Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Let’s play a game called Guess the Software Architecture! Can you guess the software architecture in these diagrams in this post? What characteristics determine which type of software architecture is being used? Do you think its a monolith or microservices? Or possibly something else!
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Evolution
So, first, we’ll start with an HTTP API that talks with a database. The HTTP API could be a single process or within a container, and it could be scaled out horizontally behind a load balancer.
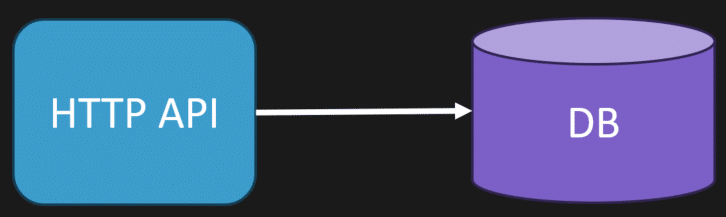
In a larger system, not all the work is done within the HTTP API. You’ll often have a separate process that does asynchronous work. Usually, it processes messages from a queue from a message broker.
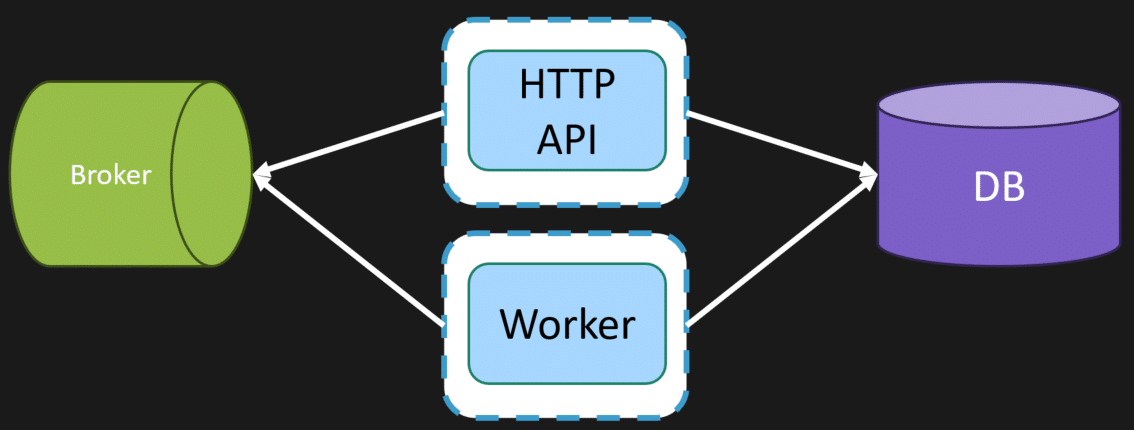
The worker will process messages and interact with the same database as our HTTP API. Usually, the HTTP API will add messages to our queue, and the Worker will process them asynchronously. This is called the Web-Queue-Worker pattern.
It’s important to note that the HTTP API and the worker, while different processes, can be from the same underlying codebase. They are just different executables built. You can think of them as different entry points into your system. But they could be built sharing the same underlying code.
If we dig a bit deeper into that codebase, we can see that we have defined different boundaries or modules.
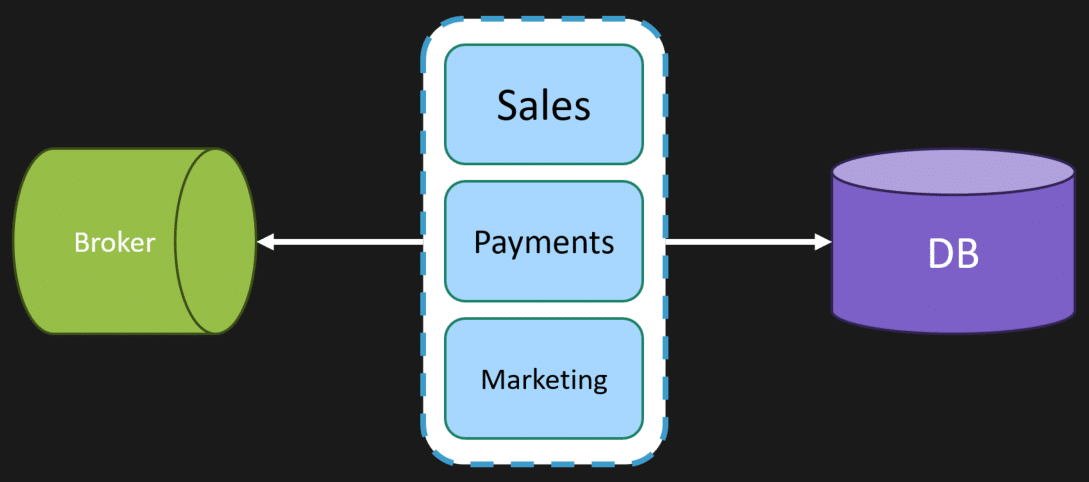
Sales, Payments, and Marketing boundaries/modules handle all the related functionality. Sales handles all types of order processing; payments handle credit card transactions; marketing handles emails, etc.
