Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
Event-driven architecture is excellent for decoupling—or is it? The industry is trending towards losing the value of decoupling because of how it uses and defines events. Let me explain so you can avoid getting caught up in the same coupling trap.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Events
I’ve been seeing events defined in four ways in the industry right now: in terms of size, they are either coarse or granularity and are derived from CRUD and data-centric or business-focused and behavior-centric.
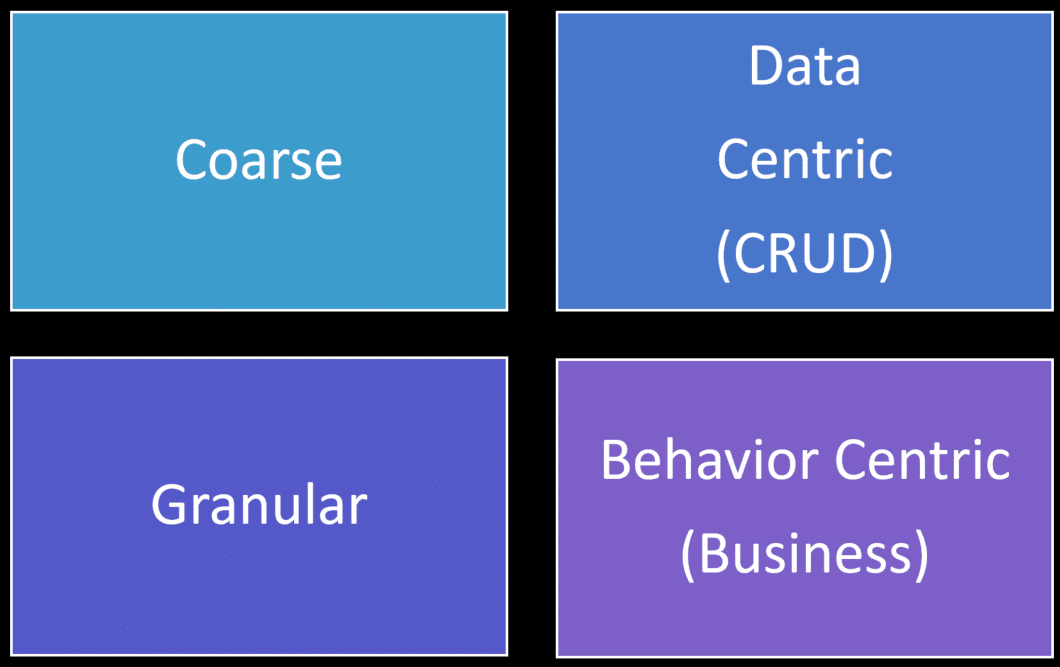
Coarse events are often called fat events because they generally contain a lot of data. More granular events are the exact opposite and are generally pretty slim and often only contain identifiers (IDs).
Data-centric events driven by CRUD often result in coarse events. If an “entity” changes in your system a course event would be the entire entity’s contents. On the other hand, behavior-centric events often result in more granular events that only contain identifiers or a limited amount of data because they are more often for notification purposes to other parts of your system for workflows and business processes.
I’ve been noticing an industry trend of coarse data-centric events driven by CRUD. Unfortunately, this loses some of the value of an event-driven architecture because of how these events are being used: data propagation. Event-driven architecture isn’t some magical silver bullet that removes coupling; it doesn’t. However, with the publish-subscribe pattern, you’re decoupling producer and consumer and often removing the temporal coupling if you’re using a message broker, but you still have a coupling of the event (message contract).
And when that event (message contract) revolves around the data because you want to propagate that data between services, it is where you have some unintended coupling that you might not realize.
Data-Centric
What do I mean by data-centric events? They are often when your system is very CRUD (create-read-update-delete). Where you have forms that allow you to create an “entity”, update it and delete it. When you do this, you might create events that mimic CRUD. For example, you might have a ProductChanged event that contains all the data that was updated or the entire entity and its new state in the event.
