Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
How do you scale a monolith? Scale-up? Scale-out? A monolith doesn’t need to be a big ball of mud! Monoliths with well-defined boundaries that are loosely coupled, you have a lot of options for scaling.
With well-defined boundaries, you can scale out each boundary independently, including the database. Boundaries within a system are so important, regardless of Monolith or (micro)Services, and give you more options for scaling.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything that is in this post.
Solution Structure
For a refresher, here’s the project structure of a loosely coupled monolith.
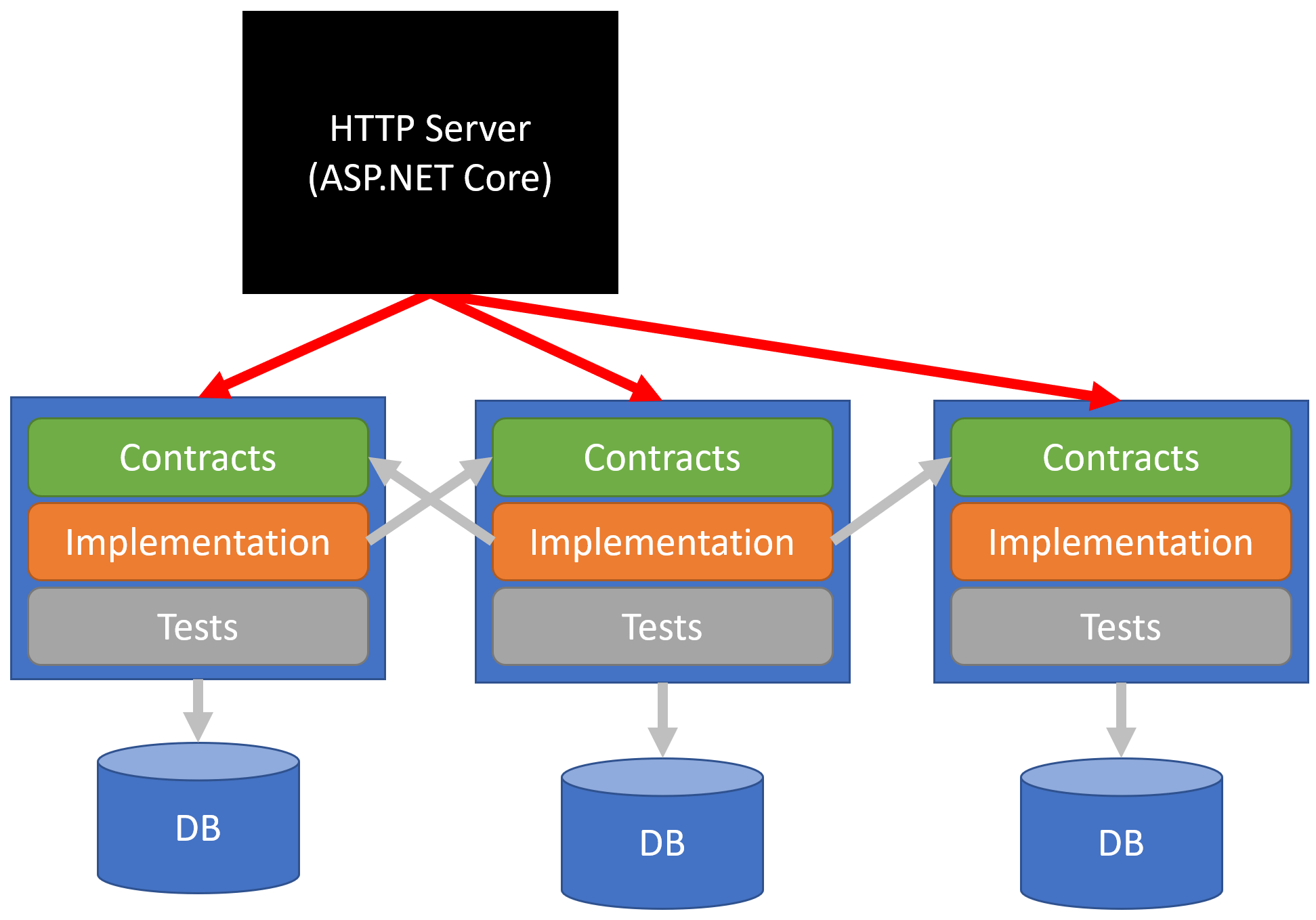
Boundaries are defined in the blue boxes that contain Contracts, Implementation, and Tests. Implantations only reference Contracts. Implementations do not reference other implementations.
