Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.
I’m convinced that CRUD APIs and CRUD-driven systems—meaning systems built around Create, Read, Update, and Delete operations—are, in the long run, the hardest to change and evolve. This might sound unintuitive at first, especially since many of us have read blog posts, watched videos, or taken courses on building HTTP APIs under the guise of REST. But often, what we’re really doing is just CRUD-driven development over a database record using HTTP methods and JSON.
YouTube
Check out my YouTube channel, where I post all kinds of content accompanying my posts, including this video showing everything in this post.
Beyond CRUD
Ultimately, what ends up happening is that we try to map HTTP methods to relational database operations. For example, a GET request corresponds to a SELECT, a POST to an INSERT, PUT or PATCH to UPDATE, and DELETE to DELETE.
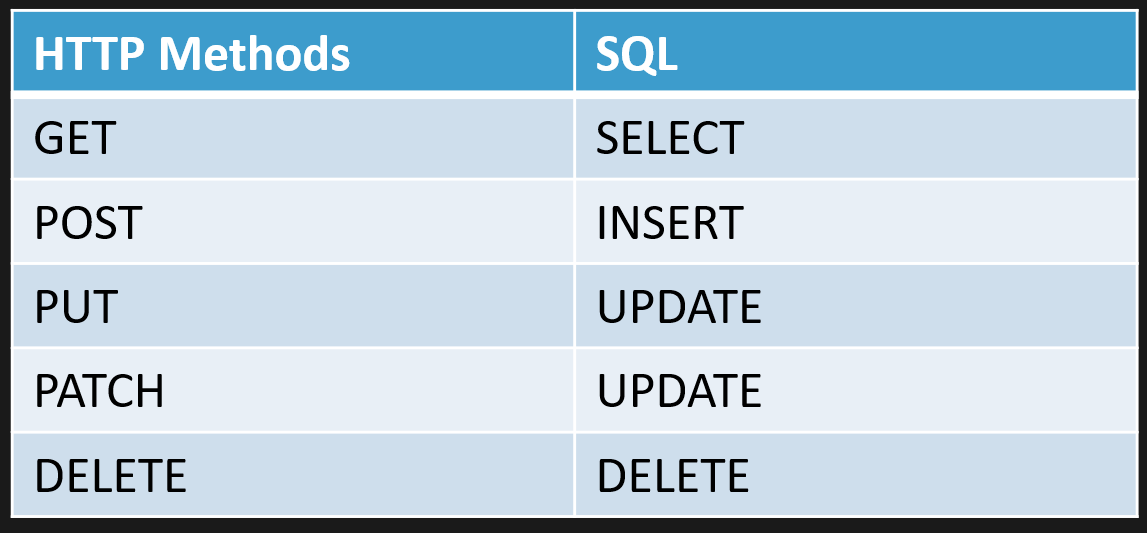
This is not REST as most would believe. Rather, it’s CRUD over HTTP with usually JSON.
This leads us into a world of bike-shedding about how APIs should be designed—how we construct URIs, which HTTP methods to use, and how to return status codes properly. You’ve probably seen the standard way people advocate for this: if you want to get a shipment (like a package delivery), you call GET on the URI /shipment/{id}, which is just a read or select. To create a new shipment, you POST to that URI. To update or partially update, you PUT or PATCH, and to delete, you DELETE the shipment. This is the typical CRUD mapping.
But how can this be bad, you might ask? CRUD is everywhere, it’s advocated for widely.
What’s Wrong with a CRUD-Driven API?
There’s nothing inherently wrong with CRUD APIs. However, if you plan on building a system that’s long-lived, it becomes really hard to evolve and change for a couple of reasons. The first big issue is that the focus is on data and data structures. Essentially, you’re just building an API or UI on top of data structures that represent your business processes. But here’s the catch: those business workflows and processes aren’t actually captured in your system—they live entirely in your end users’ heads.
What you’re exposing is the data structure behind those processes, not the processes themselves. Over time, business processes change. The way users think about performing tasks evolves, but the data structure you built might not fit anymore. Or you might have new processes that don’t align well with the existing data structure. This is when you get into the “square peg, round hole” problem.