They can also be a bit more fine-grained but still CRUD-driven. If you can update a specific field or subset of fields, you may end up with a ProductPricedChanged event as an example.
This has become fairly popular with current tooling, like Change Data Capture (CDC) tools that have the ability to capture database changes, then convert those to events and publish them to your event or message broker.
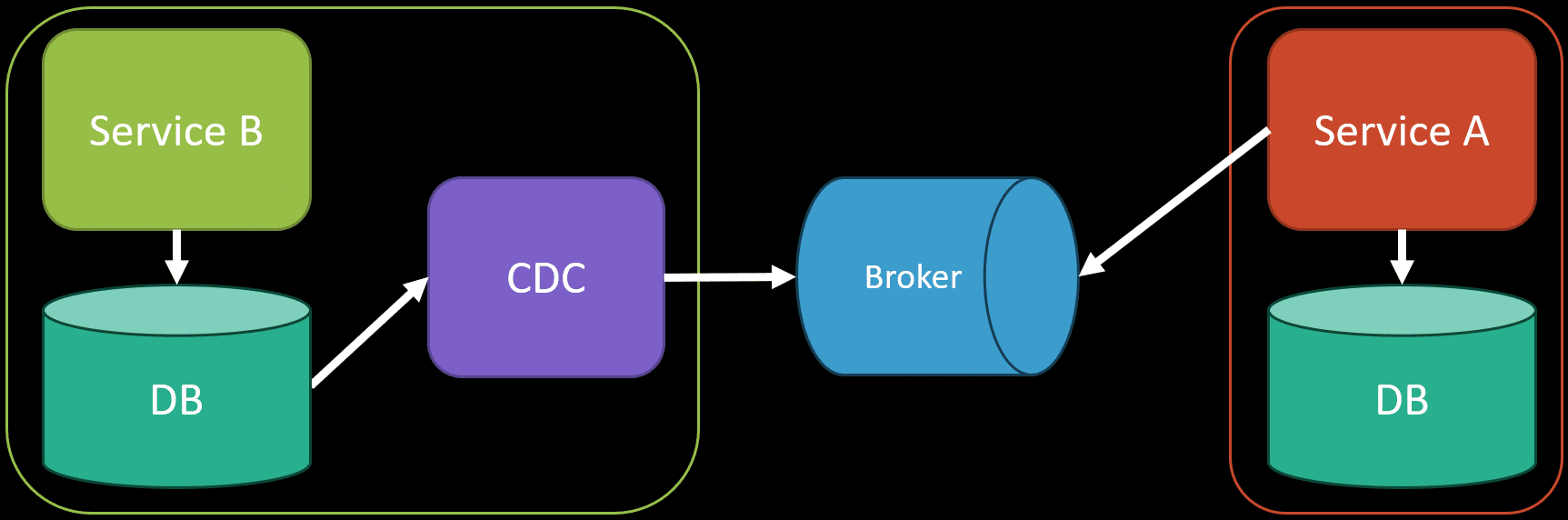
The issue is you’re leaking internal implementation details. Your database schema is private information to your service (ServiceB) which is being leaked our via CDC and an event to Service A. If you change any schema details of Service B, service A needs to be already aware of it immediately. There is no difference between the diagram above and interactiving with another services database directly (which I do not recommend).
Events are an API and a contract.
A common solution is to add some type of translation so that the event generated from the CDC tool is translated/transformed into another type of event.
