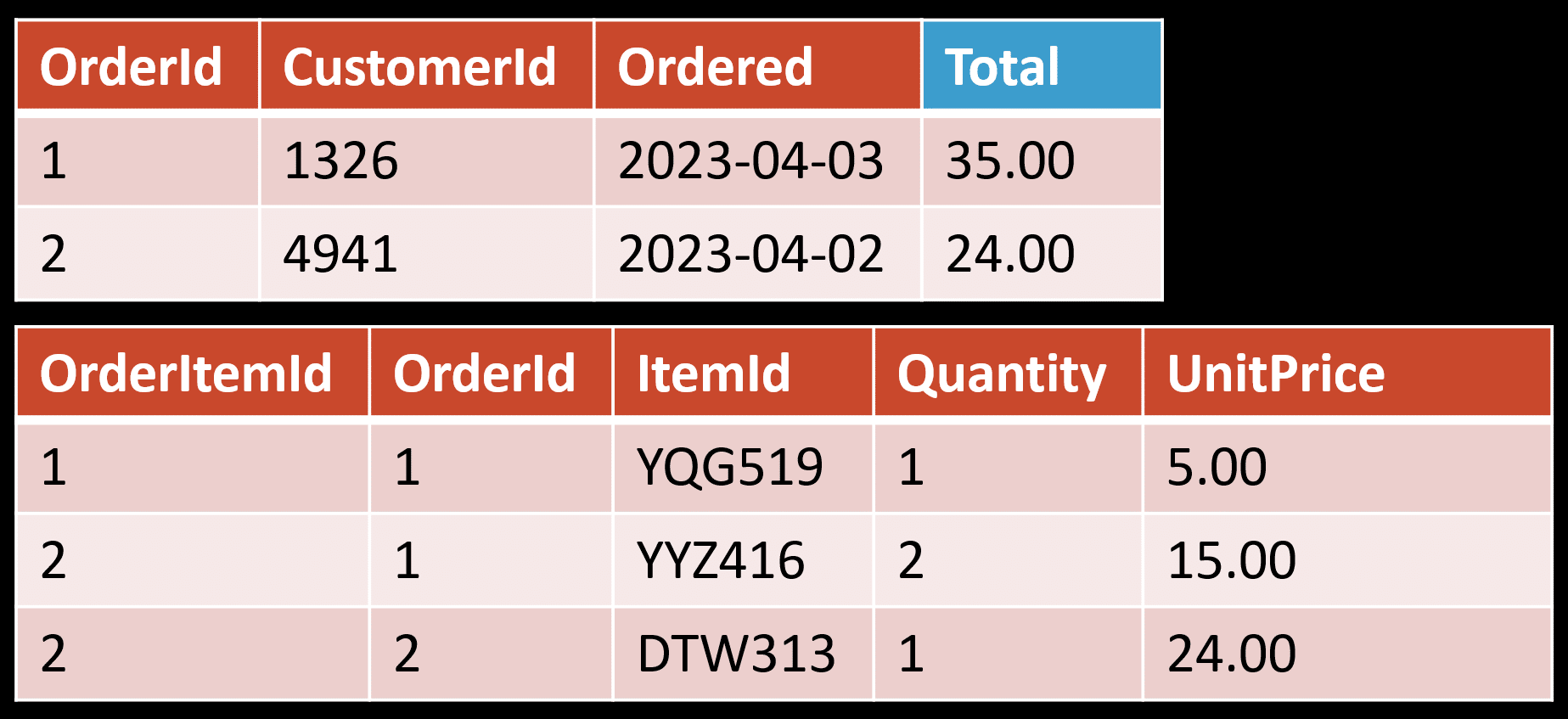
Rather than have to query and join the tables, we just query this individual table directly. Now this example is rather trivial, but you can see how doing pre-computation can be helpful. Another example is when the order is placed if we have to calculate the tax on the order. Instead of having to do that at run-time or via a query, we would just calculate it once and persist it.
