Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Your system has 500 users and also has 20 microservices, including the gauntlet of Kubernetes, a message broker, distributed tracing, multiple different databases, and a pretty dashboard that probably nobody looks at.
Someone will ask the question: why is this so complicated for 500 users?
And usually the answer is, “Well, we’re building for scale.”
No. No, you’re not.
You’re building for scale you don’t have yet. That’s a lot of extra complexity.
Scaling software architecture is important to think about. But there’s a difference between actually implementing for scale and giving yourself the options to scale when you need it. You can build a path forward without paying all the upfront costs and complexity.
YouTube
Check out my YouTube channel, where I post all kinds of content on Software Architecture & Design, including this video showing everything in this post.
Scale Means Different Things
The word scale has a lot of different meanings, and that causes a lot of confusion.
You might hear things like:
“We need to split into microservices so we can scale independently.”
“We need to add a message broker so we can scale more background work concurrently.”
“We need to add a read model or a separate database because we have a read heavy system and a different shape of data.”
All of these are talking about scaling, but they’re not talking about the same thing. They all have different utility, and they all come with different tradeoffs.
That’s why the word scale by itself is so vague.
Are we talking about user scale, in terms of the number of requests, where you want to horizontally scale instances?
Are we talking about splitting into microservices for team or organizational reasons, where different teams have ownership over different boundaries?
Are we talking about database scale, read scale, write scale, or different shapes of data?
Are we talking about deployment scale, meaning how different parts of the system are deployed and how each part needs to scale differently?
Scale is just too vague on its own.
Every pattern has tradeoffs. I’m always trying to explain what the problems are, what the solutions are, and what the tradeoffs are, because sometimes the cost of complexity just is not worth it.
Patterns Are Great When You Actually Have the Problems

Microservices are useful for independent scale of code, teams, and deployments.
A message broker is useful for background work, asynchronous processing, buffering, reliability, and dealing with work that does not need to happen immediately.
Multiple databases can be useful for read and write scale, performance, or when the shape of data you mutate is different from the shape of data you need to query.
Kubernetes can be useful for infrastructure scale.
But all of it has costs. All of it has tradeoffs.

If we’re talking about microservices, most people know the list. You add a network boundary. You now have contracts, depending on how those services communicate with other boundaries. You have deployment, versioning, observability, failures, retries, timeouts, and the list goes on.
Messaging has a lot of the same concerns. Retries. Timeouts. Ordering, if you need it. Duplicates. Poison messages. Workflows. There is a lot of complexity in messaging.
Different databases have their own complexity too. What kind of replica is it? Are you using replication? Is there eventual consistency or lag? Are you creating a different shape of data where your application has to route between the read database and the write database? Do you have drift because of application code?
And Kubernetes has its own complexity. Everybody knows that.
There are complexities and tradeoffs. Don’t add them if you don’t need them yet.
So how do you build for scale so you can scale when you actually need to, without paying all the upfront costs?
Logical Boundaries Are Not Physical Boundaries
Let’s start with microservices.
A lot of people confuse logical boundaries with physical boundaries.