There likely is some coupling between these modules/boundaries. Oftentimes, there will be some type of cross-boundary communication because you might want to invoke some behavior from one boundary to another.
Because these boundaries are defined, we might decide that one particular boundary has different deployment concerns so we carve it off so it can be deployed separately.
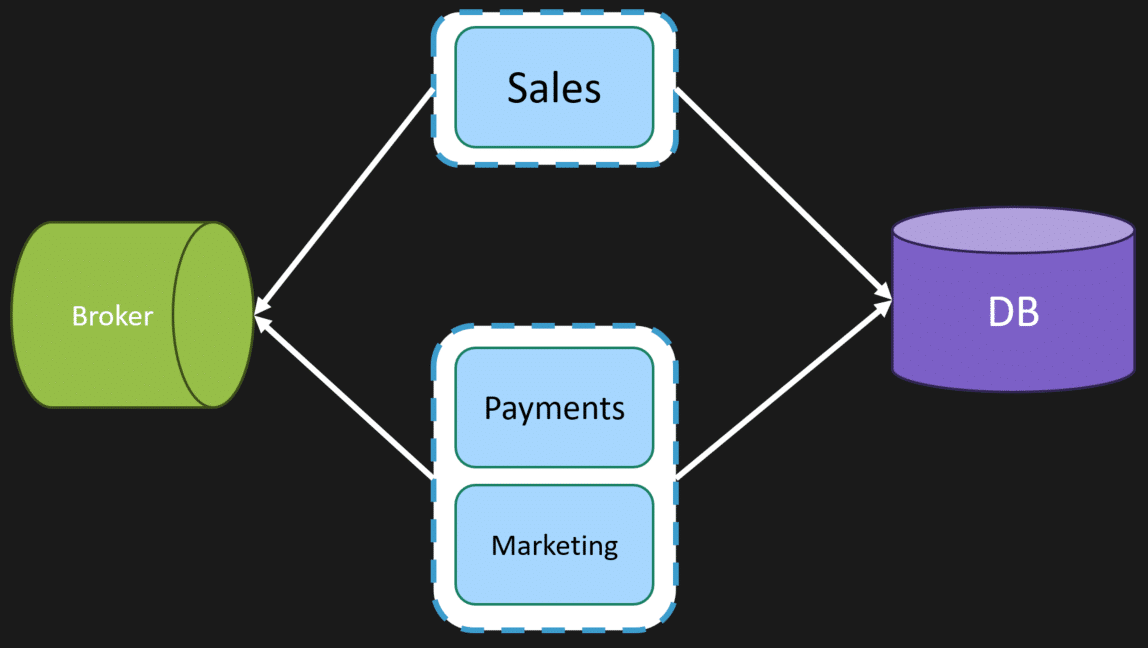
This means we could have Sales in an independent process. We can deploy it at a different cadence and scale it differently than the payments and marketing that are bundled together in the same process for both the HTTP API and the Worker.
The issue is that we likely had some cross-boundary coupling that was previously in process. Now, since it’s separated, we’d need to make some type of RPC call between processes.
