Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
For the last 10 years, I’ve been developing a single product, greenfield, designing the architecture from scratch, and evolving it over time. Over this decade-long journey, I’ve made some architectural decisions I’m proud of—and some I definitely regret. Today, I want to share those experiences with you, diving deep into the good and bad decisions I made, and what I learned along the way.
One theme that runs throughout my experience is the importance of isolation. How you isolate parts of your system, define boundaries, and manage dependencies can make or break your ability to evolve your architecture over time.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Industry Trends: The Good and the Bad
Let’s start by looking at industry trends I followed—and some I didn’t. Staying on top of trends is important, but it’s equally important to understand when to follow them and when to take a different path.
Ten years ago, there were two big trends: single page applications (SPAs), especially with AngularJS, and microservices. Back then, AngularJS was gaining traction as the go-to SPA framework, and microservices were all the rage for backend architecture.
The AngularJS SPA: A Regrettable Decision
Looking back, one of my more regrettable architectural decisions was building a monolithic single page application using AngularJS. It wasn’t the framework itself that was the problem, but how I structured the application around it. The SPA was monolithic in nature, which severely limited options for evolution.
What I mean by this is that when you build all your components in AngularJS, you’re locked into that framework. The components only work within AngularJS, and it’s very difficult to swap out or evolve dependencies. If your entire front end is tied to a monolithic AngularJS SPA, you’re stuck. This rigidity makes it hard to adapt as technology and requirements change.
Choosing Not to Use Microservices: A Good Decision
On the flip side, one of the better decisions I made was not jumping on the microservices bandwagon for the backend. Instead, I stuck with a monolithic backend architecture. But—and this is important—my backend monolith was designed with clear boundaries around business capabilities.
