Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Over five years ago, back in 2020, I posted a series of blog posts and videos outlining what the Loosely Coupled Monolith is. I was recently tagged in a post saying they read those original posts and moved forward with the concept.
In this article/video, I want to share with you the core ideas behind the Loosely Coupled Monolith, focusing on three key points: cohesion, managing coupling, and the realization that your logical boundaries aren’t your physical boundaries. We’ll circle back to these points at the end, and I think they’ll really make you rethink the last decade or so of this microservices vs monolith debate.
YouTube
Check out my YouTube channel, where I post all kinds of content on Software Architecture & Design, including this video showing everything in this post.
Focusing on Cohesion
The first two points—focusing on cohesion and managing coupling—go hand in hand. If you’re working in a system or trying to build one that’s hard to change or easy to introduce bugs into, it’s likely because you have a high degree of coupling and low cohesion. That’s exactly what we want to avoid.

When breaking apart a big system, or better yet, not producing a big system in the first place, think about it like this: instead of building one big pile of poop, you want to build lots of little piles of poop.

The reality is, not everything in your system is going to be perfect. Some parts will be great, others not so much, but the goal is to break your system into logical boundaries.
What Is a Logical Boundary?
A logical boundary is simply a grouping of functionality or capabilities within your system. Not all parts of your system are created equal. Usually, you have a core part where your real value lies—those end-user capabilities that matter most—and then other essential parts that support that core.
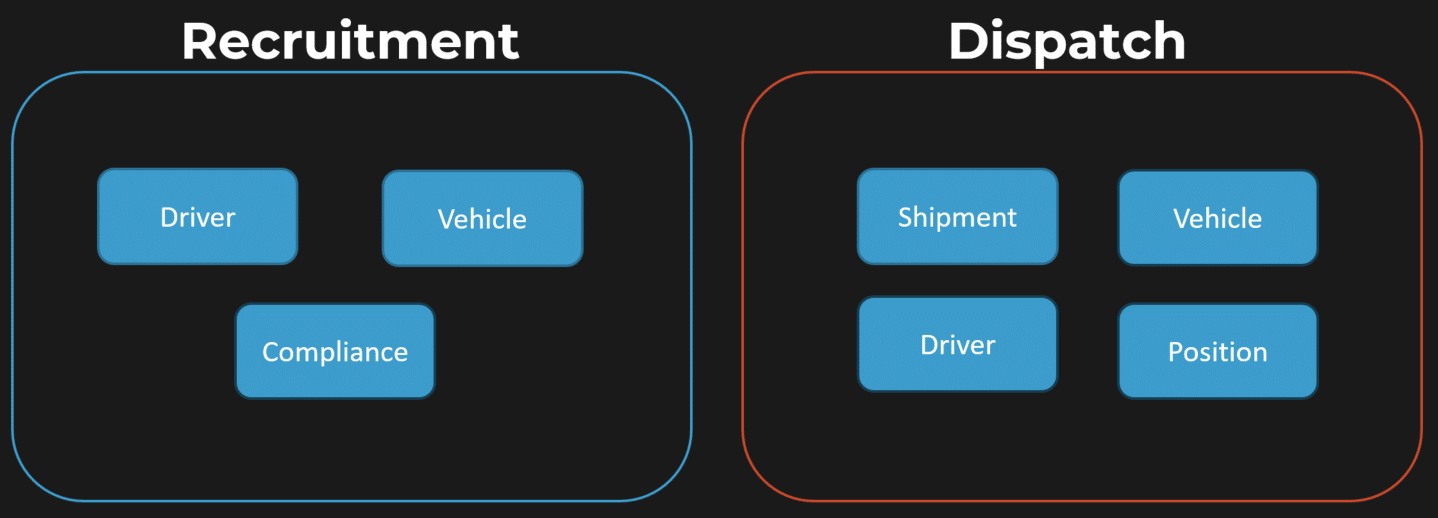
Let me give you an example from transportation in the illustration above:
- Recruitment boundary: This includes concepts like driver, vehicle compliance, and driver’s license.
- Dispatch boundary: This involves shipment, vehicle, driver, and position.
Now, a common mistake developers make is focusing too much on entities. For example, “vehicle” exists in both recruitment and dispatch, but it’s not the same vehicle concept. In recruitment, the vehicle is about compliance—insurance, registration, etc.—while in dispatch, the vehicle is tied to executing a shipment: arriving, loading, unloading, and so on.
