Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
How do you handle long-running HTTP requests that take long to complete? For example, how would you design an HTTP API that needs to generate a transcript for a specific video (by ID)? Deeper into that question, you can assume that won’t be a fast request/response, so how can we better manage this? Using asynchronous request/reply with HTTP.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Designing an API Endpoint
This video/blog were spurred on by this post I came across on Twitter/X. I didn’t think the suggested solutions fit the question that was posed for a few different reasons.
The reason is that the scenario above likely isn’t a quick response. Typically, when you make an HTTP call to your API, you expect a response as soon as possible to either get the data you requested or know whether your action was accepted or completed.
However, many scenarios like the one proposed won’t have an immediate response. I’m assuming here that generating the transcript for a video isn’t something that will take less than a second or two. Sure, it might be quick for a short video, but what about an hour or two of our video with all the dialog?

The problem is that if it takes 3 minutes to generate a transcript, then the HTTP request will take at least that amount of time to complete and return a response to the client. There are many issues with an HTTP request taking this long. First, you must deal with HTTP Timeouts defined upstream if you’re behind a load balancer. Another is the client having its own timeout. This could be another server, the browser directly, or a JavaScript client making the request. If the request is retried because it’s “taking too long” for the client, how are you handling idempotency?
So the two options above about a POST or GET request are not really the concern. The root problem is how to handle a long-running process or workflow.
Async
A solution is to process work asynchronously. In our example, to perform the work of generating the transcript won’t happen when the HTTP request is made, rather we’ll perform that work asynchronously, independently from the HTTP request.
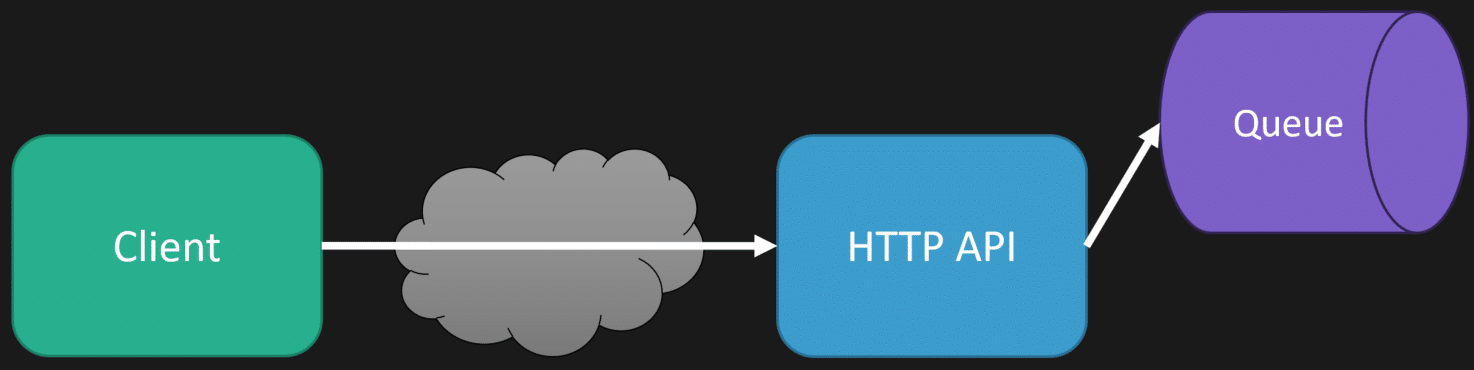
This means that when the client makes the HTTP request to the HTTP API to create the transcript, instead of doing it immediately, we’re going to place a message on a queue. Then, we can return a response to the client immediately (within milliseconds) from our HTTP API.
Separately (process or thread), we consume the message from the queue to generate the transcript.

But there’s a problem here. How do we communicate to the client to provide the transcript or notify them that the transcript has been generated? If we return immediately after placing the message on the queue, what do we tell the client? Without the queue, the client had to wait an unknown amount of time, but when it was completed, they knew it was generated, assuming a successful HTTP response.
So, how do we communicate with the client now that we’ve moved the work async?
A common solution is providing the client with a URI that they can poll to find out the status of the work being processed async.
