Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
You’re ready to deploy a new service but need to seed it with data from other services. How do you do that? I’ll cover various solutions to this common problem I often ask about. Stick around because I will challenge you to comment to provide use cases and why I don’t think it should be that common.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Local Cache
Often, people want to seed a new service with data from another service because they’re keeping a local cache copy of that other services data. This is typical when you’re using event-carried state transfer to distribute data between services.
Let’s be clear: I don’t suggest using Event-Driven Architecture to propagate data. But this is how the industry is going, so I figured I’d address the question.
Event-carried state Transfer is when you publish data-centric events rather than behavior-driven ones. This means that when your underlying data model changes, you might publish an event to reflect either that specific data model change or publish an event of the entire “entity” that changed.
Let’s say that Service B publishes a ProductChangedEvent or a ProductPriceChangedEvent, which ServiceA consumes and updates its database so it has a local cached copy.
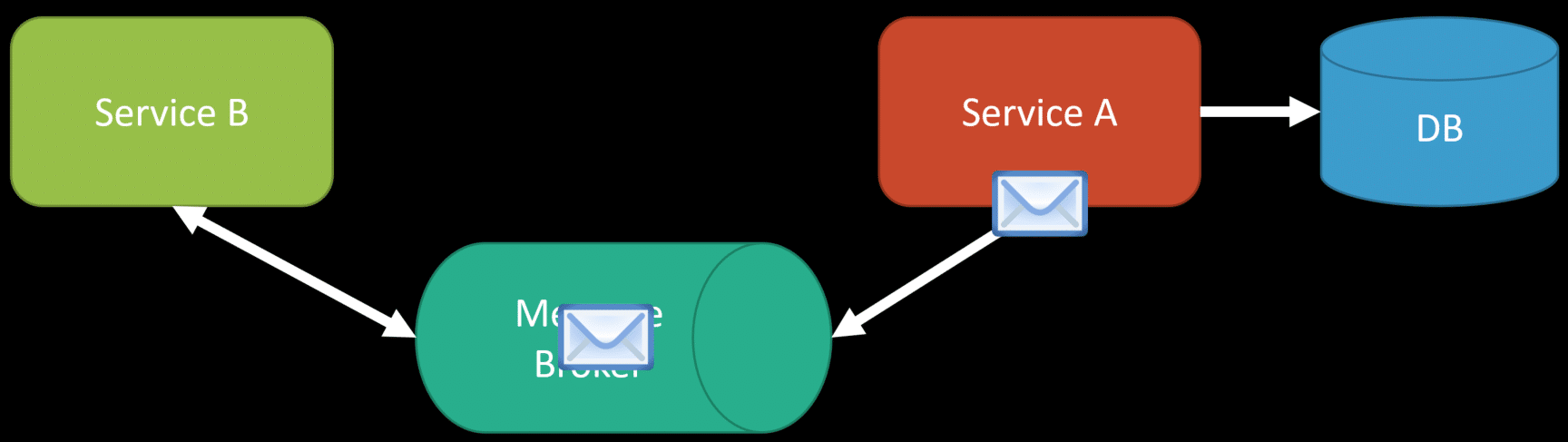
The challenge is that if you’re starting a brand new service, you likely need some seed data. You’ll have nothing initially. So, if you consume a ProductPriceChangedEvent but don’t have any of the initial data, you can’t update anything.
Seed a new Microservice
One of the most popular solutions seems to be using an event log, something like Kafka, with indefinite retention.
That way, when you deploy a brand new service, you can have it read from the existing topics from the beginning to populate and build out its own local cache copy of whatever data you need. This allows you to get all the initial data you need from all the historical events.
This requires you to use an event log or something similar to Kafka right from the very beginning of your system to leverage this type of solution.
Change Data Capture
Another trend has been using CDC (Change Data Capture) tools to capture database changes and then publish those to a log or message broker. One of these tooling solutions is using Debezium alongside Kafka.