Contracts are generally for Messages (Data Transfer Objects) and do not contain any application logic.
The top level application are the actual executable processes that reference all the other projects. They are the hosts/entry points to all the boundaries.
Each boundary has its own database. Implementations in a boundary are the only thing that can access that boundaries database. Period.
Scaling a Monolith
Usually, the obvious solution for scaling is to scale-up (vertical). This generally means increasing resources. Increasing CPU, Memory, Network, Storage, etc, for higher performance which allows you to perform more work and handle more load.
Scale-out (horizontal) scaling is distributing the workload over many resources. Loosely coupled systems allow you to distribute the system over different resources and provide better availability.
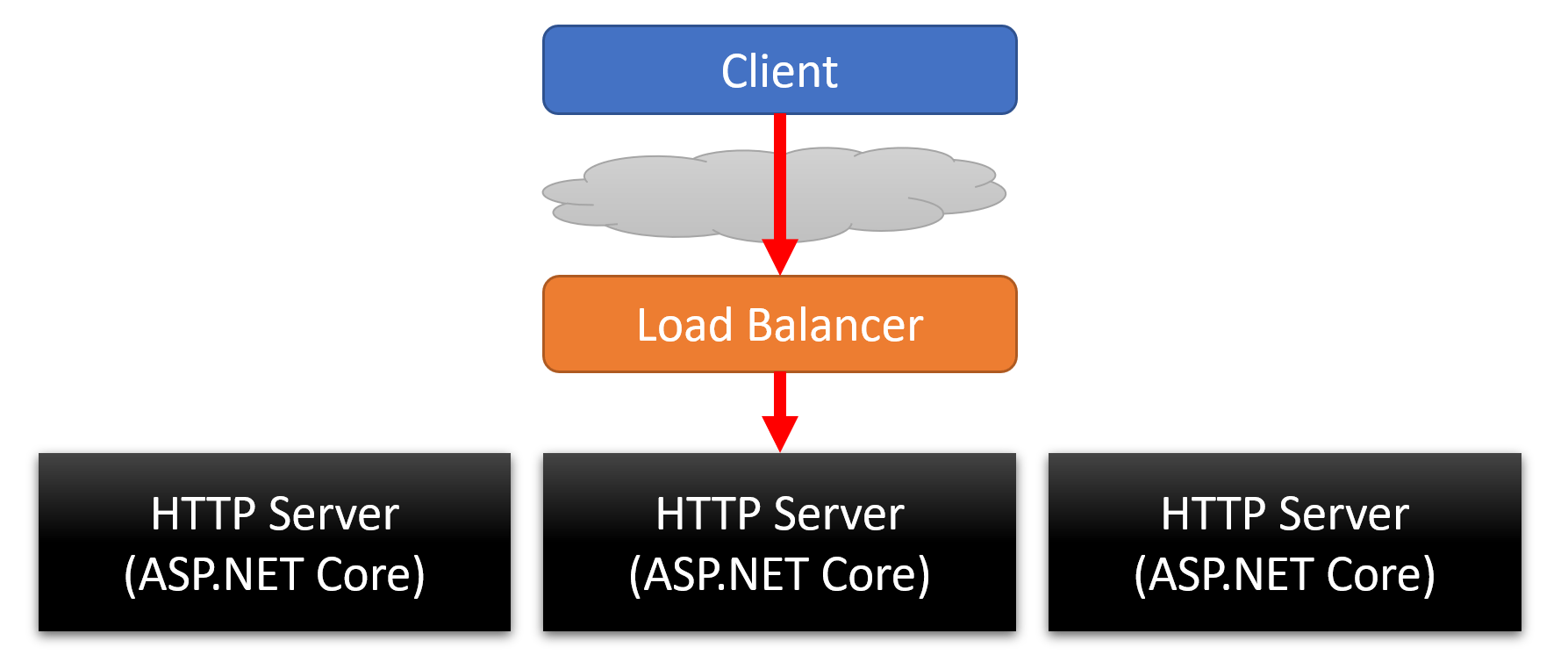
In the example diagram above, requests are handled by a load balancer, which then distributes the requests to the application. There are a variety of ways a load balancer distributes requests, the most common being Round Robin.