You also don’t have to persist any of this data separately. You can often leverage the existing structures you have. Meaning some columns are persisted as calculated columns that are specific for queries.
CQRS
CQRS fits naturally because the point is to separate commands and queries as distinct operations. Queries can be optimized separately from commands.
When a command is executed that makes some type of state change, we can perform the write operation and also do that pre-computation and also persist the data that are specifically for queries.
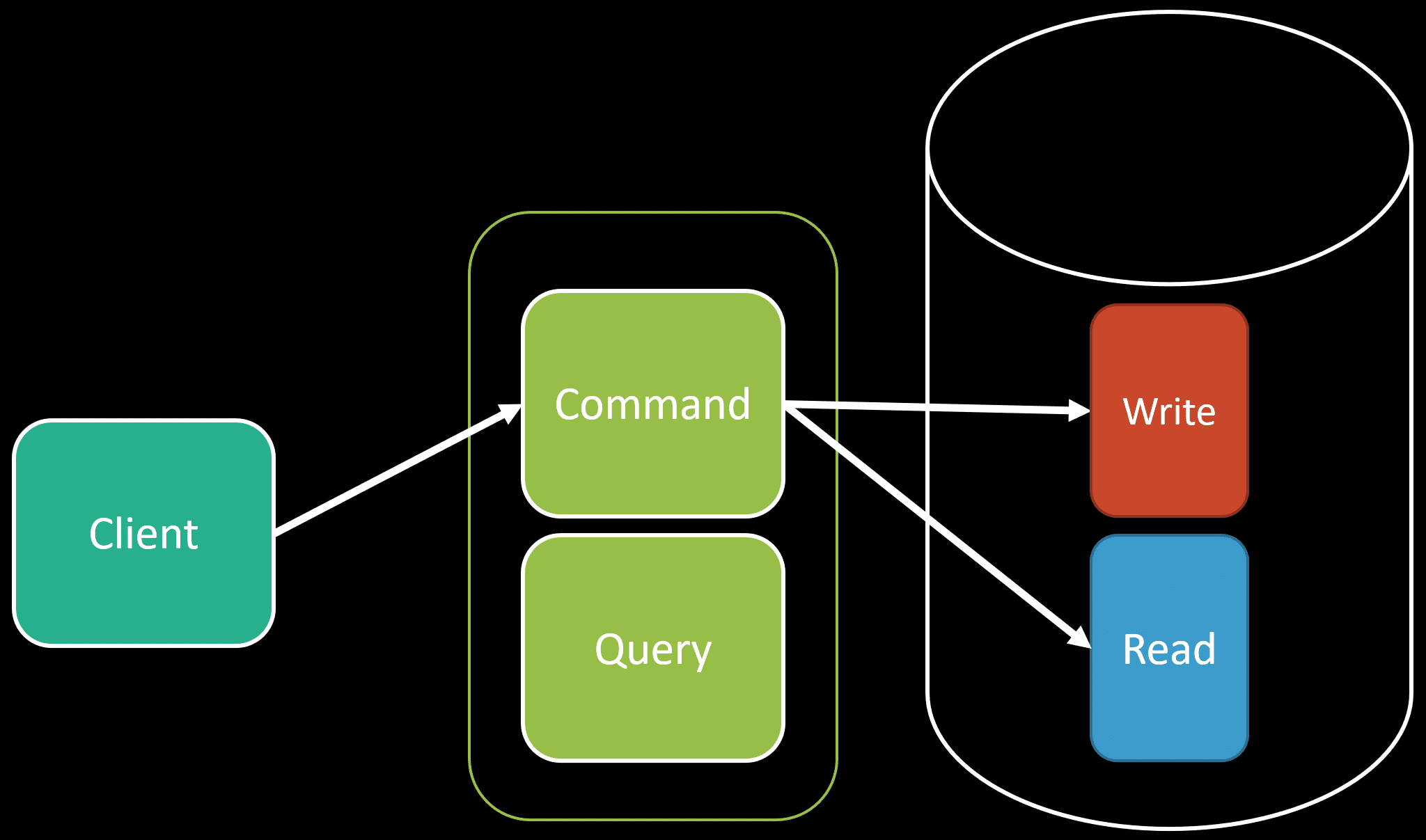
That way when we execute a query it can use that specific tables/columns that are explicitly for queries and that are optimized for them.
