Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
When you need to scale your API, one of the first things developers often think about is, “Let’s just add a cache.” If API Caching were that simple. Adding caching introduces a whole new set of problems that you need to consider carefully to be successful with your caching strategy. In this article, I want to walk you through some key points and trade-offs based on my experience, so you can make informed decisions about caching in your APIs.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
What Are You Caching?
One of the very first questions you need to ask yourself is: what exactly are you caching? Are you caching a one-to-one mapping of your database records into the cache? Or are you caching some type of composed data that you’ve built by combining multiple queries or aggregations?
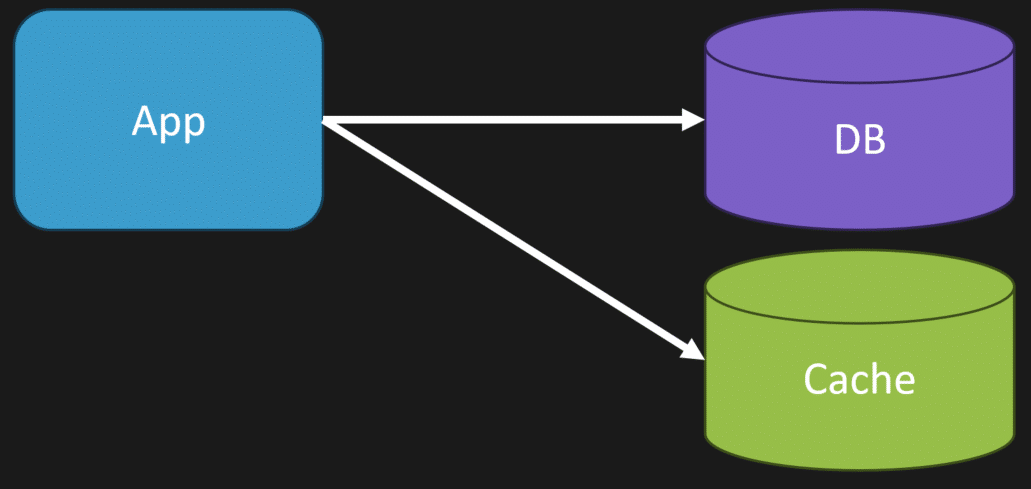
Let me explain what I mean by that. Imagine you have a book record in your database. This record contains fields like ISBN, title, author ID, published date, and the number of pages. If your cache is just storing the exact same data in a one-to-one relationship with your database record, you might wonder if you really need a cache at all.
On the other hand, maybe you’re doing something more complex. Instead of just caching the author ID, you might be caching the full author information. Or you might be including aggregated data such as the total number of reviews, average rating, or price. This kind of data composition is often the real reason why caching is beneficial because it reduces the number of queries and the amount of processing your API has to do on every request.
Understanding what you’re caching matters because it helps guide your caching strategy and infrastructure choices. If you’re simply caching one-to-one database records, you might be better off using read replicas if your database supports them, rather than adding a separate caching layer like Redis or Memcached.
Where Is the Cache?
Another common misconception is that all caching needs to be distributed. People often assume that caching means you must have a central cache store like Redis or Memcached. That’s not always true.

Depending on what you’re caching, a local in-memory cache in your API application can be sufficient. Even in horizontally scaled environments with multiple instances behind a load balancer, each instance can maintain its own local cache. This approach depends heavily on your context and the amount of data you’re caching.
For example, if you’re caching data that’s frequently accessed and changes infrequently, a local in-memory cache might reduce latency and complexity. But if your data is highly dynamic and needs to be consistent across many instances, a distributed cache like Redis can be more appropriate.
Using Your Existing Infrastructure as Cache
Let me take this idea a bit further. If you’re doing data composition that aggregates multiple queries into a single response, you might not need a traditional caching system at all. Instead, you can consider using your existing database infrastructure to store these precomputed results.
For instance, you can create a separate schema, table, or document store within your primary database to persist these composed read models. This approach means you’re not jumping to additional infrastructure just to cache data; you’re optimizing your existing storage to serve your queries more efficiently.
