Sponsor: Do you build complex software systems? See how NServiceBus makes it easier to design, build, and manage software systems that use message queues to achieve loose coupling. Get started for free.

In my previous post, I explored how words and language used by users of our system in our domain space can have different meaning based on their context. This establishes which services own which behavior and data. In this post, I’m going to explore why services are autonomous and how we can communicate between them
This blog post is in a series. To catch up check out these other posts:
- Context is King: Finding Service Boundaries
- Using Language to find Service Boundaries
- Focus on Service Capabilities, not Entities
- 4+1 Architectural View Model
Autonomy
Autonomy is the capacity to make an informed, uncoerced decision. Autonomous services are independent or self-governing.
What does autonomy mean for services? A Service is the authority of a set of business capabilities. It doesn’t rely on other services.
We are constantly in a push/pull battle between coupling and cohesion. High coupling ultimately leads to the big ball of mud.
What’s unfortunate is the move to (micro)services with non-autonomous services that rely on RPC (usually via HTTP) hasn’t reduced coupling at all. It’s actually made the problem worse by introducing an unreliable network turning the big ball of mud into a distributed big ball of mud.
Prefer Messaging over RPC
We want services to be autonomous and not rely on other services over RPC to reduce coupling. One way to do this is to communicate state changes between our services with events.
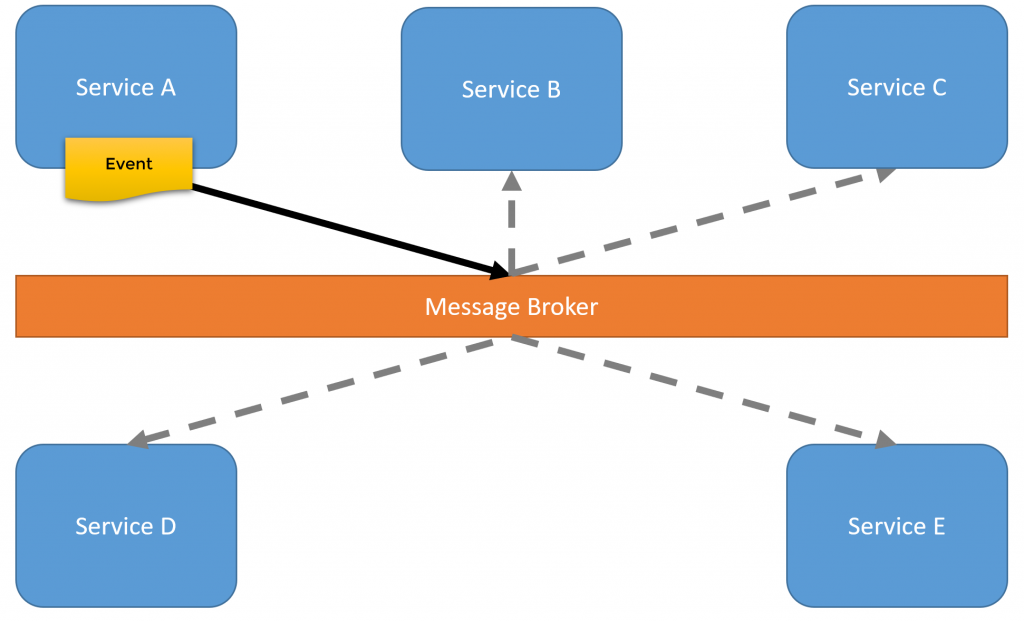
When Service A has a state change, we publish that event to our message broker. Any other service can subscriber to that event and perform whatever action it needs to internally. The producer of the event (Service A) doesn’t care about who may consume that event.
Services that don’t Serve
This may seem completely counter-intuitive since the definition of a service is an act of assistance. However, an autonomous service does not want to assist other services synchronously via behaviors, rather exposing to other services things that have happened to it via asynchronous messaging.
An example of this in our distribution domain is in the form of Sales services and the quantity on hand of a product.
Does Sales need the quantity on hand of a product?
Sort of. You could assume without knowing this domain that you do not want to oversell. However, in my experience in distribution, overselling isn’t really a sales problem as it is a purchasing problem.
Sales want to know the quantity on hand of a product, as well as what has purchasing ordered from the vendor but has not yet been received. This is called Available to Promise (ATP) and is used by sales to determine if they can fulfill an order for a customer.
Another interesting point is related to Quantity on Hand. The quantity on hand that is owned by the warehouse service is still not really the point of truth for the real quantity on hand. Whatever the quantity on hand is for a product in a database isn’t the truth. The real truth is what’s physically in the warehouse. Products get damaged or stolen and aren’t immediately reflected in the system. This is why physical stock counts exist which end up as inventory adjustments in our warehouse service.
If we’re using RPC, for the Sales Service to calculate ATP it would need to make synchronous RPC to:
- Purchasing Service to get what purchase orders have not yet been received.
- Warehouse Service to get the quantity on hand.
- Invoicing Service to determine what other orders have been placed but not yet shipped.
However, if we want our Sales Service to be autonomous it needs to manage ATP itself. It can do so by subscribing to the events of the other services.
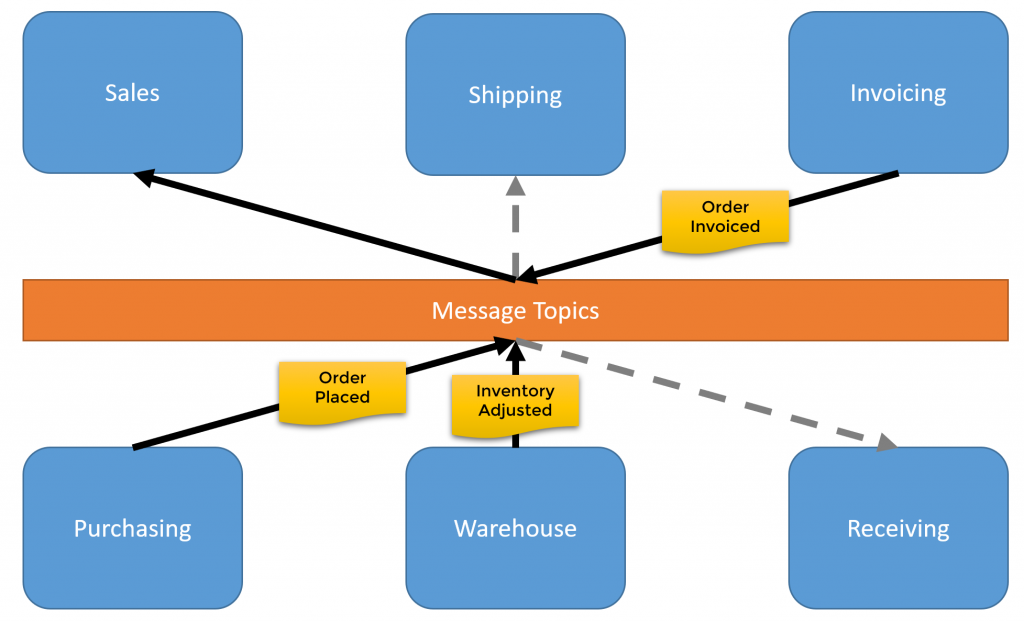
Sales can manage it’s own ATP for a product subscribing to the various events. When a purchase order is placed it will increase the ATP. When inventory is adjusted it will increase or decrease the ATP. And finally when an order is invoiced it will decrease it’s ATP.
Blog Series
More on all of these topics will be covered in greater length in other posts. If you have any questions or comments, please reach out to me in the comments section or on Twitter.