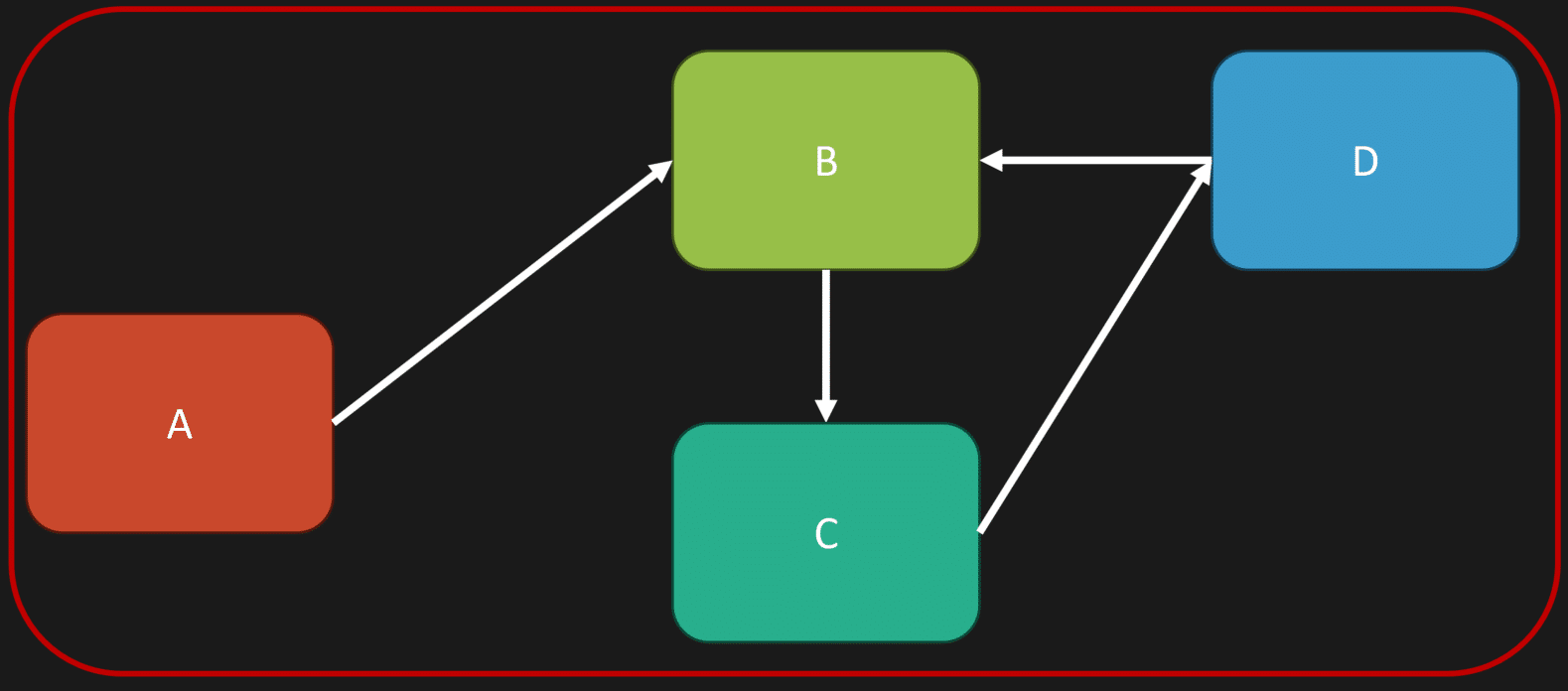
Say we have a monolith. We have modules A, B, C, and D. A is coupled to B. B is coupled to C. C is coupled to D. We have a rat’s nest of coupling, but it’s all inside one monolith.
Now take that same system and remove it from being a monolith. Each one of those modules is now a service or a microservice.
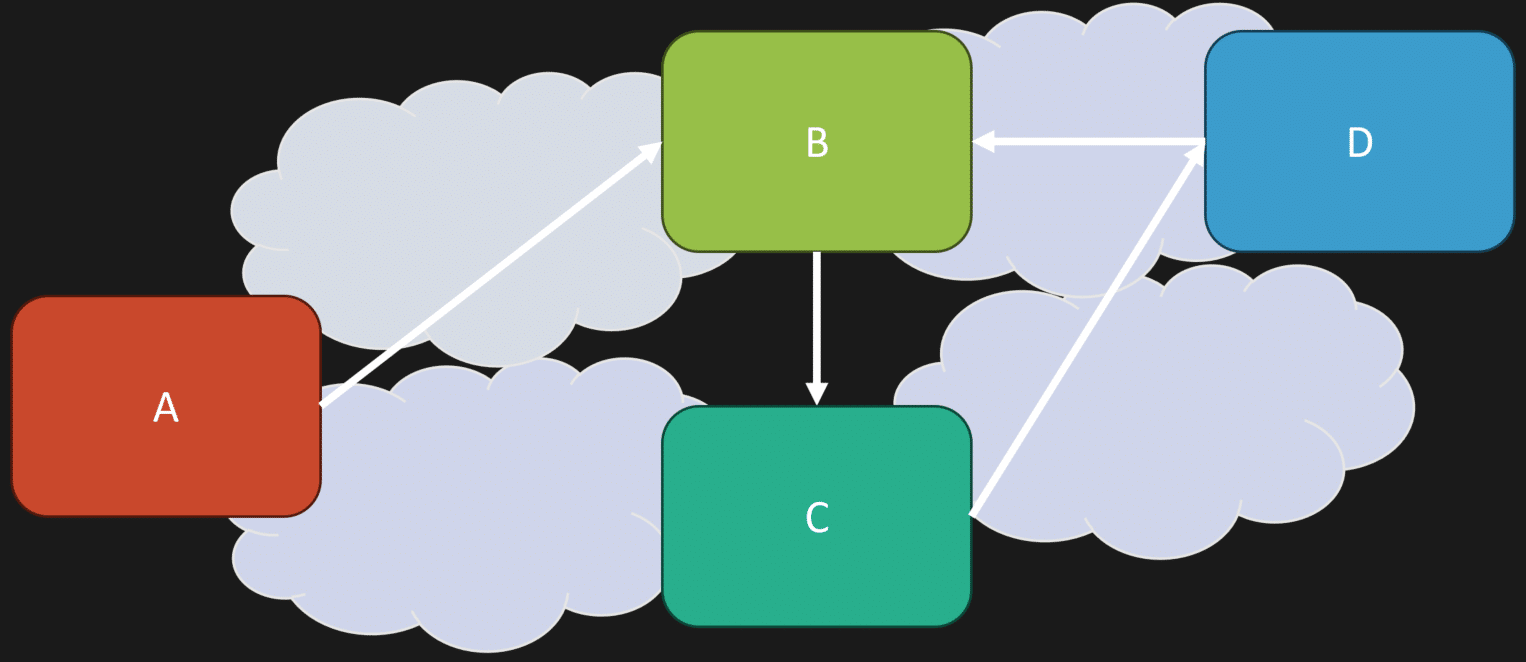
Are we less coupled?
No.
We’re still just as coupled. Actually, it might be worse now because we introduced network boundaries. We’re not magically decoupled because these things use HTTP to communicate with each other, or because they happen to use a message broker.