Read Models and CQRS
This concept aligns with the idea of read models and the Command Query Responsibility Segregation (CQRS) pattern. If you’re using event sourcing, your events represent state changes. You can build a projection or read model that’s optimized for your queries by precomputing the data you need.
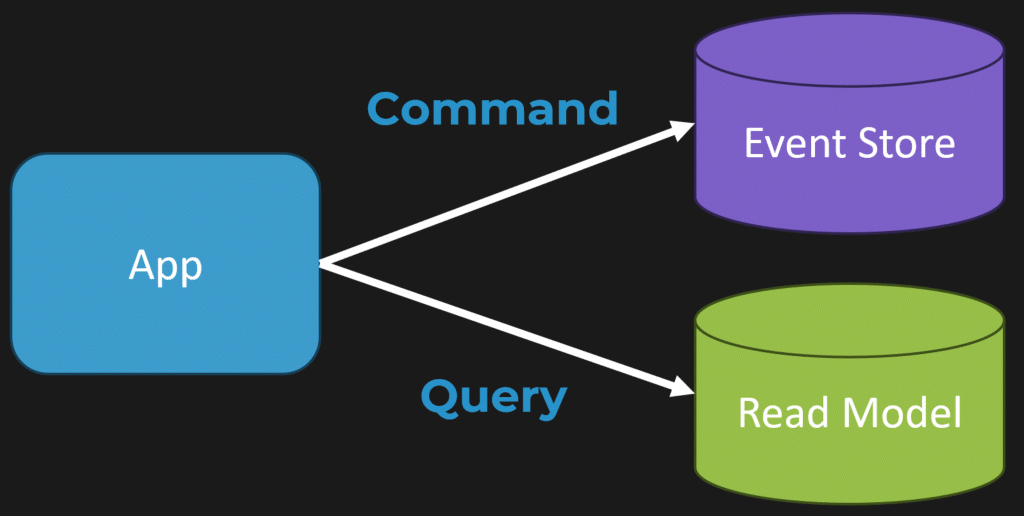
Even if you’re not doing event sourcing, you can apply a similar principle. Instead of querying normalized third normal form tables that require multiple joins and complex queries, you can maintain denormalized tables that answer your queries directly. This reduces CPU-intensive operations and improves performance.

So, when you think about caching, consider whether what you really need is a read model optimized for your queries rather than a traditional cache.
Strategies for Using Your Cache
Once you know what you’re caching and where, the next question is how to use your cache effectively. There are a couple of common patterns to consider: write-through caching and cache-aside (lazy loading).
Write-Through Caching
Write-through caching means that when you make a change to your database, you immediately update your cache as part of the same request. This requires your application to be aware of the cache and manage it alongside the database state.
The benefit here is consistency. Your cache is always up-to-date with your database, especially if you can do this within the same transaction or request scope. Other requests will see the updated data immediately.
However, there are trade-offs. Your write operations will take longer because you’re doing twice the work—updating both the database and the cache. You also have to handle failures carefully. If you update the database but fail to update the cache, you’ll introduce inconsistencies.
Cache-Aside (Lazy Loading)
Cache-aside, or lazy loading, works differently. When a request comes in, you first check the cache. If the data is there (a cache hit), you return it immediately.
If the data is not in the cache (a cache miss), you query the database, do any necessary data composition, then write the result back to the cache for future requests. This way, your cache only contains data that has been requested at least once.
The advantage of cache-aside is that your cache contains less data overall, only what’s needed. But the downside is more round trips for the initial request: check cache, miss, query database, update cache, return result. This adds latency and complexity.
Additionally, you need to be careful about scenarios where your cache is unavailable or data never gets written back to the cache. In those cases, your database can end up with more load than you anticipated, as every request falls back to the database.