With a loosely coupled monolith, because we have very defined boundaries, this allows you to scale even further. You can start scaling the individual boundaries.
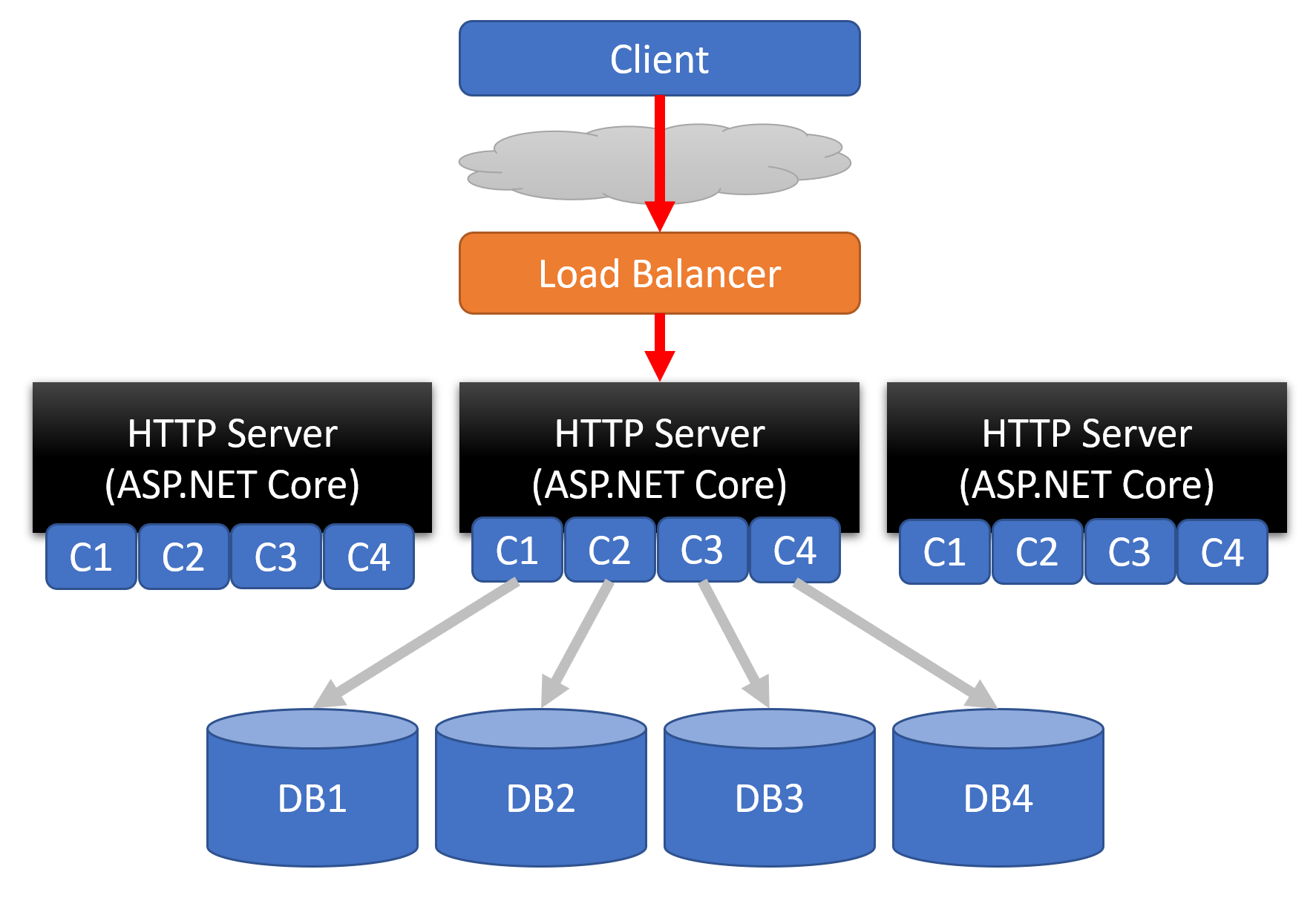
In the example above, all 3 servers are hosting all 4 boundaries (C1, C2, C3, C4). However, we can create load balancing rules to create groups of servers that will only handle requests for a specific boundary. These are often called Target Groups.