Let me know if you can relate to this. Many times, I’ve faced situations where we needed to implement something new, but the existing system just didn’t seem to fit the new requirements. So, what do you do? You try to shimmy it in somehow, and it feels gross and hacky. But the system is so hard to change that you have no real options—you just make it work.
Here’s the unintuitive part: by doing this, you’ve actually made your system harder to change. Why? Because originally, you built your data structure around one business process—one that might only exist in your users’ heads. Now, you’re trying to force another business process on top of that same data structure. This means you’re coupling two unique business processes to the same underlying data structure. So, if you need to change the data structure, you’re now affecting two very different processes.
Focus on Business Capabilities, Not Just Data
Instead of focusing on data, focus on what your system actually does—its capabilities. A business capability defines an organization’s capacity to successfully perform a unique business activity. It’s about the what. What does your system actually do?
Using my example of shipment or package delivery, how does that actually work? With CRUD, you’d POST to create a shipment, then PUT or PATCH to update it. But what does “update” really mean here? What are you updating about the shipment? That’s not really how business processes work.
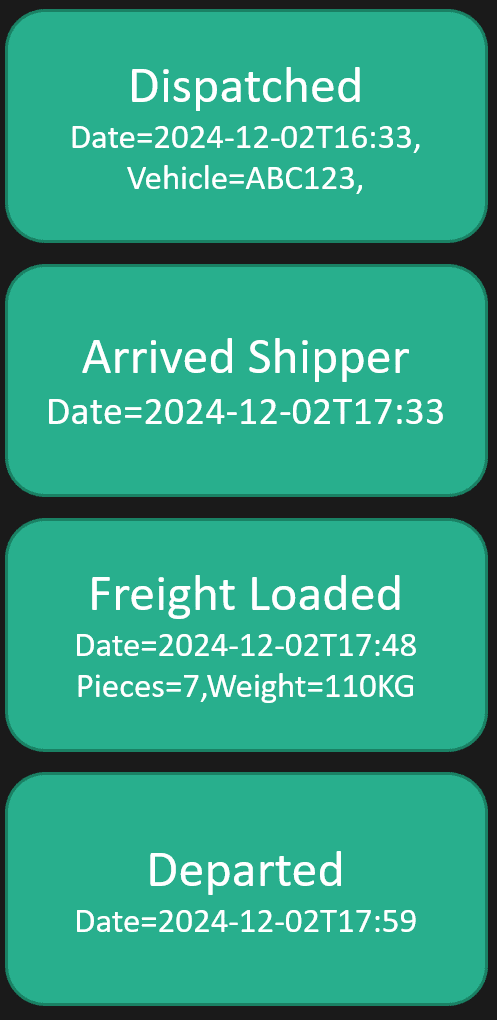
Like many business processes, shipment has a life cycle—a beginning and an end. The first thing that happens is dispatch: you tell a driver or someone with a vehicle, “Hey, you need to pick up this package.” Behind that, there’s data like the date and time, which vehicle is on route, and so on.
When the vehicle arrives at the shipper’s location, that’s another event with its own data—arrival time, for example. Then when the package is physically loaded onto the vehicle, there’s again data like the number of packages, total weight, and date-time of loading. This continues with departure, route progress, stops, and eventually delivery.
This is all part of a sequence, a workflow, or a life cycle. How would you represent this with typical CRUD operations? You wouldn’t, because there’s a hierarchy and process involved. It’s not just “update shipment” and set some dates. The workflow captures explicit events and states that are happening during the process.
Why Capturing Workflow Explicitly Matters
Explicitly capturing the workflow and behaviors allows your system to evolve. For example, when the freight is loaded onto the vehicle, maybe you want to trigger different actions—like sending a webhook to third parties, notifying customers via email, or integrating with other systems.