Here’s what that means: I defined what the system actually did, grouped related capabilities together, and set explicit boundaries around those groups. This approach gave me the flexibility to evolve each boundary independently. For example, one boundary might be simple—just interacting with a database—while another might have a rich domain model with complex business rules and an HTTP API in front.
This boundary-driven design gave me the best of both worlds: the simplicity of a monolith with the flexibility to adopt different tooling, dependencies, or implementations within each boundary. It allowed me to be pragmatic rather than dogmatic about architectural patterns like Domain Driven Design or Event Sourcing.
Defining Boundaries: The Key to Evolution

What does defining boundaries mean? It means grouping functionality based on what the system actually does—its business capabilities—and setting clear boundaries around those groups. This approach lets you decide independently how each boundary implements its features, what dependencies it has, and even what tooling or technology it uses.
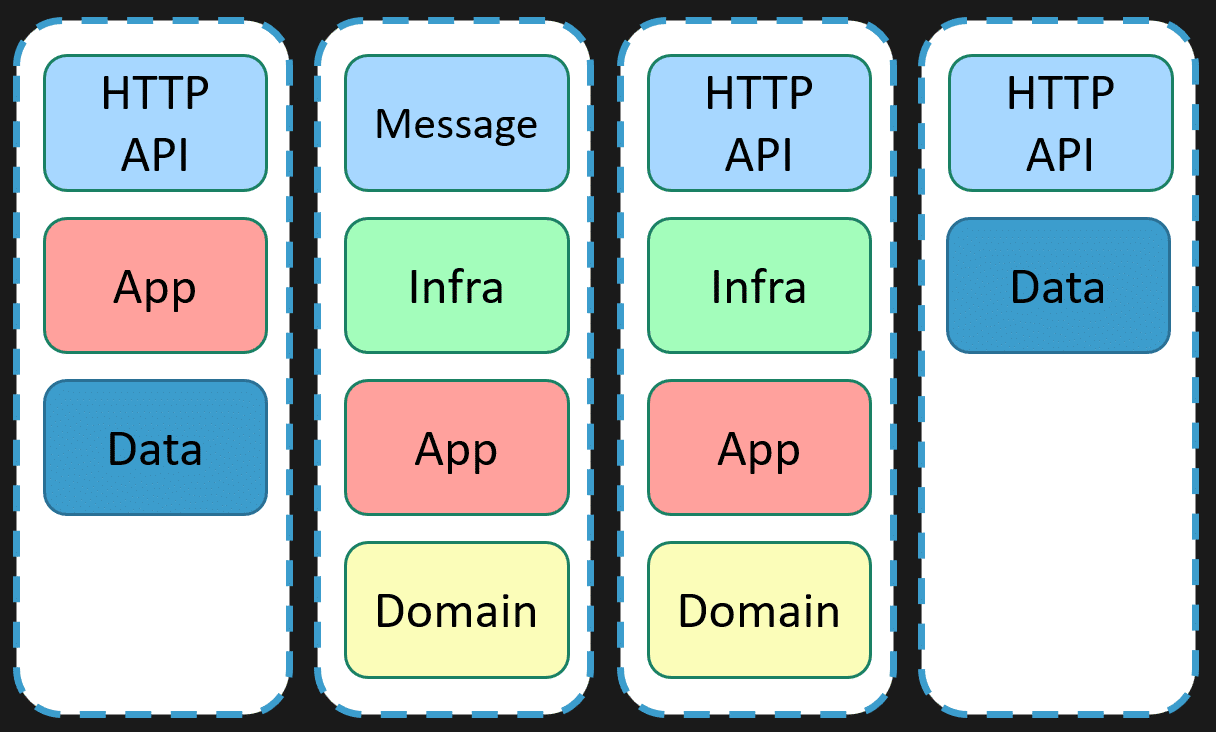
For example, one boundary might be simple, just interacting with the database directly. Another might have a rich domain model that captures all the business rules and invariants, exposing an HTTP API. Yet another might be just a simple supporting role with almost no business rules, just an API over a database. The point is, you don’t apply the same architectural pattern everywhere. You’re pragmatic—choosing the right level of complexity for each part of the system.
I often get questions from folks on Discord or other places about how to apply Domain-Driven Design (DDD) or event sourcing or clean architecture. The reality is, these are tools or solutions to specific problems. If you try to apply them everywhere indiscriminately, you just add unnecessary complexity and overhead. Defining boundaries helps you focus on what you actually need to solve in each part of your system.
The Front End: Rethinking the Single Page Application
Going back to the monolithic AngularJS SPA, one thing I wish I had done differently was to think about boundaries at the page level instead of the component level. Instead of making every component tightly coupled to AngularJS, I should have grouped by pages or sets of pages, creating boundaries there.