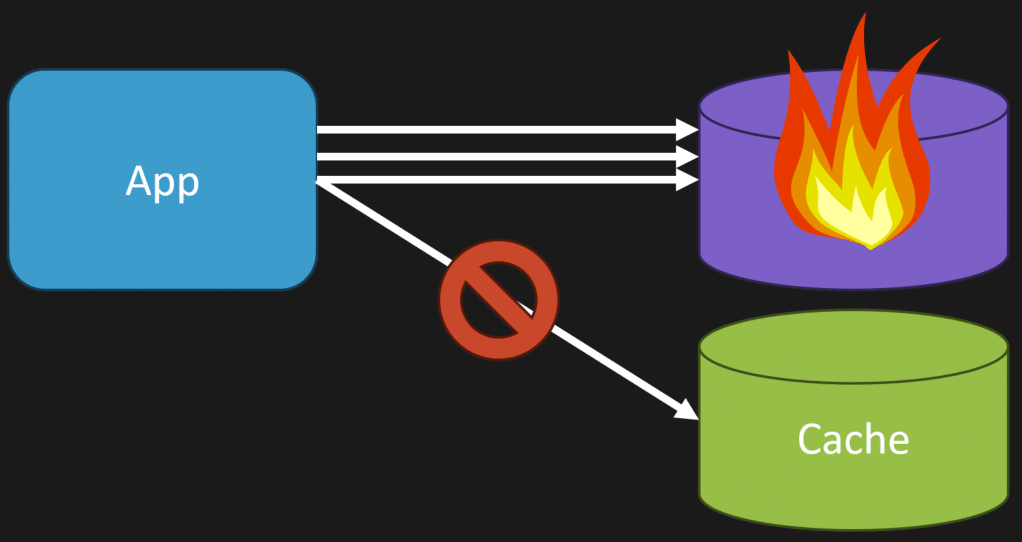
Combining Patterns
You can combine write-through and cache-aside strategies. For example, you might update the cache immediately on writes but still use lazy loading for cache expiration scenarios. This hybrid approach can help you balance consistency and performance.
Cache Invalidation
Cache invalidation is one of the hardest problems in caching. How do you keep your cache in sync with your database, especially when data changes outside of your API’s control?
Expiry (Time to Live)
The simplest approach is to add a time-to-live (TTL) or expiry to your cached items. After a certain period, the cache automatically removes the data, forcing the next request to refresh it from the database.
I highly recommend having some kind of expiry, but the length depends on your data volatility and business context. Expiry helps reduce stale data but doesn’t eliminate it entirely.
Why Expiry Still Matters with Write-Through
You might wonder, “If I’m updating the cache immediately on every write, why do I still need expiry?” The answer is that your cache might get out of sync if changes happen outside of your application.
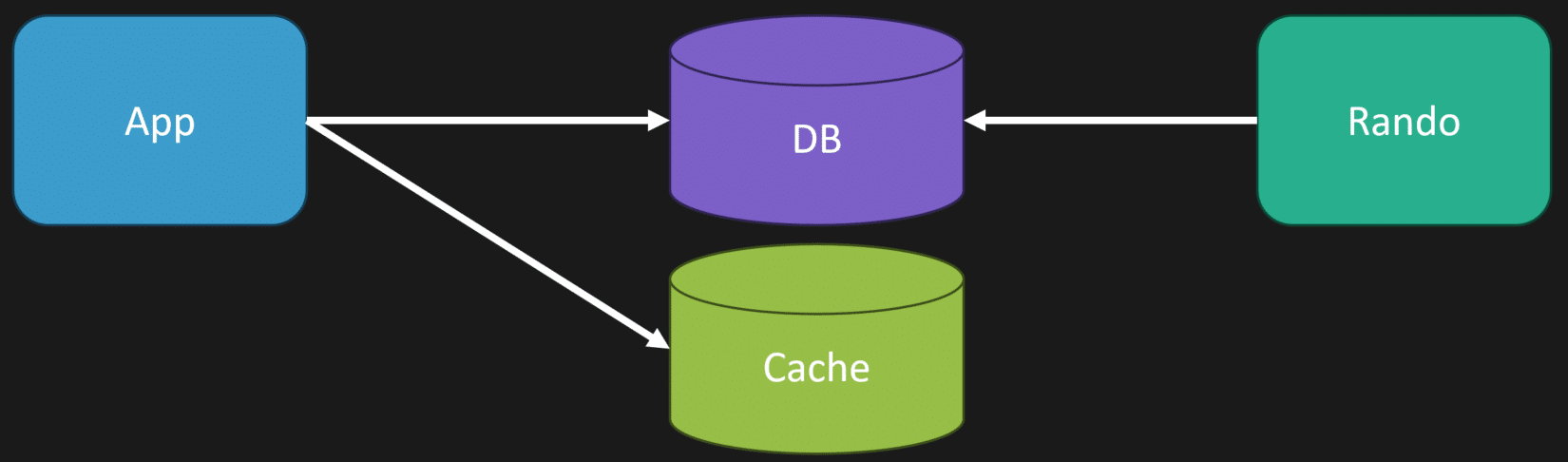
For example, if someone manually updates the database or another service changes data, your cache won’t be updated automatically. Expiry helps mitigate this issue by eventually clearing stale data and forcing a refresh.