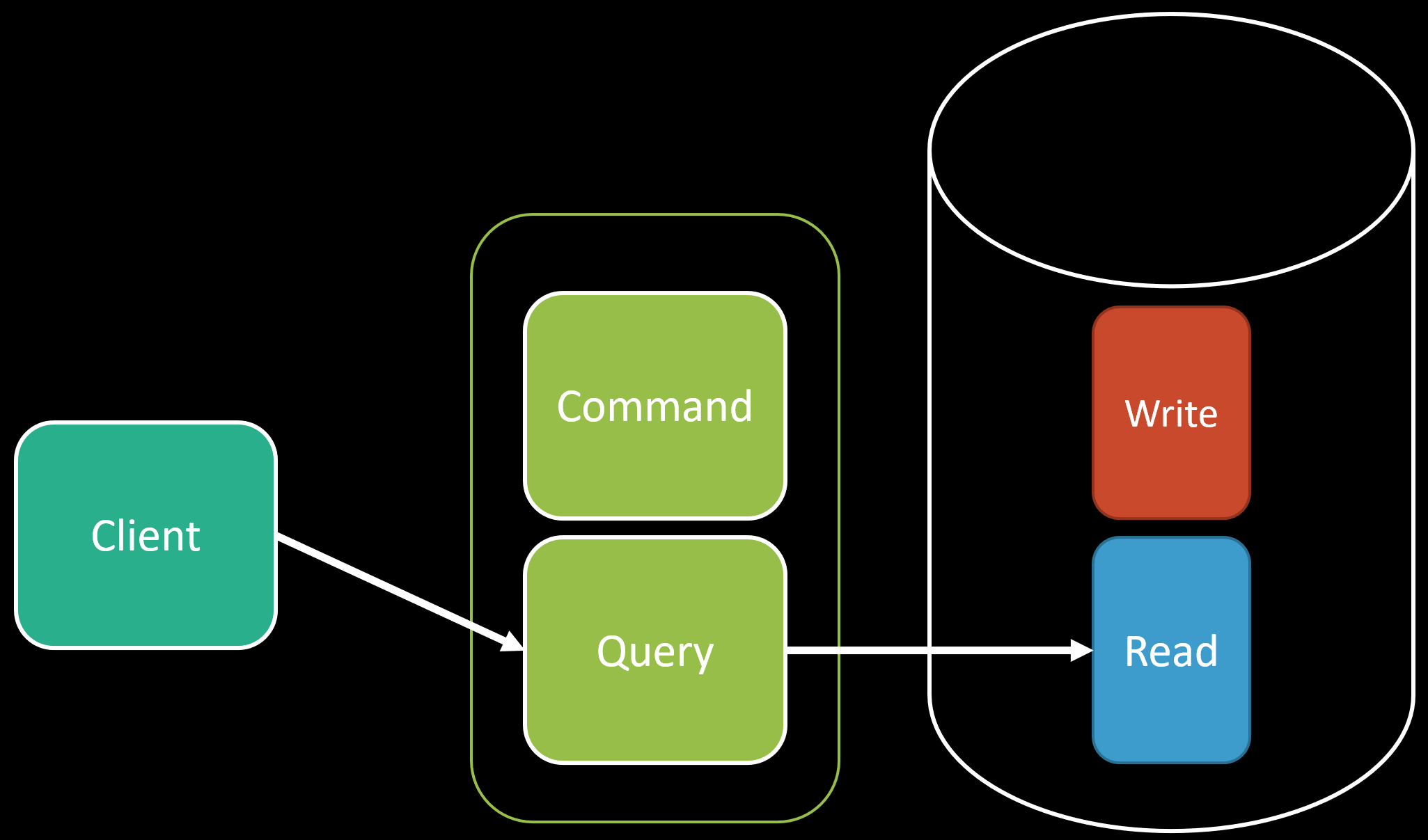
One caveat to this is if you are doing this precomputation at the time of the write, you could be adding latency to your writes. However, in a lot of systems, you’re often more ready-heavy than write-heavy. But it’s worth thinking about if you need low-latency writes.