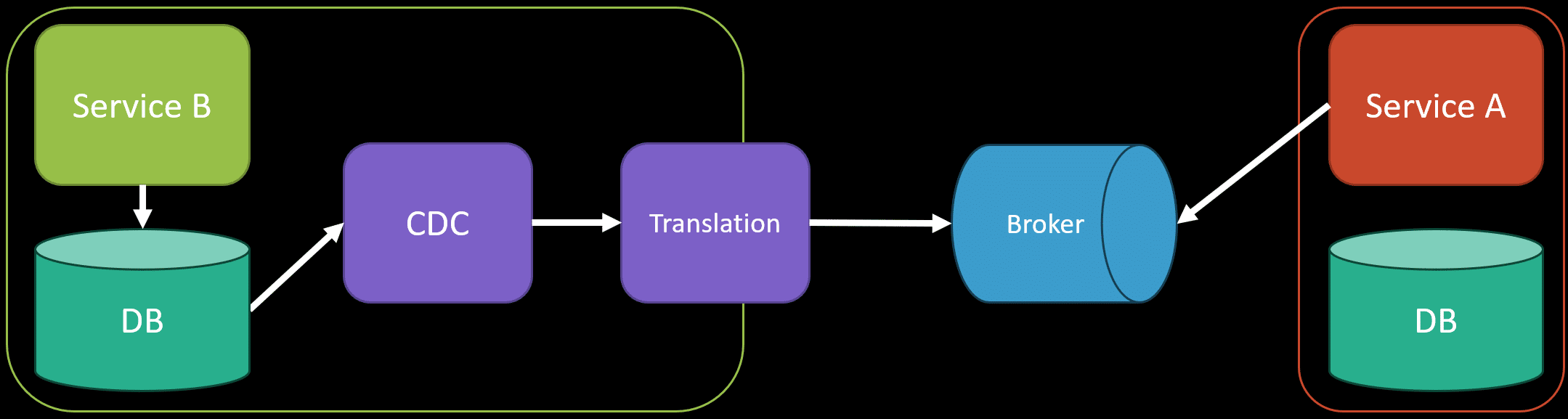
This way, we’re not exposing or leaking any internal implementation details of Service B. Rather, we have an explicit API/contract of events that are used for integration between other services.
It sounds great, but there’s still a glaring issue. You’re using an event-driven architecture for data distribution to propagate data between services.
First question. Why do you need data from another service? If you think you need data from another service, check out my post, “I NEED data from another service!”… Do you really?
Second question. An event represents something that happened. Do you know what happened when a ProductChanged event occured?
Sure, the data changed. But why did it change? You might be able to imply it if you know what data changed. Take, for example, a ProductPriceChanged event. Sure, you might know the price went up or down, but why? There are business reasons why. It’s not explicit. You’re losing that information with CRUD-driven events.
Business concepts are things that the business cares about, which is what you’re writing software for. They are not technical nonsense but actual business concepts.
Behavior Centric
As an example, there’s a difference between ProductUpdated and InventoryAjdusted.
Why did a ProductUpdated event occur? Why was a product updated? No idea.
InventoryAdjusted is an explicit business concept that occurs in the warehouse. If you do a stock count, you may adjust inventory. Part of the InventoryAdjusted might be a reason code for why you’re increasing or decreasing. For example, the product was damaged, or more product was found. The event contains explicit information about why the product quantity is changing.
EmployeeDeleted event. What? EmployementEnded. Ok, it makes a bit more sense and has some context.
EmployeeRoleUpdated event. Or EmployeePromoted. Which one do you think has more context and explains why something occurred?
In your own system, you can probably think of many of these examples where your end users perform actions in the system for a specific reason. Capturing these behaviors leads to realizing they are often a part of business processes and workflows. That’s why you care about them.
Here’s an example of an e-commerce checkout with a payment.
The first step is going to the checkout process, which would persist in a temporary order in our database.