This way, when AngularJS eventually became obsolete and was replaced by Angular or other frameworks, I wouldn’t have been stuck with a massive monolithic front end. Instead, I could have isolated the legacy AngularJS code to just a part of the app, allowing other parts to evolve independently with different technologies.
Web-Queue-Worker Pattern: Scaling with Pragmatism
Related to microservices and the idea of distributing your system by service, I took a different approach: a monolithic backend with well-defined boundaries, combined with the web-queue-worker pattern to handle asynchronous processing.
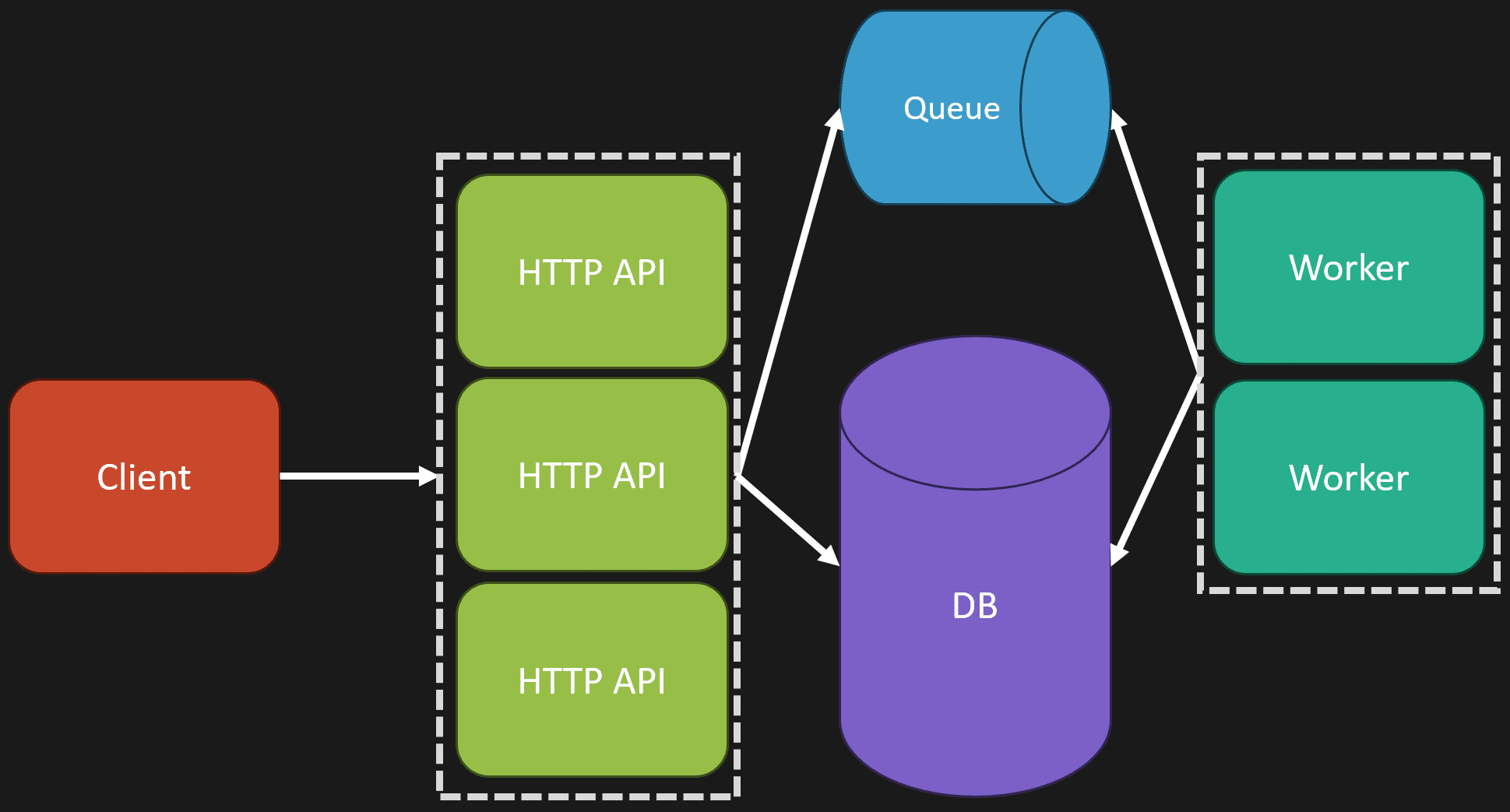
Here’s how it works: the front end, whether AngularJS or something else, makes requests to an HTTP API. Sometimes these requests involve synchronous operations, like querying the database. Other times, they’re asynchronous—say, you want to send an email or kick off a long-running job.
Instead of making the client wait for the job to finish, the API places a message on a queue and immediately returns a response. A separate worker process then picks up the message from the queue and does the actual work, whether that’s sending the email, interacting with the database, or something else.
This approach has many benefits:
- Scalability: You can scale your worker processes independently from your web API, adding more workers to handle more messages concurrently.
- Responsiveness: Clients don’t have to wait for long-running tasks to complete, improving user experience.
- Scheduled Jobs: The same queueing mechanism can handle recurring or scheduled jobs, like cron jobs.
That said, this pattern comes with trade-offs. It’s not as simple as just adding a queue and everything magically works. You have to handle complexities around message processing, failure handling, idempotency, and more. I’ve made videos diving deeper into these topics, and I’ll link them below.
Another important point is that the web API and the worker can share the same codebase. They’re just different entry points into the same underlying application, which makes maintenance and deployment easier. For example, my HTTP API runs on ASP.NET Core, and the worker process uses the same code to handle messages from the queue.
Event-Driven Architecture: Decoupling for Flexibility
Building on the idea of decoupling, event-driven architecture (EDA) was another pattern I embraced. The core idea is to decouple different parts of your system by using events to communicate asynchronously.