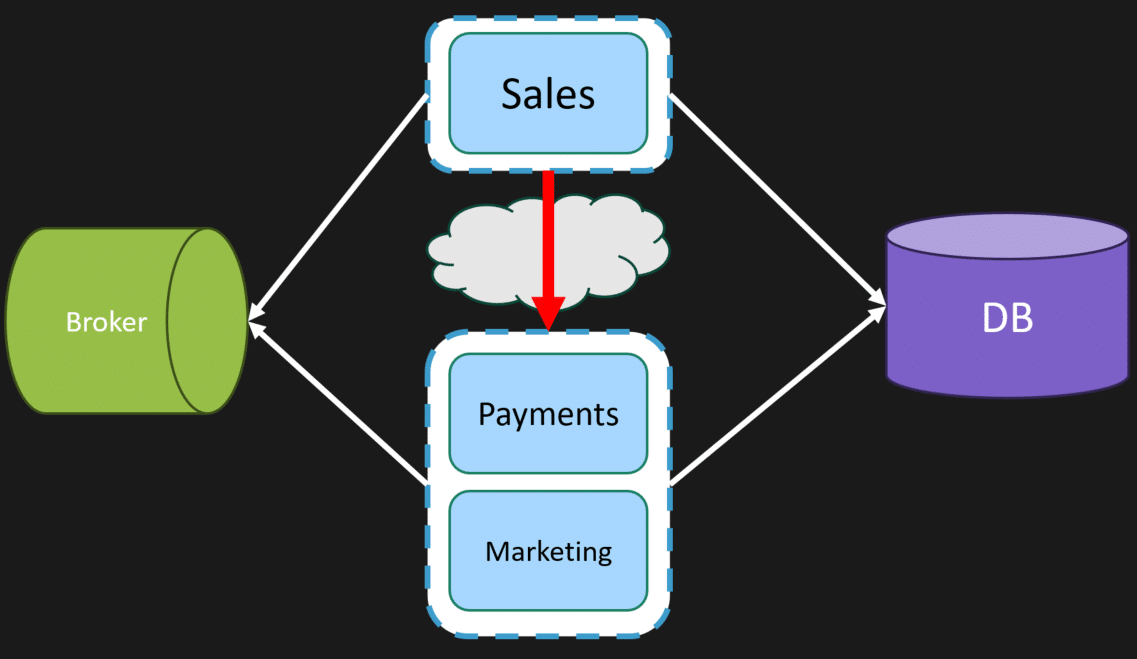
When these boundaries are defined in code, they also apply to the underlying schema, meaning that each owns a part of the database schema. The database might be a single instance, but it’s partitioned per boundary. So, this means we could have Sales interact with a totally different database instance for its specific schema.
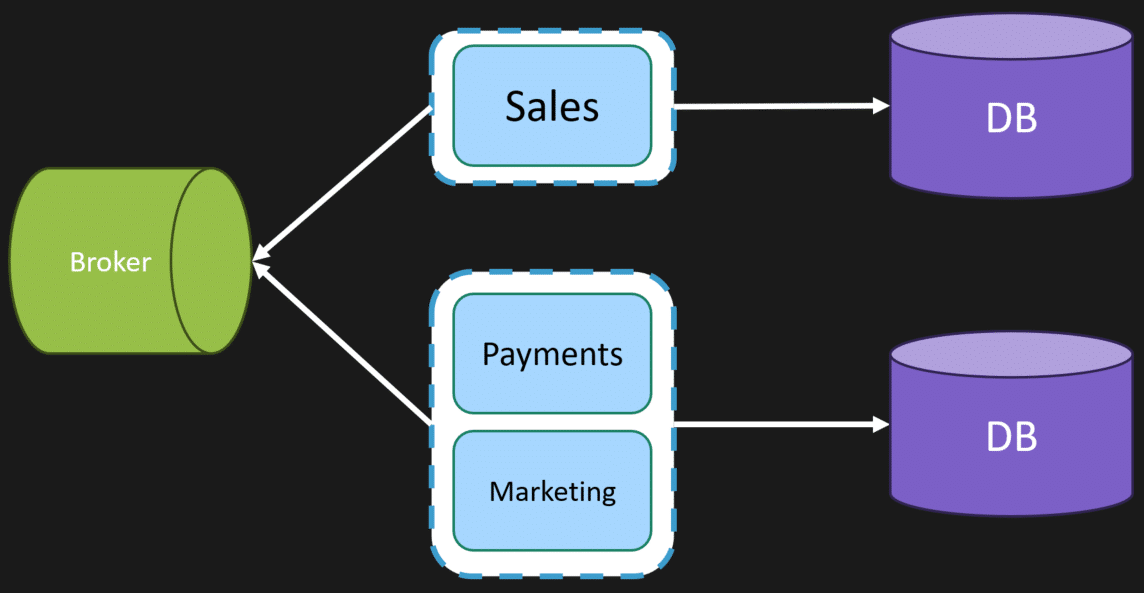
If each boundary owns its own schema, we could separate them into their own units of deployment.