This shows why a single model doesn’t rule them all. Instead, you want to focus on the capabilities of your system when defining logical boundaries. On the dispatch side, that means workflows like dispatching an order, tracking positions en route, and managing delivery. On recruitment, it’s about compliance and certifications. These are very different concerns, even if they share some entities by name.
Managing Coupling
Once you’ve defined your logical boundaries by grouping capabilities cohesively, they still need to interact. So, how do you manage coupling between those boundaries?
From a development perspective, you can think of a logical boundary as having three parts, which might be called projects, modules, or packages depending on your platform:
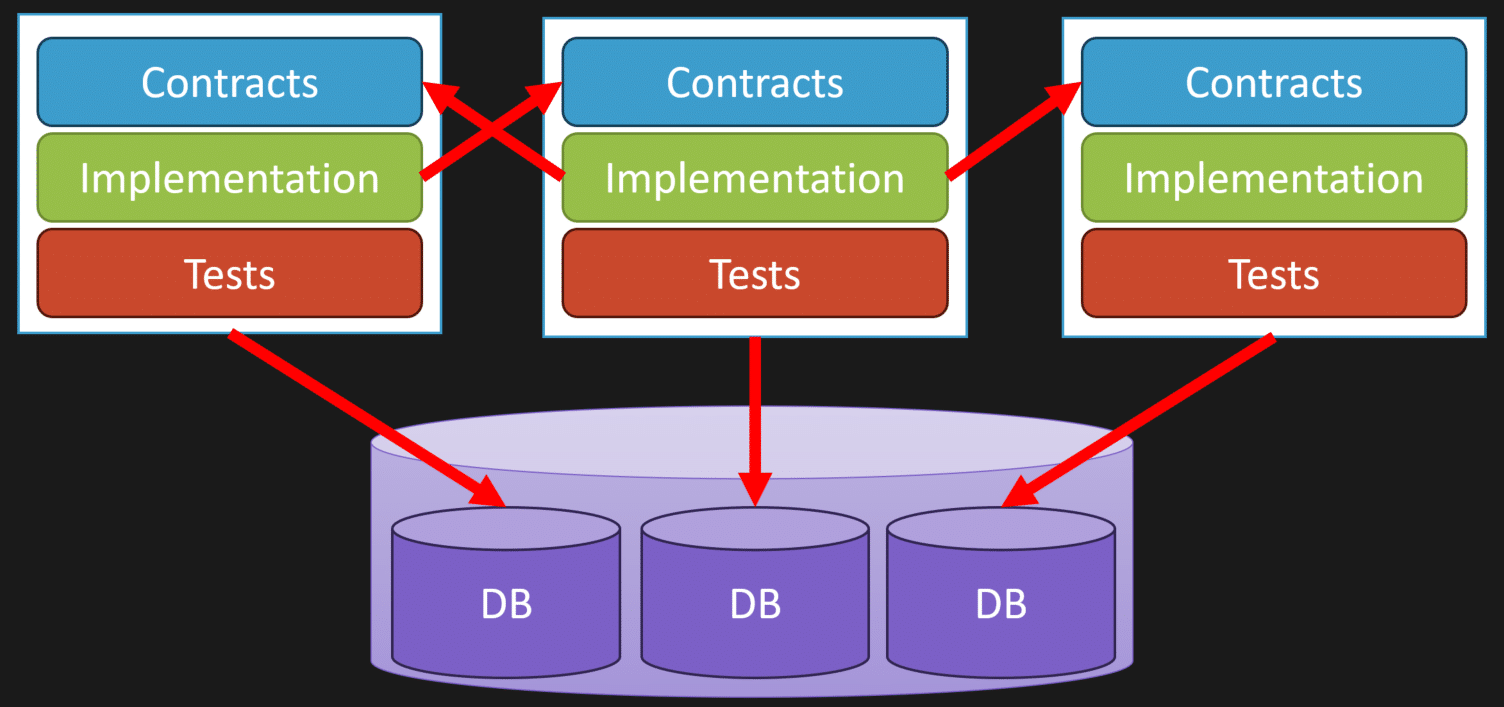
- Contracts: This is your public API—an interface, delegate, function definition, or schema defining messages. It’s the slowest form of coupling your platform supports.
- Implementation: The actual code that executes the logic behind those contracts.
- Data ownership: Each logical boundary owns its own data. This doesn’t mean each must have its own database instance, but it should have its own schema or tables it exclusively reads and writes.
To manage coupling, implementations should never reference other implementations directly. Instead, implementations reference contracts—the public APIs. This way, you avoid tight coupling to internal details and make boundaries more maintainable.
