Sponsor: Using RabbitMQ or Azure Service Bus in your .NET systems? Well, you could just use their SDKs and roll your own serialization, routing, outbox, retries, and telemetry. I mean, seriously, how hard could it be?
Once you understand how Event Sourcing works, the most common thought is: “What happens when you have a lot of Events? Won’t it be inefficient to fetch every event from the event stream and replay all of them to get to the current state?”. It might be. But to combat this, you can use snapshots in event sourcing to rehydrate aggregates. Snapshots give you a representation of your aggregates state at a point in time. You can then use this as a checkpoint and then only replay the events since the snapshot.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything that is in this post on using Snapshots in Event Sourcing.
Large Event Streams
I’d guess in most situations, you won’t have a stream with a lot of events because you’ll have a lifecycle to the stream. Meaning an event stream usually has a life where it being and ends. For example, an Order as a lifecycle from when from the OrderPlaced to maybe an OrderShipped. After the order has been shipped, there likely are no more events for that specific order that will occur. However, you could have a stream that is opened ended or possibly has a really long life, such as maybe a product in a warehouse. That event stream could be long-lived as long as you keep selling and having a given product in the warehouse. In these situations, you may have thousands or millions of events depending on the context.
When you have a lot of events, the challenge is you generally will fetch from the Event Store all the events from the very beginning of the stream, and then replay them in your aggregate to build up to the current state. This could take an undesirable amount of time if you have to fetch and replay a significant amount of events.
Snapshots in Event Sourcing
Snapshots are a way of solving this issue by recording the state of an aggregate at a point in time. You then store this state in a separate event stream. Along with the state, you record the version of the last event you processed that represents this state.
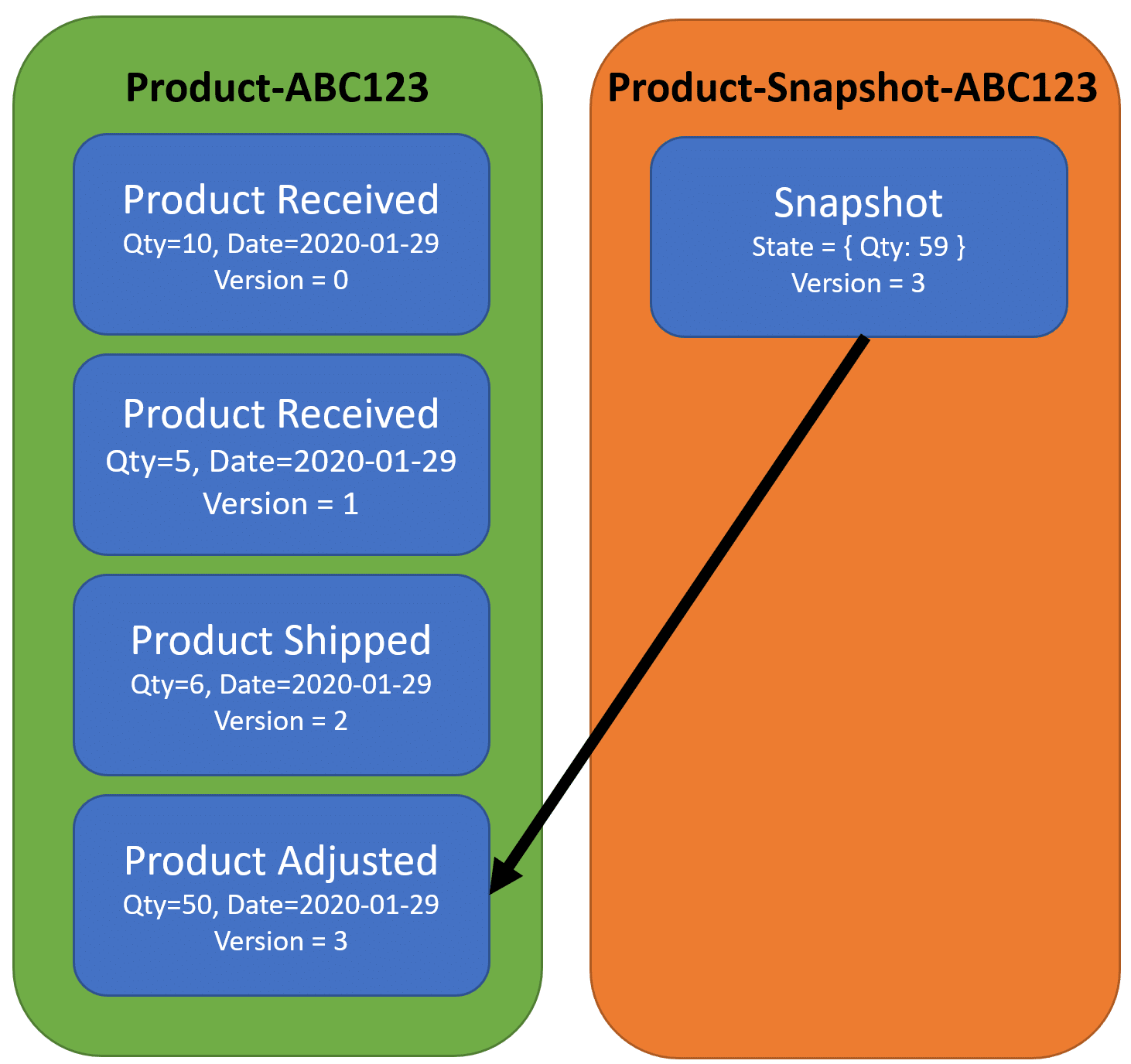
For illustration, you can see that the snapshot has our current state, which we’re recording the total quantity on hand. It also captures version (3) which is the last event in our event stream. For my example, I’m creating a snapshot on every 4th event. In reality, at what interval you create a snapshot is totally dependent on your situation. This could be hundreds.
