Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
How do you build resilient architecture and systems? I will give you five tips on things you can look at and implement to keep your systems functioning correctly and consistently.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Fallbacks
You want to consider having a fallback for any external services you use. For example, this could be a payment gateway or something as simple as a URL shortener. Why? If you depend on these external services and they become unavailable, this can negatively affect the availability of your app/service, especially if it is critical to you.
If you want your app/service to be resilient, you can’t assume or expect 3rd party services to always be available. You’ll want to have a fallback in place to achieve the same outcomes. For example, if you depended on URL Shortener, then you’d have to define some abstraction to use your primary and fallback to the secondary if needed.
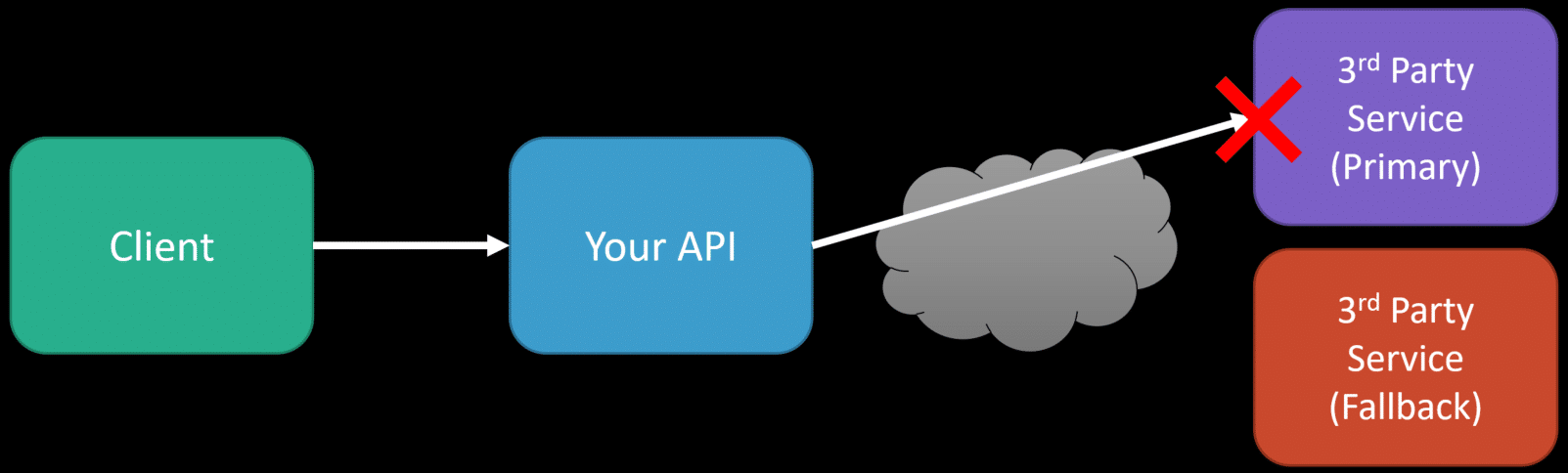
Don’t assume a 3rd party service will always be available. A fallback for even transient errors will make your app/service resilient.
This also plays into the circuit breaker pattern, another resilient architecture pattern in which if the primary is unavailable, you might use the circuit breaker to send all subsequent requests to the fallback for some time. After that period has exceeded, you try the primary again.
Timeouts
Very related to fallbacks is having a timeout for any network call. Usually, it’s a fairly quick timeout (relative to the normal latency of the service). In the example of communicating with a 3rd party service, let’s say over HTTP if an average request takes 500ms. Then, all of a sudden, the third-party service has degraded performance and suddenly starts taking 30 seconds; how will that affect your app/service? You’ll have degraded performance now.
Adding timeouts to network calls allows you to be resilient to use your fallback, not just when a service is unavailable but also when its latency is higher than you expect or can tolerate.
Queues
Moving work to be done asynchronously can have a significant impact on the resilience of your system. It gives you many options on how you want to handle failures.
When you have a request from a client, and that work doesn’t need to be done to provide them with a response, you can move that work to be done asynchronously. There are a lot of use cases that you may not realize exist in your systems that fit great for being asynchronous. To give a simple generic example is processing a payment when an order is placed. If you had an e-commerce system, when an order was placed, you needed to process their credit card. This doesn’t need to happen within the same process as saving the order to your database. This could be handled asynchronously after the fact, even by another process.