Also, boundaries should never directly access each other’s data stores. They must communicate through the public API (contracts), not by querying or updating another boundary’s database tables. This keeps coupling low and boundaries well encapsulated.
The Loosely Coupled Part
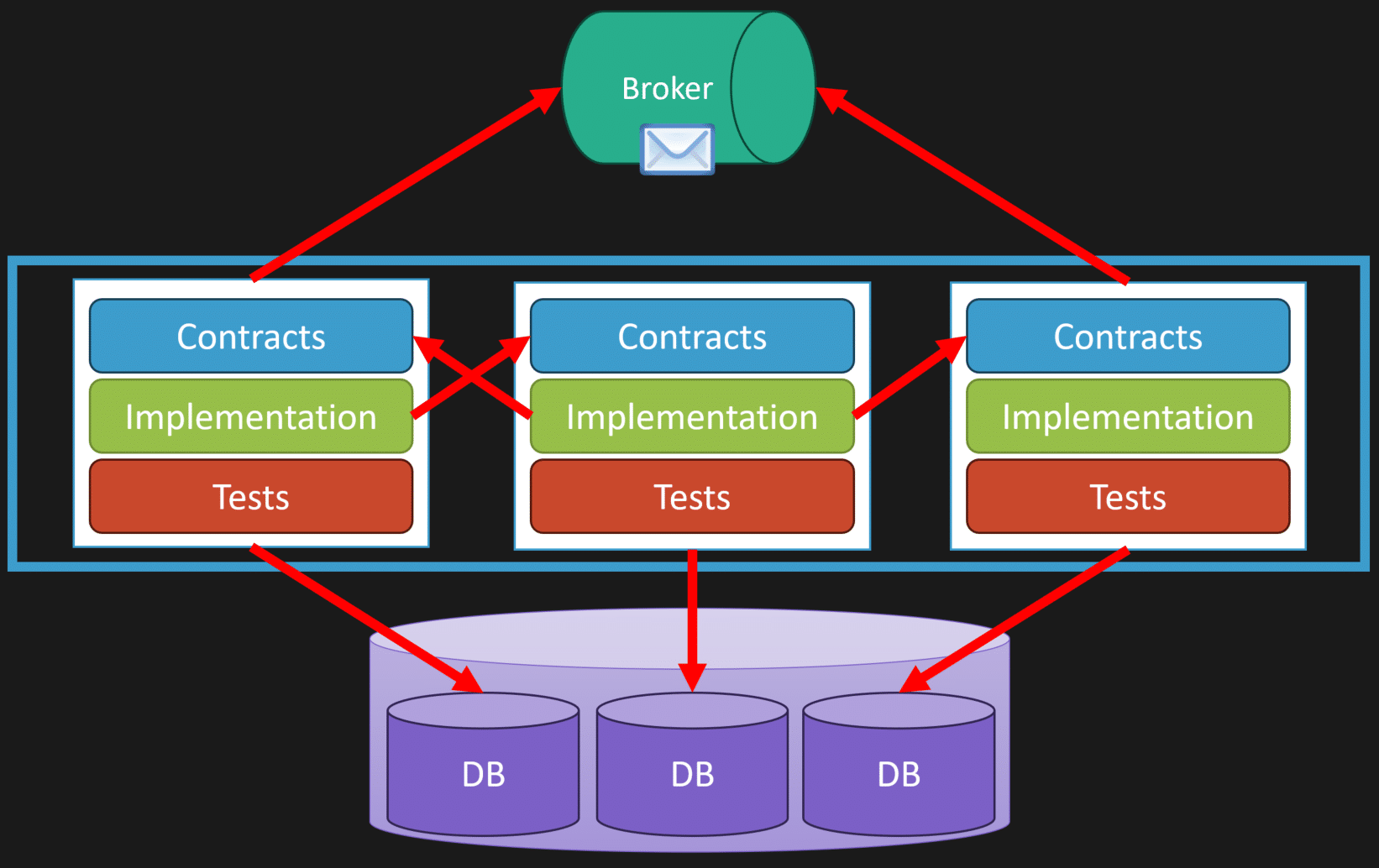
So where does the “loosely coupled” part come in? It’s through messaging. Messaging helps remove the temporal aspect of coupling. Two logical boundaries can be coupled because they need to communicate, but they don’t have to execute at the same time.
For example, you can have a message broker where one boundary publishes an event, and other boundaries consume it asynchronously. This could be a message queue, event bus, or even database-driven messaging depending on your use case.
