Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
If you’re working in a system that’s hard to change, it can be incredibly frustrating. It feels brittle, as if making a change in one part causes a bug or some negative side effect in another part that you had no idea about. You want to improve your system, but how? How do you go about this when it feels like a disaster? There is a way, and I’m going to share a strategy with you: look at your database first, you likely have database coupling that is the root cause.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Understanding the Root Cause of a Brittle System
The first thing you really need to address is finding out what the root cause is that’s making your system hard to change and brittle. Typically, it’s integration at your database level. It’s your database actually causing this issue.
If we just had a simple app and a simple database, you likely wouldn’t have this problem. However, the way to illustrate this is if you have multiple applications involved: it could be a cron job, some batch job, some simple other process besides your main application, or even somebody going in and manually changing data directly in your database.
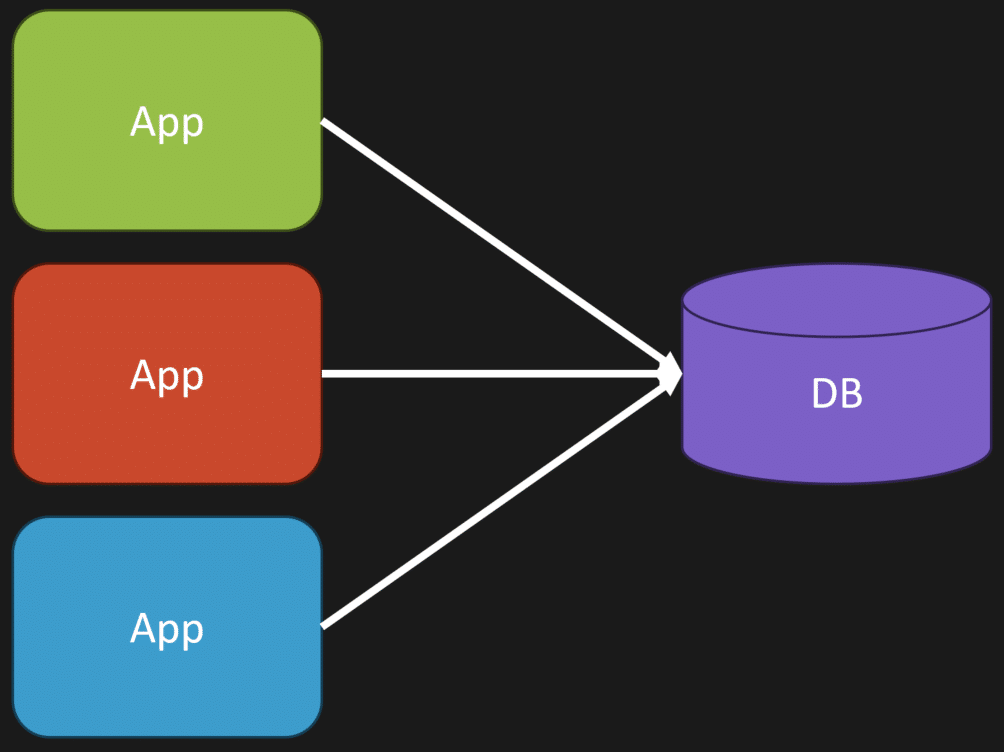
The key point here is that you have many different interactions with that singular schema, with that database.
Owning Your Database Schema
Who owns the database? This is an important question. You want to have one singular thing in your system, in your codebase, that owns that schema. You want ownership over it because ultimately it’s deciding how data is getting written to it and how you’re reading from it. You want ownership. You do not want a free-for-all where any part of anywhere can just read and write data.
I’m making these two things distinct here:
- Writing: You’re going to have constraints about what data can be written and how. Often times, if one particular property is changed, maybe something else needs to be changed with it to keep it valid.
- Reading: How you read the data might be different, but it has to respect the ownership boundaries as well.
You want ownership to enforce those rules so you’re setting data correctly.