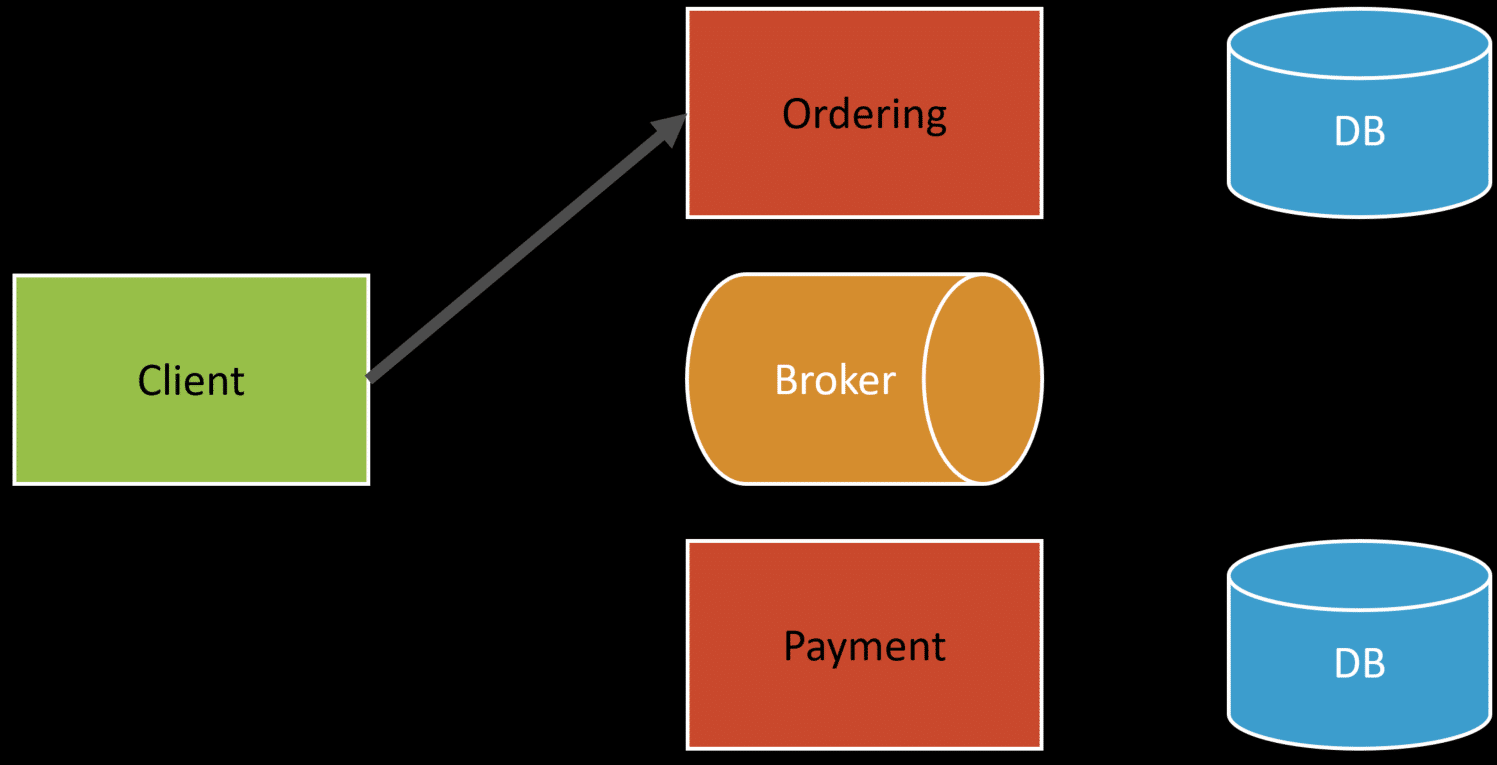
The OrderID is often a GUID generated by the client. This doesn’t need to be an untrusted client (browser) but rather generated on the server prior to processing.
The client going through the checkout next entered the payment and submits that to a different service, using the same orderID.