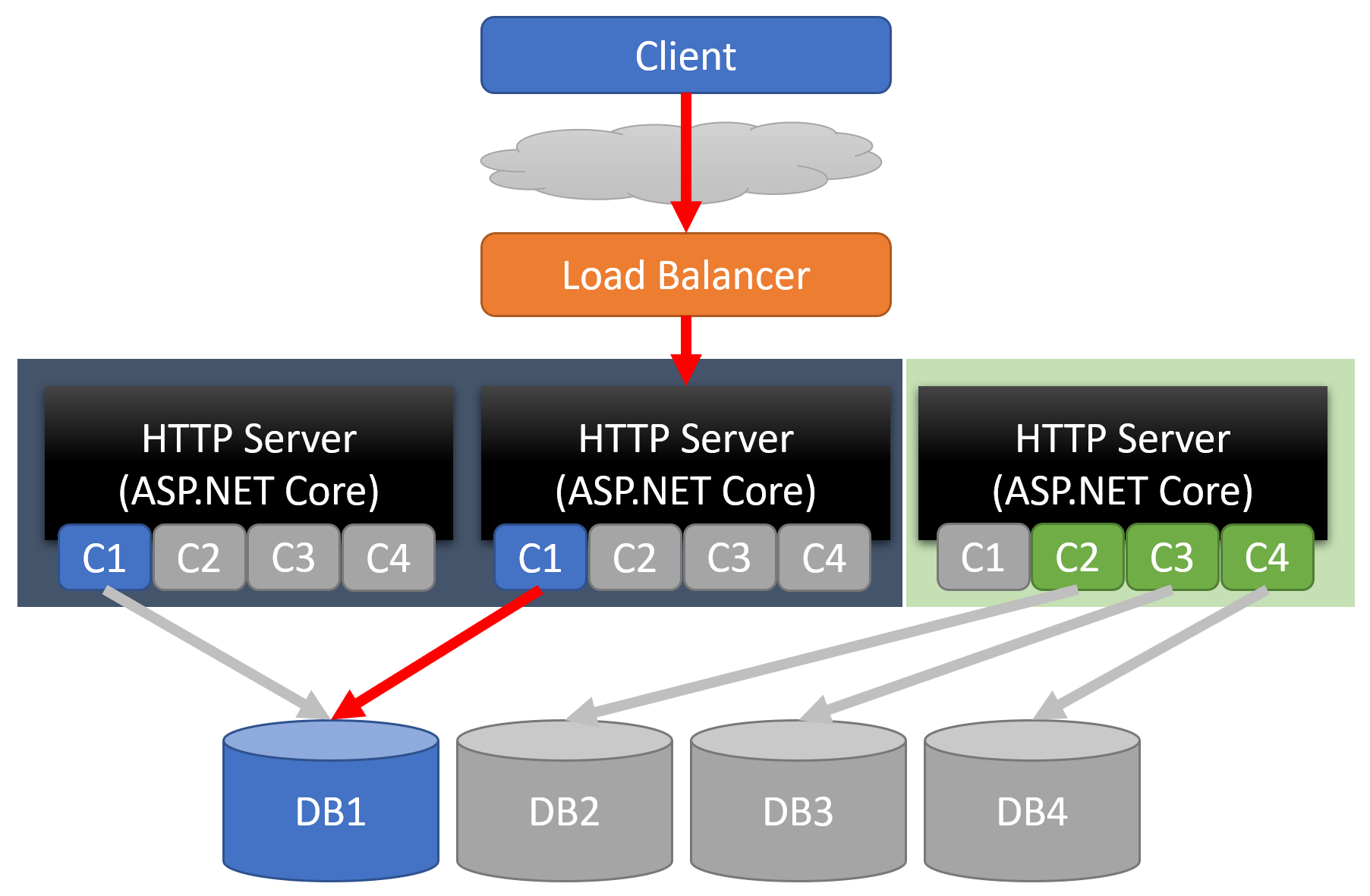
Here there are two servers that are handling the C1 boundary, and one server handling C2, C3, C4.