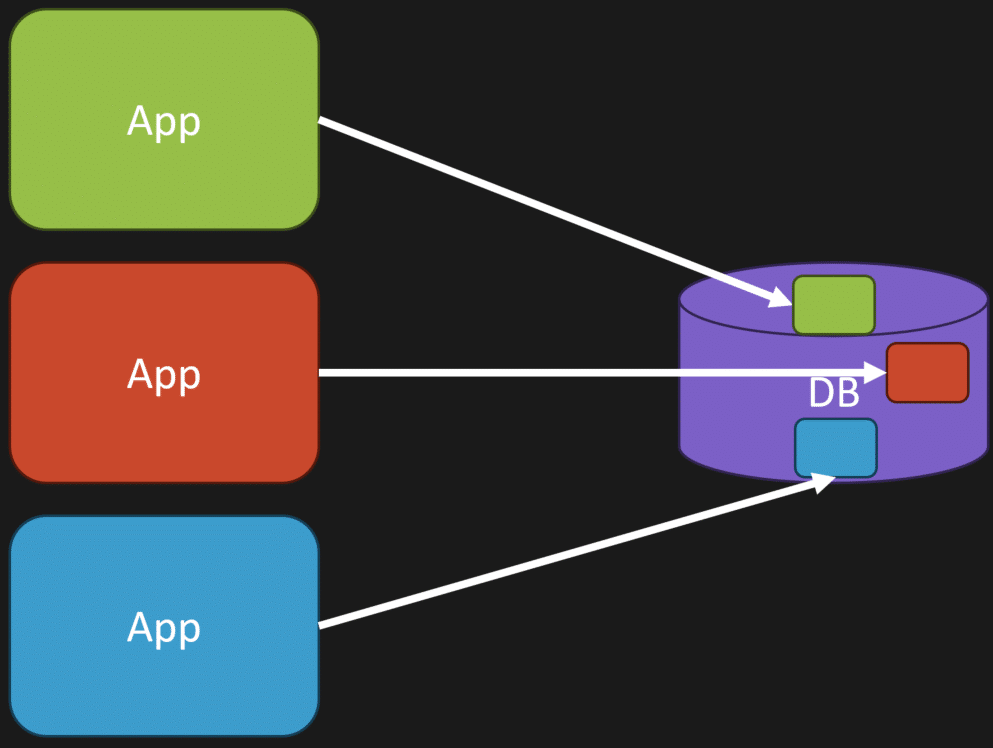
To illustrate this, you don’t want to be thinking, “Okay, I just have one schema and it’s a free-for-all.” Rather, what we want to be thinking about is, “Okay, we have this part of the schema; we can segregate that.” Then we can have a portion of our app — whether it’s independent or a monolith — it doesn’t really matter. We just think, “Okay, within that monolith or that particular service, this is the data that it owns, it manages.”
That’s the first step: siloing off, segregating, and slicing off the ownership of what the particular pieces of data are for the functionality.
Defining Ownership Boundaries
Define what the ownership is for a grouping of functionality. That’s really the first exercise.
Look at your database, look at your system, and you’ll know the context to think about, “Okay, what’s an easy part that we can carve off? This isn’t going to be the core part of your system that’s very complicated.” You know your system, and you’ll know there’s a part that’s kind of on the fringes — maybe it’s important but not used as much, like referential setup data or something similar. That might be a good place to carve and isolate.
You can isolate the schema and isolate the code so they’re kind of one-to-one together, and then define that ownership.
Visualizing Ownership in a Monolith
Just another way to visualize this: if you had a monolith, it’s really just defining what these ownerships are at the schema level and then segregating the code that way. You kind of have this one-to-one between ownership and code to the exact piece of schema that it owns in that database.
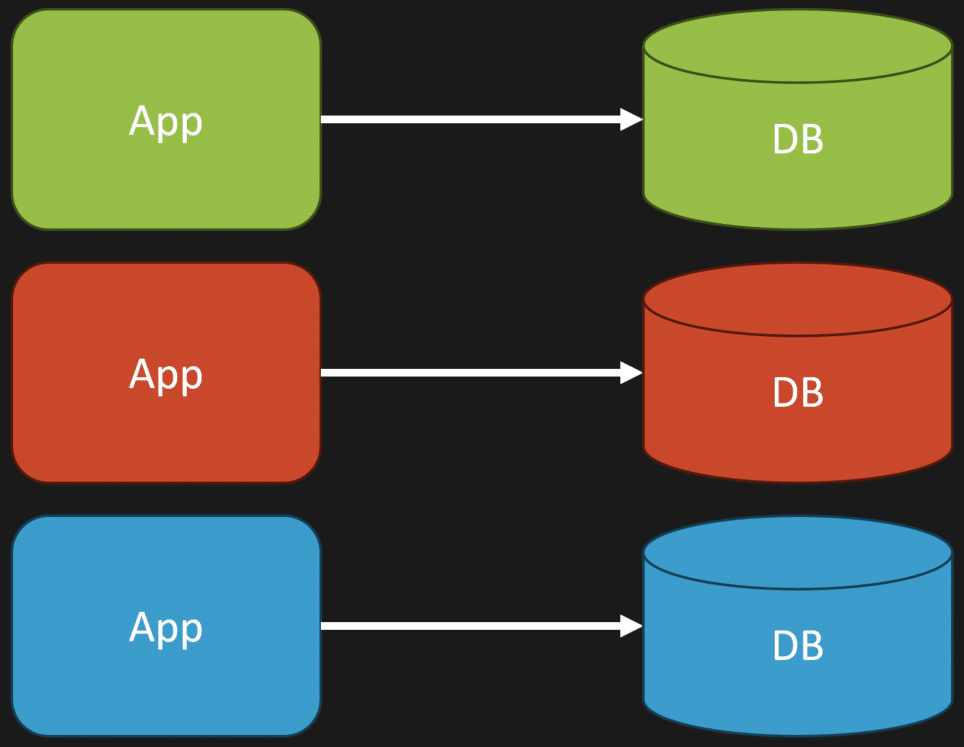
Does this mean you have to have different databases, different executable deployments, or microservices? No. It’s not about that physical aspect. It’s about in code, whether it’s a monolith or not, having code that has ownership of the schema.

