Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
You wanted your system to be resilient, so you followed the standard advice.
You added retries.
You added circuit breakers.
You added fallbacks.
But now your system is less resilient.
Not because those patterns are bad. They are not. The problem is they are doing exactly what you told them to do.
YouTube
Check out my YouTube channel, where I post all kinds of content on Software Architecture & Design, including this video showing everything in this post.
Retries are great for network blips and transient issues. But the tradeoff is that you are adding more load to a system that might already be struggling.
Circuit breakers are great because you do not have to keep hammering something that is already down. But in a distributed system, everything might be sitting in its own silo on each instance.
Same thing goes for fallbacks. They can provide a better experience because you fall back to something that you know is reliable. But they can also hide the underlying issues that are occurring.
All of these patterns are useful. So are the libraries that implement them. But you do not get resilience just by applying them or using some library. It does not work that way.
In the wrong context, you can actually make things worse.
The question is not, “Can I apply this pattern?” or even, “Should I apply this pattern?”
The question is, “What is the failure mode?”
The Example
Here is the example I am going to use.

We have some type of message broker queue interacting with a worker. That worker ends up making an HTTP call to some third party API.
But this has nothing to do with queues specifically. It has nothing to do with HTTP APIs or brokers specifically. It is just an example to illustrate that one pattern for resilience can work great in one context and be a total disaster in another.
Imagine a worker consuming a message from a queue. The message is something like ShipOrder.
The worker needs to make an HTTP call to a shipments route or some third party service. Maybe it is UPS, FedEx, some carrier, whatever the case may be. You need to create the shipping label in their system and get the response back.
Once you know that is good, maybe you do some internal state change in your own database, marking the shipment label as created.
That is the happy path.
Consume a message.
Call a third party API.
Update some internal state.
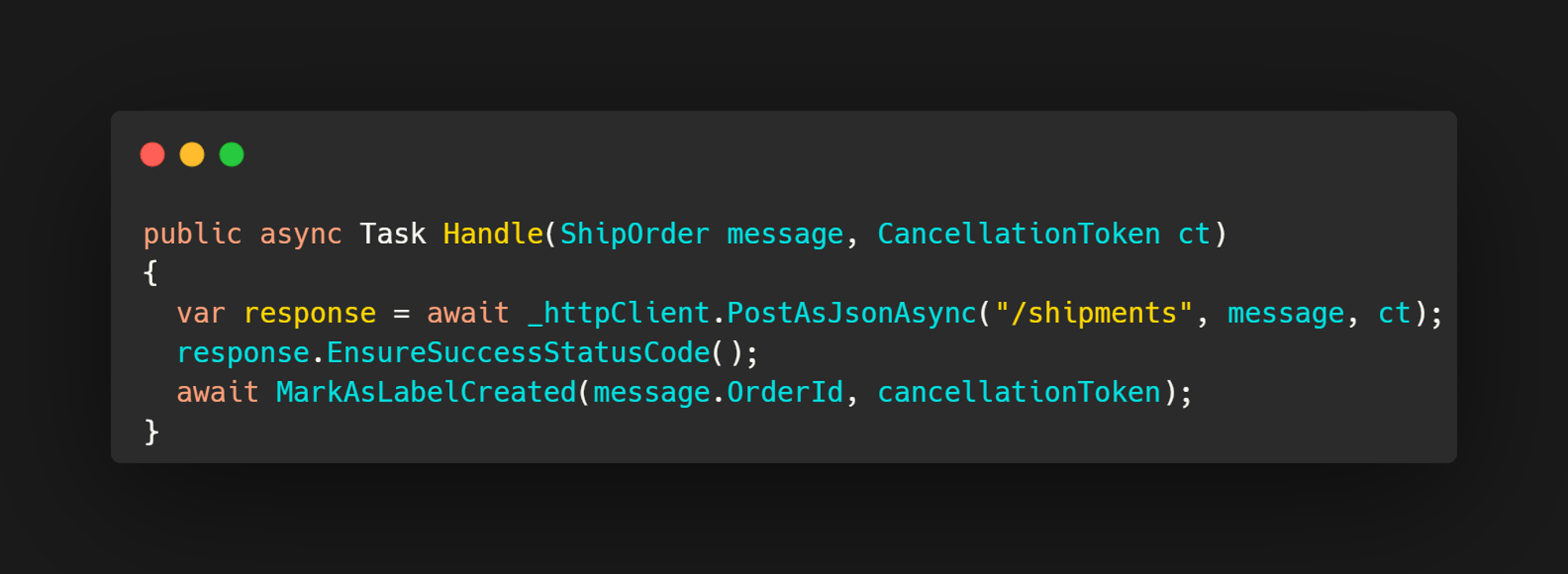
That code would be incredibly simple on purpose, because it does not show what really matters.