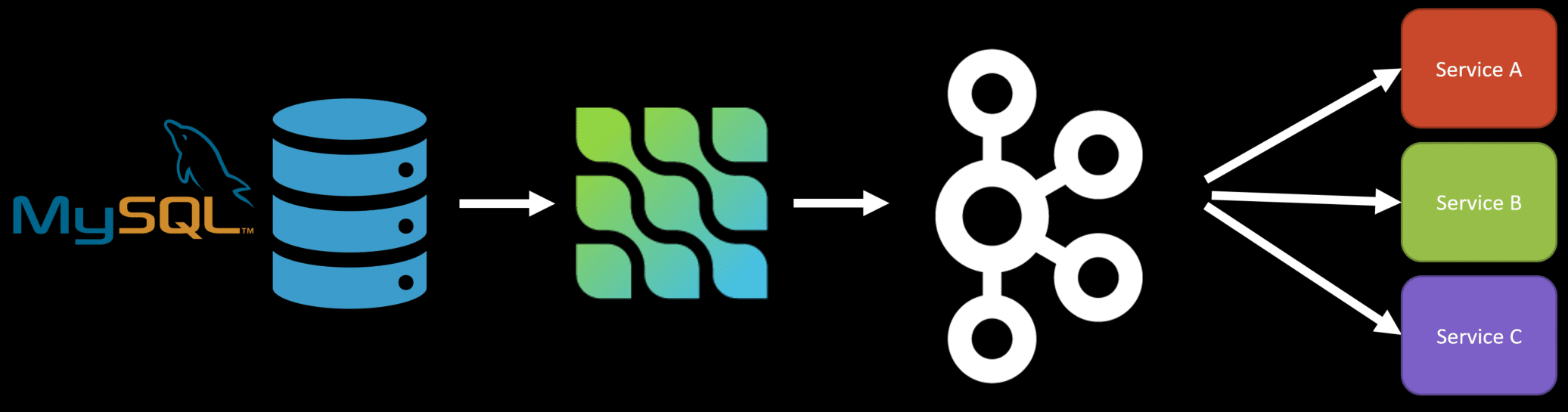
Debezium listens to the replication binary log of MySQL in the example and then can publish events of the changes to Kafka. From there, you can have other services consume those events.
There’s nothing wrong with CDC. However, this form of using Event-Driven Architecture is really about data distribution. Just because you’re moving to an asynchronous model of distributing data, does not mean you’re not coupling. If your CDC events are representative of your database schema, you’re not only leaking internal implementation details from a service but also coupling by data. Sure, moving asynchronously with a broker removes the temporal aspect, but you’re still coupled.
There’s not much difference between that and accessing another database directly besides the temporal aspect.
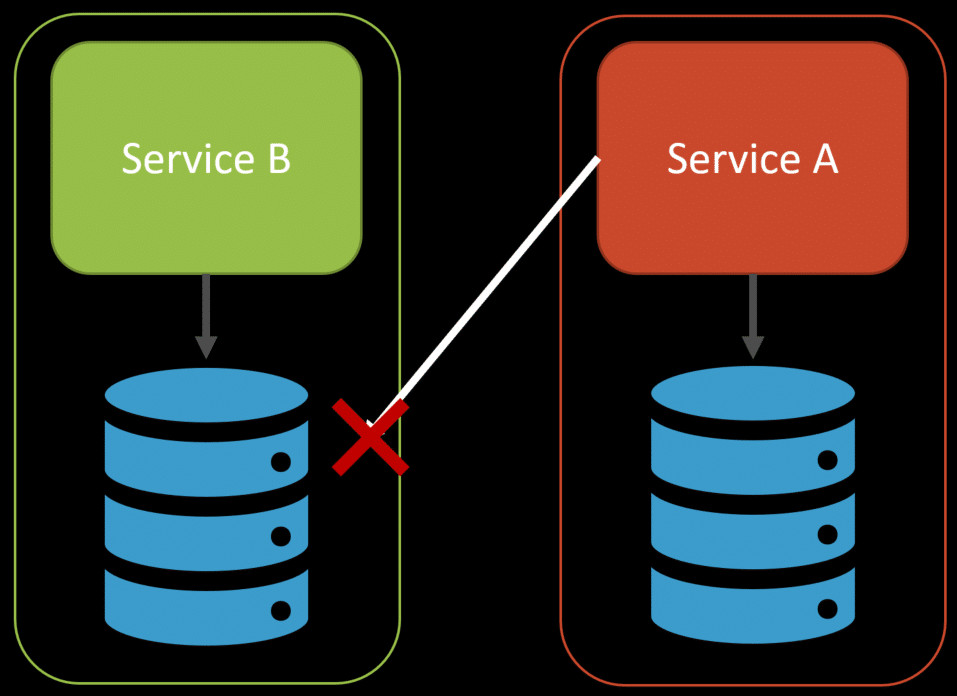
We don’t want this coupling, regardless of whether it is synchronous or asynchronous.
