Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.

With microservices all the rage over the past decade or so, there has been little attention paid to how to develop a Loosely Coupled Monolith.
Both microservices and monoliths have their strengths and weaknesses. The intent of this blog and video series is not to debate the use of one or the other but rather to illustrate how you can develop a loosely coupled monolith. What the benefits come from a loosely coupled monolith and some of the drawbacks.
Loosely Coupled Monolith
This blog post is apart of a series of posts I’ve created around Loosely Coupled Monoliths.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts.
Boundaries
Regardless of Monolith or Microservice based architectures, boundaries are critical to both. In Domain Driven Design, the concept of a Bounded Context is defined. I’d argue it’s the most important concept from Domain Driven Design. It’s driven by language and mutual understanding between business and software. I’ve written & talked about boundaries in my Context is King: Finding Service Boundaries series.
For a short re-cap, for me, boundaries are about ownership. A Bounded Context is about business capabilities and the data behind those capabilities.
It’s NOT about entities. It’s NOT about having an entity service that performs CRUD over those entities.
It’s about capabilities that will be owned by the bounded context. With that, you cannot have behavior without data.
In a solutions view of a bounded context, I like to think of it as having 3 projects.
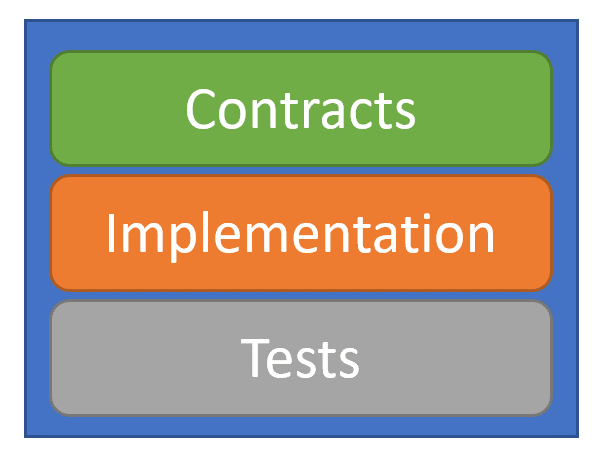
Contacts project contains things like interfaces, delegates, and DTOs (Data Transfer Objects).
Implementation project contains all of the code for the actual implementation of your bounded context.
Tests project is for well… tests.
Project References
With any large monolith, you’re going to have many bounded contexts. The key is that they are silo’ed from other bounded contexts implemenation.
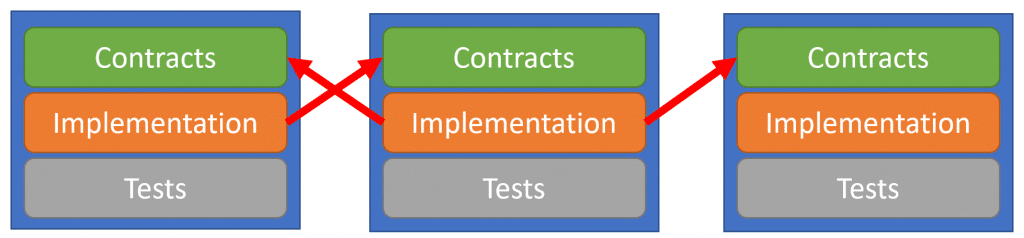
Any implementation project will not reference the implementation of another bounded context. The only reference it can have is that of other contract projects.
An implementation project will only couple (reference) to contacts projects because that’s where our DTOs that represent messages & events live. DTOs are nothing more than data buckets. The contract projects contain no actual logic.
Databases
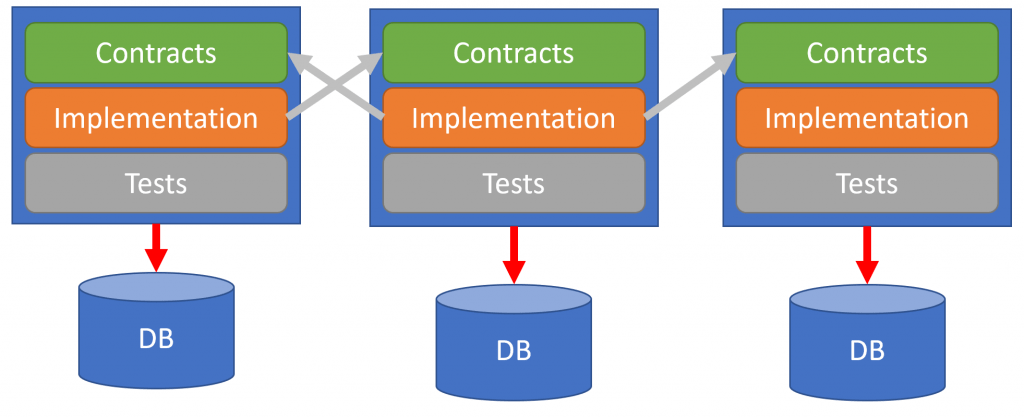
Since each bounded context is the owner of its own data, there is no need for a shared database.