What really matters is understanding things operationally.
How many messages are you processing? What is your throughput? Is everything in the same queue? How many worker instances do you have concurrently processing messages? What happens if that third party HTTP API is down? What happens if it is just really slow compared to what it normally is?
The code only illustrates the happy path. It does not illustrate what you want to deal with when failures occur or what is acceptable in your context.
Standard Advice Is Incomplete
If that HTTP API was a little flaky, the standard advice might be to just slap on a retry and a circuit breaker. Maybe even a fallback.
So you add a retry policy around the HTTP call. You add a circuit breaker. Good to go.
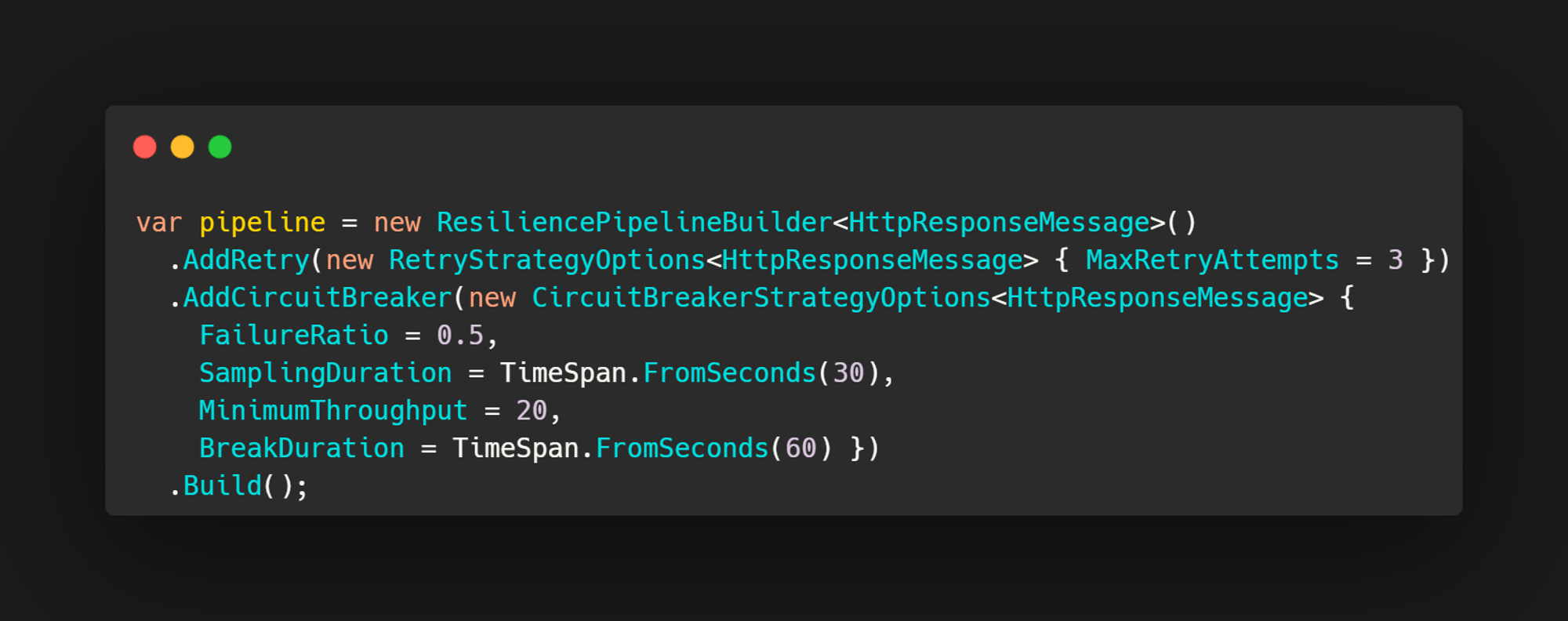
That is not necessarily bad advice. It is just incomplete.