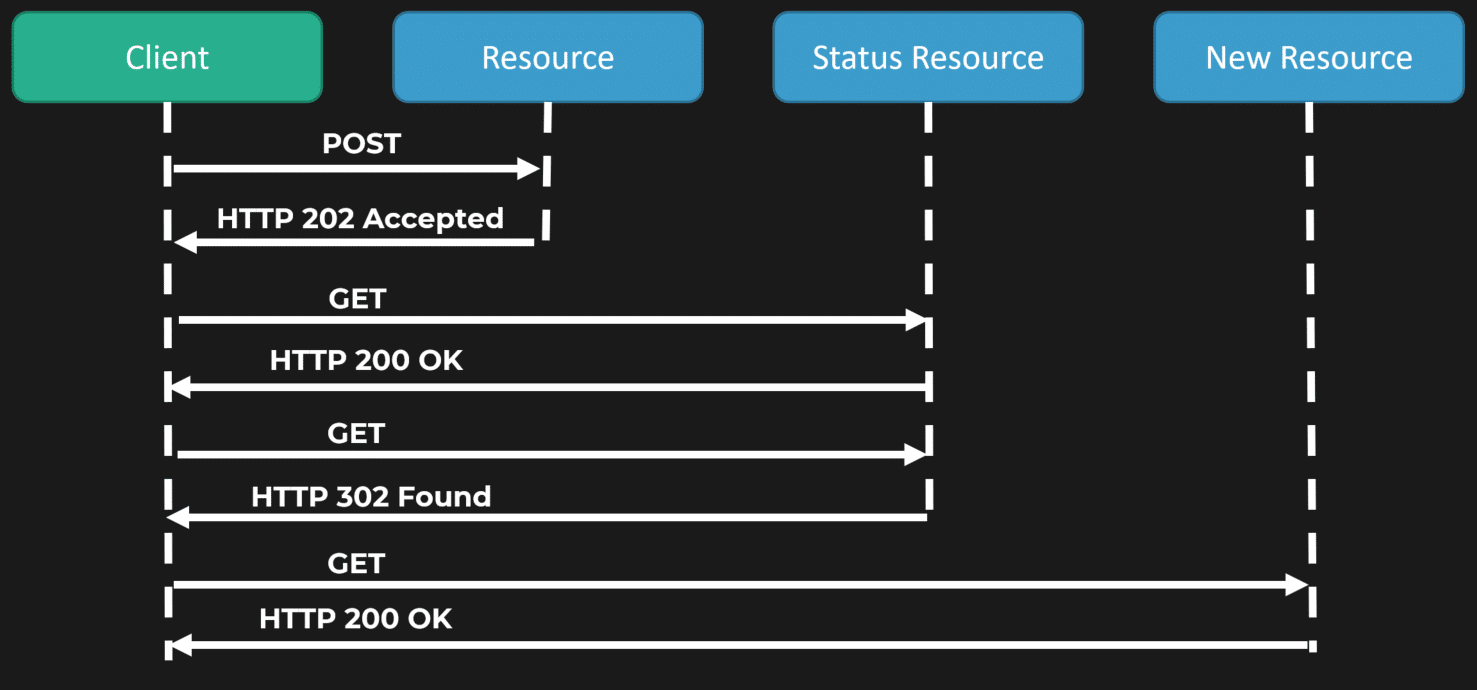
The diagram above illustrates that we first return the client a 202 Accepted with a location header to indicate they can poll another URI to get the status. If the processing of the work (transcript in our example) isn’t complete, we return a 200 OK. At this point, the client will poll the status URI again after some interval, and if the processing is complete, we can return an HTTP 302 found with a location header to the URI of the generated transcript.
This is a very common pattern. However, you might think it seems archaic that the client has to do polling.
There are other options, which I’ll talk about coming up, but not all clients will be able to handle them, so polling is a valid solution.
Push
Another solution is to use more real-time server push to the client. An example of this is WebSockets. This means your client can have a persistent WebSockets connection where the server can push a notification to it, to tell it when the processing is completed, rather than polling.
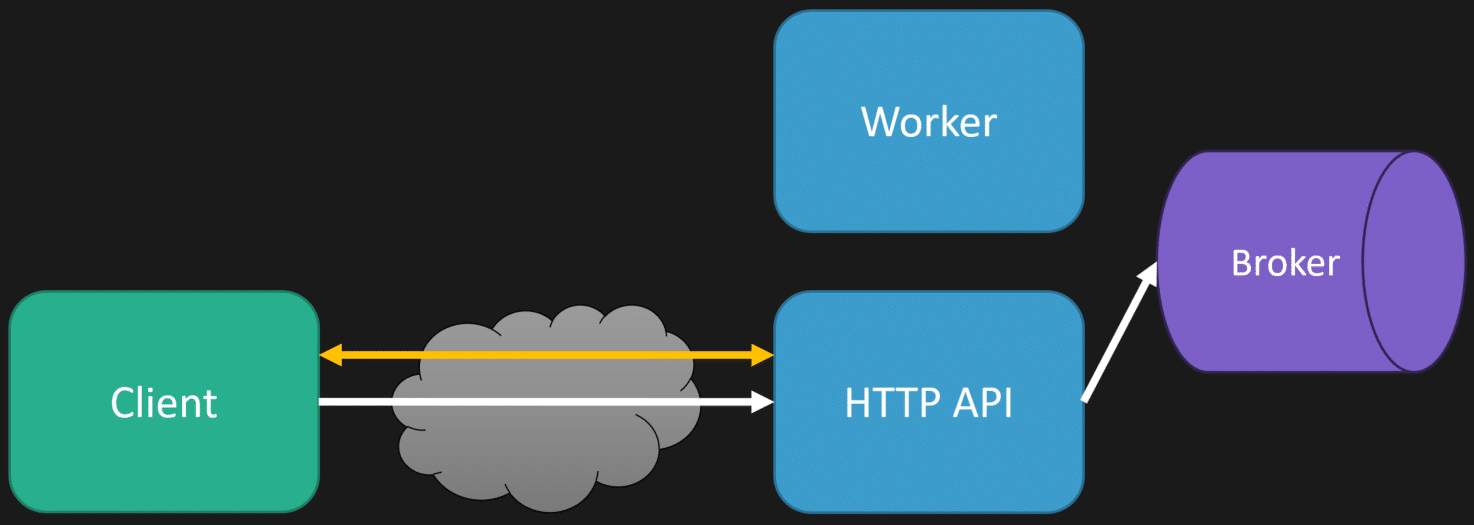
The initial HTTP is still the same, where the HTTP API immediately puts a message on the queue and returns it to the client; however, we also have a separate WebSockets connection.