If you’re using a relational database, this could be as simple as a set of tables that you have ownership over. If you’re using an event store, it could be a certain set of event streams. Same thing with a document store — a set of collections. It’s just about having that ownership. It doesn’t matter if it’s a single database instance or multiple.
How to Decide What to Carve Off
Another helpful hint on how to figure out what exactly to carve off when looking at your system: typically, it’s data that changes together.
I mentioned earlier that it’s important to think about reads and writes differently. When you look at your database and ask, “Okay, what can we carve off?” look at the data and how you’re changing it. What data changes together?
This distinction is important because you can often segregate how you’re doing your writes to some specific set of code that manages all that state change.
The more difficult aspect is that systems are often more read-heavy and they do a lot of composition. How do we handle that?
Why Direct Database Queries Between Components Cause Problems
To illustrate, imagine you have multiple apps (or a monolith with defined boundaries) and schemas they own. What you don’t want to do is have one part of your system querying another database or schema that’s owned by something else.
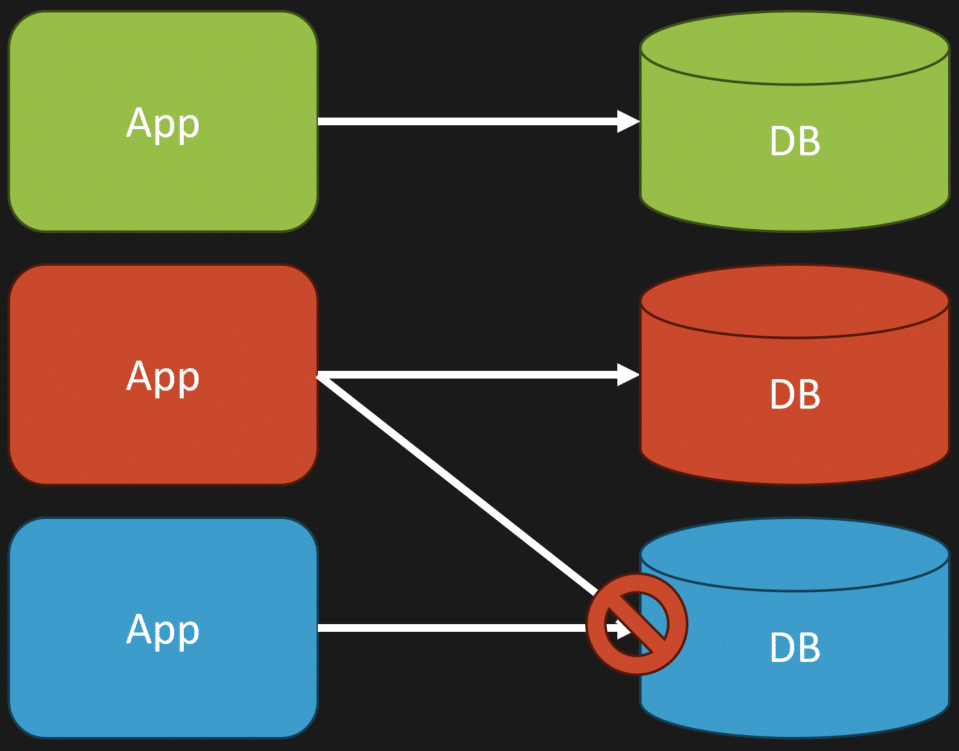
Why? Because that’s what got us into this problem in the first place. This makes it hard to change. Even if you’re only doing this for query purposes, the reason is that the lower database is owned by that lower segment of code. It’s an internal implementation detail about how it persists data.
