Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
When people are getting into Event Sourcing, there are a few common questions that I often get or issues see people run into. CRUD Sourcing, Pre-mature optimization using Snapshots, and exposing your event streams for integration. Here are my top three Event Sourcing Tips to help you down the right path.
YouTube
Check out my YouTube channel where I post all kinds of content that accompanies my posts including this video showing everything in this post.
CRUD Sourcing
My first event sourcing tip, which is probably the most common issue I see people run into when new to Event Sourcing is what is often called “CRUD Sourcing”. If you’re used to developing applications/systems in a Create-Read-Update-Delete style, then this means you’ll likely end up creating Events that are derived from Create, Update, Delete.
There’s a shift when moving from an application that simply maintains the current state via CRUD to having your point of truth be a stream of events. Often events are artifacts of the state change as well as the business event that caused that state change.
If you provide a UI that’s CRUD driven on Entities, you’ll end up with events that are derived from that. As an example, you’d start creating events such as ProductCreated, ProductUpdated, and ProductDeleted.
Still in line with this is if you have updates that are for properties on Entities, you’ll end up with events such as ProductQuantityUpdated or ProducePriceChanged.
In both cases, the events are simply representing state changes but not why the state changed.
What was the reason why a ProductUpdated occurred? It was updated, great, but why?
How about the ProductQuantityUpdated event, why did that change? Was it because there was an inventory adjustment? Did we receive more quantity of the product from the supplier? Why was it updated?
Being explicit about the events is important because we want to be driven by business concepts. To get out of CRUD we need to move to more of a Task Driven UI. This allows us to have the client/UI explicitly perform a Command/Task. For example, if the user performs an Inventory Adjustment as an explicit Command/Task, that’s a business concept. We will generate an InventoryAdjustment event.
Being explicit is important because you do not need to derive or guess based on the data of the event and why it occurred. You’ll have many more answers to questions when you look at an event stream when they are explicit. As an example, when’s the last time we did an inventory adjustment? When we do inventory adjustment, how many times are we decreasing the quantity on hand? You cannot answer these questions with a ProductUpdated or a ProductQuantityChanged.
Optimizations
Once people understand Event Sourcing and how it works, the most common question is:
That seems really inefficient to have to fetch all the events from a stream to build up current state! What happens if I have 1000’s events!
To understand how event sourcing works check out my post Event Sourcing Example & Explained in plain English.
As a quick primer, you have a stream of events for a unique aggregate, such as Product with a SKU of ABC123.
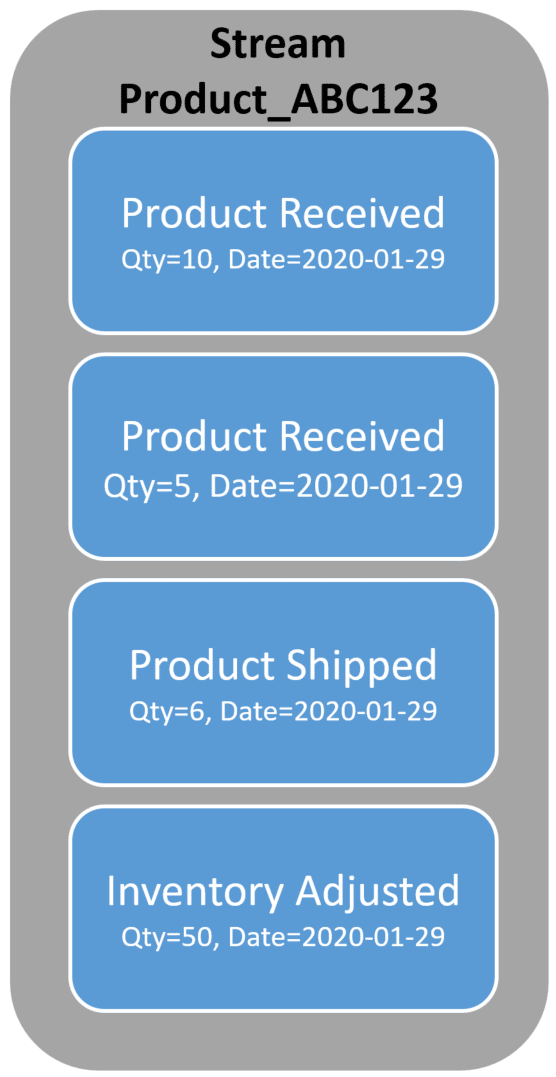
Anytime we want to perform a command which will append a new event to the stream, we’ll generally fetch all the events form the stream, build up the current state, then enforce any invariants for the command we want to perform.