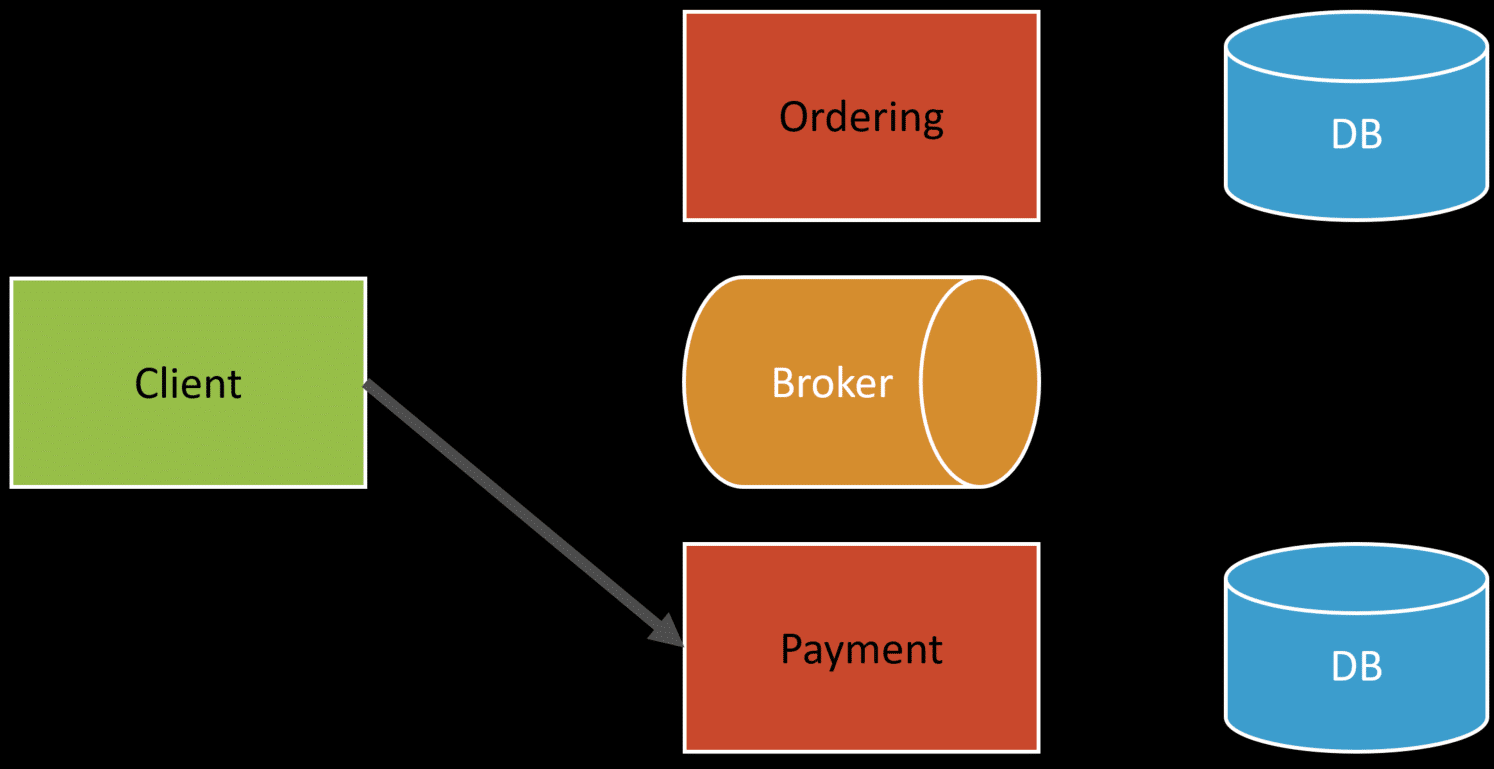
Finally, the client finalizes and places the order, which marks it as “Placed”. At this point the order service has persisted the order in a Placed state and publishes an OrderPlaced event.