Call Producer
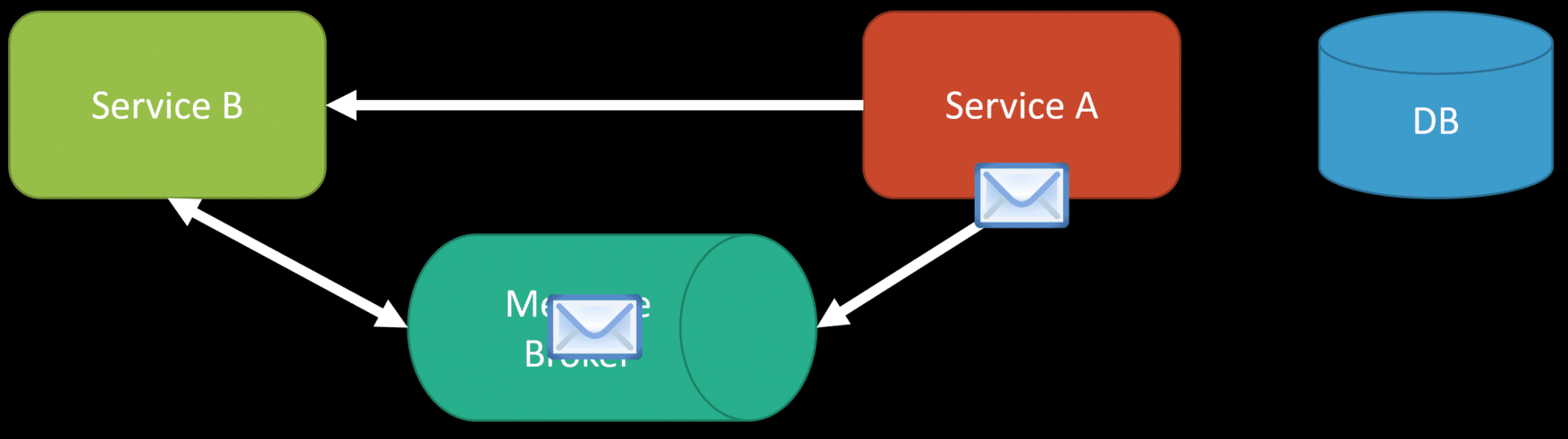
If you’re getting delta change events or need some initial data before it, another solution is to lazily call back the producer when you need it.
If you receive an ProductPricedChangedEvent for a product you do not yet have, you call back the producing service to get that data via synchronous API call.
Data Dump
Another option is to have each service do periodic data dumps to some blog storage of historical data. Then, you can use any new service as a snapshot seed data.
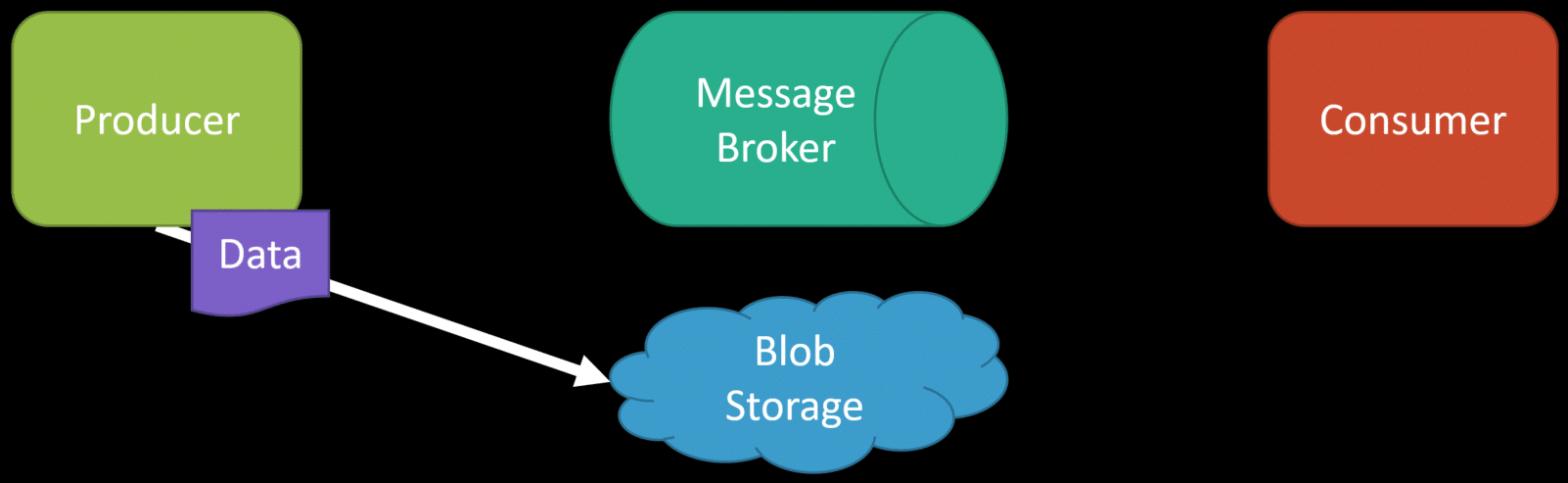
Once your new service has been restored using the snapshot/dump of data, it can start consuming messages from your event log or message broker given a point in time from when you restored the dump.