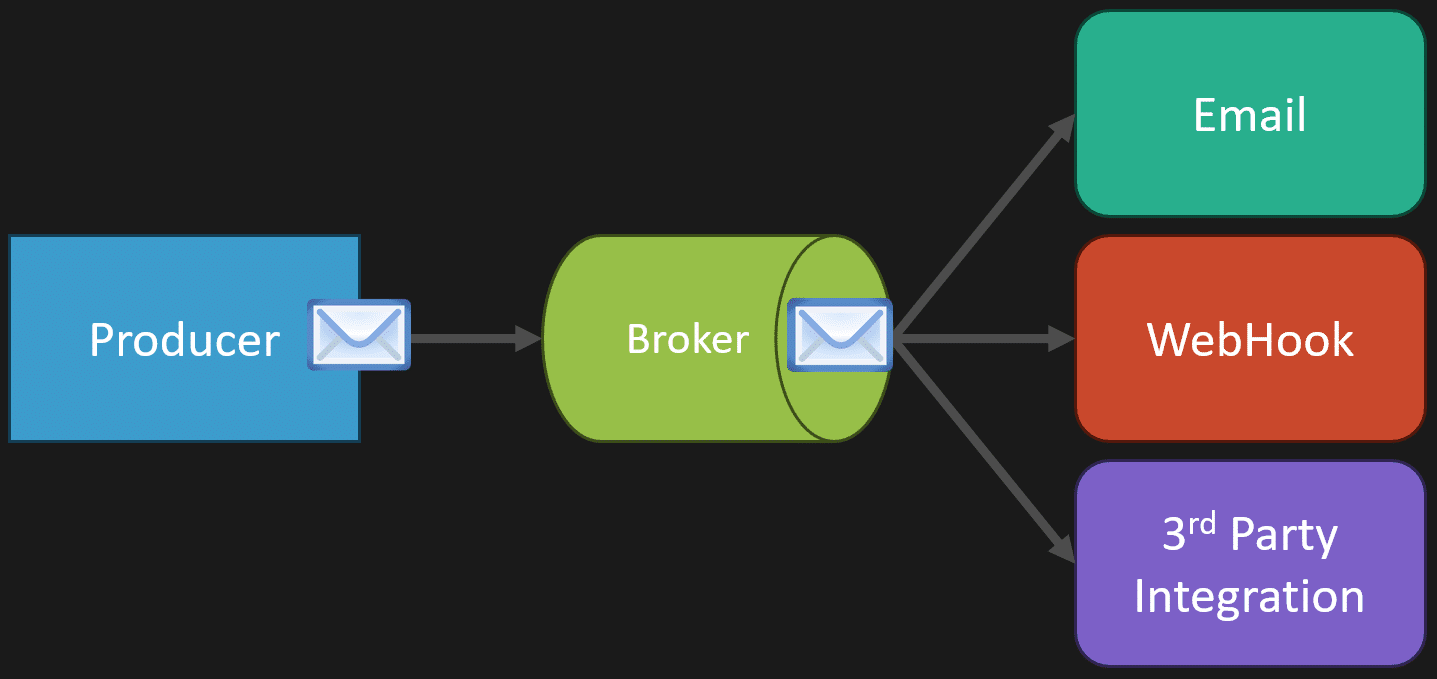
You’ve probably all received emails when you order something online—tracking info, status updates, arrival notifications. Those emails are triggered by events in the shipment’s lifecycle, not by CRUD operations on a shipment record.
Similarly, third-party integrations might require calling external APIs when certain events occur. These are completely independent of each other. If one integration becomes irrelevant, you just remove it. If a new requirement comes up, you add it. Nothing is coupled to anything else except the event or action within the business process.
What you’re really doing is capturing the business process—the capabilities and behaviors—and then modeling the data behind those behaviors. This is very different from just exposing internal data structures through CRUD APIs.
The Problem with CRUD: Exposing Internal Data Structures
When you use CRUD, you expose internal data structures as your API. This causes tight coupling between consumers and your internal implementation. For example, imagine you have billing and shipping systems. If billing accesses the shipment schema directly, any change in shipping’s internal data structure breaks billing. This makes evolving the shipping system very difficult.