Another option is to remove that pre-computation at the time of the write and do it asynchronously.
When you perform your state change from a command to your database, you then publish an event that the query side will consume. It will handle then updating your query optimized read side.
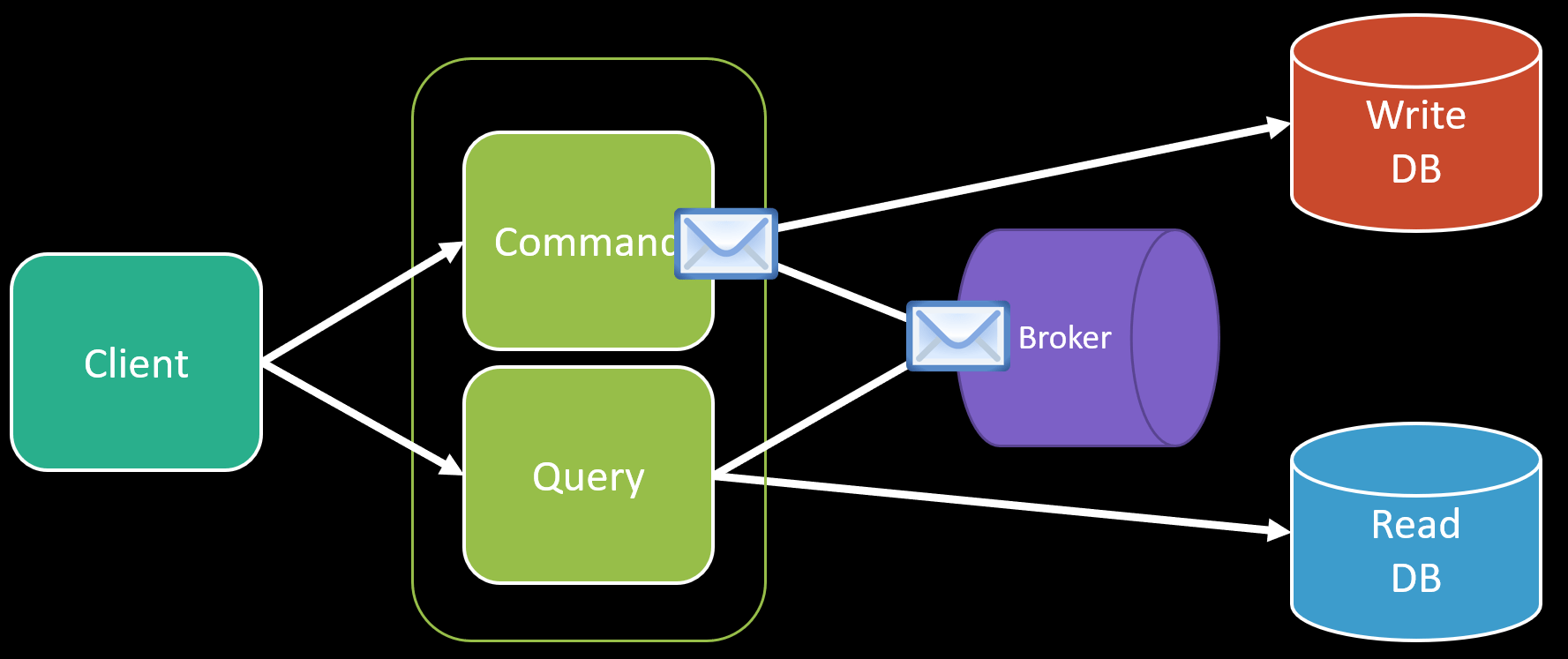
Because this is asynchronous, your read database is eventually consistent. This has implications about not being able to immediately query the read database after you complete your command. Check out my post Eventual Consistency is a UX Nightmare for ways of handling this.