And it can have consequences that affect your overall system negatively. Not more resilient. Less resilient.
The resilience patterns or policies you build up in code can only happen after you understand the failure mode and all the different parts of your system that are affected when a failure happens.
But “failure” is not really one thing. I am not even sure it is a good name for it.
Something could be down. Straight up down. It is not responsive. Something could be slow or degraded. You could have intermittent issues that are transient, where one request works and one does not. A service could be overloaded because you are hammering it, or because other services are.
It could be a partial issue where you make a request, maybe it times out, but it actually is working on the other side. You are just not getting a response. Or you might have no idea what the heck is going on with it.
But all of that gets put under the label of “failure.”
That is the problem. Not every failure type deserves the same resilience pattern. One pattern can work for one type of failure and be a disaster for another.
Down Is Not The Same As Slow
Take the difference between something being straight up down versus something being really slow.
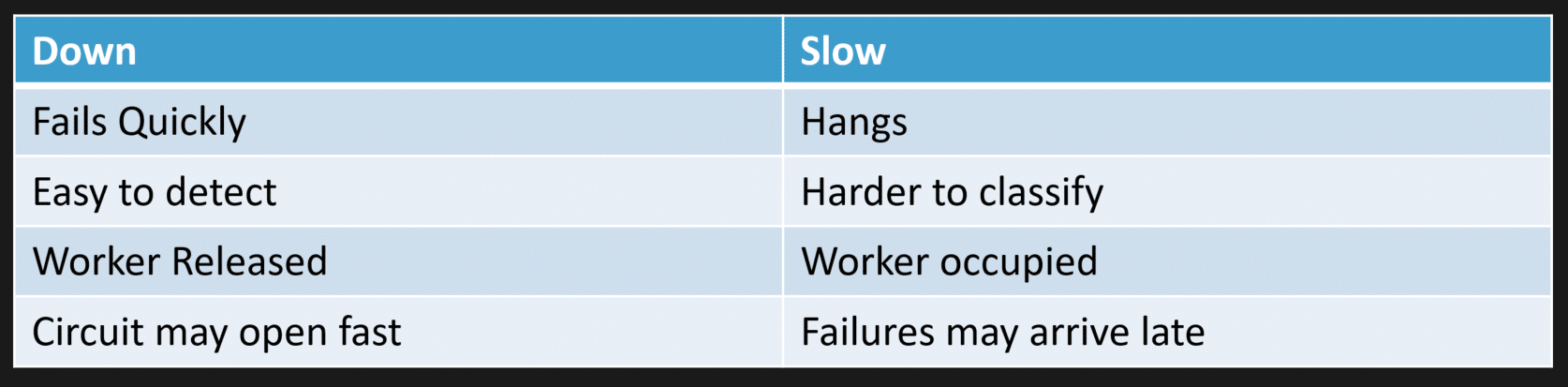
If something is down, it usually fails very quickly.
You try to make the HTTP call and you get a 503. Or connection refused. It happens immediately. It is easy to detect because it is happening right away.