In the stream above if we were keeping track of “quantity” as the current state, it would be 59.
So back to the common comment of “that’s really inefficient”, is a pretty valid concern. The answer to this problem is called Snapshots, but they are an optimization that you don’t necessarily need to apply right from the start or often.
In my experience, event streams are generally finite and have a life cycle with a beginning and end. There may be a long time duration for how long a stream is “active” but the events that are persisted are often limited.
If you have a lot of events and it’s taking a long time to rebuild the state, then creating snapshots can help. They are a way of creating a point-in-time representation of the state.

After so many events append to a stream, you persist another event to a separate stream that is the current state, also recording at which version of the stream it represents. This way when you want to rebuild the current state, you first get the last snapshot and then get the events from the stream since that snapshot was created.
Now the question is, when do you create snapshots? If you think the event stream is going to contain a lot of events, how many for a given situation is a lot? Each different type of event stream is going to have different events which contain different data. There’s no magical number of events that is a threshold for creating a snapshot, it’s going to be use-case specific.
Event Sourcing Tip, don’t jump to snapshots immediately, look at how you’ve defined your streams and boundaries.
Communication & State
This last mess people get in with Event Sourcing is conflating events representing state as well as using events as a way to communicate with other service boundaries.
Your event store, the event streams, and the events within a stream represent the state.
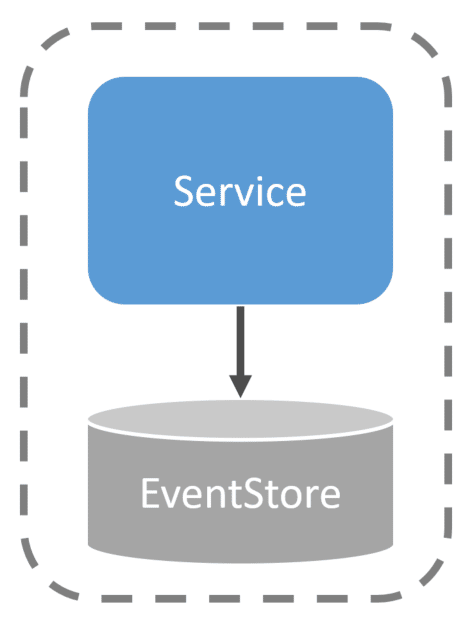
Often with Event Sourcing, you’ll create Projections as a way to represent the current state for Queries/UI/Reports. This way you can query a separate data store that’s pre-computed the current state. This means you don’t have to pull all the events to a stream to build the current state. It’s already pre-computed as events occur (usually asynchronously)

This means you’ll have two different databases. One for your event streams and one for projections. This is all within the same logical service boundary.
Now if you’re using an Event Store that supports subscriptions, this doesn’t mean that other logical service boundaries should directly access the Event Store.
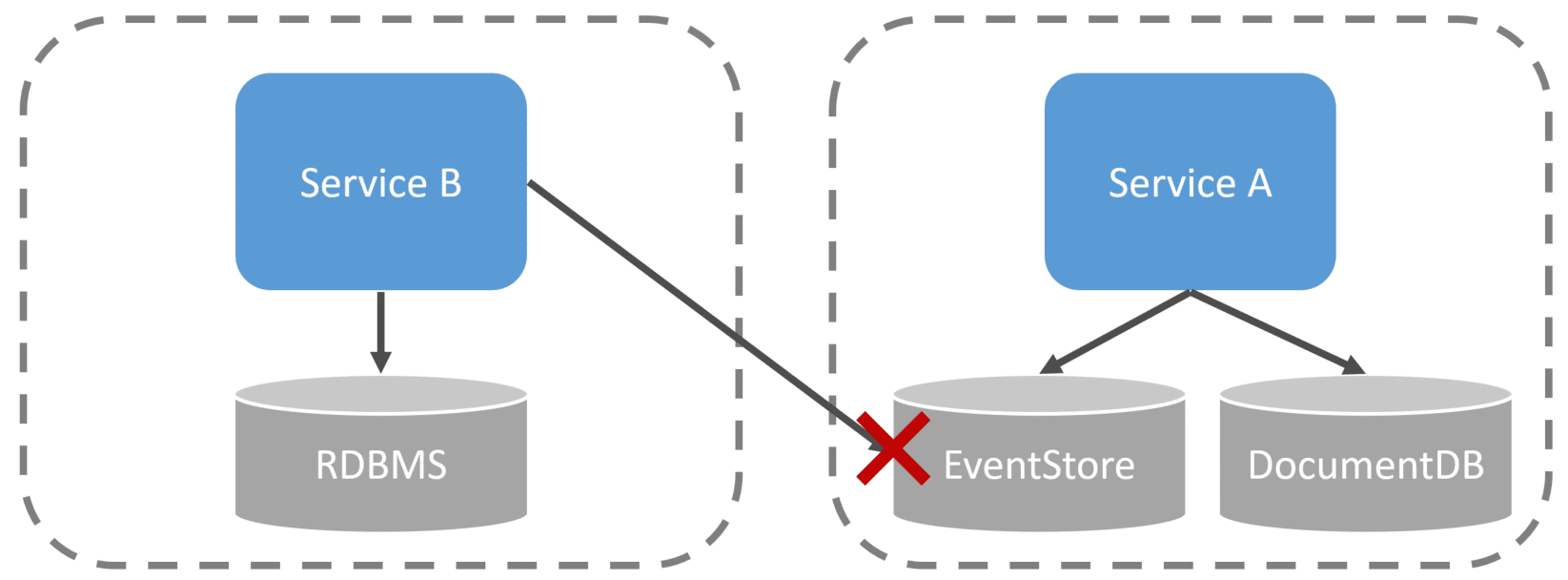
People often do this as a way of Pub/Sub which is used for communication. But there is a difference between Events used inside a logical boundary to represent state and events used to communicate with other services.
You wouldn’t have one service connect to another service’s relational database, would you? Then why would you access its Event Store?
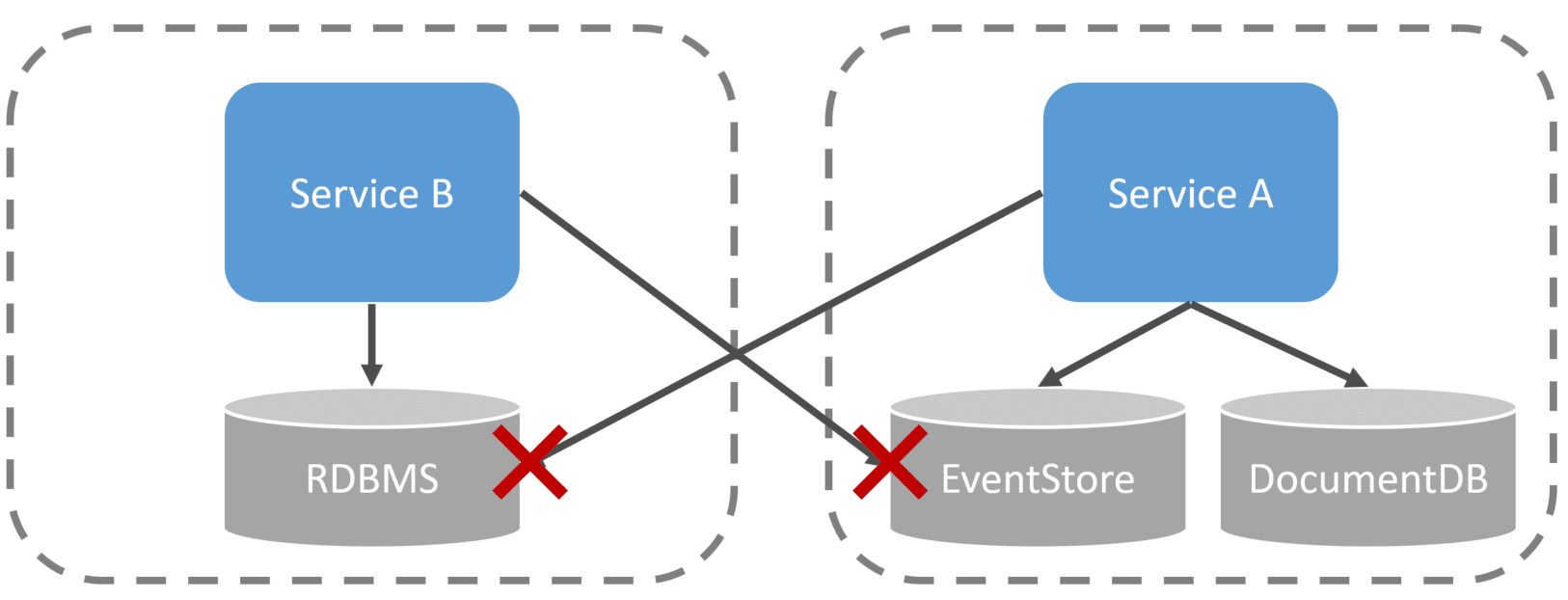
Domain Events used within a service boundary to represent the state are not integration events.