Each bounded context MUST have its own database which it is the owner.
No other bounded context will have access to this database or any type of data access layer such as Entity Framework DbContext. Each context has access to its own database and that’s it.
Top Level Entry Points
There must be some top-level entry points to our application. These are the actual executables that are running in service, in a virtual machine, or in a container.
In the example of this monolith, I’m assuming it’s a web application that is either an HTTP API or is serving HTML as a server-side web app.
ASP.NET Core
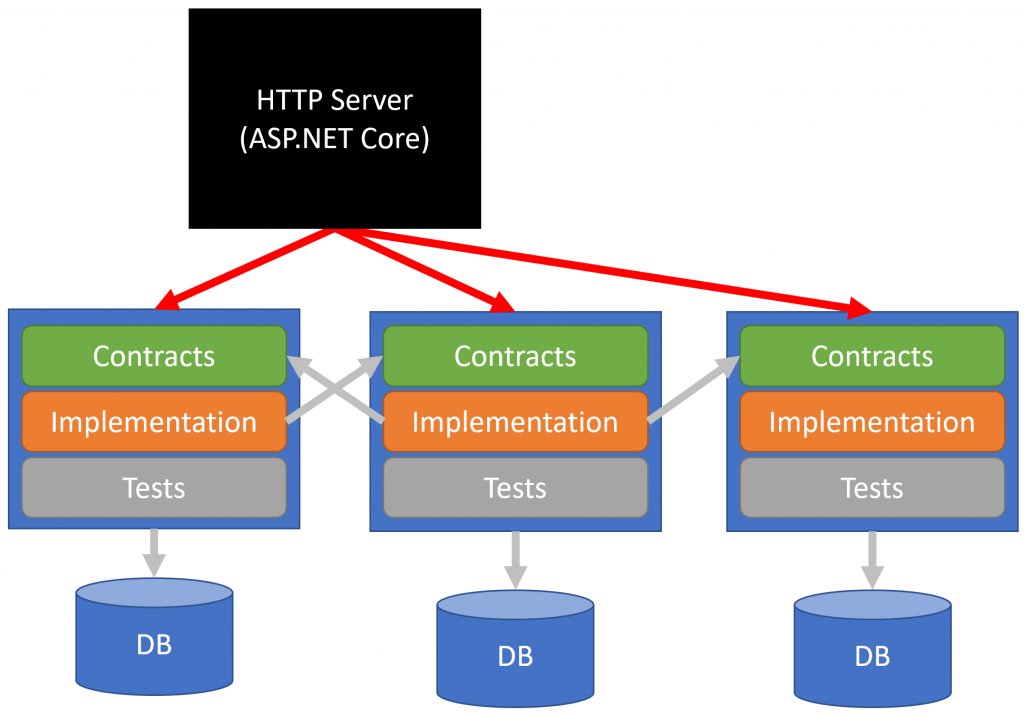
There is a single project that is the ASP.NET Core Host. Basically this hosts the WebHostBuilder and the ASP.NET Core Startup class to configure the app. It will reference all of the bounded-context to provide them with a means to expose their HTTP routes (MVC Controllers or Endpoints).
ASP.NET Core is composing all the bounded contexts together.
Message Broker
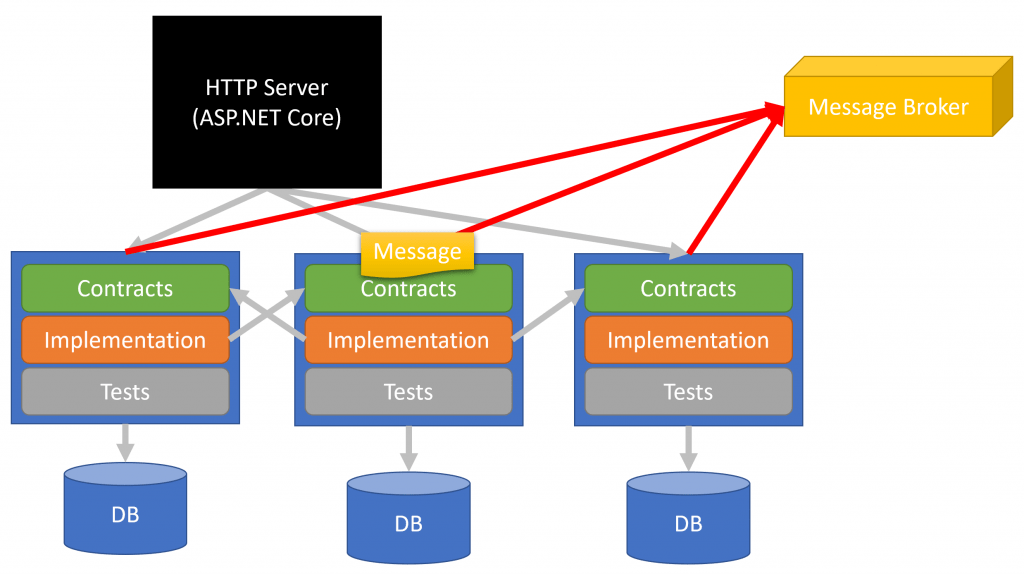
Bounded Contexts generally will need to communicate. This is done via events. This is no different than Service Oriented (SOA) or Microservices architecture that is event-driven.