All we’ve really done is take a highly coupled monolith and turn it into a highly coupled distributed monolith.
That’s it.
If you take that source code and spread it apart into different repositories, that does not change anything. What we’re really after is defining logical boundaries.
How you deploy those boundaries physically, whether as a monolith or as different services, is a different concern.
What we’re after is logical boundaries and avoiding a big ball of mud.
A Service Does Not Have to Mean One Repository and One Deployment
When people think about microservices or services, they often think each service does something, has its own source repository, and gets built into its own deployable unit.
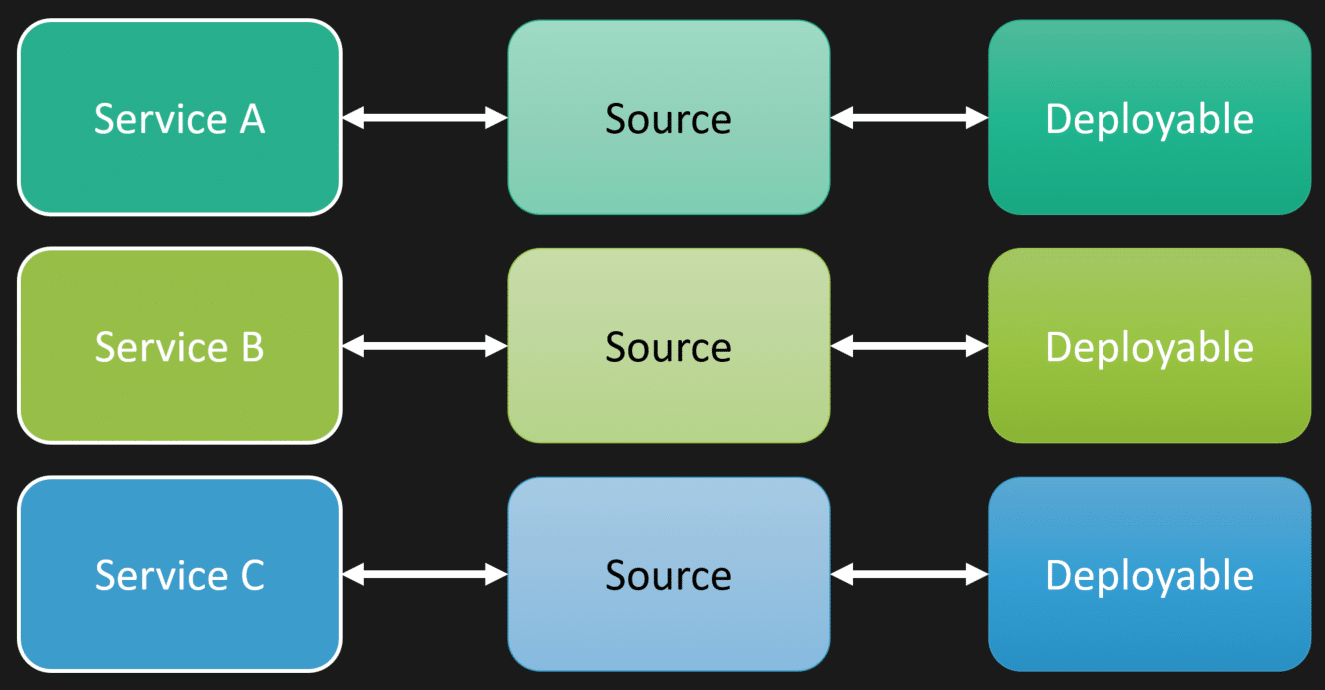
Service A has a repository and a deployment. Service B has a repository and a deployment. Service C has a repository and a deployment.
But that does not need to be the case.
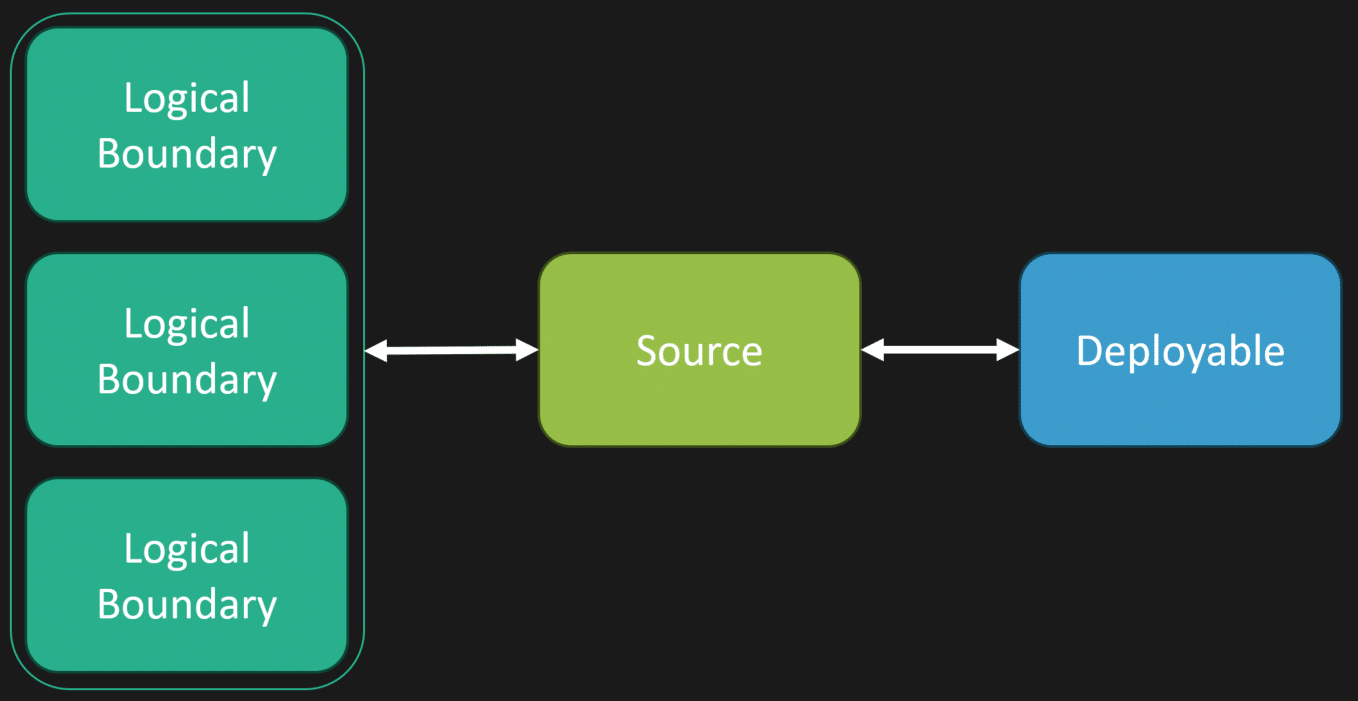
In a monolith, you can still have different logical boundaries. Those boundaries can live in the same repository and be deployed as one deployable unit.