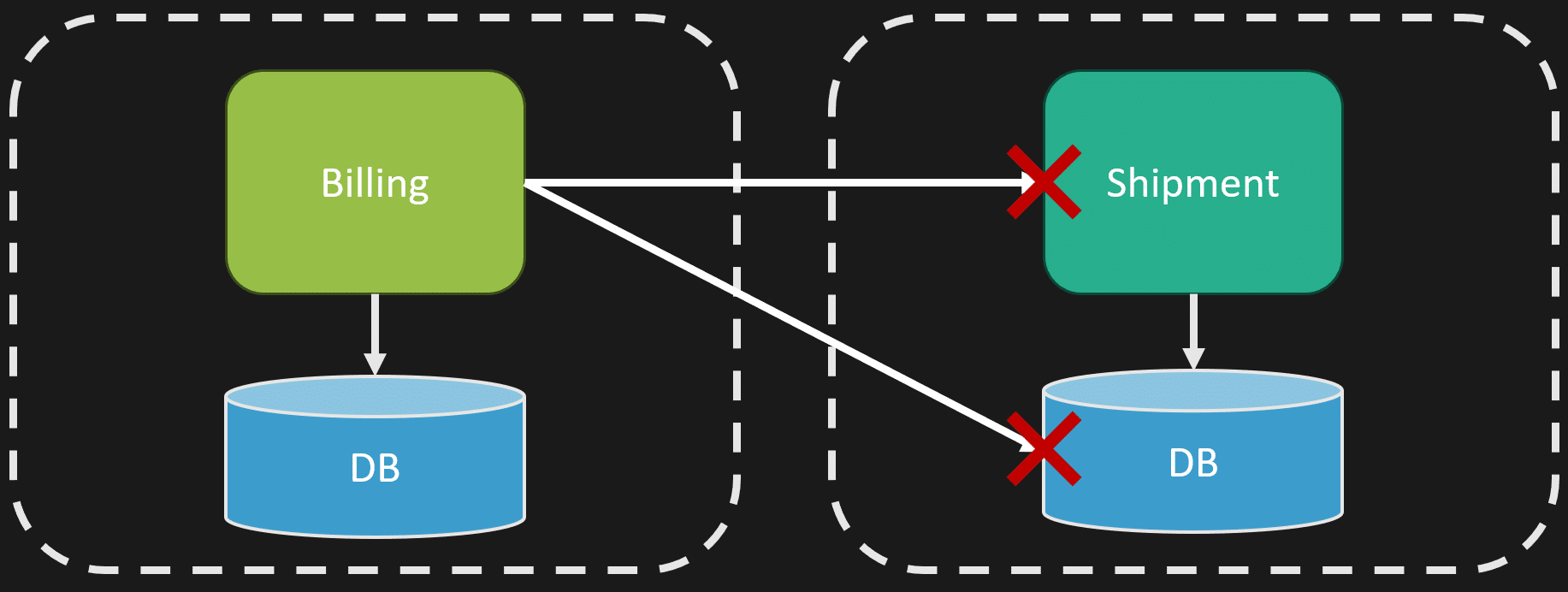
Instead, you want to expose an API that acts as a contract. This API defines what you expose to the outside world, allowing you to evolve your internal processes and data models independently. The data model you use to persist information and the domain model representing your workflows aren’t the same—they shouldn’t be.