If the middle tier or that part of the code interacts with that database directly, it becomes highly coupled to it. It knows the data types, the names of the columns, tables, event streams, or documents — whatever your persistence layer is. It knows too much.
Introducing Explicit Contracts and APIs
What we want to do instead is expose something we can version and manage as a contract. Our database should be internal, an internal implementation detail to the code that owns it. We want to find something else as a contract that we can manage for all the other consumers.
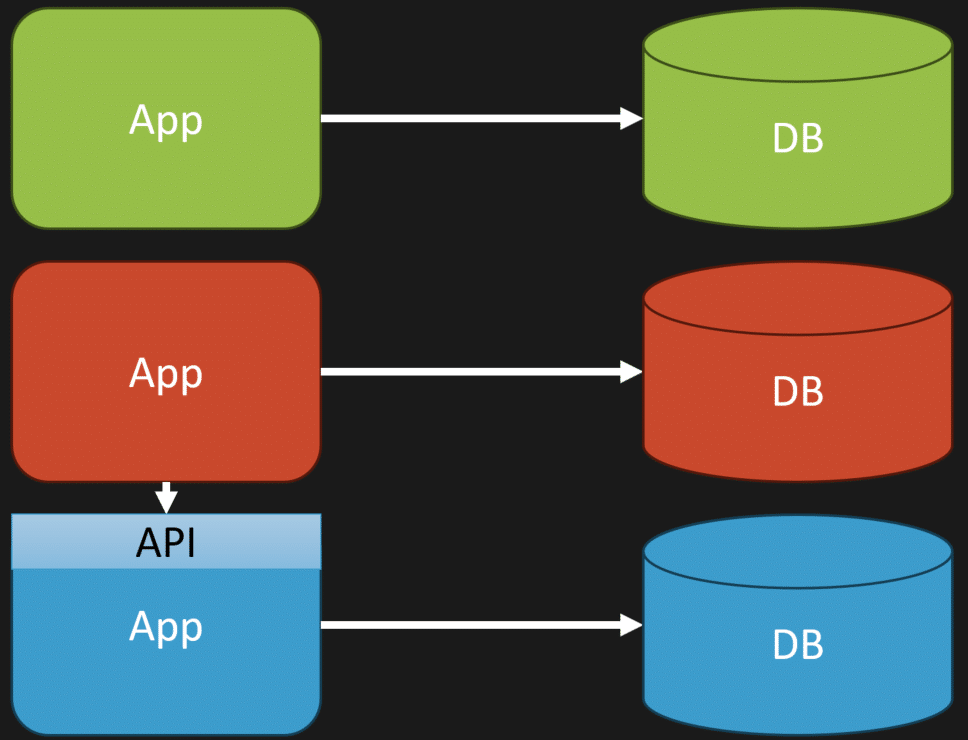
That’s why we want to find some type of public API that other parts of our system can interact with. We want to get rid of this interaction directly with our database from other parts.
This is a step in the right direction because we’ve removed all that chaos and integration at the database level. Now, we just have explicit contracts and APIs. But that’s what everything is coupled to now. You’re not removing coupling — there’s no magic here. It’s about managing coupling.
This is one way of doing it. We’re explicitly managing coupling on something that we can version and manage rather than a free-for-all at our database.
How You Interact with the API Depends on Your System
How you interact with that API really depends on your system. If you’re in a monolith, it’s as simple as exposing an interface that you inject and that other parts of your system use. Maybe it has to go over the network because you have another system deployed separately. You might use gRPC or develop an HTTP API. It depends on your system and whether you have physical constraints or not.
The Next Step: Removing Coupling with Messaging
Even if you just carved off one piece — and you have this direct API call in memory or over the network, you might realize you don’t want that coupling.
How else can you manage it?
If you take off one of those boundaries that is more in a supporting role, you might be able to use messaging to provide information that can be used later for whatever it needs to interact with.
Instead of making that API call, you can use asynchronous messaging. This could be commands and queues, events and topics. You’ll explore this more once you go down that path.