In the case of our worker, the worker is released quickly, so it can start performing other work. Maybe it removes that message, throws it into a dead letter queue, however you have that configured, and then it can start processing another message.
If you are using a circuit breaker, it can open rather quickly.
But what if the call is not failing fast? What if it is just slow? What if it is slower than you expect on the happy path and it just hangs there?
That is much harder to classify. Is it degraded? Is it slow? Is it partial? You are not really sure yet.
And there is a big difference for our workers.
You are occupying them.
If something that normally takes milliseconds to process is now taking 10 seconds or 30 seconds, your worker is sitting there waiting. It is occupied. It cannot process other work.
Because of that delay, it may take you much longer to realize that failures are actually happening.
Retries Are Not Free
Now take the standard practice of adding retries.

Maybe you have a shared policy that you use for all HTTP calls to third party services. There is a little bit of backoff to it.
If there is a failure, maybe you wait 500 milliseconds and retry. If the failure continues, you wait 2 seconds. Then maybe 10 seconds. Then 30 seconds. Finally 100 seconds. After that, you give up.
But retries are not free.
If this was not a transient issue, not just a blip, that retry is ultimately costing every job more time to complete. That means every worker processing messages that needs to make that call is now taking longer.
And it can get worse. Because not all failures are the same.
What happens if the third party API is just really slow? You process the message. You call the API. It takes 30 seconds. Finally, it fails. Maybe you have a timeout. It returns some error.
Guess what you do now? You wait 500 milliseconds and try again.
How long is that going to take? Potentially another 30 seconds. And you keep going with this.
So something that you thought might take a couple of seconds because of retries can now take minutes, depending on how long it takes that third party API to time out.