This is really the 4 + 1 architectural view model. You have logical views, development views, physical views, and process views. Not everything has to be one to one to one.
This is why I like the idea of a loosely coupled monolith.
The Loosely Coupled Monolith
Imagine a system with three different logical boundaries. Each boundary defines contracts. If this is inside a monolith, those contracts might just be DTOs, interfaces, delegates, or function definitions.
You might still have one database instance. But within that database, you can have specific schemas or tables owned by a particular boundary.
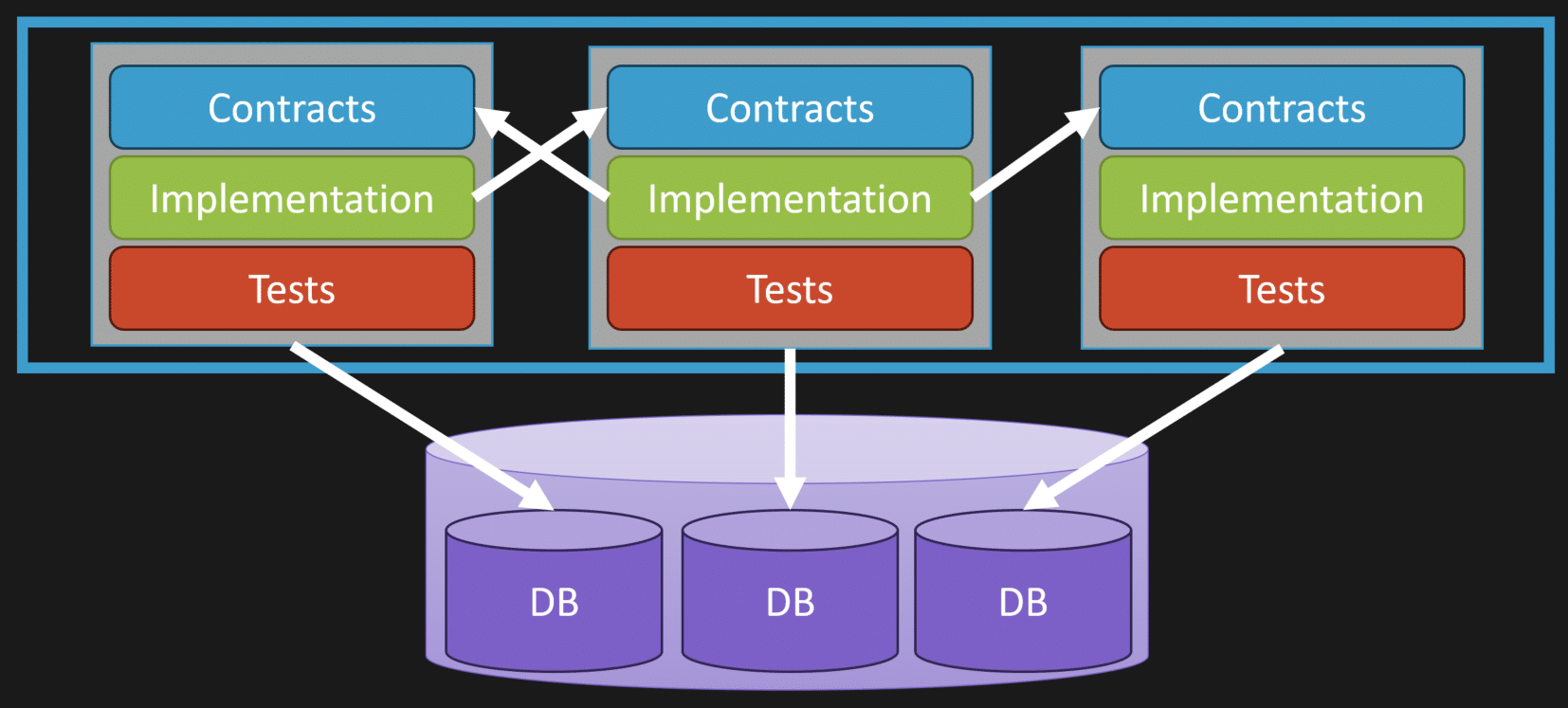
That means you already have segregation between what your code does, what feature sets it owns, and what specific data it references for read and write purposes.