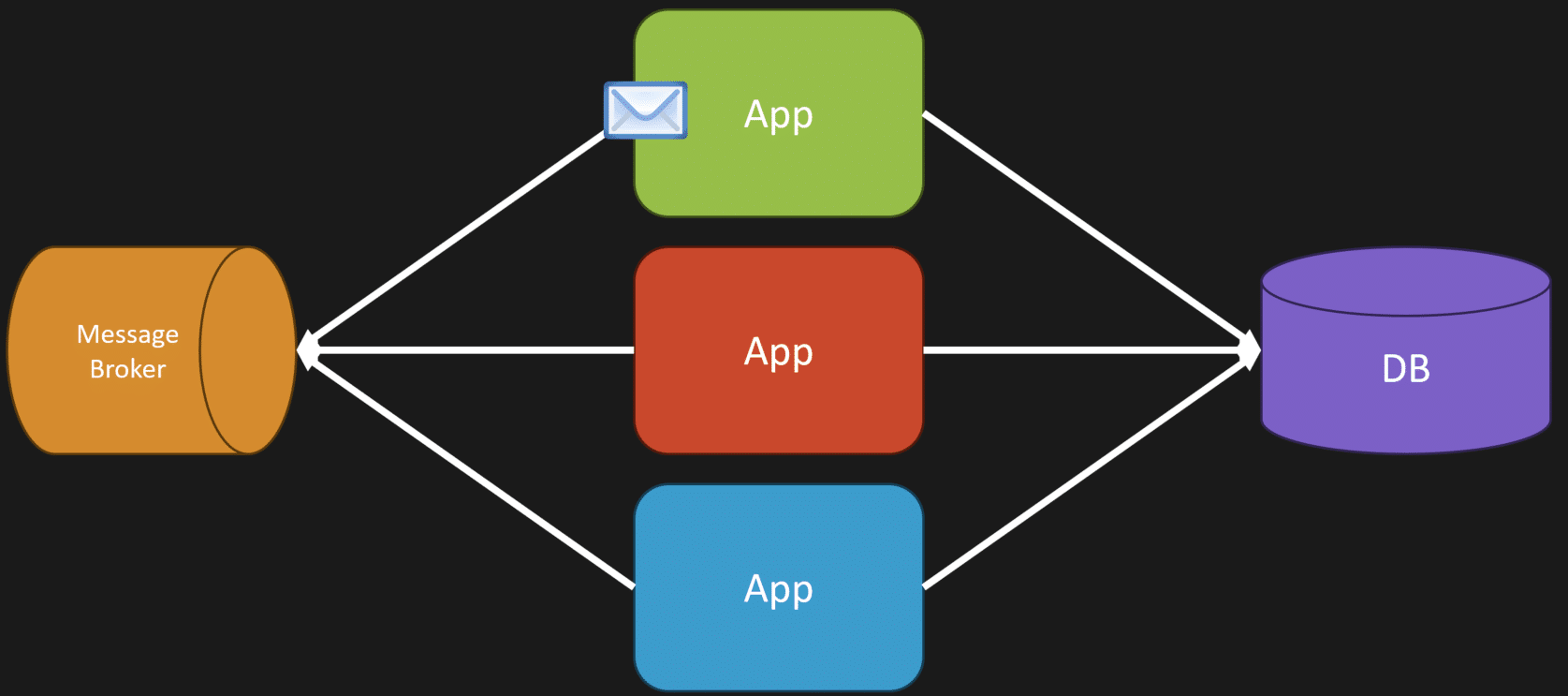
The general gist is: once something happens in one part of your app that you’ve carved off, and you need to let other parts know something occurred, you can use an event-driven architecture.
Then, different consumers can understand, “Okay, this happened previously.” You would have been notified directly before via an API call, but now you’re removing that temporal aspect. You’re just publishing events that other parts of your app can interact with when something occurs.
Why Defining Boundaries is Difficult But Important
Defining boundaries in your system is one of the most important things to do, but it’s also one of the most difficult things to do, especially if you have an existing system. It’s hard to see where those boundaries actually lie.
This is not an easy task or exercise to carve something off and extract it.
My suggestion for your journey forward is to look at your database and your codebase and figure out a small subset that you can separate. Start there as an exercise. You’ll learn a lot when you carve off something small: how the rest of the system interacts with it and how you manage that coupling, how you expose that API, etc.
Look at your database, look at the data that changes together. That really revolves around the same capabilities of your system. Try to carve that off. That’s my recommendation if you’re in this situation now or thinking about doing this.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.