Another way of putting this is that retry policies are not just about reliability. That is why you use them, but everything has tradeoffs. The tradeoff is that you are now consuming a resource.
In this example, that resource is your worker. You are consuming that worker for the length of time that you are applying the retry policy.
The Resource You Are Actually Consuming
With our retry policy, what resources are we affecting? How does it affect them? Is that something we can deal with?
Say we have four instances processing messages off our queue. We have retries configured, but the third party API is slow.
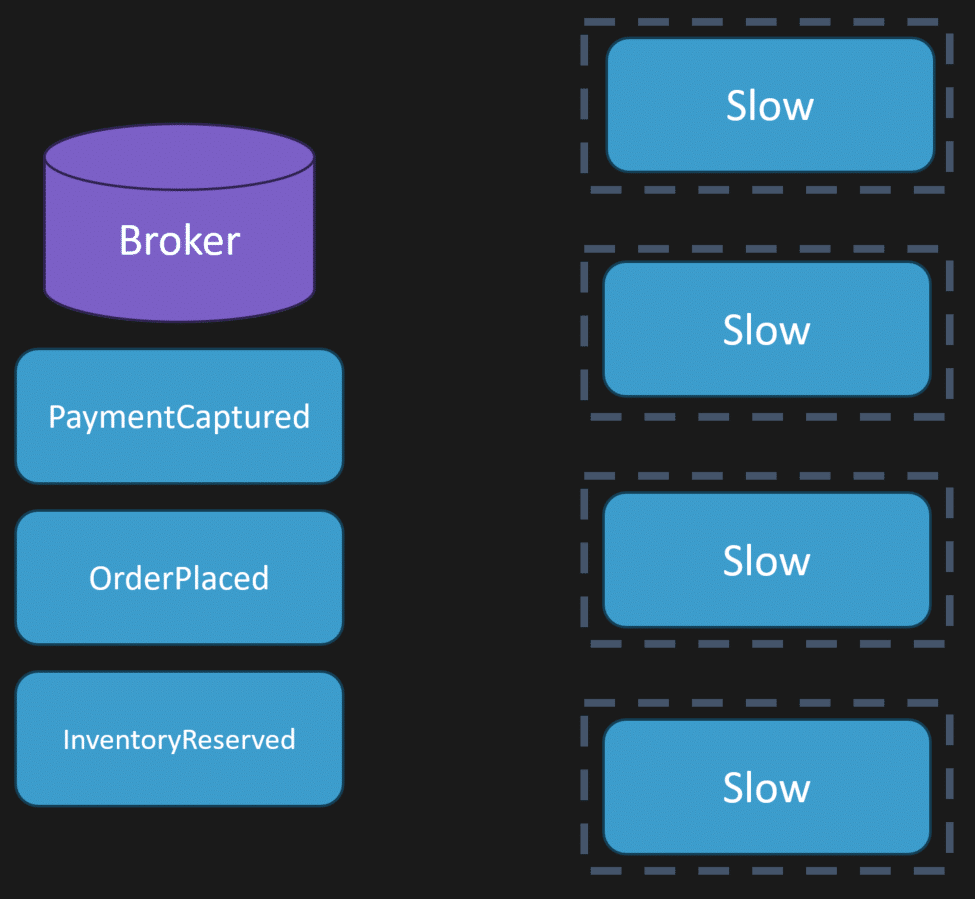
Each instance is now stuck sitting there for seconds or minutes, depending on the policy. Each one is processing a message that requires that HTTP API, but the call is not succeeding.
Now the broker is getting backlogged with queued messages because nothing can process anything else.
In that exact example, a lack of isolation is the problem.
If we have a shared pool of workers, maybe we do not want a shared pool. Maybe we want specific queues. Maybe our queue design should determine which workers are working on which queues.
Is retry the answer? It depends on the type of error. If it is transient, maybe you do want to retry. If it is timing out, maybe that is a different failure type and you do not want to retry.
Local Decisions In A Distributed System
What can be problematic is trying to make that distinction when you are also in a distributed environment.
Maybe you have multiple workers. Each one has its own local view of the world.
A great way of dealing with this is metrics. Publish metrics about the failure types so you can react to them accordingly across workers and build your policies around that.
You want to know what is happening. Say there is a temporary issue with the third party HTTP API and it is failing. You might not want everything to be localized to each instance.
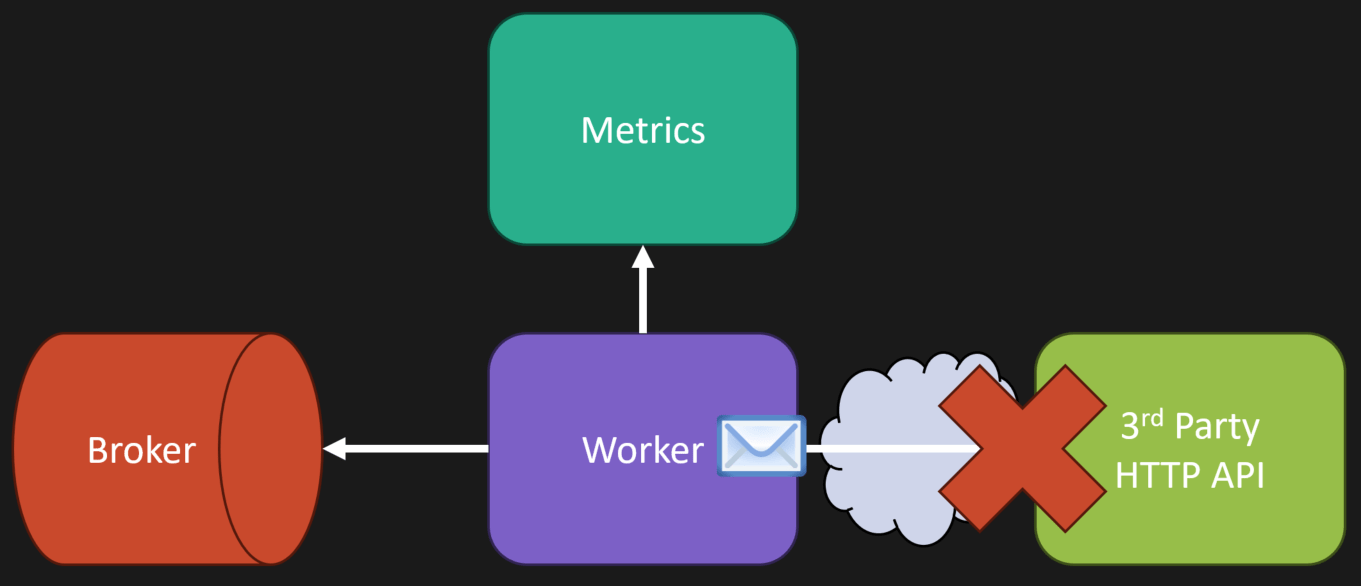
You can publish a metric that says, “Hey, this failed,” or “This timed out,” or whatever the case may be.