There is not a tangled web where anything can reach into the database and talk to anything else. Boundaries talk to each other through APIs when they need to invoke actions related to data owned somewhere else.
If you build this way, there is nothing stopping you from changing the physical boundaries later.
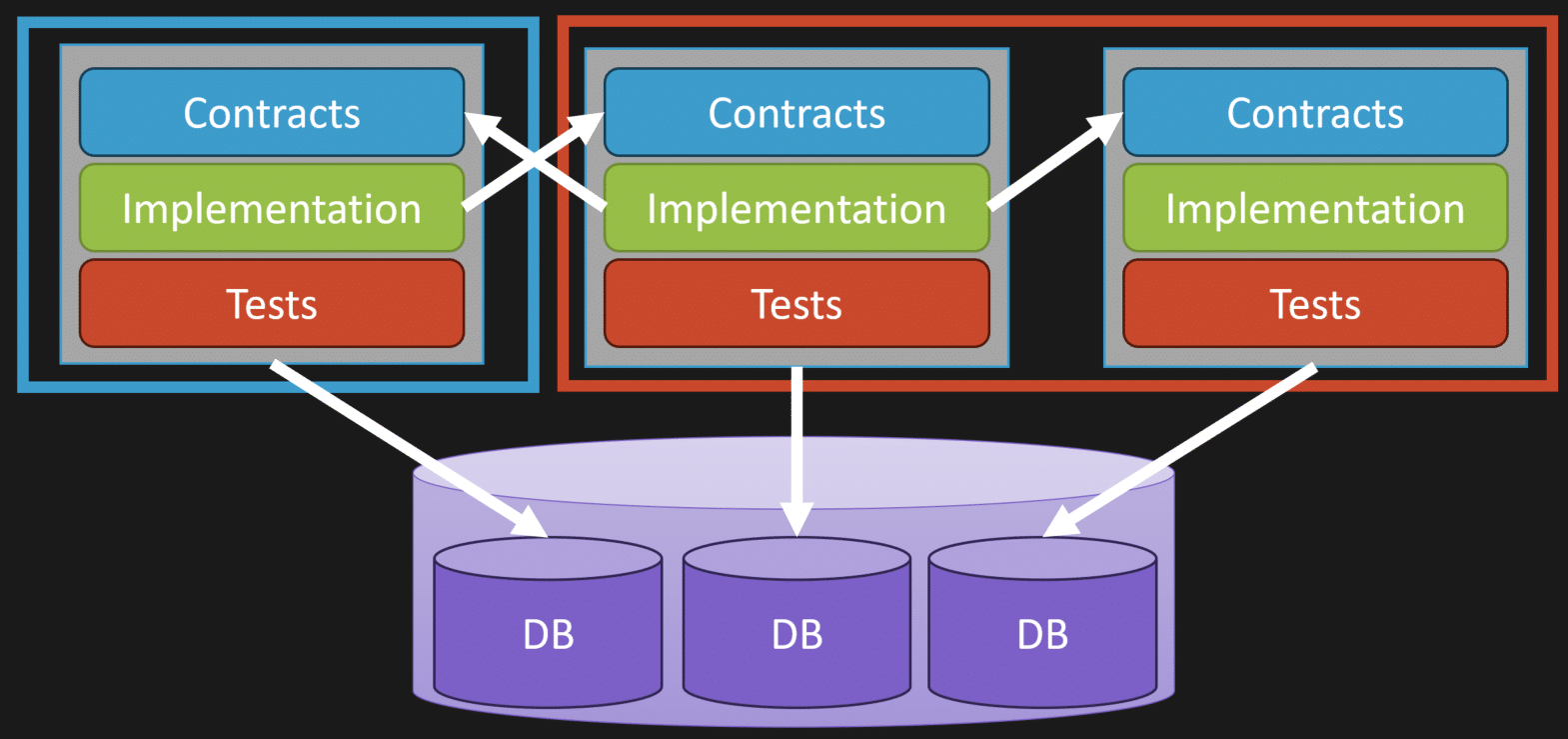
Maybe one logical boundary suddenly needs to be deployed separately because it needs to scale differently in terms of requests or users. The other two boundaries can still be bundled together. You can still have a single database. The logical model does not have to change just because the physical deployment changed.