Using messaging means you’re not tightly coupling implementations at runtime. Instead, you’re coupling schemas (message contracts) and asynchronously processing events. All of this can happen inside the same monolith code base.
Scaling and Deployment
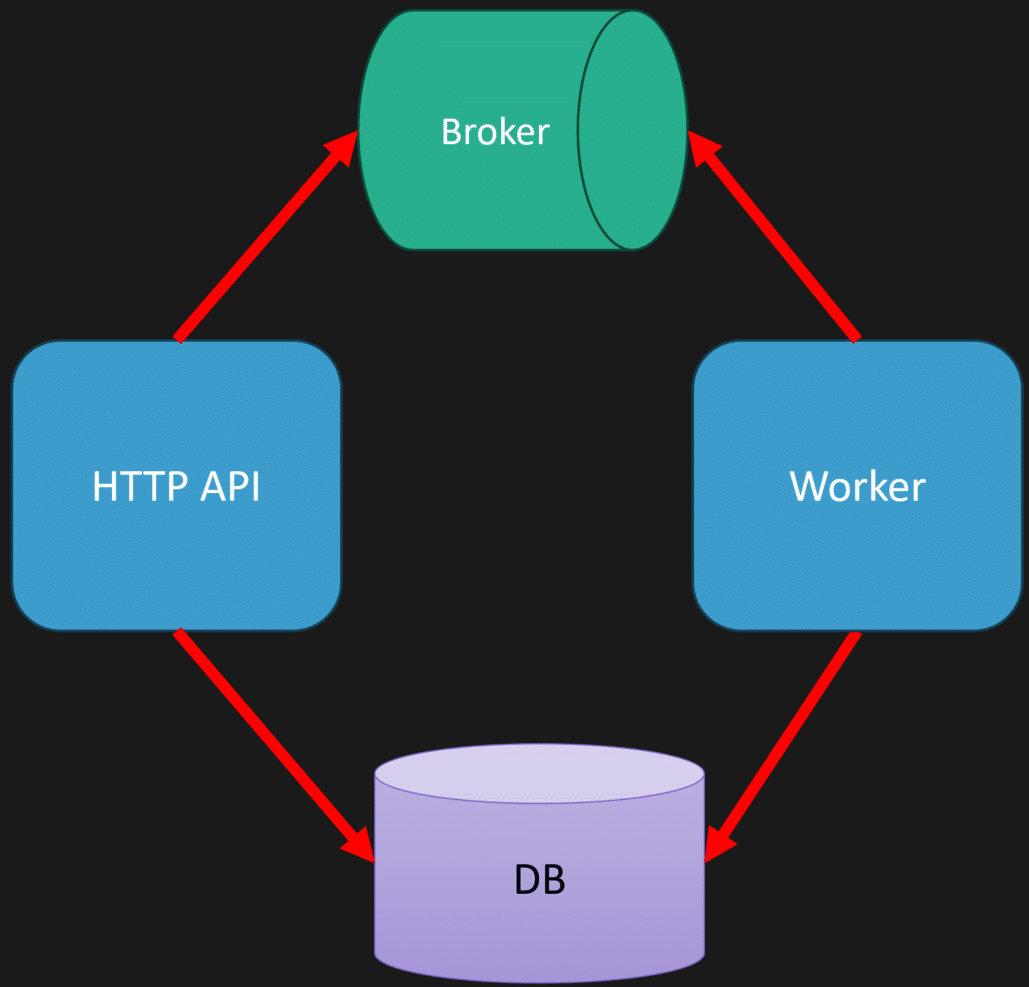
With multiple logical boundaries in the same codebase, you can still scale and deploy differently. Imagine three logical boundaries grouped into the same code base, but with two different entry points:
- An HTTP API for web requests
- A worker process consuming messages
Both entry points are part of the same code base but are built and deployed separately.