This is where a message broker enters and also why the contracts project contains our DTOs that represent events.
Whenever a bounded-context has a state change that is derived from behavior, it can publish an event to the message broker.
Message Processor
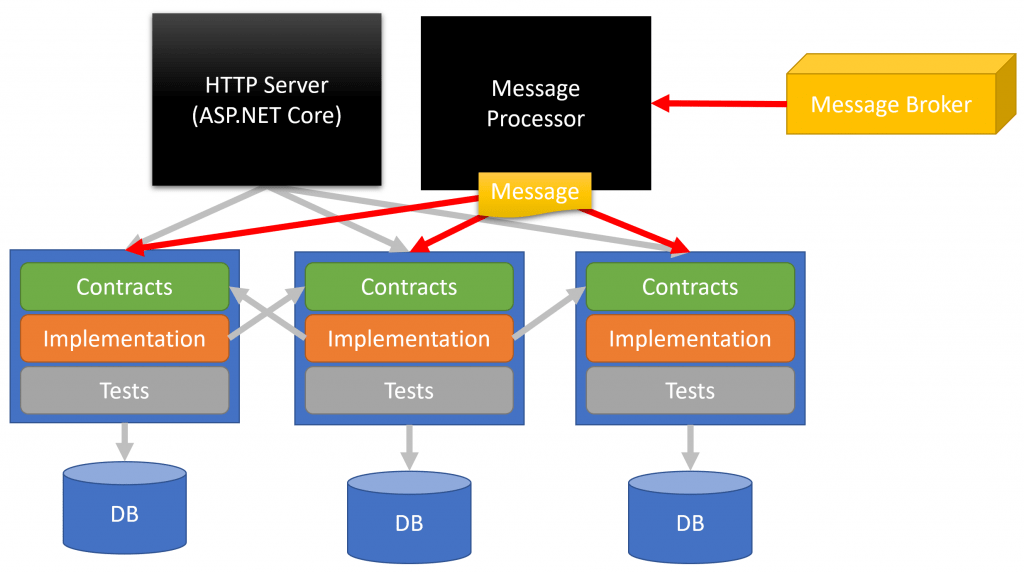
Another top level entry point is the Message Processor. This is the process that receives events/messages from the Message Broker and dispatches them to the appropriate bounded context that wants to receive them.
An event/message may be received by none or many different bounded contexts.
A bounded context that receives an event might then perform some state change and publish another event back to the message broker.
Loosely Coupled Monolith
This is really just an event/message driven architecture inside a monolith. It has clear boundaries between bounded context and separation of data.
In many ways, you could view a lot of the aspects of this architecture as similar SOA however the difference being that they are all in the same codebase and all hosted in the same top-level entry points (executables).
Benefits & Drawbacks
As with everything there are benefits and drawbacks to this approach here are a few of the bigger ones to note.
Benefits
The benefits of this approach are that the same of any monolithic architecture. The code is altogether. All the source code is all within the same solution/repository.
If you want to refactor an event you can find all the different bounded contexts that use that event.
Simplified deployment (and local debugging). There are only two actual executables that need to be deployed (this can also be a drawback).
Lastly, if you ever want to carve off a bounded context and host it on its own, you simply do it. There’s no coupling preventing it. You simply copy the top-level entry points and only have it access the bounded context you’re extracting.
Drawbacks
Single deployment. This isn’t a drawback on this specific approach but on monoliths in general. When you’re deploying, one bounded context can take down the entire application. Since ultimately all the code gets run together in the top-level entry points, there’s more risk during deployment.
You must be diligent in following the rules of not referencing implementation and not accessing another database of a different bounded context. This takes an understanding of all developers working on the system.
If your system becomes large enough, build times and deployment times can take a while.
Questions or Feedback
If you have any questions or comments, let me know in the comments of the YouTube video, in the comments on this post or on Twitter.