Domain Events: Inside Events
Integration Events: Outside Events
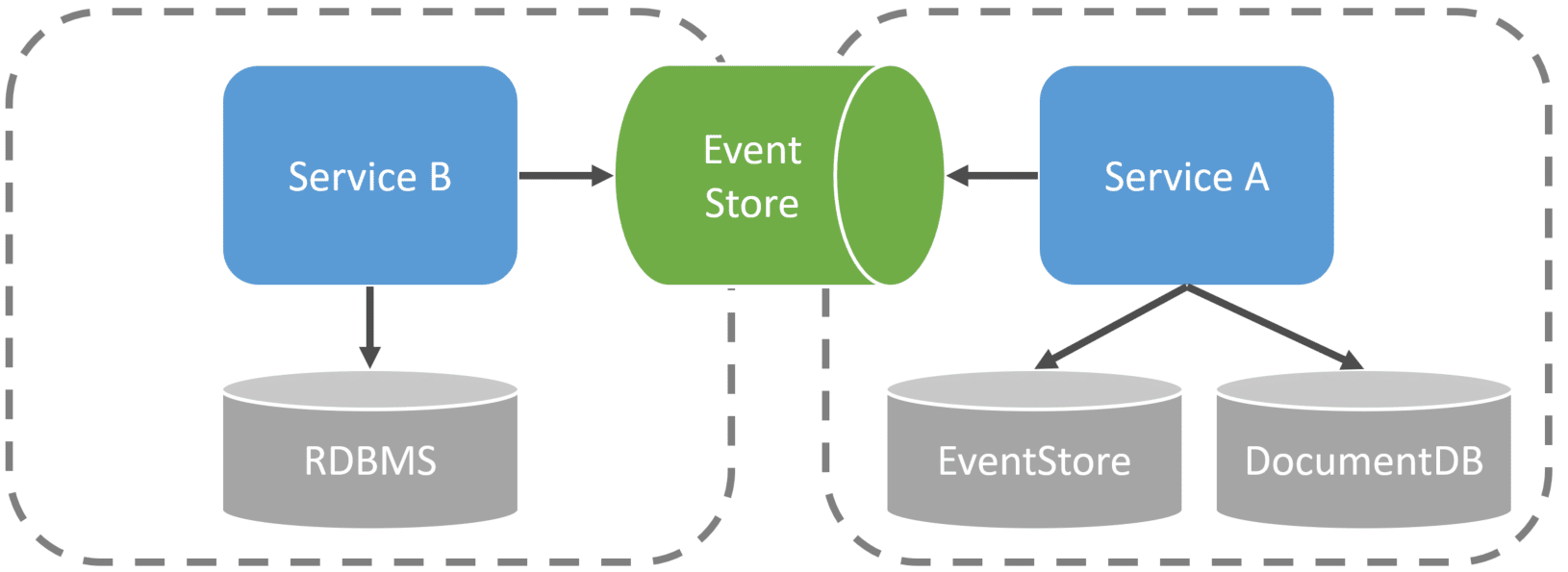
You want to define which events you want to publish to the outside world for integration. Domain Events and Integration events will be versioned entirely differently. The moment you expose a domain event to the outside world you potentially now have consumers that are going to rely on it. If you don’t publish your internal domain events, you can refactor and change events very differently.
If another service was interacting with your relational database, and you made a change to a column name, you’d break them. If you change an event that’s not backward compatible, you’re going to break consumers. Don’t expose internal domain events as integration events.
Event Sourcing do’s and don’ts
Hopefully, these three Event Sourcing Tips give some insights that can help you if you’re new to Event Sourcing or if you ever questioned how various aspects work.
Join!
Developer-level members of my YouTube channel or Patreon get access to a private Discord server to chat with other developers about Software Architecture and Design as well as access to source code for any working demo application that I post on my blog or YouTube. Check out the YouTube Membership or Patreon for more info.