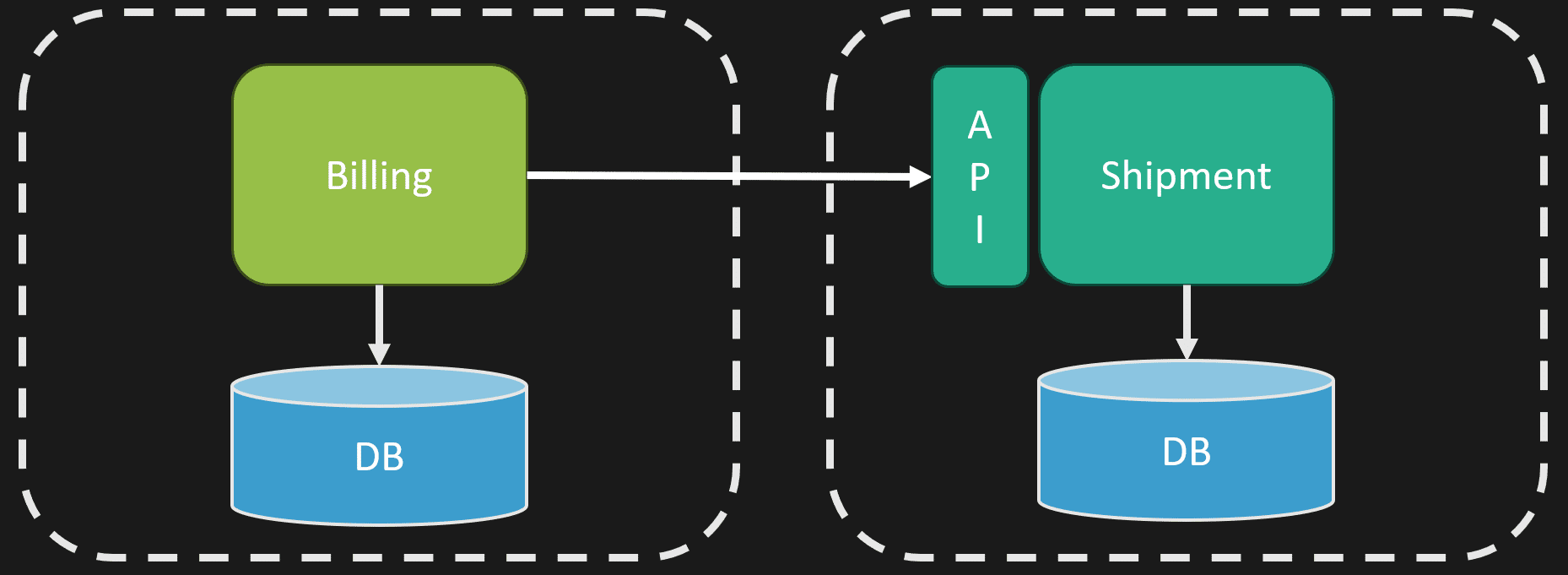
You want to capture the domain workflows explicitly and surround them with an API fortress—a defined boundary that hides internal complexity and protects your system from external dependencies.
How Explicitly Capturing Workflows Enables Evolution
When you explicitly model behaviors and workflows, evolving your system becomes easier. Let’s revisit the shipment example. Suppose you need to add a new step in the process—a stop at a border crossing, for instance. This stop isn’t related to freight loading but is part of the shipment’s lifecycle.
With a workflow-based model, you can add this new step easily without breaking existing functionality. If you have a new type of shipment with a different workflow, you can model it independently instead of shoehorning it into your existing CRUD-based model.
You don’t need one model to rule them all. Each business process can be modeled and evolved independently, which is the opposite of what happens in CRUD-based systems that live a long time.
CRUD-based systems often build data structures on a specific business process that’s only in users’ heads. Trying to fit other business processes into the same structure leads to coupling and fragility. When you change one process, you risk breaking others that aren’t even explicitly defined in your system.
Are CRUD-Based Systems Bad?
To be clear: CRUD systems are not bad by nature. It really depends on the context and what you’re using them for. Many systems have supporting or referential data without complex business processes on top. Those systems are perfectly suitable for CRUD APIs.
What’s problematic is using CRUD-based systems where you have complex workflows and business processes layered on top. That’s when CRUD becomes a poor design choice.
When CRUD Works Well
- Simple, static data that supports business processes but doesn’t have workflows itself.
- Reference data like countries, currencies, or user profiles where the operations are straightforward.
- Systems where business logic and workflows are minimal or handled elsewhere.
When CRUD Falls Short
- Systems with complex business workflows and life cycles.
- Applications that require flexibility to evolve processes independently.
- Systems needing integration with external services triggered by domain events.
Join CodeOpinon!
Developer-level members of my Patreon or YouTube channel get access to a private Discord server to chat with other developers about Software Architecture and Design and access to source code for any working demo application I post on my blog or YouTube. Check out my Patreon or YouTube Membership for more info.