With well-defined boundaries, you can decide how to scale and route traffic with a load balancer to a target-group that handles that boundary. Although each server has all the code in our monolith, it is really only using the boundary that it’s handling. All other boundaries are basically dead code.
Database
The database can also become a bottleneck in a monolith. But just as you can scale by the boundary on the application/hosting layer, you can also make these same types of scaling decisions at the database layer of the topology.
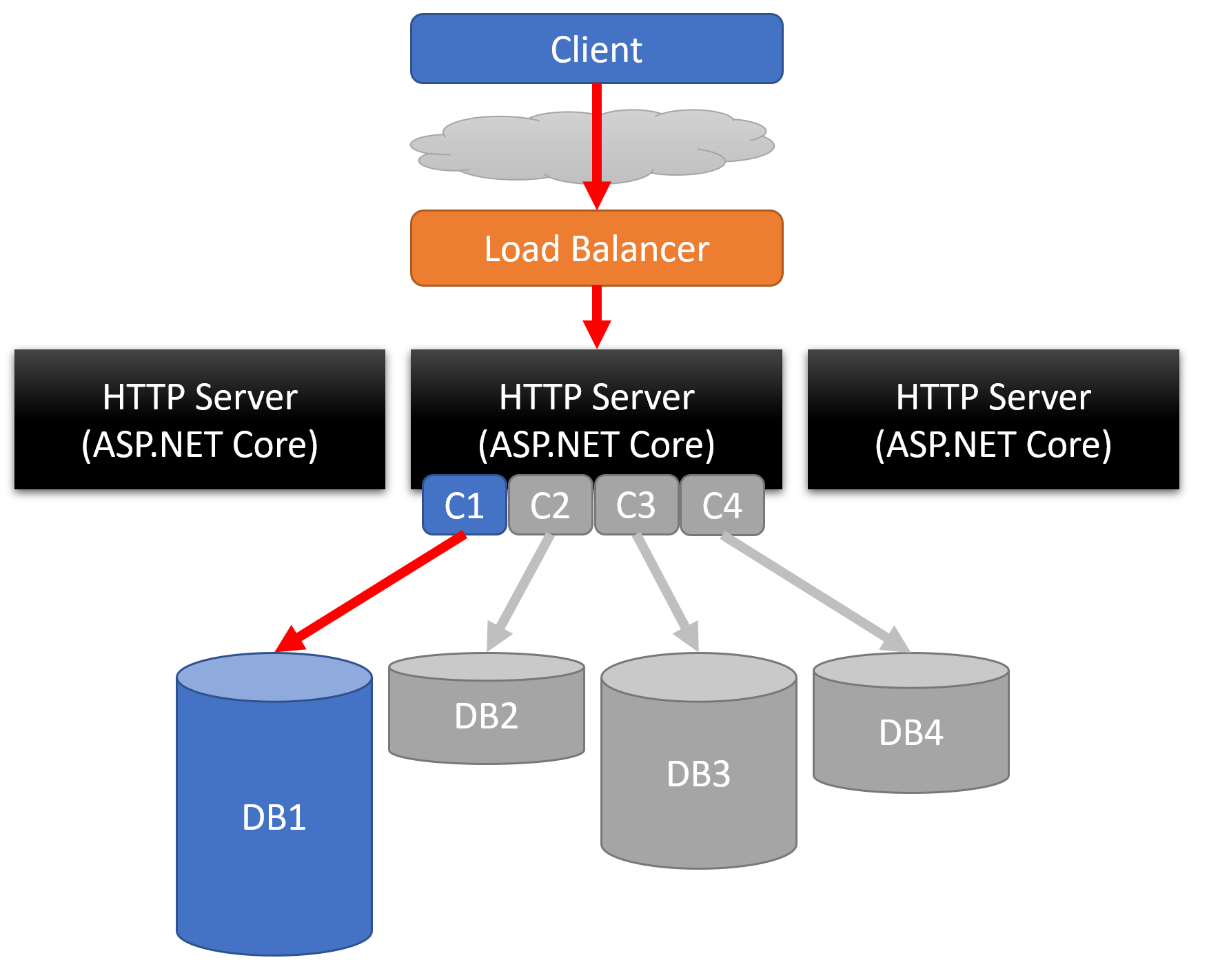
If one boundary has to handle more load, you could scale each database vertically differently. In the example above, DB1 might have more resources (CPU, Memory, etc) than the others.