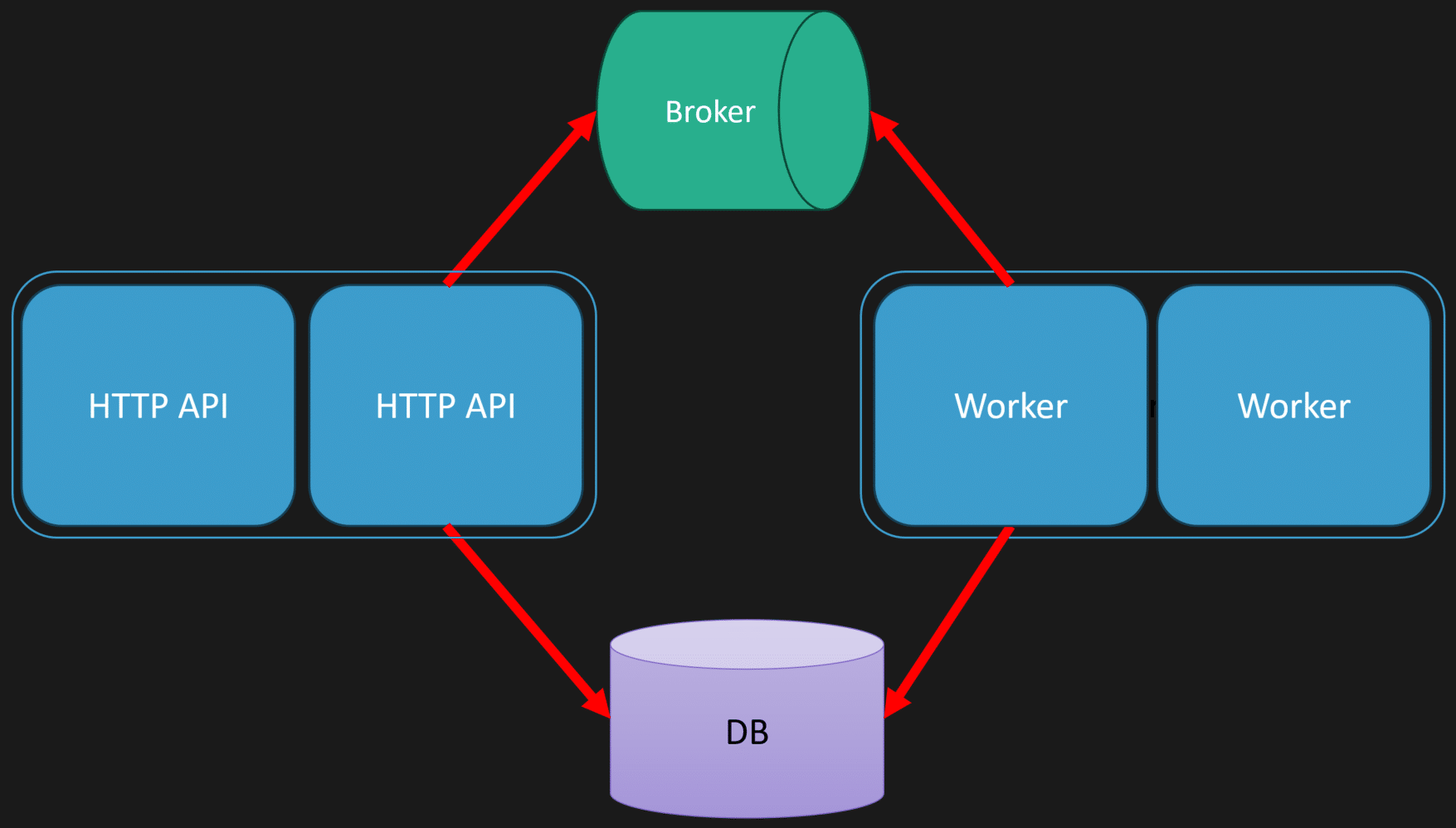
This lets you scale web traffic and message processing independently. For example, scale out the HTTP API behind a load balancer and scale workers separately based on message volume.
Logical Boundaries Aren’t Physical Boundaries
The key realization is that logical boundaries are not the same as physical boundaries. Too often, we get stuck thinking that a logical boundary must have its own source code repository, build artifact, or container. It doesn’t have to be that way.

You can:
- Have a single source code repo containing many logical boundaries
- Build multiple executables or containers from that repo (e.g., one for HTTP API, one for workers)
- Deploy logical boundaries separately or combined, depending on scaling needs
Mix and match whatever works best. Recognizing this opens up a lot of possibilities and removes many of the limitations traditionally associated with microservices or monolith debates.


Loosely Coupled Monolith
The Loosely Coupled Monolith is about grouping functionality into logical boundaries with high cohesion, managing coupling through contracts and messaging, and realizing that logical boundaries don’t have to map 1:1 to physical deployment boundaries.
Thinking this way changes how you approach software architecture and design. It frees you from pointless debates about microservices vs monoliths and instead focuses on what really matters: building flexible, scalable systems that hold up over time.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.