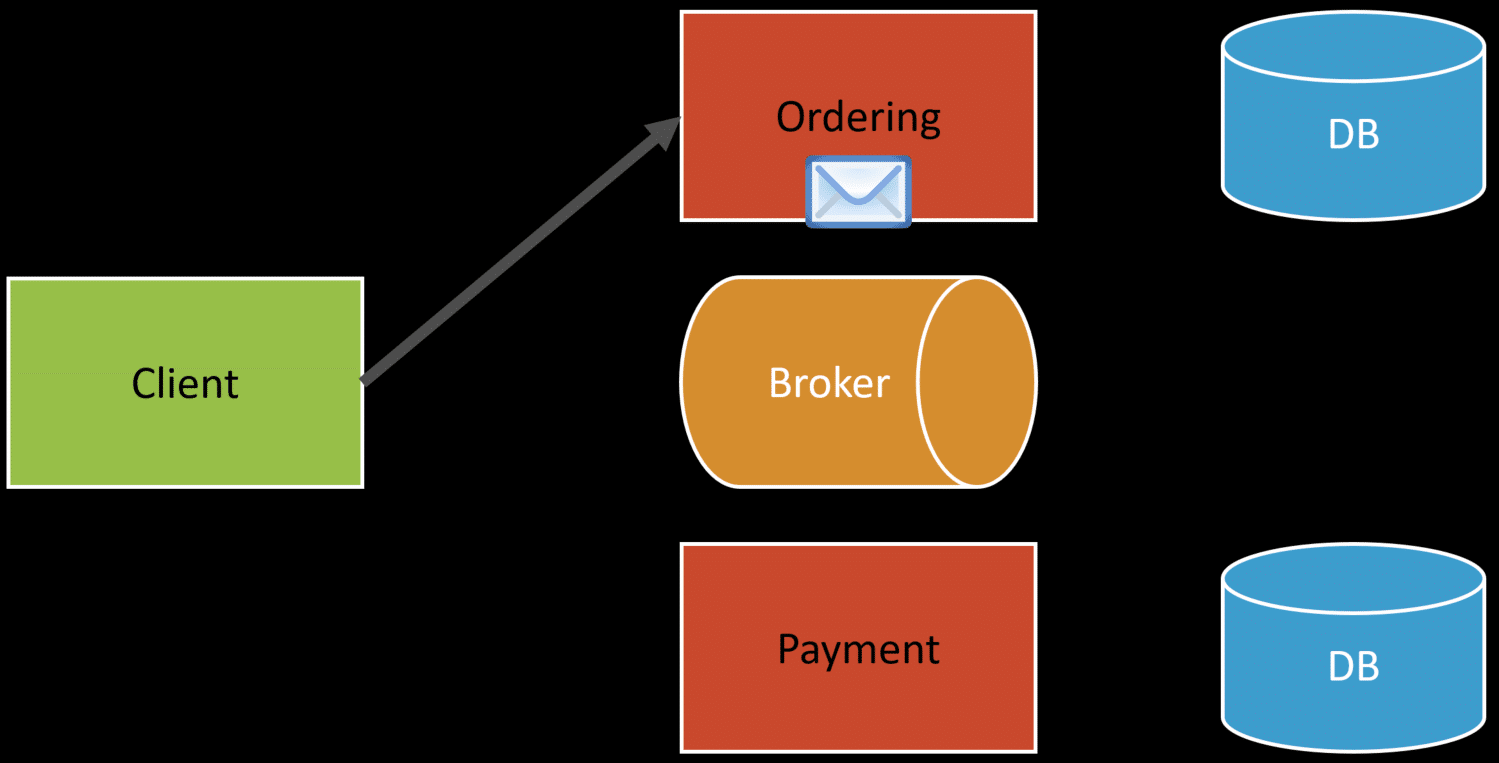
The OrderPlaced event only has the OrderID for reference. It doesn’t need to propagate data or contain any of the payment information in the event, because the payment service already has the data it needs.
Coupling
The industry trend of using event-driven architecture as data distribution doesn’t magically remove the coupling from your system. Sure, you’re removing the temporal aspect, but you’re still just as coupled as making RPC calls to call another service at runtime to get data. You’re coupling services together by data. At worse, stale or inconsistent data.
That’s not to say I don’t think there’s any use case for events as a form of data distribution. One of them is for reporting purposes. You need to combine data from various services to compose data for reporting. There are other alternatives to doing this, but I do think it has its place. Check out my post on event-carried state transfer.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.