Once the worker (thread/process) processes the message from the queue and has generated the transcript, it can then communicate back with the HTTP API to push down a message from the WebSockets connection to the client to notify it that processing is complete by providing it the URI where the transcript can be retrieved or even passing it the transcript.
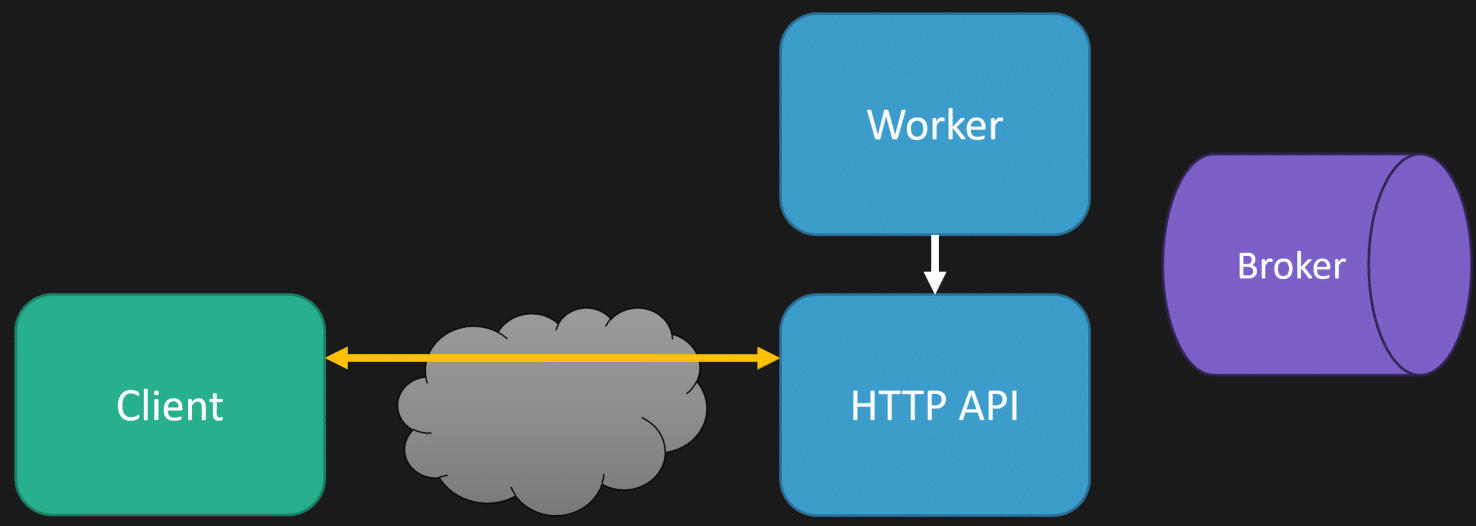
If you’re in the dotnet space and using something like SignalR, the worker doesn’t communicate directly with the HTTP API. Rather, it uses a backplane such as Redis.
Other options for pushing the client are using Server Events or WebHooks as callbacks to the client. Check out my post Building a Webhooks System with Event Driven Architecture
Long-running HTTP API Requests
How do you handle long-running HTTP requests that take a long time to complete? Generally, you want to return quickly from an HTTP API to the client. As mentioned, long-running HTTP requests have implications, such as timeouts, increased load on HTTP servers/infrastructures, retries, and idempotency.
That’s not to say moving to async processing is a silver bullet. As you can see, there are many trade-offs and more moving parts. If you already have the queue infrastructure and a means to communicate back to clients via WebSockets, Server-Sent Events, WebHooks, etc., moving work asynchronously for long-running processes or workflows is a good option.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.