It’s worth noting, just like above, these don’t have to be different physical databases. They could be the same underlying database instance but separate tables and/or columns as I explained above.
If you’re familiar with Event Sourcing, then you actually have a leg up as your events in your Event Store are the point of truth where you can derive all other types of views of that data.
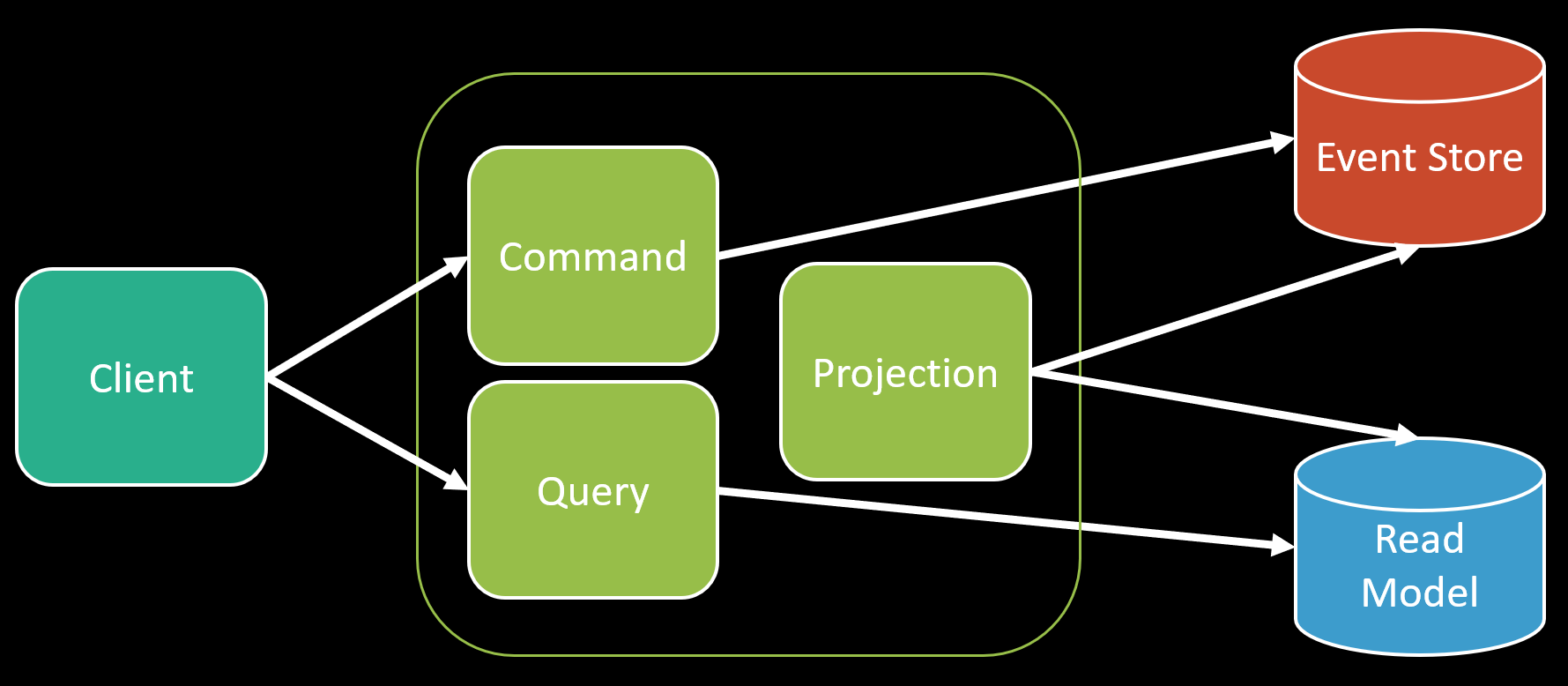
This is called a Projection and it allows you to read the events from your event stream and do all the same type of precomputation and persist it however you want for query purposes. You’ll also notice there is no message broker in the mix because you don’t need one. You’re event store often supports different subscriptions or, at worst, poll it to get the events you need to process to build your read model.