Once more events are added to our event stream, we create new snapshots of the state and keep track of the version they pertain to.
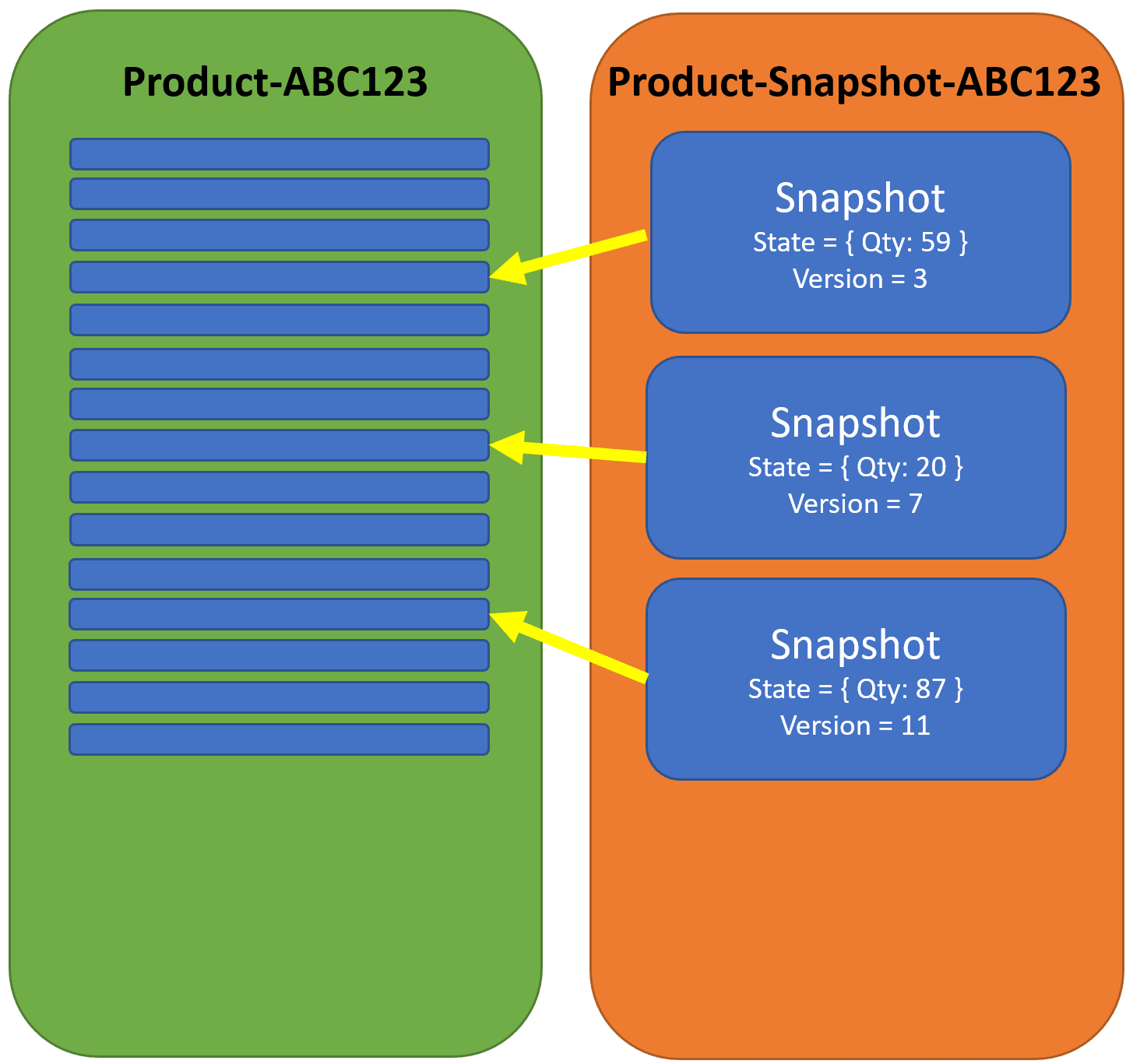
Rehydrating Aggregate
Now instead of replaying all the events from the beginning of the event stream, what we do is first look at the snapshot stream and see if there are any events. But you do so reading the stream backward! So in the example above, we would get the last snapshot in the stream, which has a State with the Qty: 87 and the Version = 11. We will pass the state into our aggregate, then we will query the event stream and start at Version 12. In my example above, it would then retrieve 3 events from that point, which would be replayed in our aggregate.
Here is some example of code from a Repository that is rehydrating an aggregate. That repository is using EventStoreDB as the EventStore.
Before you go down this road, make sure you absolutely need snapshots. They might not be required. Or perhaps you need to implement them for a specific type of event stream that is more open-ended. Keep track of metrics related to how long it takes to replay your aggregates, how many events typically in a stream, then decide if it’s worth adding.
Source Code
Developer-level members of my CodeOpinion YouTube channel get access to the full source for the working demo application available in a git repo. Check out the membership for more info.