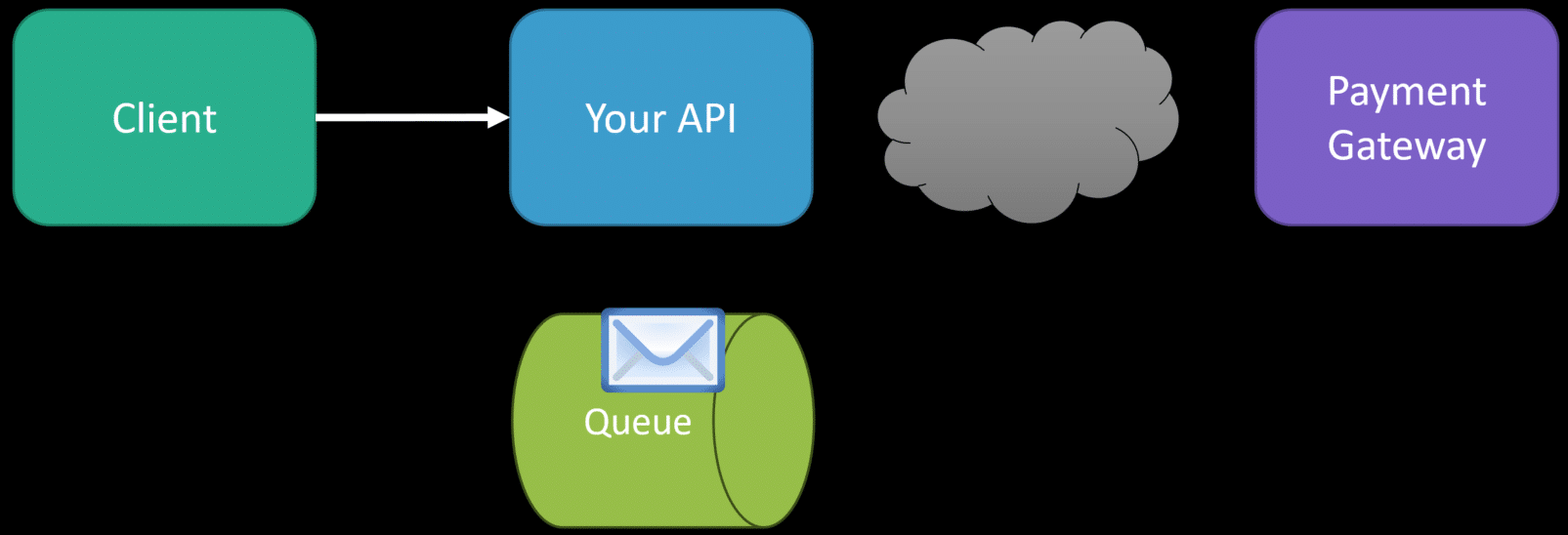
Once a message is placed on the queue, you could have the same instance or another instance entirely consume that message off the queue and then attempt to process the credit card by making a request to the payment gateway. Why is this a better strategy than having it when the order is saved to the database? What happens if you save the order to the database but the payment gateway is unavailable? Let’s say you don’t have a fallback in this situation.
Queues are perfect because you don’t lose the intent of what work needs to be done. That message, if not processed successfully, doesn’t just magically disappear. Many different strategies are built around queues, such as retries, exponential backoffs, and dead letter queues. This means that if the payment gateway isn’t available, we can move the message to a dead letter queue, representing messages that failed and were not processed correctly.
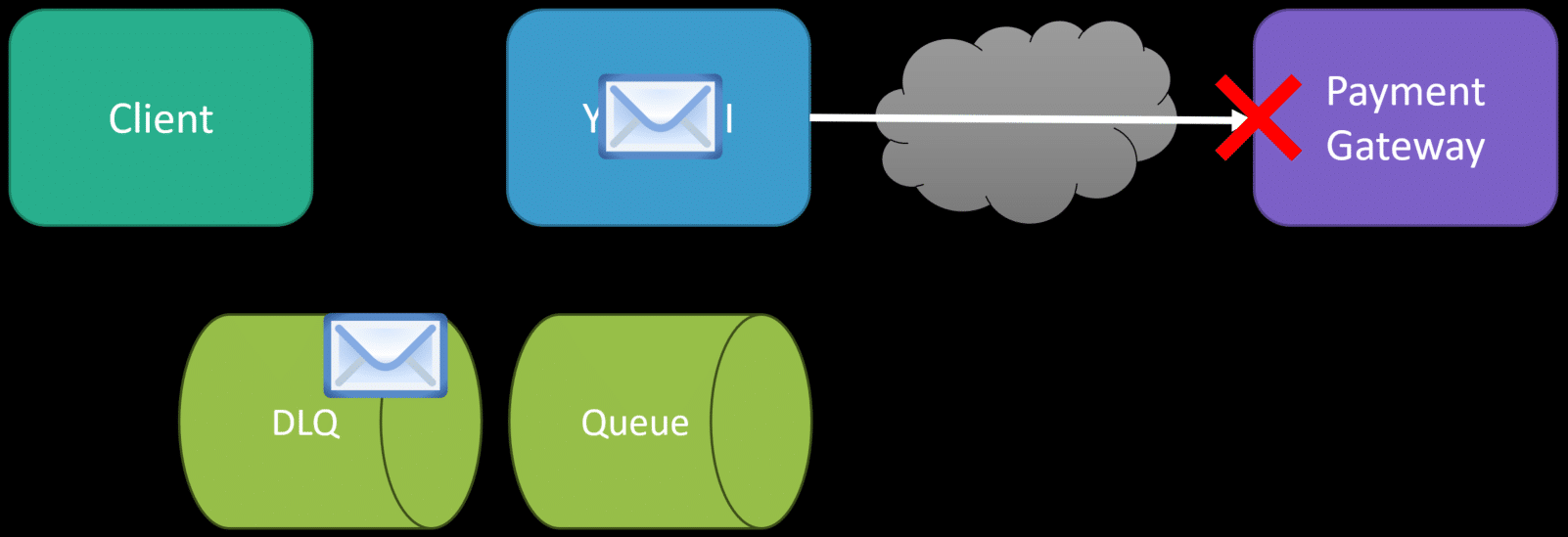
Once in the DLQ, we can manually try to re-process those messages. Another use case is for handling an influx of volume. Your system might be able to handle processing, but your payment gateway might not and might throttle you. In this case, your queue is a great way not to lose any work to be done. This segways nicely into Capacity.