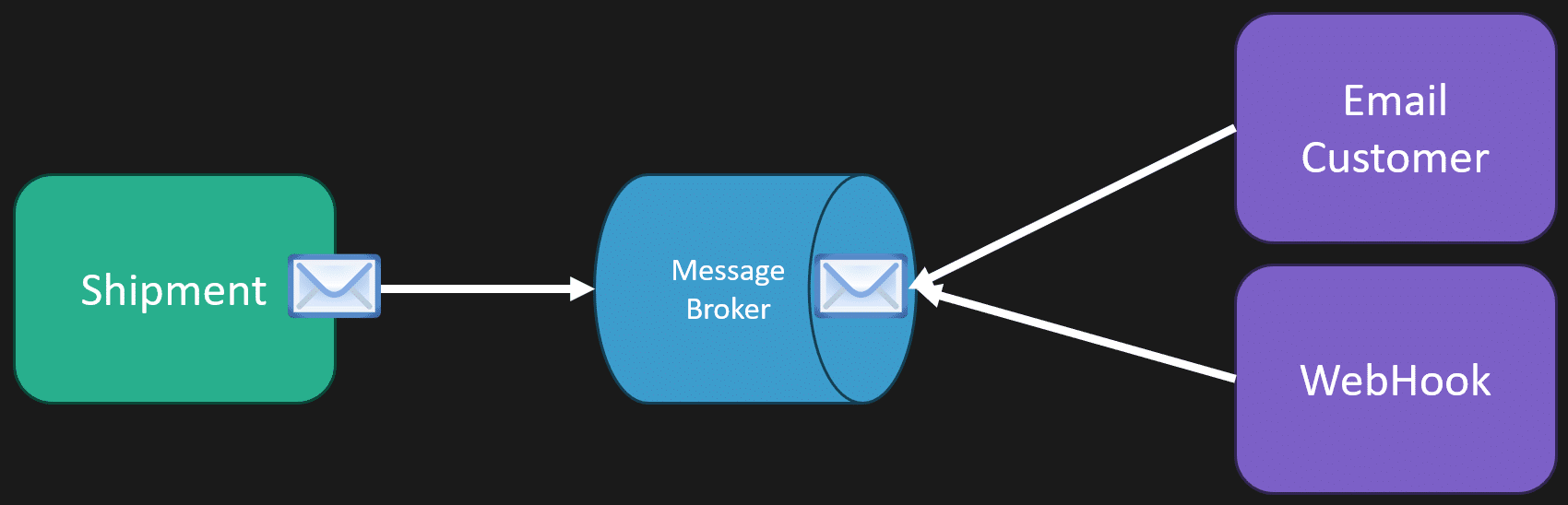
For example, imagine a package shipment system. When a package gets delivered, several things need to happen:
- Send an email to the customer notifying them of delivery.
- Send an SMS message.
- Trigger webhooks to third-party systems.
With event-driven architecture, each of these actions can be handled independently by different event handlers. If one handler fails, it doesn’t affect the others or the main event of the package delivery itself. This isolation makes the system more resilient and easier to evolve.
The key takeaway here is, again, boundaries. Each event handler is isolated, so if you decide to remove or replace one (like webhooks), you can do so without impacting the rest of the system. You can add new handlers for new features without touching existing code.
But EDA isn’t a silver bullet. It brings a learning curve and new complexities, such as handling eventual consistency, debugging asynchronous flows, and managing event schemas. Wix.com posted a great article outlining some pitfalls they encountered with EDA, and I’ve also discussed those challenges in my videos.
Event Sourcing: The Good and the Bad
Part of our system used event sourcing, and while it was a good decision overall, I want to highlight a bad architectural choice we made related to it.
Event sourcing records the state of your system as a series of events. For example, in our shipment system, we had events like:

Here’s the problem: the position updates were flooding the event stream, but they didn’t affect the business logic state. For instance, whether the vehicle has arrived or the package is loaded depends on specific events, not on the continuous position updates.
This cluttered the event stream and complicated the logic for determining what actions were valid next steps. It’s like having a database table with hundreds of columns where many aren’t relevant to your current queries. Not everything belongs in the same event stream or storage blob.
The lesson is to compartmentalize. Store and handle data where it makes the most sense, avoiding unnecessary coupling of unrelated data. This keeps your event streams clean and focused, improving maintainability and performance.
Wrapping Up: The Essence of Good and Bad Decisions
Looking back, the best architectural decisions I made were about defining boundaries, isolating components, and decoupling parts of the system. These choices gave me the flexibility to evolve the product over time, swap out technologies, and add or remove features without massive rewrites.
On the other hand, the bad decisions mostly came down to not defining those boundaries well enough—whether it was a monolithic AngularJS SPA on the front end or cluttered event streams in event sourcing. These choices made evolution harder and introduced technical debt.
Ultimately, the key is giving yourself options to evolve. Defining small, clear boundaries lets you manage complexity and adapt over time. When you don’t, you can still evolve your system, but it’s often more work and requires more thought to fix the issues.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.