Or you may choose to scale horizontally at the database level by adding read replicas or a cluster.
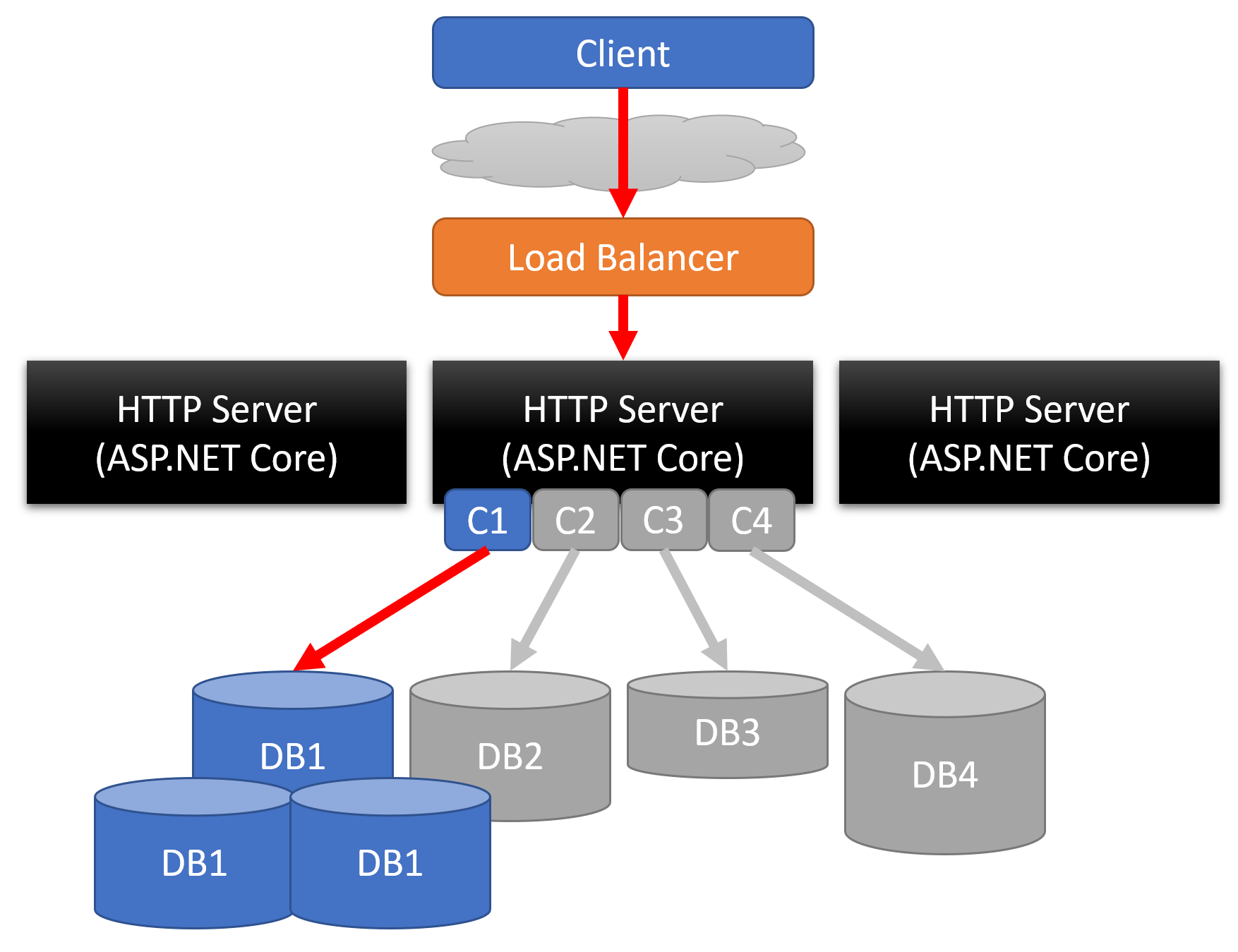
Scaling a Monolith
Well-defined boundaries are the enabler. They allow you to make scaling decisions per boundary. They give you options.
Check out the following posts on defining boundaries in a monolith or (micro)service architecture.