Capacity
Understanding your system’s capacity limits and how you can scale. If you’re using a queue, you’ll have a limit on the number of messages you can consume and process. Over time, if you start producing more messages than you can consume, you’ll have a backlog in your queue and never catch up.
The answer is scaling out, adding more consumers, and using the competing consumers pattern. Add more consumer processes that will all consume messages from the queue. This enables us to process more message concurrency and increase our throughput.
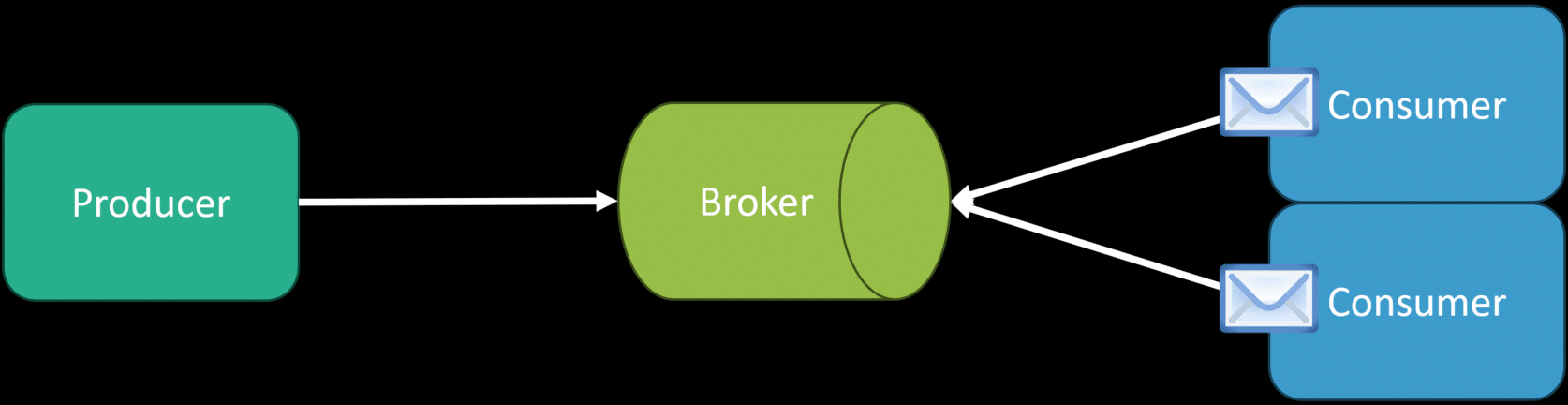
However, we must also be aware that you might move the bottleneck. Often, when processing messages, you might use other downstream services.
In my example earlier, I mentioned a payment gateway. Its capacity can be different than your own. In that case, as mentioned, you may want to limit the number of messages you’re processing concurrently or in a sliding window based on its capacity.
Another example is your own database. If the messages you process interact with your database, you might not just be able to scale out your consumers as you might move the bottleneck and overload your database.

Moving work asynchronous is great, but you must understand capacity at various points throughout your system, including the external systems you use. Using various load leveling techniques with queues and different priorities of queues is a great way not to overwhelm any downstream services.
But it’s not just queues; it’s any part of your system. How many requests can your HTTP API handle, and how many database calls? All these are variable on the workload being performed and at what volume. Not all work is created equal.
So, how do you know what your capacity is? I’m glad you asked.
Monitoring
A resilient architecture means you need great metrics about how your system runs during normal options and being able to alarm those metrics when things start going off-side. In other words, you want to be proactive to keep your system running without any disruption. You want to be notified when there isn’t a problem yet so you can adjust your system before something goes wrong.
As the example with queues, you would want to know your inflow and outflow rates. In other words, how many messages are you producing per second, and how many messages are you consuming and fully processing per second?
You’ll have peaks and valleys, but in a sliding window of time, you’ll have an upper bound of the number of messages you can process. Having metrics around queue depth in a window of time is a great metric to alarm on so you can get ahead of any backlogs.
Are you making HTTP calls to third-party services? How long do those normally take? Start getting metrics around those calls to alarm when they exceed your threshold.
Building a resilient architecture is about being proactive and giving yourself options on how to handle failures and scale your system when needed. Hopefully, these 5 tips give you some ideas on where you can start looking at your system to make it more resilient.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.