Event-Driven Cache Invalidation
If you’re using an event-driven architecture, you can leverage events to keep your cache in sync asynchronously.
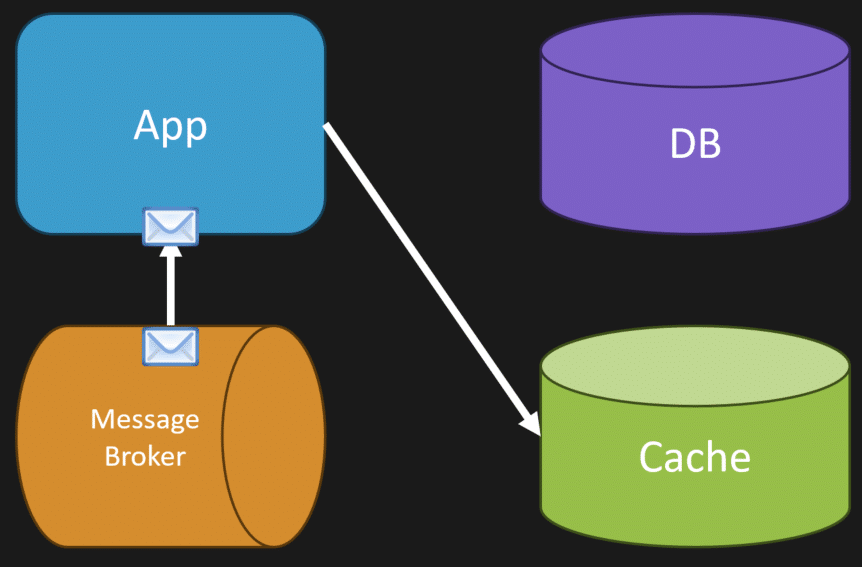
For example, going back to our book example, when someone adds a review to a book, you can publish an event like “BookReviewed.” An event consumer can listen for this event and update or invalidate the cache entry for that book’s review count or rating.
This approach decouples cache invalidation from the main API request and can scale well, but it requires building and maintaining an event infrastructure.
Final Thoughts on Scaling Your API with Caching
Scaling your API by adding caching is not a silver bullet, and it’s not as simple as just “adding a cache.” API caching has many factors and trade-offs to consider, including what data you cache, where you cache it, how you keep it consistent, and how you invalidate it.
My advice is to cache only when you absolutely must. If your database is overloaded, first look at optimizing your queries and database design. Often, reducing complexity and improving database performance will give you more benefit than adding caching layers.
Also, think carefully about your context and use the right tool for the job. Sometimes a local in-memory cache is enough. Other times, a distributed cache or read model in your existing database infrastructure makes more sense.
And remember, caching introduces complexity. You’ll have to handle cache misses, invalidation, stale data, and error scenarios, so be prepared for that.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.