Then you can get those metrics pushed back to your workers, or your workers can look them up to decide what to do.
Should we continue calling?
Should we adjust our retry limits?
Should we stop calling that dependency entirely for now?
You can be very runtime specific about how you want to handle failures.
Because if you have four different workers and there is a timeout with that third party system, they all have to experience it enough times to hit their own circuit breaker.
But if you are recording metrics like failure rate, timeout rate, retry rate, and all of your instances have a global view, they can react faster.
They can decide, “I am not going to that third party service because it is timing out.”. That helps messages move through your system more predictably.
The tool does not matter. It could be CloudWatch. It could be Prometheus. That is not the point. The point is that you are signaling to your system that something is degraded and how you want to handle it across all instances.
What Should You Actually Do?
Whether something is local or systemwide is part of the process of figuring out what you should do.
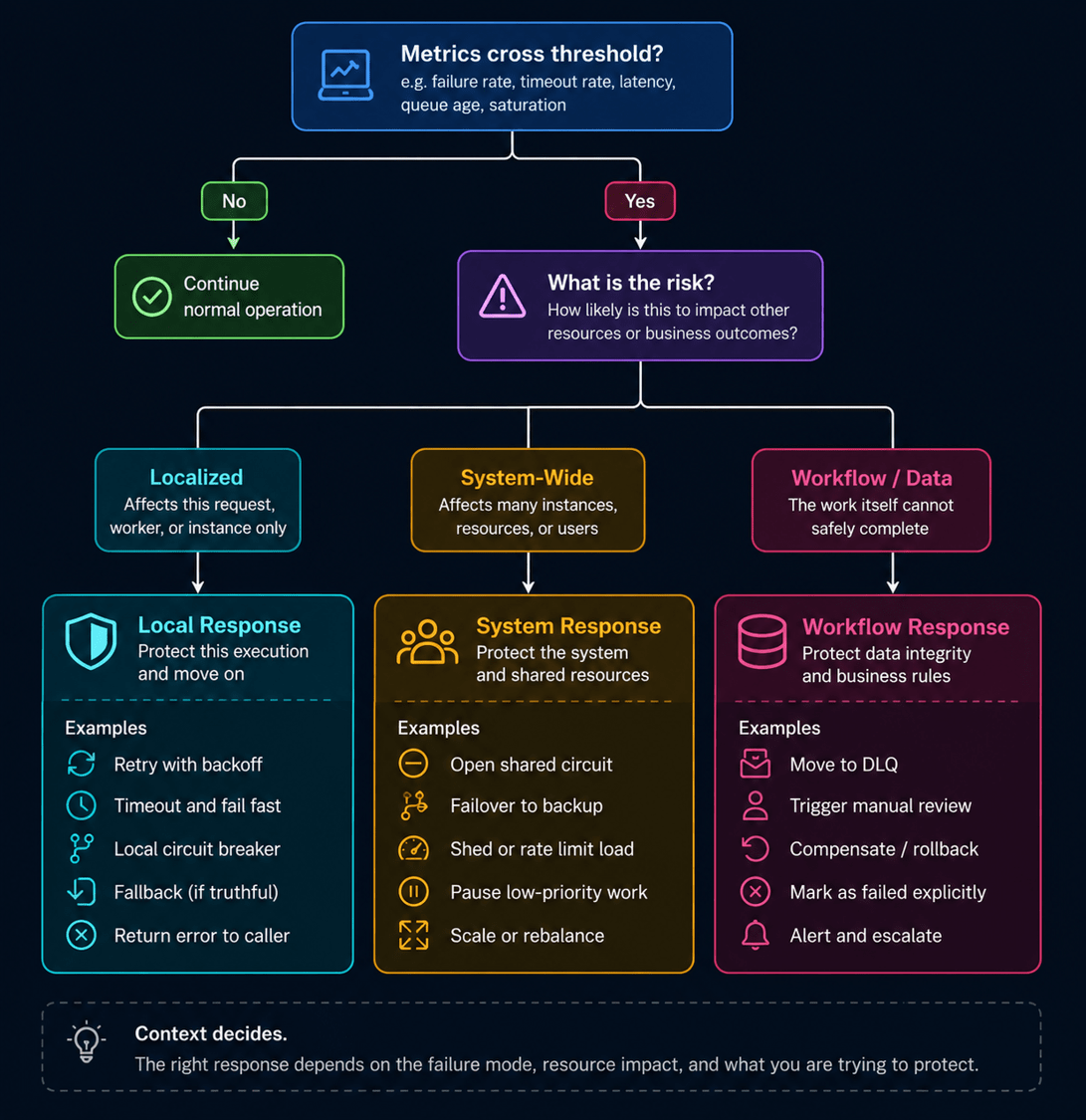
If there is a failure, did you reach some kind of failure rate? Timeout rate? Latency threshold?
What is the risk? What is the impact on other resources? There are always other resources involved that are going to be affected by it.
If it is localized, maybe you retry with backoff. Maybe you time out and fail fast. Maybe you develop your own timeout because the built in timeout for the HTTP client is not what you want. In C#, for example, the default HttpClient timeout is 100 seconds.
Do you really want to use that? Maybe you use a local circuit breaker that only applies to that particular instance.
If it is systemwide, maybe you want a shared circuit breaker based on metrics. Maybe you want a global fallback. Maybe you want to fail over to another service. Maybe you want to rate limit load or change how you scale things.