Lastly, a common scenario is for reporting purposes, where you need to compose data from various sources. This is where I find the value in Event Streams where various logical boundaries and published events that are persisted.
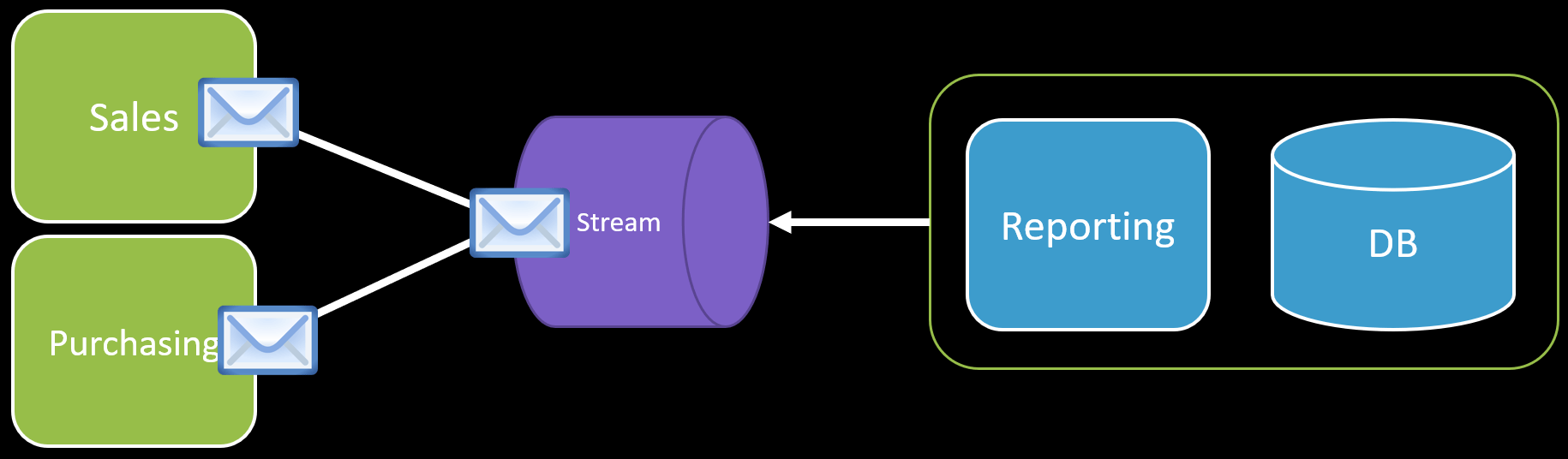
I’m not talking about a queue-based message broker, as you want these events to be re-consumed at any time. They don’t have a lifetime and can be persisted in the event stream log forever. This allows you to rebuild your materialized view at any time.
Materialized Views
You have a lot of options for creating materialized views that are optimized for queries. It’s interesting that many applications are more read-intensive than write-intensive, yet we typically persist data in a structure that’s optimized for writes. You can find the balance and optimize both where needed, especially in hot paths within your application that are query heavy.
Join!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.