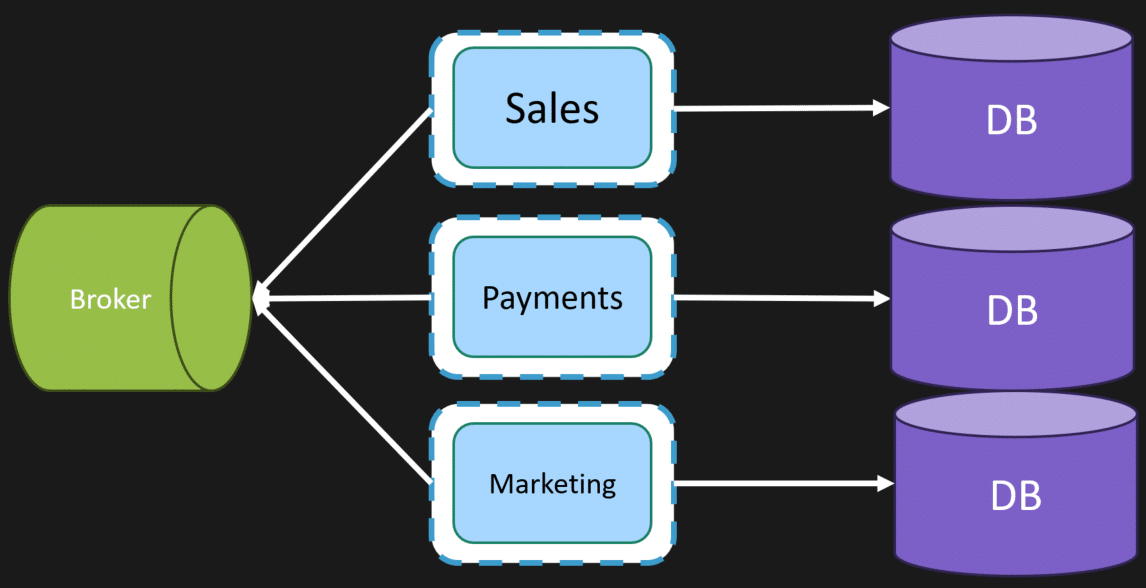
Guess the Architecture
So, is this a monolith or microservices? Or something else?
So, we have a system with two different entry points: an HTTP API and a Worker. Boundaries are defined so that each can be independently deployed as its own unit and solely interact with its own database schema.
But having said that, because these boundaries are defined, it could be mentioned at the very beginning that they could be deployed all together in a single unit.
So what’s the architecture? Monolith? Microservices? Distributed Monolith?
The trouble is the industry has decided what architectural styles are applied based on its physical deployment.
Microservices are an excellent example of this because, generally, people view their logical, development, and physical deployment boundaries as being one-on-one.

But in reality, if a service was using a web-queue-worker, it looks more like this:

But you might have a service with different repositories because they are built differently, possibly using different languages or platforms.

An example is if you have a service composed of an HTTP API, a Worker, and a Mobile frontend.
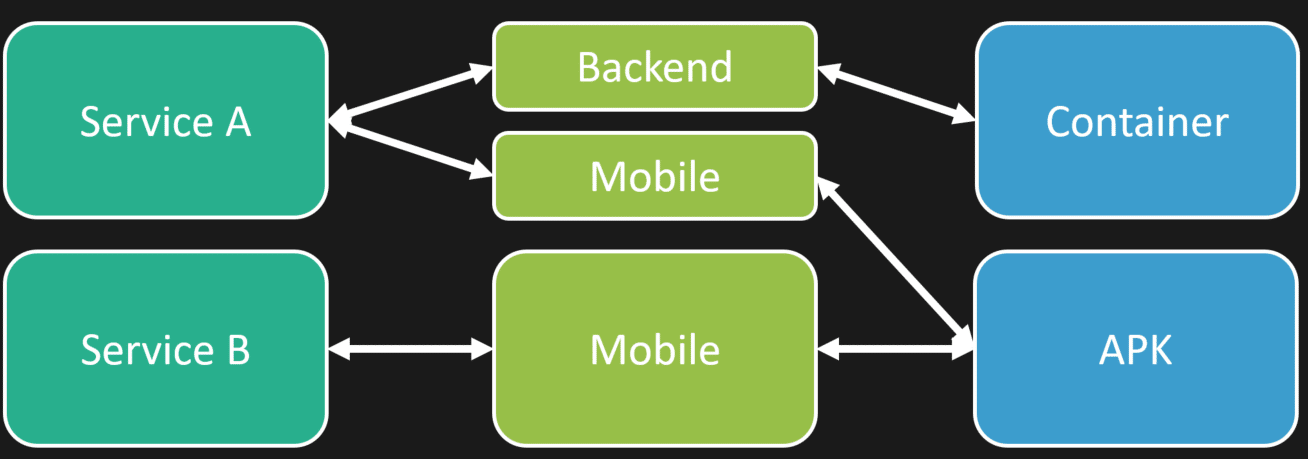
Composition occurs because your logical and physical boundaries don’t need to be the same. For example, Service A and Service B can be composed for a mobile app. Service A could have an HTTP API and a Worker composed into a single container.
A lot of your options about how you do composition is based on coupling and communication. How you choose to couple will dictate your deployment options.
If you’re tightly coupled by types in process, you will deploy everything as a single unit. Suppose you have a separate boundary deployed separately but using RPC. In that case, it can deploy independently until there’s a breaking change, at which point all have to be deployed simultaneously.
So what’s the architecture? Monolith or Microservices… or none of the above.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.