And if it is workflow or data related, what are the implications of something failing?
Do you need to move it to a dead letter queue?
Can you kick this off later?
Do you need to trigger something else?
Is there some kind of compensating action you need to perform? Some type of rollback, if you want to think of it that way?
Or do you mark the workflow as failed and say, “We are done. It is at this point. Somebody needs to look at it.”
Maybe that means an email. Maybe it means escalating through issue tracking. Maybe it means alerting someone.
How you decide which flow to go down depends on what resources are affected and whether this is localized to a particular queue worker or something systemwide.
The Patterns Are Still Useful
Retries are great for handling transient faults.
Circuit breakers stop repeated calls so you do not keep hammering the same service that is already failing. Timeouts bound waiting so you do not let something go on forever, like waiting 100 seconds for an HTTP call when that makes no sense in your workflow.
Fallbacks enable degraded behavior. It does not need to be perfect. It can just get you by so your system does not come to a crumbling halt.
But the question is not which resiliency library you should use. The question is not which patterns you should be applying. It has to start with the failure mode.
What is the failure type? And if you apply this pattern, what is the tradeoff? Because it is going to affect something. It is going to have an effect on other resources.
In the retry example, the retry policy affected the worker. It consumed more time. Because it was retrying, it could not process more messages.
There is always a tradeoff. There is always something that you are affecting.
You can still control the blast radius. Even if you apply a pattern that has a tradeoff, you can design around that tradeoff and localize the impact.
But you have to design around your context.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.