Again, logical is not physical.
Adding Asynchronous Processing Later
You can take this a step further.
Maybe you need to introduce asynchronous processing because you need to do more work in the background. You can introduce a broker for that.
Maybe messaging becomes a primary way you communicate between boundaries. If some interaction needs to occur, there could be an event that happened or a command that needs to be processed. You send that to the broker, and another part of your system consumes it.
That can still happen inside the same monolith. One boundary can produce a message, and another boundary can consume it, even though physically they are deployed together.
Then, if you split things apart later, you are still using the broker to message between those same logical boundaries. This could still all be in the same repository. It could be deployed together or deployed separately.
Logical is not physical.
A monolith does not have to be a rat’s nest of coupling. You can have defined logical boundaries and decide how you want those boundaries to communicate.
The same is true with microservices. Yes, you can have a distributed monolith because you have a rat’s nest of coupling. But it does not have to be that way if you define your boundaries well and are intentional about how they communicate.
Building a Path for Scale
This is how it relates to scale.
You’re not ignoring scale. You’re building a path forward depending on how you need to scale.
If you have well-defined boundaries and later need to separate something for independent deployability, you can do it.
If you need to separate something for team or organizational reasons, you can do it.
If a particular part of the system needs to scale differently for requests, users, or background work, you have a path.
That does not mean you need to build out the full scaled architecture before you actually have the problems that require it.
Messaging Does Not Fix Bad Boundaries
Another one that comes up a lot is asynchronous processing with a message broker or something like a distributed log.
Messaging has a ton of value and solves real problems.
It gives you temporal decoupling, where two different systems, or even two different boundaries inside the same monolith, do not need to be online or available at the exact same time.
It gives you buffering, where you can have messages going into another system and processed as load ebbs and flows.
It can improve reliability because you have durable messages sitting in a queue or topic, depending on how you are processing them.
One of the things I love about messaging is integrations, especially when you need to deal with external systems. Something happens in one part of your system, you need to react to it, and you need to talk to another system.
Messaging also helps with asynchronous workflows. In most business systems, that’s really what is happening. Something happens, then something else happens, then there is some handoff. There are a ton of workflows in business systems.
But there is also a lot of complexity that comes with messaging.
You have to deal with idempotency because duplicate messages are going to happen. You have timeouts, backoffs, retries, poison messages, ordering, and workflow coordination.
There is a lot to deal with. You need to have enough value to justify that complexity.
If you have a distributed monolith making HTTP calls from service to service and you decide, “Well, this is not reliable enough, so we’ll move to something asynchronous,” sure, you may improve reliability in some areas.
But you still have the same coupling.
Adding messaging, a message broker, an event log, or event driven architecture does not solve bad boundaries.
Coupling Is Still Coupling
Ultimately, it does not really matter whether you have a monolith with in-process communication, HTTP between services, a message broker, or events.
If you are temporally coupled, you have to coordinate everything between those parts.
If you are coupled by data, whether by events or by a database, you still have to coordinate everything because changes have to be understood by everybody who depends on that data.
If you are behaviorally coupled between services, where one service needs to know what to invoke on another service because that service performs some action, you still need to coordinate everything.
The mechanism does not remove the coupling.
For scale, it is about building a path.
That does not mean building out a full scaled architecture before you actually need to scale. It means defining good boundaries and understanding the distinction between a logical boundary, what something actually does, and the capabilities it provides, versus the physical boundary of how you deploy it.
That distinction matters.
Define the boundaries so you can build a path for scale. Don’t pay all the costs before you have the problems.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.