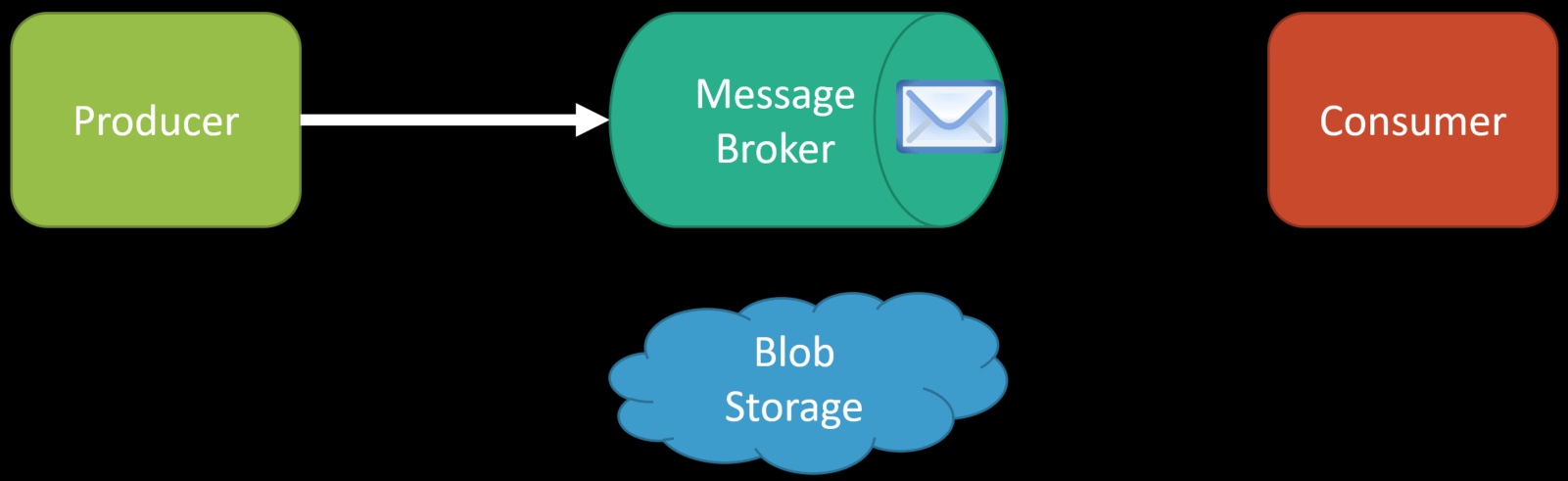
You may decide that since a service doesn’t have a lot of data, you expose some type of API that a new service can call to get the historical data. A lot of this is context-specific about how much load or stress this might put on a service.
This shouldn’t be a problem.
I mentioned initially that I don’t think needing to seed a new Microservice should be a problem. These are solutions to a problem I don’t think you should have often.
Distributing data around into a decomposed system is difficult because you’re dealing with stale data and possibly inconsistent data. If you need consistency, you’re likely in a bad design where data isn’t owned where it should be.
Most often, however, services need data from another service for query/ui/reporting purposes. If this is the case, you might want to check out my post The Challenge of Microservices: UI Composition.
BI and Reporting I view as legitimate places where you want to compose disparate data, and CDC and Event-Carried State Transfer can be a solution. However, if you need data from another service to enforce some business rules, I’d be looking at if you have data ownership in the correct place. Check out my post “I NEED data from another service!”… Do you really?
Join!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.